Learning discrete Bayesian networks with hierarchical Dirichlet shrinkage
Pith reviewed 2026-05-18 15:52 UTC · model grok-4.3
The pith
A hierarchical prior on conditional probabilities shrinks discrete Bayesian networks to low-dimensional latent parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a hierarchical Dirichlet model for node-parent conditional probabilities in discrete Bayesian networks induces a posteriori shrinkage to low-dimensional latent parameters. Posterior samples of these latent variables are generated via the Metropolis-adjusted Langevin algorithm within a Gibbs sampler. The full conditional distribution is shown to be log-concave under mild conditions, which supports efficient sampling. Structure-learning algorithms are developed that incorporate the hierarchical prior while preserving the DAG property.
What carries the argument
The hierarchical Dirichlet shrinkage prior placed directly on the conditional probability tables of each node given its parents, which concentrates posterior mass on a lower-dimensional latent representation.
If this is right
- Improved parameter estimation when cell counts are sparse.
- More reliable recovery of network structure in simulated settings.
- Principled selection among competing DAGs.
- Practical application to prognostic networks in categorical medical data.
Where Pith is reading between the lines
- The shrinkage mechanism could be combined with other structure priors to further regularize very high-dimensional networks.
- The same hierarchical construction might apply to learning in other discrete graphical models that suffer from parameter proliferation.
- Testing the method on longitudinal or time-stamped categorical data would check whether the latent-parameter reduction remains effective outside static networks.
Load-bearing premise
The full conditional distribution is log-concave under mild conditions, allowing the Metropolis-adjusted Langevin step to sample efficiently inside the Gibbs sampler.
What would settle it
Simulations in which the posterior mass does not concentrate on the low-dimensional latent parameters, or in which the structure-learning algorithms recover the true DAG no better than standard non-hierarchical methods, would falsify the claimed benefit.
Figures


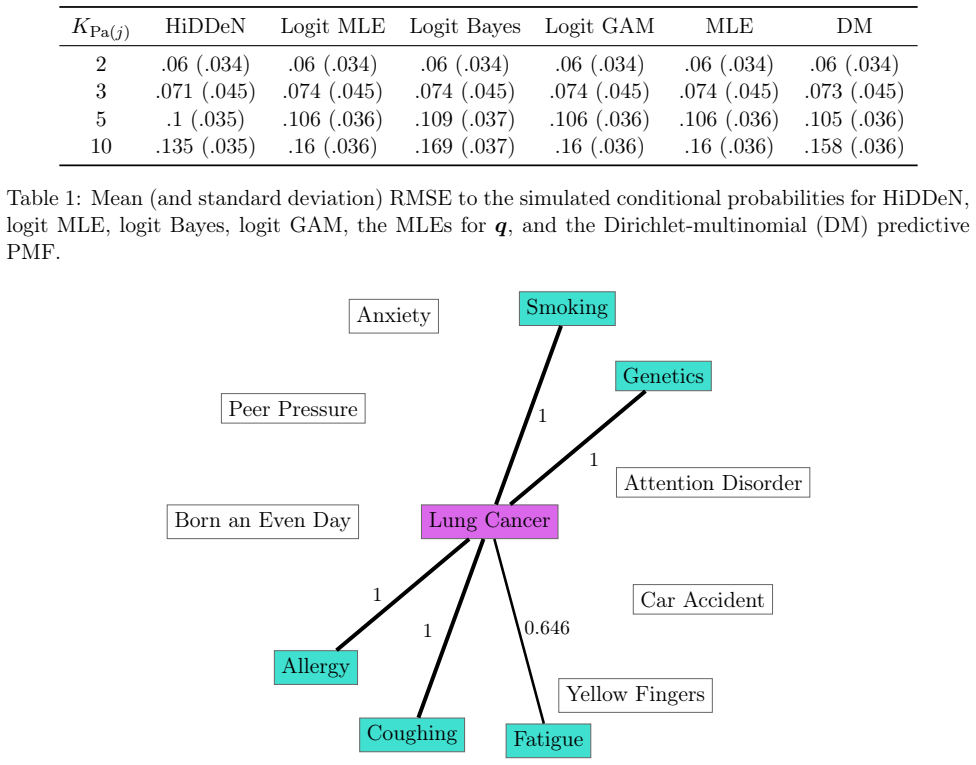



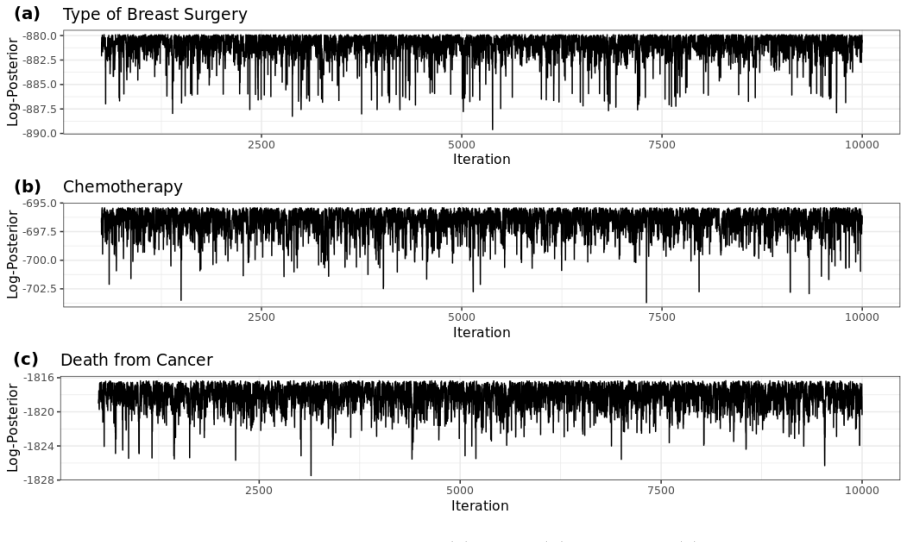


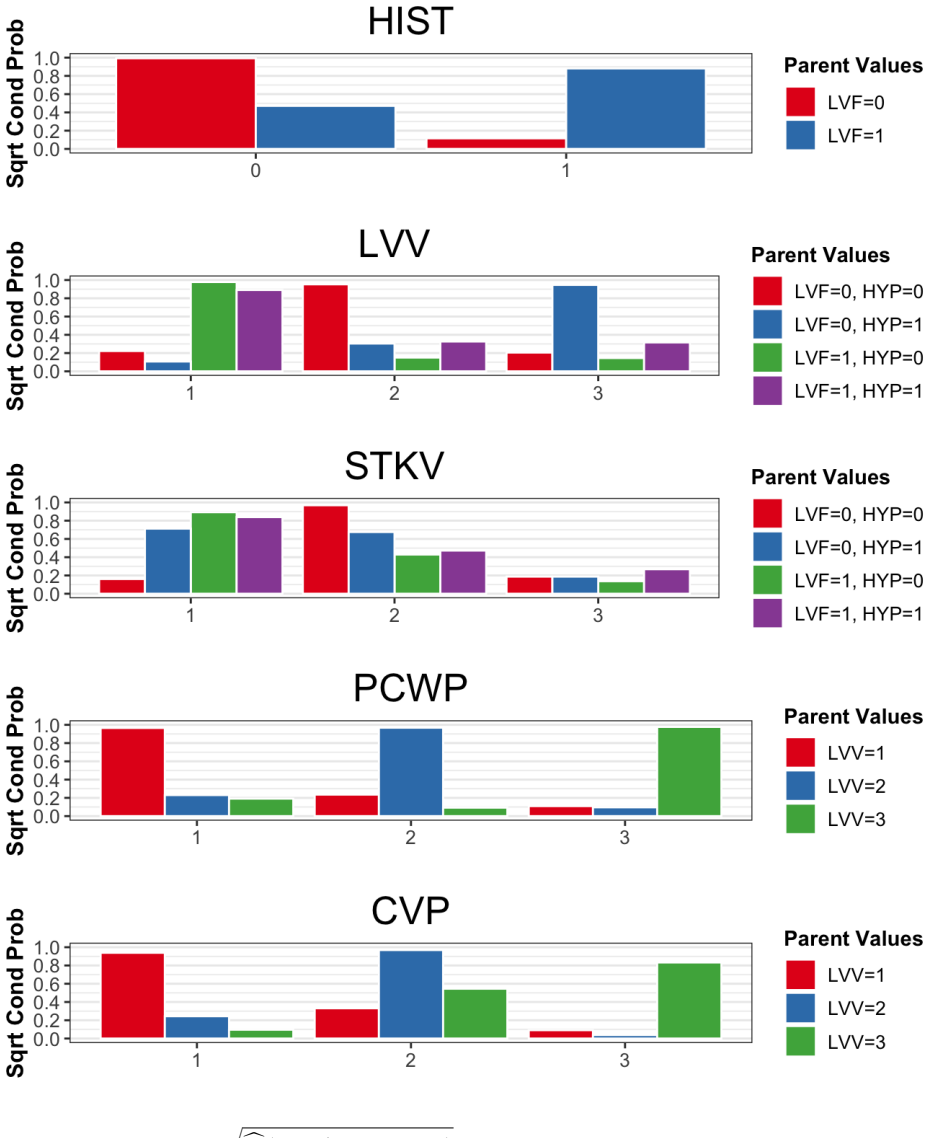
read the original abstract
A discrete Bayesian network is a directed acyclic graph (DAG) consisting of categorical variables. Two popular approaches for DBN modeling include classification and nonparametric methods. However, both methods often require a large number of parameters, such as high-order interactions in the former and cell probabilities in the latter. In this article, we propose a hierarchical model for node-parent conditional probabilities, inducing shrinkage to low-dimensional latent parameters aposteriori. We generate samples from the posterior distribution of these latent variables using the Metropolis-adjusted Langevin algorithm within a Gibbs sampler. Moreover, we verify that the full conditional distribution is log-concave under mild conditions, facilitating efficient sampling. We then detail several algorithms for structure learning that incorporate our hierarchical prior and preserve the DAG property. Through simulations, we evaluate the performance of our method for sparse counts, discovering graph structure, and selecting between competing DAGs. We conclude with an application to uncovering prognostic network structure from a breast cancer dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical Dirichlet model for the conditional probability tables of discrete Bayesian networks that induces posterior shrinkage toward low-dimensional latent parameters. Posterior inference on the latents is performed via a Metropolis-adjusted Langevin algorithm (MALA) embedded in a Gibbs sampler, with the claim that the relevant full conditional is log-concave under mild conditions. The prior is incorporated into several structure-learning algorithms that preserve the DAG property. Performance is assessed via simulations on sparse counts, graph recovery, and model selection, followed by an application to prognostic network structure in a breast cancer dataset.
Significance. If the log-concavity result and resulting sampler efficiency hold for general parent sets, the approach supplies a practical Bayesian shrinkage mechanism for high-dimensional discrete BN parameters, potentially improving inference under sparse data relative to saturated or nonparametric alternatives while retaining interpretability through the latent-parameter hierarchy.
major comments (2)
- [Abstract / Sampling Method] Abstract and sampling section: the assertion that 'the full conditional distribution is log-concave under mild conditions' is load-bearing for the efficiency of the MALA-within-Gibbs sampler. No explicit statement of the mild conditions, nor a derivation or Hessian analysis for arbitrary parent cardinalities and sparse count regimes, is supplied; without this the claimed mixing guarantees and downstream structure-learning reliability cannot be verified.
- [Hierarchical Model] Section on hierarchical model: the low-dimensional latent parameters to which the node-parent CPTs shrink are introduced without a precise mapping from parent-set cardinality to latent dimension. This leaves open whether the shrinkage remains effective (and the log-concavity claim intact) when parent sets grow or when observed counts are extremely sparse, both of which are central to the simulation experiments.
minor comments (2)
- [Model Specification] Notation for the hierarchical Dirichlet layers and the latent-parameter dimension should be introduced with an explicit equation or diagram early in the model section to avoid ambiguity when parent sets differ across nodes.
- [Simulations] Simulation tables would benefit from reporting effective sample sizes or autocorrelation times for the MALA chains to substantiate the efficiency claim beyond visual trace plots.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript. We address each major comment below in detail and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Sampling Method] Abstract and sampling section: the assertion that 'the full conditional distribution is log-concave under mild conditions' is load-bearing for the efficiency of the MALA-within-Gibbs sampler. No explicit statement of the mild conditions, nor a derivation or Hessian analysis for arbitrary parent cardinalities and sparse count regimes, is supplied; without this the claimed mixing guarantees and downstream structure-learning reliability cannot be verified.
Authors: We agree that an explicit statement of the mild conditions and supporting derivation would strengthen the presentation. The conditions are that all observed counts are strictly positive and that the latent Dirichlet parameters lie in the interior of the probability simplex. In the revised manuscript we will add a precise statement of these conditions in the sampling section and include a full Hessian analysis of the log full-conditional density in a new appendix. The analysis shows that the Hessian remains negative definite for any finite parent cardinality provided the positivity conditions hold, which covers the sparse-count regimes examined in our simulations. We will also note that the MALA step-size tuning used in the experiments already reflects the curvature under these conditions. revision: yes
-
Referee: [Hierarchical Model] Section on hierarchical model: the low-dimensional latent parameters to which the node-parent CPTs shrink are introduced without a precise mapping from parent-set cardinality to latent dimension. This leaves open whether the shrinkage remains effective (and the log-concavity claim intact) when parent sets grow or when observed counts are extremely sparse, both of which are central to the simulation experiments.
Authors: The latent dimension d is a fixed hyperparameter chosen independently of parent-set cardinality (typically d=2 or 3 in our experiments) so that the shrinkage strength increases with the size of the CPT. We will revise the hierarchical-model section to state this mapping explicitly: for a node with c categories and parent configuration of size m, the CPT is of dimension c by (product of parent cardinalities), yet the latent vector remains d-dimensional. We will add a short paragraph discussing why the log-concavity result is unaffected by parent-set growth under the stated positivity conditions, and we will include a brief additional simulation with larger parent sets to confirm that posterior shrinkage remains effective even when counts are extremely sparse. revision: yes
Circularity Check
No significant circularity: hierarchical prior and MALA-Gibbs sampler rely on standard Bayesian modeling and MCMC techniques
full rationale
The paper proposes a hierarchical Dirichlet model for conditional probability tables that shrinks toward low-dimensional latent parameters, then samples the posterior via MALA embedded in a Gibbs sampler while verifying log-concavity of the full conditional under mild conditions. These steps are presented as direct applications of existing Bayesian hierarchical modeling and Langevin dynamics; no equation reduces a claimed prediction or uniqueness result to a fitted parameter or prior self-definition by construction. The structure-learning algorithms are described as preserving the DAG property via standard topological constraints. No load-bearing self-citation chain or ansatz smuggling is evident in the provided derivation outline. The central claims therefore remain independent of the inputs they are meant to explain.
Axiom & Free-Parameter Ledger
free parameters (1)
- Dirichlet concentration hyperparameters
axioms (1)
- domain assumption Full conditional distributions are log-concave under mild conditions
invented entities (1)
-
low-dimensional latent parameters
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2. ... h_{j,xj}(t) is log-concave in t ... if ρ_j ≥ k_j and n_j(x_j) > 0. ... d² log h / dt² = (1 - ρ_j/k_j)/t² + ∑ ... (ψ¹(n_{Pap(j),j}(x_{Pap(j)},x_j) + t) - ψ¹(t))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a hierarchical model for node-parent conditional probabilities, inducing shrinkage to low-dimensional latent parameters a posteriori.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Agresti, A. (2002). Categorical Data Analysis . John Wiley & Sons, Incorporated
work page 2002
-
[2]
Alam, M. H., J. Peltonen, J. Nummenmaa, and K. J \"a rvelin (2019). Tree-structured hierarchical D irichlet process. In Distributed Computing and Artificial Intelligence, Special Sessions, 15th International Conference , pp.\ 291--299. Springer International Publishing
work page 2019
-
[3]
Atchad \'e , Y. F. (2006). An adaptive version for the M etropolis adjusted L angevin algorithm with a truncated drift. Methodology and Computing in Applied Probability\/ 8\/ (2), 235--254
work page 2006
-
[4]
Azzimonti, L., G. Corani, and M. Scutari (2022). A B ayesian hierarchical score for structure learning from related data sets. International Journal of Approximate Reasoning\/ 142 , 248--265
work page 2022
-
[5]
Azzimonti, L., G. Corani, and M. Zaffalon (2017). Hierarchical multinomial- D irichlet model for the estimation of conditional probability tables. In 2017 IEEE International Conference on Data Mining (ICDM) , pp.\ 739--744
work page 2017
-
[6]
Azzimonti, L., G. Corani, and M. Zaffalon (2019). Hierarchical estimation of parameters in B ayesian networks. Computational Statistics & Data Analysis\/ 137 , 67--91
work page 2019
-
[7]
Barbieri, M. M. and J. O. Berger (2004). Optimal predictive model selection . The Annals of Statistics\/ 32\/ (3), 870 -- 897
work page 2004
-
[8]
Beinlich, I. A., H. J. Suermondt, R. M. Chavez, and G. F. Cooper (1989). The ALARM monitoring system: A case study with two probabilistic inference techniques for belief networks. In J. Hunter, J. Cookson, and J. Wyatt (Eds.), AIME 89 , Berlin, Heidelberg, pp.\ 247--256. Springer Berlin Heidelberg
work page 1989
-
[9]
Berger, J. O. (1985). Statistical Decision Theory and Bayesian Analysis . Springer Science & Business Media
work page 1985
-
[10]
Bernardo, J. M. and A. F. Smith (1994). Bayesian Theory . John Wiley & Sons
work page 1994
-
[11]
Biron-Lattes, M., N. Surjanovic, S. Syed, T. Campbell, and A. Bouchard-Cote (2024, 02--04 May). autoMALA : Locally adaptive M etropolis-adjusted L angevin algorithm. In S. Dasgupta, S. Mandt, and Y. Li (Eds.), Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , Volume 238 of Proceedings of Machine Learning Research...
work page 2024
-
[12]
Bishop, C. M. (2006). Pattern Recognition and Machine Learning . Springer
work page 2006
-
[13]
Blei, D. M., A. Y. Ng, and M. I. Jordan (2003). Latent D irichlet allocation. Journal of Machine Learning Research\/ 3 , 993--–1022
work page 2003
-
[14]
Castelletti, F. and S. Peluso (2021). Equivalence class selection of categorical graphical models. Computational Statistics & Data Analysis\/ 164 , 107304
work page 2021
-
[15]
Catal\'an Cerezo, D. (2023). Parametric learning of probabilistic graphical models from multi-sourced data. Master's thesis, Universitat de Barcelona
work page 2023
- [16]
-
[17]
Chakrabarti, A., Y. Ni, E. R. A. Morris, M. L. Salinas, R. S. Chapkin, and B. K. Mallick (2024). Graphical D irichlet process for clustering non-exchangeable grouped data. Journal of Machine Learning Research\/ 25\/ (323), 1--56
work page 2024
-
[18]
Chen, S. X. and J. S. Liu (1997). Statistical applications of the P oisson-binomial and conditional B ernoulli distributions. Statistica Sinica\/ 7\/ (4), 875--892
work page 1997
-
[19]
Chen, Y. and X. Ye (2011). Projection onto a simplex. arXiv preprint arXiv:1101.6081\/
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[20]
Das, S., Y. Niu, Y. Ni, B. K. Mallick, and D. Pati (2024). Blocked G ibbs sampler for hierarchical D irichlet processes. Journal of Computational and Graphical Statistics\/ In Press
work page 2024
-
[21]
Dawid, A. P. and S. L. Lauritzen (1993). Hyper markov laws in the statistical analysis of decomposable graphical models. The Annals of Statistics\/ 21\/ (3), 1272--1317
work page 1993
-
[22]
Dwivedi, R., Y. Chen, M. J. Wainwright, and B. Yu (2019). Log-concave sampling: M etropolis- H astings algorithms are fast. Journal of Machine Learning Research\/ 20\/ (183), 1--42
work page 2019
-
[23]
Friedman, N. (1998). The B ayesian structural EM algorithm. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence , UAI'98, pp.\ 129–--138. Morgan Kaufmann Publishers Inc
work page 1998
-
[24]
Gelman, A., J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, and D. B. Rubin (2013). Bayesian Data Analysis . Chapman and Hall/CRC
work page 2013
- [25]
-
[26]
Gu, Y. and D. B. Dunson (2023). Bayesian pyramids: identifiable multilayer discrete latent structure models for discrete data. Journal of the Royal Statistical Society Series B: Statistical Methodology\/ 85\/ (2), 399--426
work page 2023
-
[27]
Hashim, D., P. Boffetta, C. La Vecchia, M. Rota, P. Bertuccio, M. Malvezzi, and E. Negri (2016). The global decrease in cancer mortality: trends and disparities. Annals of Oncology\/ 27\/ (5), 926--933
work page 2016
-
[28]
Hausser, J. and K. Strimmer (2009). Entropy inference and the J ames- S tein estimator, with application to nonlinear gene association networks. Journal of Machine Learning Research\/ 10 , 1469–--1484
work page 2009
-
[29]
Heckerman, D., D. Geiger, and D. M. Chickering (1995). Learning B ayesian networks: The combination of knowledge and statistical data. Machine Learning\/ 20\/ (3), 197--243
work page 1995
-
[30]
Hoffman, M. D., A. Gelman, et al. (2014). The N o- U - T urn sampler: adaptively setting path lengths in H amiltonian M onte C arlo. Journal of Machine Learning Research\/ 15\/ (1), 1593--1623
work page 2014
-
[31]
Kass, R. E. and A. E. Raftery (1995). Bayes factors. Journal of the American Statistical Association\/ 90\/ (430), 773--795
work page 1995
-
[32]
Kitson, N. K., A. C. Constantinou, Z. Guo, Y. Liu, and K. Chobtham (2023). A survey of B ayesian network structure learning. Artificial Intelligence Review\/ 56\/ (8), 8721--8814
work page 2023
-
[33]
Kong, L., G. Chen, B. Huang, E. Xing, Y. Chi, and K. Zhang (2024). Learning discrete concepts in latent hierarchical models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Advances in Neural Information Processing Systems , Volume 37, pp.\ 36938--36975. Curran Associates, Inc
work page 2024
- [34]
- [35]
-
[36]
Lin, Z., Y. Wang, and Y. Hong (2022). The P oisson multinomial distribution and its applications in voting theory, ecological inference, and machine learning. arXiv preprint arXiv:2201.04237\/
-
[37]
Lindley, D. V. (1964). The B ayesian analysis of contingency tables. The Annals of Mathematical Statistics\/ 35\/ (4), 1622--1643
work page 1964
-
[38]
Lucas, P. J., L. C. van der Gaag , and A. Abu-Hanna (2004). Bayesian networks in biomedicine and health-care. Artificial Intelligence in Medicine\/ 30\/ (3), 201--214. Bayesian Networks in Biomedicine and Health-Care
work page 2004
-
[39]
Marshall, T. and G. Roberts (2012). An adaptive approach to L angevin MCMC . Statistics and Computing\/ 22 , 1041--1057
work page 2012
-
[40]
Meinshausen, N. and P. B \"u hlmann (2006). High-dimensional graphs and variable selection with the Lasso . The Annals of Statistics\/ 34\/ (3), 1436--1462
work page 2006
-
[41]
Nolan, E., G. J. Lindeman, and J. E. Visvader (2023). Deciphering breast cancer: from biology to the clinic. Cell\/ 186\/ (8), 1708--1728
work page 2023
-
[42]
Pearl, J. (1985). Bayesian networks: A model of self-activated memory for evidential reasoning. In Proceedings of the 7th conference of the Cognitive Science Society, University of California, Irvine, CA, USA , pp.\ 15--17
work page 1985
-
[43]
Pearl, J. (1988). Probabilistic reasoning in intelligent systems: networks of plausible inference . Morgan Kaufmann
work page 1988
-
[44]
Pearl, J. (2009). Causality: Models, Reasoning, and Inference . Cambridge University Press
work page 2009
-
[45]
Pereira, B., S.-F. Chin, O. M. Rueda, H.-K. M. Vollan, E. Provenzano, H. A. Bardwell, M. Pugh, L. Jones, R. Russell, S.-J. Sammut, et al. (2016). The somatic mutation profiles of 2,433 breast cancers refine their genomic and transcriptomic landscapes. Nature Communications\/ 7\/ (1), 11479
work page 2016
-
[46]
Perotte, A., F. Wood, N. Elhadad, and N. Bartlett (2011). Hierarchically supervised latent D irichlet allocation. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Weinberger (Eds.), Advances in Neural Information Processing Systems , Volume 24. Curran Associates, Inc
work page 2011
-
[47]
Petitjean, F., W. Buntine, G. I. Webb, and N. Zaidi (2018). Accurate parameter estimation for B ayesian network classifiers using hierarchical D irichlet processes. Machine Learning\/ 107\/ (8), 1303--1331
work page 2018
-
[48]
Rijmen, F. (2008). Bayesian networks with a logistic regression model for the conditional probabilities. International Journal of Approximate Reasoning\/ 48\/ (2), 659--666
work page 2008
-
[49]
Roberts, G. O. and J. S. Rosenthal (1998). Optimal scaling of discrete approximations to L angevin diffusions. Journal of the Royal Statistical Society: Series B (Statistical Methodology)\/ 60\/ (1), 255--268
work page 1998
-
[50]
Ronning, G. (1989). Maximum likelihood estimation of D irichlet distributions. Journal of statistical computation and simulation\/ 34\/ (4), 215--221
work page 1989
-
[51]
Scutari, M. (2010). Learning B ayesian networks with the bnlearn R package. Journal of Statistical Software\/ 35\/ (3), 1--22
work page 2010
- [52]
- [53]
- [54]
-
[55]
Trayes, K. P. and S. E. Cokenakes (2021). Breast cancer treatment. American Family Physician\/ 104\/ (2), 171--178
work page 2021
-
[56]
Wood, S. N. (2011). Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. Journal of the Royal Statistical Society: Series B\/ 73\/ (1), 3--36
work page 2011
-
[57]
Zhang, H., F. Petitjean, and W. Buntine (2020). Bayesian network classifiers using ensembles and smoothing. Knowledge and Information Systems\/ 62 , 3457--3480
work page 2020
-
[58]
Zhang, J., Y. Song, C. Zhang, and S. Liu (2010). Evolutionary hierarchical D irichlet processes for multiple correlated time-varying corpora. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data mining , pp.\ 1079--1088
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.