Bayesian Mixture Models for Heterogeneous Extremes
Pith reviewed 2026-05-18 15:25 UTC · model grok-4.3
The pith
A Dirichlet process mixture of GEV distributions models heterogeneous block maxima while aligning with the extremal types theorem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
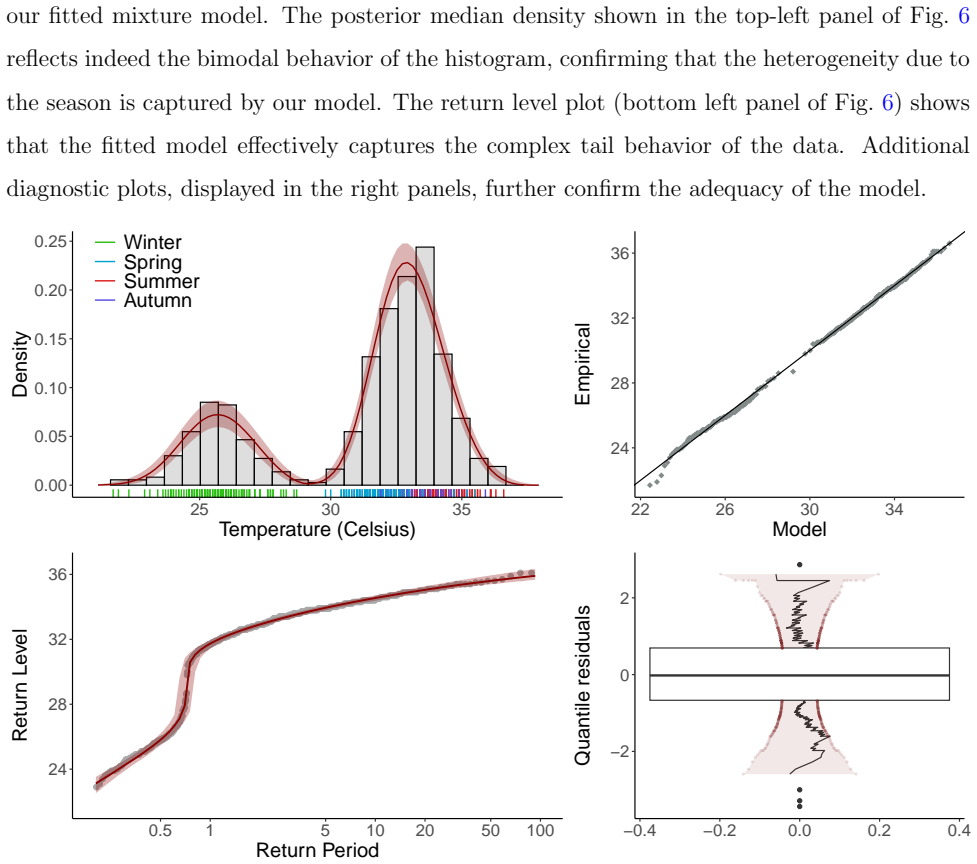
The paper establishes a mixture model for block maxima that has a Bayesian nonparametric interpretation as a Dirichlet process mixture of GEV distributions. By using an infinite number of components, it characterizes every possible block behavior and captures similarities between observations according to their extremal behavior, without needing to pre-specify the number of mixture components.
What carries the argument
Dirichlet process mixture of GEV distributions, which places a prior on the mixing measure to allow the data to determine the effective number of components for modeling heterogeneous extremes.
If this is right
- The model remains consistent with the extremal types theorem.
- It captures complex structures in extreme data without pre-specifying the number of components.
- Similarities between observations are captured based on extremal behavior.
- The approach applies directly to both simulated and real-world data.
Where Pith is reading between the lines
- If the approach works, standard single-component GEV fits in many fields may need checking for latent heterogeneity.
- Comparable nonparametric mixtures could be developed for other extreme value limit laws.
- The model might be extended by adding covariates that help explain why blocks fall into different groups.
Load-bearing premise
That alternative block maxima-based models can be constructed to align with the extremal types theorem while allowing the mixture to represent heterogeneous groups effectively.
What would settle it
A simulation study where data is generated from a single GEV distribution and the fitted model is checked to see if it selects only one component with high posterior probability.
Figures





read the original abstract
The conventional use of the Generalized Extreme Value (GEV) distribution to model block maxima may be inappropriate when extremes are actually structured into multiple heterogeneous groups. In this work, we propose a novel approach for describing the behavior of extreme values in the presence of such heterogeneity. Rather than defaulting to the GEV distribution simply because it arises as a theoretical limit, we show that alternative block maxima-based models can also align with the extremal types theorem while providing improved flexibility in practice. Our formulation leads us to a mixture model that has a Bayesian nonparametric interpretation as a Dirichlet process mixture of GEV distributions. The use of an infinite number of components enables the characterization of every possible block behavior, while at the same time capturing similarities between observations based on their extremal behavior. By employing a Dirichlet process prior on the mixing measure, we can capture the complex structure of the data without the need to pre-specify the number of mixture components. The application of the proposed model is illustrated using both simulated and real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Dirichlet process mixture of GEV distributions as a model for block maxima under heterogeneity. It claims that this formulation aligns with the extremal types theorem while offering greater flexibility than a single GEV, interprets the model as a Bayesian nonparametric extension that captures all possible block behaviors via infinitely many components, and illustrates the approach on simulated and real data.
Significance. If the claimed alignment with the extremal types theorem can be rigorously established, the work would provide a flexible nonparametric Bayesian framework for modeling heterogeneous extremes without pre-specifying the number of components. The use of a Dirichlet process prior and the demonstration on both simulated and real data are positive features that could support broader adoption in extreme value applications.
major comments (1)
- [Abstract / theoretical development] Abstract and the theoretical development section: the central claim that the proposed mixture 'aligns with the extremal types theorem while providing improved flexibility' is load-bearing but unsupported by an explicit derivation. The Fisher-Tippett-Gnedenko theorem requires any non-degenerate limiting distribution of normalized block maxima to be a member of the GEV family; a non-degenerate mixture of GEVs is generally not itself GEV (e.g., it can exhibit multimodality or tail behavior outside any single GEV). No argument is given showing how heterogeneity in the underlying process produces a mixture as the limiting law rather than a single GEV.
minor comments (1)
- [Simulation study] The simulation study would benefit from an explicit statement of the data-generating process and the precise criteria used to assess recovery of heterogeneous structure.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight the need for greater clarity in the theoretical justification. We address the major comment below and will revise the manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: Abstract and the theoretical development section: the central claim that the proposed mixture 'aligns with the extremal types theorem while providing improved flexibility' is load-bearing but unsupported by an explicit derivation. The Fisher-Tippett-Gnedenko theorem requires any non-degenerate limiting distribution of normalized block maxima to be a member of the GEV family; a non-degenerate mixture of GEVs is generally not itself GEV (e.g., it can exhibit multimodality or tail behavior outside any single GEV). No argument is given showing how heterogeneity in the underlying process produces a mixture as the limiting law rather than a single GEV.
Authors: We agree that the original manuscript lacks an explicit derivation and will revise the theoretical development section accordingly. When block maxima arise from heterogeneous processes (latent groups with distinct normalization constants or domains of attraction), the Fisher-Tippett-Gnedenko theorem applies conditionally on each group, yielding a GEV limit for that block. The unconditional distribution of observed maxima is then a mixture of GEVs. This formulation aligns with the theorem by extending it to heterogeneous settings, where a single GEV would be misspecified. The mixture's potential multimodality or varied tail behavior is a deliberate feature for capturing distinct extreme regimes rather than a violation. We will add this argument and clarify the distinction between conditional and unconditional limits. revision: yes
Circularity Check
No circularity: new modeling framework with independent content
full rationale
The paper introduces a Dirichlet process mixture of GEV distributions as a Bayesian nonparametric approach for heterogeneous block maxima. The central formulation is presented as a modeling choice that extends beyond the single GEV while claiming alignment with the extremal types theorem, without any derivation steps that reduce by the paper's own equations to quantities already fitted from the target data or to self-citations. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided derivation chain; the proposal remains self-contained as an alternative modeling framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Alternative block maxima-based models align with the extremal types theorem.
Forward citations
Cited by 1 Pith paper
-
How long should a block be?
Excessively long blocks lower asymptotic relative efficiency in the block-maxima method, and new likelihood and diagnostic procedures are proposed to check whether a chosen length is adequate under rounding or censoring.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION format.url url empty "" url if FUNCTION article output.bibitem format.authors "author" output.check author format.key output output.year.check new.block format.title "title" output.check new.block crossref missing format.jour.vol output format.article.crossref output.nonnull format.pages output if ne...
-
[2]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 '...
-
[3]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in " " * FUNCTION format....
-
[4]
write newline invisible empty 'skip invisible write newline if
" write newline invisible empty 'skip invisible write newline if "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTION or pop #1 'skip if FUNCTION new.block.checkb empty swap empty and 'skip 'new.block if FUNCTION field.or.null duplicate empty pop "" 'skip if FUNCTION emphasi...
-
[5]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 '...
-
[6]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[7]
" write newline "" before.all 'output.state := FUNCTION article output.bibitem format.authors "author" output.check author format.key output output.year.check new.block format.title "title" output.check new.block crossref missing format.jour.vol output format.article.crossref output.nonnull format.pages output if new.block note output fin.entry FUNCTION b...
- [8]
-
[9]
(2004), Statistics of Extremes : Theory and Applications , Hoboken, NJ: Wiley
Beirlant, J., Goegebeur, Y., Segers, J., and Teugels, J. (2004), Statistics of Extremes : Theory and Applications , Hoboken, NJ: Wiley
work page 2004
-
[10]
Boldi, M.-O. and Davison, A. C. (2007), A mixture model for multivariate extremes, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 69, 217--229
work page 2007
-
[11]
Cabras, S. and Castellanos, M. E. (2011), A Bayesian approach for estimating extreme quantiles under a semiparametric mixture model, ASTIN Bulletin: The Journal of the IAA, 41, 87--106
work page 2011
-
[12]
(2001), An Introduction to Statistical Modeling of Extreme Values , London: Springer
Coles, S. (2001), An Introduction to Statistical Modeling of Extreme Values , London: Springer
work page 2001
-
[13]
(2025), DATAstudio: The Research Data Warehouse of Miguel de Carvalho, R package version 1.2.1
de Carvalho , M. (2025), DATAstudio: The Research Data Warehouse of Miguel de Carvalho, R package version 1.2.1
work page 2025
-
[14]
de Carvalho , M., Huser, R., Naveau, P., and Reich, B. J. (2026), Handbook on Statistics of Extremes, Boca Raton, FL: Chapman & Hall/CRC
work page 2026
-
[15]
de Carvalho , M. and Ramirez, K. P. (2025), Semiparametric Bayesian modeling of nonstationary joint extremes: how do big tech's extreme losses behave? Journal of the Royal Statistical Society, Ser. C, 74, 447--465
work page 2025
-
[16]
Dunn, P. K. and Smyth, G. K. (1996), Randomized quantile residuals, Journal of Computational and Graphical Statistics, 5, 236--244
work page 1996
-
[17]
Dunson, D. B. (2010), Nonparametric B ayes applications to biostatistics. In B ayesian N onparametrics, ( N . L . H jort et al., eds.), pp. 223--273, C ambridge U niversity P ress, C ambridge UK
work page 2010
-
[18]
(2013), Modelling Extremal Events: For Insurance and Finance, New York: Springer
Embrechts, P., Kl \"u ppelberg, C., and Mikosch, T. (2013), Modelling Extremal Events: For Insurance and Finance, New York: Springer
work page 2013
-
[19]
Escobar, M. D. and West, M. (1995), Bayesian density estimation and inference using mixtures, Journal of the American Statistical Association, 90, 577--588
work page 1995
-
[20]
Ferguson, T. S. (1973), Bayesian analysis of some nonparametric problems, The Annals of Statistics, 209--230
work page 1973
-
[21]
--- (1974), Prior distributions on spaces of probability measures, The Annals of Statistics, 615--629
work page 1974
-
[22]
Gallego, M., Trigo, R., Vaquero, J., Brunet, M., Garc \' a, J., Sigr \'o , J., and Valente, M. (2011), Trends in frequency indices of daily precipitation over the I berian P eninsula during the last century, Journal of Geophysical Research: Atmospheres, 116
work page 2011
-
[23]
Guillotte, S. and Perron, F. (2016), Polynomial Pickands functions, Bernoulli, 22, 213--241
work page 2016
-
[24]
Guillotte, S., Perron, F., and Segers, J. (2011), Non-parametric Bayesian inference on bivariate extremes, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 73, 377--406
work page 2011
-
[25]
E., de Carvalho , M., and Chen, Y
Hanson, T. E., de Carvalho , M., and Chen, Y. (2017), Bernstein polynomial angular densities of multivariate extreme value distributions, Statistics and Probability Letters, 128, 60--66
work page 2017
-
[26]
Hazra, A. and Huser, R. (2021), Estimating high-resolution Red Sea surface temperature hotspots, using a low-rank semiparametric spatial model, The Annals of Applied Statistics, 15, 572--596
work page 2021
-
[27]
In \'a cio de Carvalho , V., de Carvalho , M., and Branscum, A. J. (2017), Nonparametric Bayesian regression analysis of the Youden index, Biometrics, 73, 1279--1288
work page 2017
-
[28]
Ishwaran, H. and James, L. F. (2001), Gibbs sampling methods for stick-breaking priors, Journal of the American Statistical Association, 96, 161--173
work page 2001
-
[29]
--- (2002), Approximate Dirichlet process computing in finite normal mixtures : smoothing and prior information , Journal of Computational and Graphical Statistics, 11, 508--532
work page 2002
-
[30]
Kalli, M., Griffin, J. E., and Walker, S. G. (2011), Slice sampling mixture models, Statistics and Computing, 21, 93--105
work page 2011
-
[31]
Lugrin, T., Davison, A. C., and Tawn, J. A. (2016), Bayesian uncertainty management in temporal dependence of extremes, Extremes, 19, 491--515
work page 2016
-
[32]
MacDonald, A., Scarrott, C., Lee, D., Darlow, B., Reale, M., and Russell, G. (2011), A flexible extreme value mixture model, Computational Statistics & Data Analysis, 55, 2137--2157
work page 2011
-
[33]
A., and Antoniano-Villalobos, I
Marcon, G., Padoan, S. A., and Antoniano-Villalobos, I. (2016), Bayesian inference for the extremal dependence, Electronic Journal of Statistics, 10, 3310--3337
work page 2016
-
[34]
Otiniano, C., Gon c alves, C., and Dorea, C. (2017), Mixture of extreme-value distributions: identifiability and estimation, Communications in Statistics---Theory and Methods, 46, 6528--6542
work page 2017
-
[35]
Otiniano, C. E., Paiva, B. S., Vila, R., and Bourguignon, M. (2023), A bimodal model for extremes data, Environmental and Ecological Statistics, 30, 261--288
work page 2023
-
[36]
A., M \"u ller, P., Jara, A., and MacEachern, S
Quintana, F. A., M \"u ller, P., Jara, A., and MacEachern, S. N. (2022), The dependent D irichlet process and related models, Statistical Science, 37, 24--41
work page 2022
-
[37]
P., de Carvalho , M., and Gutierrez, L
Ramirez, V. P., de Carvalho , M., and Gutierrez, L. (2025, to appear), Heavy-tailed NGG -mixture models, Bayesian Analysis
work page 2025
-
[38]
Reich, B. J. and Ghosh, S. K. (2019), Bayesian Statistical Methods, Boca Raton, FL: Chapman and Hall/CRC
work page 2019
-
[39]
Richards, J., Tawn, J. A., and Brown, S. (2023), Joint estimation of extreme spatially aggregated precipitation at different scales through mixture modelling, Spatial Statistics, 53, 100725
work page 2023
-
[40]
Rodu, J. and Kafadar, K. (2022), The q--q Boxplot, Journal of Computational and Graphical Statistics, 31, 26--39
work page 2022
-
[41]
(1994), A constructive definition of Dirichlet priors, Statistica Sinica, 639--650
Sethuraman, J. (1994), A constructive definition of Dirichlet priors, Statistica Sinica, 639--650
work page 1994
-
[42]
Stephenson, A. G. (2002), evd : Extreme value distributions, R News, 2, 31--32
work page 2002
-
[43]
(1910), Introduction \`a la Th \'e orie des Fonctions d'une Variable , vol
Tannery, J. (1910), Introduction \`a la Th \'e orie des Fonctions d'une Variable , vol. 1, A. Hermann
work page 1910
-
[44]
Tendijck, S., Eastoe, E., Tawn, J., Randell, D., and Jonathan, P. (2023), Modeling the extremes of bivariate mixture distributions with application to oceanographic data, Journal of the American Statistical Association, 118, 1373--1384
work page 2023
-
[45]
A., Trigo, R., Barros, M., Nunes, L
Valente, M. A., Trigo, R., Barros, M., Nunes, L. F., Alves, E., Pinhal, E., Coelho, F., Mendes, M., and Miranda, J. (2008), Early stages of the recovery of Portuguese historical meteorological data, in MEDARE-Proceedings of the International Workshop on Rescue and Digitization of Climate Records in the Mediterranean Basin, WCDMP, no. 67, pp. 95--102
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.