Interpreting the Role of Visemes in Audio-Visual Speech Recognition
Pith reviewed 2026-05-18 15:46 UTC · model grok-4.3
The pith
Visual cues drive natural clustering of speech features in AVSR models, with audio refining representations for ambiguous visemes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
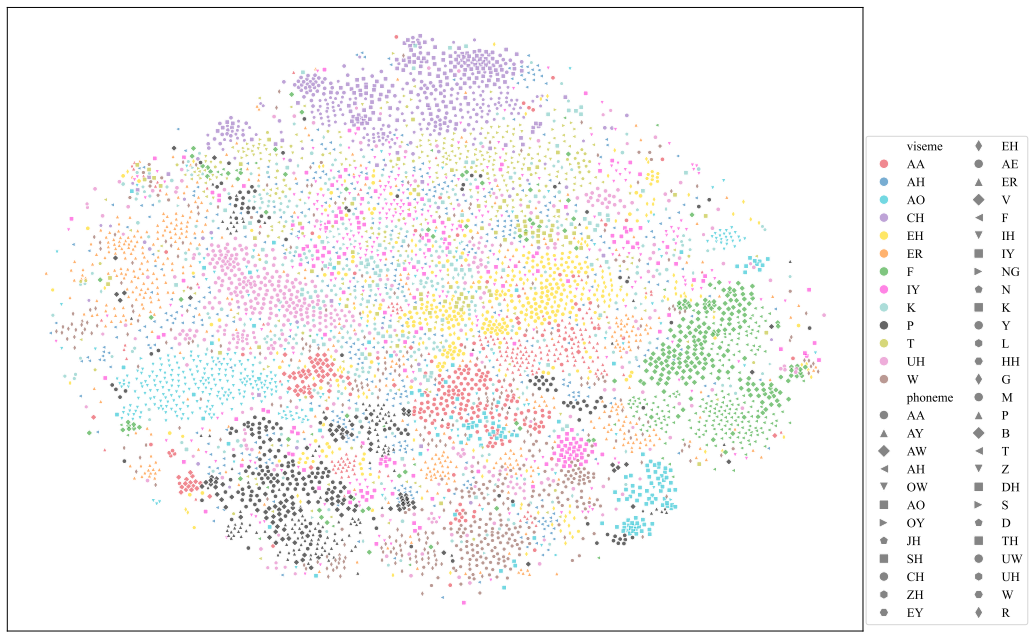
t-SNE visualizations of AV-HuBERT features reveal natural clustering driven by visual cues, which is further refined by the presence of audio. Probing shows that audio contributes to refining feature representations particularly for visemes that are visually ambiguous or under-represented.
What carries the argument
t-SNE embeddings combined with linear probing classifiers applied to AV-HuBERT multimodal features to separate visual-driven clustering from audio-driven refinement of viseme representations.
If this is right
- The visual modality supplies the dominant initial structure for grouping speech units inside the model.
- Audio input acts mainly as a disambiguator for visemes that share similar lip shapes or are rare in the data.
- AVSR performance gains arise from this staged division of labor rather than uniform fusion of the two streams.
- Targeted improvements to visual feature quality could strengthen the primary clusters before audio is added.
Where Pith is reading between the lines
- The same visual-first pattern may appear in other multimodal speech models and could be tested by applying identical visualizations across architectures.
- Training regimes that emphasize visual examples of ambiguous visemes might reduce reliance on audio and improve robustness in noisy conditions.
- The findings suggest possible parallels with human speech perception, where lip reading provides coarse categories that sound resolves.
- Lip-reading systems could adopt similar staged clustering to handle cases where visual input alone is insufficient.
Load-bearing premise
t-SNE visualizations and linear probes accurately expose the separate causal roles of visual and audio inputs without major distortion from the reduction method or the probe architecture.
What would settle it
If AV-HuBERT features extracted from audio-only or visual-only inputs produce t-SNE clusters and probe accuracies that match the full audio-visual case for ambiguous visemes, the claim that audio provides specific refinement would not hold.
Figures




read the original abstract
Audio-Visual Speech Recognition (AVSR) models have surpassed their audio-only counterparts in terms of performance. However, the interpretability of AVSR systems, particularly the role of the visual modality, remains under-explored. In this paper, we apply several interpretability techniques to examine how visemes are encoded in AV-HuBERT a state-of-the-art AVSR model. First, we use t-distributed Stochastic Neighbour Embedding (t-SNE) to visualize learned features, revealing natural clustering driven by visual cues, which is further refined by the presence of audio. Then, we employ probing to show how audio contributes to refining feature representations, particularly for visemes that are visually ambiguous or under-represented. Our findings shed light on the interplay between modalities in AVSR and could point to new strategies for leveraging visual information to improve AVSR performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies interpretability methods to the AV-HuBERT audio-visual speech recognition model to examine viseme encoding. It reports that t-SNE visualizations of learned features exhibit natural clustering driven primarily by visual cues, with audio input providing further refinement, and that linear probing indicates audio contributes to disambiguating representations for visually ambiguous or under-represented visemes.
Significance. If the methodological concerns are addressed, the work offers useful observations on modality contributions in a leading AVSR model and grounds the analysis in the linguistically relevant unit of visemes. This could inform targeted improvements in visual leverage for AVSR. The application of standard tools (t-SNE and probing) to an existing high-performing model is a positive aspect, though the observational nature and lack of quantitative validation limit the strength of the causal interpretations.
major comments (2)
- [§4] §4 (t-SNE visualizations): The central claim that visualizations reveal 'natural clustering driven by visual cues, which is further refined by the presence of audio' lacks supporting quantitative metrics such as adjusted Rand index or normalized mutual information against viseme labels, and no robustness checks (multiple perplexity values, UMAP comparison, or audio-ablated embeddings) are reported. This is load-bearing for the interpretation because t-SNE is known to produce spurious clusters sensitive to hyperparameters and initialization.
- [§5] §5 (probing experiments): The conclusion that 'audio contributes to refining feature representations particularly for visemes that are visually ambiguous or under-represented' relies on linear probes without reported controls for probe architecture (e.g., comparison to non-linear probes or random baselines), modality ablations, or statistical significance testing across viseme classes. This weakens the specific attribution of refinement effects to audio.
minor comments (2)
- [Abstract] The abstract states that 'several interpretability techniques' are applied but only describes t-SNE and probing in detail; clarify whether additional methods were used and their results.
- [Figures] Figure captions for t-SNE plots should explicitly state the color mapping (e.g., by viseme class or modality condition) and any preprocessing steps such as feature normalization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments correctly identify opportunities to strengthen the quantitative support for our interpretability claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§4] §4 (t-SNE visualizations): The central claim that visualizations reveal 'natural clustering driven by visual cues, which is further refined by the presence of audio' lacks supporting quantitative metrics such as adjusted Rand index or normalized mutual information against viseme labels, and no robustness checks (multiple perplexity values, UMAP comparison, or audio-ablated embeddings) are reported. This is load-bearing for the interpretation because t-SNE is known to produce spurious clusters sensitive to hyperparameters and initialization.
Authors: We agree that t-SNE is a qualitative tool and that quantitative validation plus robustness checks would make the clustering claims more robust. In the revised manuscript we will add adjusted Rand index and normalized mutual information scores computed between the t-SNE-derived clusters and the ground-truth viseme labels. We will also report results across a range of perplexity values and include a side-by-side UMAP comparison. To directly demonstrate the refinement effect of audio, we will include t-SNE visualizations of the visual-only branch embeddings (i.e., audio-ablated) alongside the full audio-visual embeddings. These additions address the risk of spurious clusters while preserving the observational nature of the analysis. revision: yes
-
Referee: [§5] §5 (probing experiments): The conclusion that 'audio contributes to refining feature representations particularly for visemes that are visually ambiguous or under-represented' relies on linear probes without reported controls for probe architecture (e.g., comparison to non-linear probes or random baselines), modality ablations, or statistical significance testing across viseme classes. This weakens the specific attribution of refinement effects to audio.
Authors: We acknowledge that additional controls would improve the rigor of the probing results. In revision we will report probe accuracies for both linear and non-linear (single-hidden-layer MLP) architectures, together with a random-feature baseline. We will also add explicit modality ablations by including audio-only probing results and will perform statistical significance testing (bootstrap resampling across multiple random seeds) to quantify the improvement for visually ambiguous and under-represented visemes. These controls will be presented in an expanded §5 while retaining the focus on linear probes for interpretability. revision: yes
Circularity Check
No circularity: purely observational analysis of pre-trained model features
full rationale
The paper applies standard interpretability methods (t-SNE visualization and linear probing) to features extracted from the existing AV-HuBERT model. No derivation chain, first-principles predictions, fitted parameters, or self-referential equations are present. Claims rest on direct application of these techniques to model outputs without any reduction of results to the analysis inputs by construction or via self-citation load-bearing steps. The work is self-contained as empirical observation rather than a closed predictive loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption t-SNE and probing classifiers can be used to infer causal contributions of input modalities to internal representations
Reference graph
Works this paper leans on
-
[1]
Learning audio- visual speech representation by masked multimodal cluster prediction,
B. Shi, W.-N. Hsu, K. Lakhotia, and A. Mohamed, “Learning audio- visual speech representation by masked multimodal cluster prediction,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[2]
Auto-A VSR: Audio-visual speech recognition with auto- matic labels,
P. Ma, A. Haliassos, A. Fernandez-Lopez, H. Chen, S. Petridis, and M. Pantic, “Auto-A VSR: Audio-visual speech recognition with auto- matic labels,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, p. 1–5
work page 2023
-
[3]
A. Rouditchenko, Y . Gong, S. Thomas, L. Karlinsky, H. Kuehne, R. Feris, and J. Glass, “Whisper-Flamingo: Integrating visual features into whisper for audio-visual speech recognition and translation,” in Interspeech 2024, 2024, pp. 2420–2424
work page 2024
-
[4]
H. Han, M. Anwar, J. Pino, W.-N. Hsu, M. Carpuat, B. Shi, and C. Wang, “XLA VS-R: Cross-lingual audio-visual speech representation learning for noise-robust speech perception,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024, pp. 12 896–12 911
work page 2024
-
[5]
Q. Zhu, L. Zhou, Z. Zhang, S. Liu, B. Jiao, J. Zhang, L. Dai, D. Jiang, J. Li, and F. Wei, “VatLM: Visual-audio-text pre-training with unified masked prediction for speech representation learning,”IEEE Transactions on Multimedia, vol. 26, p. 1055–1064, 2024
work page 2024
-
[6]
Jointly learning visual and auditory speech representations from raw data,
A. Haliassos, P. Ma, R. Mira, S. Petridis, and M. Pantic, “Jointly learning visual and auditory speech representations from raw data,” in The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[7]
J. Lian, A. Baevski, W.-N. Hsu, and M. Auli, “Av-data2vec: Self- supervised learning of audio-visual speech representations with con- textualized target representations,” in2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2023, pp. 1–8
work page 2023
-
[8]
Conformer: Convolution- augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution- augmented transformer for speech recognition,” inInterspeech 2020, 2020, pp. 5036–5040
work page 2020
-
[9]
wav2vec 2.0: a framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: a framework for self-supervised learning of speech representations,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020
work page 2020
-
[10]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 29, p. 3451–3460, 2021
work page 2021
-
[11]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 23–29 Jul 2023, pp. 28 492–28 518
work page 2023
-
[12]
Understanding self-attention of self-supervised audio transformers,
S. wen Yang, A. T. Liu, and H. yi Lee, “Understanding self-attention of self-supervised audio transformers,” inInterspeech 2020, 2020, pp. 3785–3789
work page 2020
-
[13]
Probing Acoustic Representations for Phonetic Properties,
D. Ma, N. Ryant, and M. Liberman, “Probing Acoustic Representations for Phonetic Properties,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Toronto, ON, Canada: IEEE, Jun. 2021, pp. 311–315
work page 2021
-
[14]
Layer-Wise Analysis of a Self- Supervised Speech Representation Model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-Wise Analysis of a Self- Supervised Speech Representation Model,” in2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). Cartagena, Colombia: IEEE, Dec. 2021, pp. 914–921
work page 2021
-
[15]
What do audio transformers hear? probing their representations for language delivery & structure,
Y . K. Singla, J. Shah, C. Chen, and R. R. Shah, “What do audio transformers hear? probing their representations for language delivery & structure,” in2022 IEEE International Conference on Data Mining Workshops (ICDMW), 2022, pp. 910–925
work page 2022
-
[16]
Domain- Informed Probing of wav2vec 2.0 Embeddings for Phonetic Features,
P. Cormac English, J. D. Kelleher, and J. Carson-Berndsen, “Domain- Informed Probing of wav2vec 2.0 Embeddings for Phonetic Features,” inProceedings of the 19th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology. Association for Computational Linguistics, 2022, pp. 83–91
work page 2022
-
[17]
Probing phoneme, language and speaker information in unsupervised speech representations,
M. de Seyssel, M. Lavechin, Y . Adi, E. Dupoux, and G. Wisniewski, “Probing phoneme, language and speaker information in unsupervised speech representations,” inInterspeech 2022, 2022, pp. 1402–1406
work page 2022
-
[18]
Understanding the role of self attention for efficient speech recognition,
K. Shim, J. Choi, and W. Sung, “Understanding the role of self attention for efficient speech recognition,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[19]
Discovering phonetic feature event patterns in transformer embeddings,
P. C. English, J. D. Kelleher, and J. Carson-Berndsen, “Discovering phonetic feature event patterns in transformer embeddings,” inINTER- SPEECH 2023, 2023, p. 4733–4737
work page 2023
-
[20]
Comparative Layer-Wise Analysis of Self-Supervised Speech Models,
A. Pasad, B. Shi, and K. Livescu, “Comparative Layer-Wise Analysis of Self-Supervised Speech Models,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
work page 2023
-
[21]
Self-supervised speech representations are more phonetic than semantic,
K. Choi, A. Pasad, T. Nakamura, S. Fukayama, K. Livescu, and S. Watanabe, “Self-supervised speech representations are more phonetic than semantic,” inInterspeech 2024, 2024, pp. 4578–4582
work page 2024
-
[22]
Probing speech quality information in asr systems,
B. T. Ta, M. T. Le, N. M. Le, and V . H. Do, “Probing speech quality information in asr systems,” inInterspeech 2023, 2023, pp. 541–545
work page 2023
-
[23]
Silence is sweeter than speech: Self-supervised model using silence to store speaker information,
C.-L. Feng, P. chun Hsu, and H. yi Lee, “Silence is sweeter than speech: Self-supervised model using silence to store speaker information,” 2022
work page 2022
-
[24]
What do self- supervised speech models know about words?
A. Pasad, C.-M. Chien, S. Settle, and K. Livescu, “What do self- supervised speech models know about words?”Transactions of the Association for Computational Linguistics, vol. 12, pp. 372–391, 2024
work page 2024
-
[25]
Understanding intermediate layers using linear classifier probes,
G. Alain and Y . Bengio, “Understanding intermediate layers using linear classifier probes,” inInternational Conference on Learning Representa- tions, 2017
work page 2017
-
[26]
Searching for structure: Appraising the organisation of speech features in wav2vec 2.0 embeddings,
P. C. English, J. D. Kelleher, and J. Carson-Berndsen, “Searching for structure: Appraising the organisation of speech features in wav2vec 2.0 embeddings,” inInterspeech 2024. ISCA, Sep. 2024, p. 4613–4617
work page 2024
-
[27]
L. van der Maaten and G. Hinton, “Visualizing data using t-sne,”Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008
work page 2008
-
[28]
Confusions among visually perceived consonants,
C. G. Fisher, “Confusions among visually perceived consonants,”Jour- nal of Speech and Hearing Research, vol. 11, no. 4, pp. 796–804, 1968
work page 1968
- [29]
-
[30]
Audio-to-visual conversion using hidden markov models,
S. Lee and D. Yook, “Audio-to-visual conversion using hidden markov models,” inPRICAI 2002: Trends in Artificial Intelligence. Berlin, Heidelberg: Springer, 2002, pp. 563–570
work page 2002
-
[31]
Decoding visemes: Improving machine lip- reading,
H. L. Bear and R. Harvey, “Decoding visemes: Improving machine lip- reading,” in2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 2009–2013
work page 2016
-
[32]
Comparison of phoneme and viseme based acoustic units for speech driven realistic lip animation,
E. Bozkurt, C. Erdem, E. Erzin, T. Erdem, and M. ¨Ozkan, “Comparison of phoneme and viseme based acoustic units for speech driven realistic lip animation,” in2007 IEEE 15th Signal Processing and Communica- tions Applications, 07 2007, pp. 1 – 4
work page 2007
-
[33]
Visual model structures and synchrony constraints for audio- visual speech recognition,
T. Hazen, “Visual model structures and synchrony constraints for audio- visual speech recognition,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 3, pp. 1082–1089, 2006
work page 2006
-
[34]
Phoneme-to-viseme mapping for visual speech recognition,
L. Cappelletta and N. Harte, “Phoneme-to-viseme mapping for visual speech recognition,” inInternational Conference on Pattern Recognition Applications and Methods, 2012
work page 2012
-
[35]
S. J. Oh, B. Schiele, and M. Fritz,Towards Reverse-Engineering Black- Box Neural Networks. Springer International Publishing, 2019, pp. 121–144
work page 2019
-
[36]
Combining residual networks with lstms for lipreading,
T. Stafylakis and G. Tzimiropoulos, “Combining residual networks with lstms for lipreading,” inInterspeech 2017, 2017, pp. 3652–3656
work page 2017
-
[37]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inProceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17, 2017, p. 6000–6010
work page 2017
-
[38]
LRS3-TED: a large-scale dataset for visual speech recognition
T. Afouras, J. S. Chung, and A. Zisserman, “LRS3-TED: a large-scale dataset for visual speech recognition,”CoRR, vol. abs/1809.00496, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Montreal forced aligner: Trainable text-speech alignment using kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal forced aligner: Trainable text-speech alignment using kaldi,” inInterspeech 2017, 2017, pp. 498–502
work page 2017
-
[40]
Prosodylab-aligner: A tool for forced alignment of laboratory speech,
K. Gorman, J. Howell, and M. Wagner, “Prosodylab-aligner: A tool for forced alignment of laboratory speech,”Canadian Acoustics, vol. 39, no. 3, pp. 192–193, 2011
work page 2011
-
[41]
MUSAN: A Music, Speech, and Noise Corpus
D. Snyder, G. Chen, and D. Povey, “MUSAN: A music, speech, and noise corpus,”CoRR, vol. abs/1510.08484, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
Robust self-supervised audio- visual speech recognition,
B. Shi, W.-N. Hsu, and A. Mohamed, “Robust self-supervised audio- visual speech recognition,” inInterspeech 2022, 2022, pp. 2118–2122
work page 2022
-
[43]
Learning lip-based audio-visual speaker embeddings with av-hubert,
B. Shi, A. Mohamed, and W.-N. Hsu, “Learning lip-based audio-visual speaker embeddings with av-hubert,” inInterspeech 2022, 2022, pp. 4785–4789
work page 2022
-
[44]
Uncovering the visual contribution in audio- visual speech recognition,
Z. Lin and N. Harte, “Uncovering the visual contribution in audio- visual speech recognition,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
work page 2025
-
[45]
M. Wattenberg, F. Vi ´egas, and I. Johnson, “How to use t-SNE effectively,”Distill, 2016. [Online]. Available: http://distill.pub/2016/ misread-tsne
work page 2016
-
[46]
S. Raschka, J. Patterson, and C. Nolet, “Machine learning in python: Main developments and technology trends in data science, machine learning, and artificial intelligence,”Information, vol. 11, no. 4, 2020
work page 2020
-
[47]
L. van der Maaten, “Barnes-Hut-SNE,” inInternational Conference on Learning Representations, 2013
work page 2013
-
[48]
On the surprising behavior of distance metrics in high dimensional space,
C. C. Aggarwal, A. Hinneburg, and D. A. Keim, “On the surprising behavior of distance metrics in high dimensional space,” inDatabase Theory — ICDT 2001. Springer Berlin Heidelberg, 2001, pp. 420–434
work page 2001
-
[49]
Neighborhood preservation in nonlinear projec- tion methods: An experimental study,
J. Venna and S. Kaski, “Neighborhood preservation in nonlinear projec- tion methods: An experimental study,” inArtificial Neural Networks — ICANN 2001. Springer Berlin Heidelberg, 2001, pp. 485–491
work page 2001
-
[50]
t-Distributed Stochastic Neighbor Embedding,
L. van der Maaten, “t-Distributed Stochastic Neighbor Embedding,” https://lvdmaaten.github.io/tsne/, 2008
work page 2008
-
[51]
Adam: A method for stochastic optimiza- tion,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,” in3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.