GLo-MAPPO: Multi-Agent Deep Reinforcement Learning for Energy-Efficient UAV-Assisted LoRa Networks
Pith reviewed 2026-05-18 14:53 UTC · model grok-4.3
The pith
GLo-MAPPO uses multi-agent reinforcement learning to let UAVs serve as mobile gateways that jointly optimize spreading factors, powers, trajectories, and associations for higher energy efficiency in LoRa networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors formulate the joint optimization of spreading factors, transmission powers, UAV trajectories, and ED-UAV associations as a partially observable stochastic game and solve it with GLo-MAPPO, a multi-agent proximal policy optimization method that uses centralized training with decentralized execution together with a gain-based association scheme; simulation results show this yields significantly higher energy efficiency and lower power consumption than prior multi-agent reinforcement learning benchmarks across varying network densities.
What carries the argument
GLo-MAPPO, the multi-agent proximal policy optimization algorithm that solves the partially observable stochastic game formulation of the joint optimization problem via centralized training with decentralized execution and a gain-based ED-UAV association scheme.
If this is right
- Higher weighted energy efficiency is achieved by jointly tuning spreading factors, powers, trajectories, and associations.
- Power consumption drops compared with prior multi-agent reinforcement learning methods at multiple network densities.
- Each optimization component and the gain-based association scheme are necessary, as shown by ablation studies.
- The centralized-training decentralized-execution structure allows scalable decisions while capturing global system goals.
Where Pith is reading between the lines
- The same joint-optimization approach could be adapted to other low-power wide-area technologies that need mobile gateways.
- Real hardware trials would reveal how much the simulated gains shrink when wind, interference, or battery aging appear.
- If the energy savings hold outdoors, operators might reduce reliance on satellite backhaul for sparse rural IoT deployments.
- The framework suggests a route to dynamic gateway placement that could later incorporate predictive traffic or weather data.
Load-bearing premise
The simulation model of LoRa propagation, UAV mobility, energy consumption, and channel dynamics matches real-world conditions without large unmodeled discrepancies.
What would settle it
Deploy the GLo-MAPPO controller on physical UAVs and LoRa end devices in an outdoor testbed and compare measured energy efficiency and power draw against the simulation predictions for the same densities and trajectories.
Figures






read the original abstract
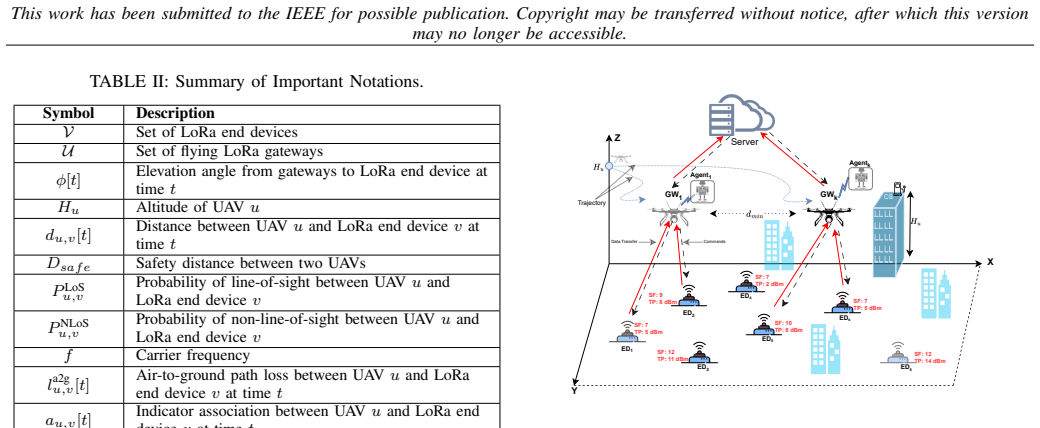
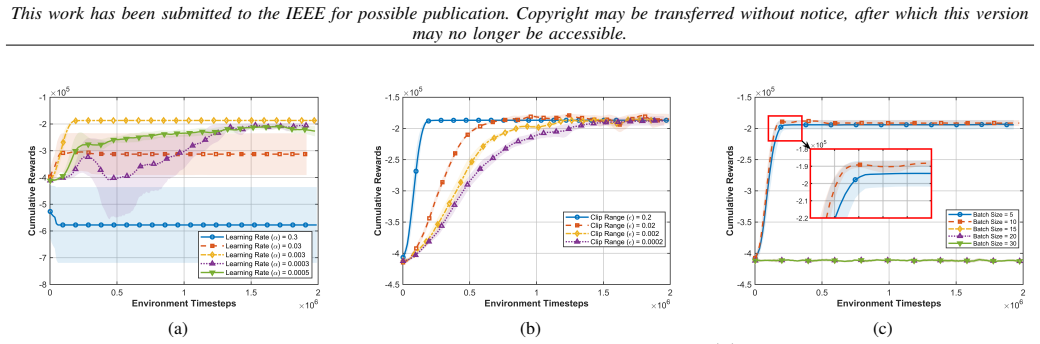
The rapid advancement of Low-Power Wide Area Networks (LPWANs), particularly Long Range (LoRa) systems, has positioned them as a cornerstone for Next-Generation Internet of Things (NG-IoT) applications within 5G/6G ecosystems. Despite their long-range and low-power advantages, achieving high energy efficiency in LoRa networks remains a significant challenge in highly dynamic environments. Traditional terrestrial gateway deployments often suffer from coverage gaps and non-line-of-sight propagation, while satellite-based alternatives incur excessive energy consumption and prohibitive latency. To address these limitations, we propose a multi-UAV architecture where unmanned aerial vehicles (UAVs) serve as mobile LoRa gateways to dynamically collect data from ground-based end devices (EDs). We formulate a joint optimization problem to maximize the system's weighted energy efficiency by jointly optimizing spreading factors, transmission powers, UAV trajectories, and ED-UAV associations. This problem is transformed into a partially observable stochastic game (POSG), which we solve using our proposed Green LoRa Multi-Agent Proximal Policy Optimization (GLo-MAPPO). Our framework leverages centralized training with decentralized execution (CTDE) and is enhanced by a gain-based ED-UAV association scheme. Simulation results show that GLo-MAPPO significantly outperforms state-of-the-art multi-agent reinforcement learning (MARL) benchmarks in energy efficiency and power consumption across varying network densities. Furthermore, ablation studies validate the necessity of each optimization component and the effectiveness of the proposed association scheme.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GLo-MAPPO, a variant of multi-agent proximal policy optimization, to solve a joint optimization problem in a multi-UAV LoRa gateway architecture. The goal is to maximize weighted energy efficiency by optimizing spreading factors, transmission powers, UAV trajectories, and ED-UAV associations, formulated as a partially observable stochastic game solved under centralized training with decentralized execution. Simulation results claim significant outperformance over state-of-the-art MARL baselines in energy efficiency and power consumption across varying network densities, with ablation studies supporting the contribution of each component and the proposed association scheme.
Significance. If the reported gains prove robust, the work could advance practical UAV-assisted LPWAN deployments for dynamic IoT scenarios by demonstrating how CTDE-based MARL can jointly handle discrete (SF, power) and continuous (trajectory) decisions. The gain-based association heuristic and explicit energy model are concrete contributions that could be reused. However, the significance is limited by the absence of external validation or real traces, so the claimed improvements remain tied to the fidelity of the chosen propagation, mobility, and energy models.
major comments (2)
- [§5] §5 (Simulation Results) and the energy-efficiency definition in §3.2: the central performance claim rests on comparisons whose statistical significance, number of independent runs, and baseline hyperparameter tuning protocol are not reported. Without these, it is impossible to determine whether the reported margins exceed what could arise from simulation variance or post-hoc tuning.
- [§4] §4 (System Model) and §5.1 (LoRa Propagation and Energy Model): the path-loss, SF-threshold, and energy-consumption equations omit log-normal shadowing, co-channel interference from external sources, wind-induced UAV control power, and altitude-dependent coverage. Because the energy-efficiency metric is defined directly from these equations, any systematic bias in the model directly inflates the reported gains relative to real deployments.
minor comments (2)
- [§3.3] The notation for the POSG tuple and the reward function in §3.3 could be clarified with an explicit table mapping each component to its mathematical symbol.
- [Figure 3] Figure 3 (trajectory plots) would benefit from an overlay of the ground-truth ED locations and a legend indicating which UAV is which across time steps.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions have been made to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: [§5] §5 (Simulation Results) and the energy-efficiency definition in §3.2: the central performance claim rests on comparisons whose statistical significance, number of independent runs, and baseline hyperparameter tuning protocol are not reported. Without these, it is impossible to determine whether the reported margins exceed what could arise from simulation variance or post-hoc tuning.
Authors: We agree that these experimental details should have been reported explicitly. Our simulations were performed over 5 independent runs per scenario using distinct random seeds, with results presented as averages; we have now added standard deviations to all figures and tables in the revised Section 5. Baseline hyperparameters were taken directly from the respective original papers to maintain fairness, while our own parameters were selected via a modest grid search on a held-out validation scenario. A new paragraph has been inserted in Section 5.1 to document the run count, statistical reporting, and tuning protocol. revision: yes
-
Referee: [§4] §4 (System Model) and §5.1 (LoRa Propagation and Energy Model): the path-loss, SF-threshold, and energy-consumption equations omit log-normal shadowing, co-channel interference from external sources, wind-induced UAV control power, and altitude-dependent coverage. Because the energy-efficiency metric is defined directly from these equations, any systematic bias in the model directly inflates the reported gains relative to real deployments.
Authors: We acknowledge the simplifications in the models of Section 4. Log-normal shadowing and external interference were deliberately excluded to focus on the joint optimization of the proposed MARL framework rather than on channel impairments; we have added an explicit limitations paragraph in the revised Section 4.2 noting that the reported gains represent an upper bound under idealized propagation. Altitude dependence has been incorporated into the path-loss formula. Wind-induced control power is omitted because the UAVs are modeled as hovering at constant altitude with negligible additional consumption in the simulated scenarios; this assumption is now stated and its implications discussed in the updated energy model section. revision: partial
Circularity Check
No significant circularity; derivation and evaluation remain independent of inputs
full rationale
The paper formulates a standard joint optimization over spreading factors, powers, trajectories and associations as a POSG, then applies a CTDE-enhanced MAPPO variant (GLo-MAPPO) with an added gain-based association heuristic. Simulation results compare the learned policy against other MARL baselines on the same objective; this is an empirical performance claim, not a reduction by construction. No equation equates the reported energy-efficiency gains to a fitted parameter or self-citation chain, and the simulation models (path-loss, energy equations) are presented as modeling assumptions rather than derived outputs. The central result therefore retains independent content from the chosen algorithm and benchmark comparisons.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate this complex optimization problem as a partially observable Markov decision process (POMDP) and propose green LoRa multi-agent proximal policy optimization (GLo-MAPPO)... jointly optimizing spreading factors, transmission powers, UAV trajectories, and ED-UAV associations.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Simulation results show that GLo-MAPPO significantly outperforms... in energy efficiency and power consumption across varying network densities.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey on scalable lorawan for massive iot: Recent advances, potentials, and challenges,
M. Jouhari, N. Saeed, M.-S. Alouini, and E. M. Amhoud, “A survey on scalable lorawan for massive iot: Recent advances, potentials, and challenges,”IEEE Communications Surveys & Tutorials, 2023
work page 2023
-
[2]
6g internet of things: A comprehensive survey,
D. C. Nguyen, M. Ding, P. N. Pathirana, A. Seneviratne, J. Li, D. Niyato, O. Dobre, and H. V . Poor, “6g internet of things: A comprehensive survey,”IEEE Internet of Things Journal, vol. 9, no. 1, pp. 359–383, 2022. This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may ...
work page 2022
-
[3]
Z. Zhang, S. Atapattu, B. Ren, Y . Wang, and M. Di Renzo, “Optimizing energy-efficient cooperative mac strategies for data collection in iot networks with terrestrial and nonterrestrial relays,”IEEE Internet of Things Journal, vol. 12, no. 17, pp. 35 556–35 576, 2025
work page 2025
-
[4]
A unified deep transfer learning model for accurate iot localization in diverse environments,
A. I. Ahmed, Y . Etiabi, A. W. Azim, and E. M. Amhoud, “A unified deep transfer learning model for accurate iot localization in diverse environments,” inIEEE 35th International Symposium on Personal, Indoor and Mobile Radio Communications, 2024
work page 2024
-
[5]
H. F. Fakhruldeen, M. J. Saadh, S. Khan, N. A. Salim, N. Jhamat, and G. Mustafa, “Enhancing smart home device identification in wifi environments for futuristic smart networks-based iot,”International Journal of Data Science and Analytics, 2024
work page 2024
-
[6]
A first step toward an iot network dedicated to the sustainable development of a territory,
G. Orazi, G. Fontaine, P. Chemla, M. Zhao, P. Cousin, and F. Le Gall, “A first step toward an iot network dedicated to the sustainable development of a territory,” inGlobal Internet of Things Summit, 2018
work page 2018
-
[7]
Spreading factor assisted lora localization with deep reinforcement learning,
Y . Etiabi, M. Jouhari, A. Burg, and E. M. Amhoud, “Spreading factor assisted lora localization with deep reinforcement learning,” inIEEE 97th Vehicular Technology Conference, 2023
work page 2023
-
[8]
Energy efficient resource allocation for uplink lora networks,
B. Su, Z. Qin, and Q. Ni, “Energy efficient resource allocation for uplink lora networks,” inIEEE Global Communications Conference, 2018
work page 2018
-
[9]
Internet of things (iot) using lora technology,
A. Zourmand, A. L. K. Hing, C. W. Hung, and M. AbdulRehman, “Internet of things (iot) using lora technology,” inIEEE international conference on automatic control and intelligent systems, 2019
work page 2019
-
[10]
Z. Yu, Z. Zhang, S. Zeadally, B. Shen, and X. Pei, “Energy-efficient computing offloading with trajectory optimization and resource allo- cation in uavs aided industrial iot,”IEEE Internet of Things Journal, vol. 12, no. 17, pp. 34 780–34 792, 2025
work page 2025
-
[11]
Fast deployment of uav networks for optimal wireless coverage,
X. Zhang and L. Duan, “Fast deployment of uav networks for optimal wireless coverage,”IEEE Transactions on Mobile Computing, vol. 18, no. 3, pp. 588–601, 2018
work page 2018
-
[12]
College admissions and the stability of marriage,
D. Gale and L. S. Shapley, “College admissions and the stability of marriage,”The American mathematical monthly, vol. 69, no. 1, pp. 9– 15, 1962
work page 1962
-
[13]
Energy efficiency in short and wide-area iot technologies—a survey,
E. Zanaj, G. Caso, L. De Nardis, A. Mohammadpour, ¨O. Alay, and M.-G. Di Benedetto, “Energy efficiency in short and wide-area iot technologies—a survey,”Technologies, vol. 9, no. 1, 2021
work page 2021
-
[14]
A study of lora: Long range & low power networks for the internet of things,
A. Augustin, J. Yi, T. Clausen, and W. M. Townsley, “A study of lora: Long range & low power networks for the internet of things,”Sensors, vol. 16, no. 9, 2016
work page 2016
-
[15]
E. M. Migabo, K. D. Djouani, and A. M. Kurien, “The narrowband internet of things (nb-iot) resources management performance state of art, challenges, and opportunities,”IEEE Access, vol. 8, 2020
work page 2020
-
[16]
The surprising effectiveness of PPO in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of PPO in cooperative multi-agent games,” inThirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022
work page 2022
-
[17]
Spreading fac- tor allocation strategy for lora networks under imperfect orthogonality,
L. Amichi, M. Kaneko, N. El Rachkidy, and A. Guitton, “Spreading fac- tor allocation strategy for lora networks under imperfect orthogonality,” inIEEE International Conference on Communications, 2019
work page 2019
-
[18]
Energy efficient uplink transmissions in lora networks,
B. Su, Z. Qin, and Q. Ni, “Energy efficient uplink transmissions in lora networks,”IEEE Transactions on Communications, vol. 68, no. 8, 2020
work page 2020
-
[19]
Dynamic spreading factor assignment in lora wireless networks,
R. Hamdi, M. Qaraqe, and S. Althunibat, “Dynamic spreading factor assignment in lora wireless networks,” inIEEE international conference on communications, 2020
work page 2020
-
[20]
Flyinglora: Towards energy efficient data collection in uav-assisted lora networks,
R. Xiong, C. Liang, H. Zhang, X. Xu, and J. Luo, “Flyinglora: Towards energy efficient data collection in uav-assisted lora networks,”Computer Networks, vol. 220, p. 109511, 2023
work page 2023
-
[21]
Efficient heuristic for optimal milp-lora adaptive resource allocation for aquaculture
M. I. Arasu, S. S. Rani, and G. R. Geoffery, “Efficient heuristic for optimal milp-lora adaptive resource allocation for aquaculture.” Intelligent Automation & Soft Computing, vol. 33, no. 2, 2022
work page 2022
-
[22]
M. R. Rao and S. Sundar, “Enhanced lorawan performance through advanced spread factor allocation empowered by machine learning,” Engineering Research Express, vol. 6, no. 4, p. 045354, 2024
work page 2024
-
[23]
Intelligent resource allocation in lorawan using machine learning techniques,
S. U. Minhaj, A. Mahmood, S. F. Abedin, S. A. Hassan, M. T. Bhatti, S. H. Ali, and M. Gidlund, “Intelligent resource allocation in lorawan using machine learning techniques,”IEEE Access, vol. 11, 2023
work page 2023
-
[24]
Mix-mab: Reinforcement learning-based resource allocation algorithm for lorawan,
F. Azizi, B. Teymuri, R. Aslani, M. Rasti, J. Tolvaneny, and P. H. J. Nardelli, “Mix-mab: Reinforcement learning-based resource allocation algorithm for lorawan,” inIEEE 95th Vehicular Technology Conference, 2022
work page 2022
-
[25]
Efficient online resource allocation in large- scale lorawan networks: A multi-agent approach,
C. Garrido-Hidalgo, L. Roda-Sanchez, F. J. Ram ´ırez, A. Fern ´andez- Caballero, and T. Olivares, “Efficient online resource allocation in large- scale lorawan networks: A multi-agent approach,”Computer Networks, vol. 221, 2023
work page 2023
-
[26]
M. R. Rao and S. Sundar, “Enhancement in optimal resource-based data transmission over lpwan using a deep adaptive reinforcement learning model aided by novel remora with lotus effect optimization algorithm,” IEEE Access, 2024
work page 2024
-
[27]
Q-learning aided resource allocation and environment recognition in lorawan with csma/ca,
N. Aihara, K. Adachi, O. Takyu, M. Ohta, and T. Fujii, “Q-learning aided resource allocation and environment recognition in lorawan with csma/ca,”IEEE Access, vol. 7, 2019
work page 2019
-
[28]
A. Scarvaglieri, S. Palazzo, and F. Busacca, “A lightweight, fully- distributed ai framework for energy-efficient resource allocation in lora networks,” inProceedings of the IEEE/ACM 16th International Conference on Utility and Cloud Computing, 2023
work page 2023
-
[29]
Multi-agent q-learning algorithm for dynamic power and rate allocation in lora networks,
Y . Yu, L. Mroueh, S. Li, and M. Terr´e, “Multi-agent q-learning algorithm for dynamic power and rate allocation in lora networks,” inIEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, 2020
work page 2020
-
[30]
Deep reinforcement learning-based energy efficiency optimization for flying lora gateways,
M. Jouhari, K. Ibrahimi, J. B. Othman, and E. M. Amhoud, “Deep reinforcement learning-based energy efficiency optimization for flying lora gateways,” inIEEE International Conference on Communications, 2023
work page 2023
-
[31]
Alternating optimization based hybrid precoding strategies for millimeter wave mimo systems,
X. Qiao, Y . Zhang, M. Zhou, and L. Yang, “Alternating optimization based hybrid precoding strategies for millimeter wave mimo systems,” IEEE Access, vol. 8, pp. 113 078–113 089, 2020
work page 2020
-
[32]
Convergence of alternating optimiza- tion,
J. C. Bezdek and R. J. Hathaway, “Convergence of alternating optimiza- tion,”Neural, Parallel & Scientific Computations, vol. 11, no. 4, 2003
work page 2003
-
[33]
P. Jiang, X. Cao, Y . He, X. Song, and Z. Lyu, “Ris-assisted integrated sensing and communication system with physical layer security enhance- ment by drl approach,” inIEEE 99th Vehicular Technology Conference, 2024
work page 2024
-
[34]
The surprising effectiveness of ppo in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in Neural Information Processing Systems, vol. 35, 2022
work page 2022
-
[35]
Bench- marking multi-agent deep reinforcement learning algorithms in coopera- tive tasks,
G. Papoudakis, F. Christianos, L. Sch ¨afer, and S. V . Albrecht, “Bench- marking multi-agent deep reinforcement learning algorithms in coopera- tive tasks,” inProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
work page 2021
-
[36]
Multi-agent reinforcement learning- based resource allocation for uav networks,
J. Cui, Y . Liu, and A. Nallanathan, “Multi-agent reinforcement learning- based resource allocation for uav networks,”IEEE Transactions on Wireless Communications, vol. 19, no. 2, pp. 729–743, 2019
work page 2019
-
[37]
K. Su and F. Qian, “Multi-uav cooperative searching and tracking for moving targets based on multi-agent reinforcement learning,”Applied Sciences, vol. 13, no. 21, p. 11905, 2023
work page 2023
-
[38]
Joint optimization of mobility and reliability-guaranteed air-to-ground communication for uavs,
J. Zhou, D. Tian, Y . Yan, X. Duan, and X. Shen, “Joint optimization of mobility and reliability-guaranteed air-to-ground communication for uavs,”IEEE Transactions on Mobile Computing, vol. 23, no. 1, pp. 566–580, 2022
work page 2022
-
[39]
Y . Shi, Y . Xia, and Y . Gao, “Joint gateway selection and resource allocation for cross-tier communication in space-air-ground integrated iot networks,”IEEE Access, vol. 9, pp. 4303–4314, 2021
work page 2021
-
[40]
Why the shannon and hartley entropies are ‘natural’,
J. Acz ´el, B. Forte, and C. T. Ng, “Why the shannon and hartley entropies are ‘natural’,”Advances in applied probability, vol. 6, no. 1, pp. 131– 146, 1974
work page 1974
-
[41]
Modeling power consumptions for multirotor uavs,
H. Gong, B. Huang, B. Jia, and H. Dai, “Modeling power consumptions for multirotor uavs,”IEEE Transactions on Aerospace and Electronic Systems, vol. 59, no. 6, 2023
work page 2023
-
[42]
Energy minimization for wireless communication with rotary-wing uav,
Y . Zeng, J. Xu, and R. Zhang, “Energy minimization for wireless communication with rotary-wing uav,”IEEE Transactions on Wireless communications, 2019
work page 2019
-
[43]
M. R. Garey and D. S. Johnson,Computers and intractability. wh freeman New York, 2002
work page 2002
-
[44]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Counterfactual multi-agent policy gradients,
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
work page 2018
-
[46]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V . Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuylset al., “Value-decomposition networks for cooperative multi-agent learning,” arXiv preprint arXiv:1706.05296, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Monotonic value function factorisation for deep multi- agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
work page 2020
-
[48]
Is indepen- dent learning all you need in the starcraft multi-agent challenge?
C. S. De Witt, T. Gupta, D. Makoviichuk, V . Makoviychuk, P. H. Torr, M. Sun, and S. Whiteson, “Is independent learning all you need in the starcraft multi-agent challenge?”arXiv preprint arXiv:2011.09533, 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.