Rethinking player evaluation in sports: Goals above expectation and beyond
Pith reviewed 2026-05-22 11:59 UTC · model grok-4.3
The pith
Residualized machine learning metrics enable valid frequentist inference for player performance in sports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Metrics based on differences between observed and model-predicted outcomes are equivalent to Rao's score tests in parametric regressions for the expected outcome; residualized versions of these metrics, obtained by additionally regressing on player involvement, inherit the Neyman orthogonality and rate conditions of double machine learning and therefore permit valid inference even when flexible nuisance estimators are used.
What carries the argument
Residualized outcome-difference metrics constructed via double machine learning, which adjust the original GAX-style quantities by an extra regression step that predicts player participation given the observed features.
If this is right
- The residualized metrics support inference on whether individual players exert a positive directional effect on outcomes such as goals or shot success.
- The same construction applies directly to goalkeeper save evaluation, basketball shooting skill, quarterback passing accuracy, and soccer player injury proneness.
- Player-specific effect estimates become interpretable within semiparametric regression models that separate the contribution of each athlete from the baseline expectation.
Where Pith is reading between the lines
- Analysts could use the framework to attach confidence intervals to player rankings, reducing the risk of overvaluing short-term luck in contract or lineup decisions.
- The residualization idea may transfer to other observational domains where flexible models are used to benchmark individual performance against a population baseline.
- Extensions could examine finite-sample coverage of the resulting confidence intervals under realistic sports-data sparsity.
Load-bearing premise
The chosen nuisance estimators for the expected outcome and for player involvement must be consistent at the rates required by double machine learning and must satisfy Neyman orthogonality after residualization.
What would settle it
In a large soccer dataset where the expected-goal model is known to be correctly specified, the residualized GAX statistic for a player with no true effect should be statistically indistinguishable from zero at conventional significance levels; systematic rejection would indicate that the regularity conditions fail in practice.
Figures











read the original abstract
A popular quantitative approach to evaluating player performance in sports involves comparing an observed outcome to the expected outcome ignoring player involvement, which is estimated using statistical or machine learning methods. In soccer, for instance, goals above expectation (GAX) of a player measure how often shots of this player led to a goal compared to the model-derived expected outcome of the shots. Typically, sports data analysts rely on flexible machine learning models, which are capable of handling complex nonlinear effects and feature interactions, but fail to provide valid statistical inference due to finite-sample bias and slow convergence rates. In this paper, we close this gap by presenting a framework for player evaluation with metrics derived from differences in actual and expected outcomes using flexible machine learning algorithms, which nonetheless allows for valid frequentist inference. We first show that the commonly used metrics are directly related to Rao's score test in parametric regression models for the expected outcome. Motivated by this finding and recent developments in double machine learning, we then propose the use of residualized versions of the original metrics. For GAX, the residualization step corresponds to an additional regression predicting whether a given player would take the shot under the circumstances described by the features. We further relate metrics in the proposed framework to player-specific effect estimates in interpretable semiparametric regression models, allowing us to infer directional effects, e.g., to determine players that have a positive impact on the outcome. Our primary use case are GAX in soccer. We further apply our framework to evaluate goal-stopping ability of goalkeepers, shooting skill in basketball, quarterback passing skill in American football, and injury-proneness of soccer players.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a framework for player evaluation in sports that compares observed outcomes to expected outcomes estimated via flexible machine learning models. It shows that standard metrics such as goals above expectation (GAX) are related to Rao's score test, then proposes residualized versions of these metrics motivated by double machine learning to restore valid frequentist inference. The residualization for GAX includes an auxiliary regression for shot-taking probability. The framework is further connected to player-specific effects in semiparametric models and is demonstrated on soccer GAX, goalkeeper performance, basketball shooting, American football passing, and soccer injury proneness.
Significance. If the inference claims hold after residualization, the work would offer a practical advance in sports analytics by permitting complex ML models for expected-outcome estimation while supplying valid standard errors and directional effect tests. The explicit links to Rao's score test and double ML provide theoretical grounding that is often missing in applied sports metrics, and the multi-sport applications illustrate generality.
major comments (2)
- [§3.2] §3.2 (residualized GAX construction): the validity of frequentist inference after residualization rests on the double ML nuisance estimators (shot probability model and outcome model) satisfying the n^{-1/4} rate and Neyman orthogonality conditions. The manuscript invokes these conditions but provides neither simulation verification under sports-data regimes (modest per-player samples, high-dimensional covariates, player heterogeneity) nor empirical rate diagnostics; without this, the reported standard errors for residualized GAX lack guaranteed coverage.
- [§4.1] §4.1 (semiparametric interpretation): the claim that residualized metrics correspond to player-specific coefficients in a partially linear model requires explicit derivation of the equivalence, including the precise form of the player indicator and the orthogonality condition after residualization. The current sketch leaves open whether the estimator remains consistent when the player-shot indicator is itself high-dimensional or sparse.
minor comments (2)
- The abstract and introduction would benefit from a concise statement of the exact regularity conditions invoked from the double ML literature (e.g., Chernozhukov et al.).
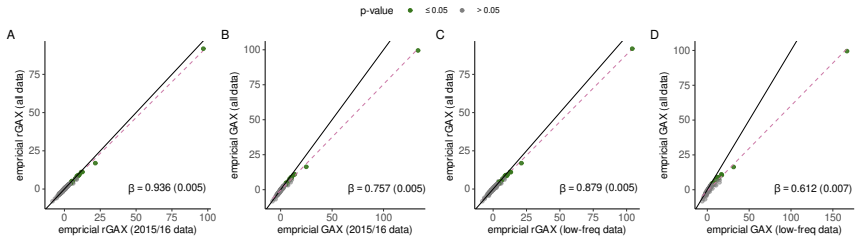
- [Figure 1] Figure 1 (GAX comparison): axis labels and legend should explicitly distinguish raw versus residualized versions to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have prompted us to strengthen the theoretical and empirical support in the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (residualized GAX construction): the validity of frequentist inference after residualization rests on the double ML nuisance estimators (shot probability model and outcome model) satisfying the n^{-1/4} rate and Neyman orthogonality conditions. The manuscript invokes these conditions but provides neither simulation verification under sports-data regimes (modest per-player samples, high-dimensional covariates, player heterogeneity) nor empirical rate diagnostics; without this, the reported standard errors for residualized GAX lack guaranteed coverage.
Authors: We agree that additional verification tailored to sports data regimes would enhance confidence in the finite-sample properties. While the double ML framework supplies asymptotic guarantees under the n^{-1/4} rate and Neyman orthogonality conditions, we acknowledge the referee's point that explicit checks are valuable when per-player samples are modest and covariates are high-dimensional. In the revised manuscript we will add a dedicated simulation study that generates data under realistic sports regimes (limited shots per player, high-dimensional features, and player heterogeneity) and reports empirical coverage of the residualized GAX standard errors together with diagnostics for nuisance estimator convergence rates. revision: yes
-
Referee: [§4.1] §4.1 (semiparametric interpretation): the claim that residualized metrics correspond to player-specific coefficients in a partially linear model requires explicit derivation of the equivalence, including the precise form of the player indicator and the orthogonality condition after residualization. The current sketch leaves open whether the estimator remains consistent when the player-shot indicator is itself high-dimensional or sparse.
Authors: We thank the referee for requesting a more explicit derivation. In the revised Section 4.1 we will supply the full equivalence proof: consider the partially linear model Y = m(X) + θ D + ε where D is the binary player (or shot-taking) indicator and m(X) is estimated by machine learning. The residualized metric is exactly the Neyman-orthogonal score for θ obtained by regressing the outcome residual on the player-indicator residual. We will show that the orthogonality condition holds after double residualization and that the resulting estimator for θ is consistent and asymptotically normal. For the high-dimensional or sparse case we will clarify that, provided the nuisance functions are estimated at the required rate (e.g., via lasso or other sparse methods) and the number of players grows appropriately with sample size, consistency is preserved; we will add a short discussion of these conditions. revision: yes
Circularity Check
No circularity: derivation relies on external DML and score-test identity
full rationale
The paper first relates standard GAX-style metrics to Rao's score test via a direct algebraic connection in parametric models (a known statistical identity, not a self-definition). It then introduces residualized versions explicitly motivated by the external double machine learning literature (Chernozhukov et al. and follow-ups), with the auxiliary regression for shot probability presented as an application of Neyman orthogonality rather than a redefinition of the target metric. No self-citation chain, fitted parameter renamed as prediction, or ansatz smuggled via prior work by the same authors appears in the provided abstract or derivation outline. The central claim of valid frequentist inference therefore rests on independent external theory plus the paper's own residualization step, leaving the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Double machine learning regularity conditions (consistent nuisance estimation at appropriate rates and Neyman orthogonality after residualization) hold for the chosen ML estimators.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose to use empirical residualized GAX (rGAX) := sum (Yi - bh(Zi))(Xi - bf(Zi)), a scaled version of the sample GCM
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. G. Altman and J. M. Bland. Statistics notes: Absence of evidence is not evidence of absence. BMJ, 311 0 (7003): 0 485--485, 1995. doi:10.1136/bmj.311.7003.485
-
[2]
G. Anzer and P. Bauer. A Goal Scoring Probability Model for Shots Based on Synchronized Positional and Event Data in Football (Soccer) . Frontiers in Sports and Active Living, 3: 0 53, 2021. doi:10.3389/fspor.2021.624475
-
[3]
E. Baron, N. Sandholtz, D. Pleuler, and T. C. Y. Chan. Miss it like Messi : Extracting value from off-target shots in soccer. Journal of Quantitative Analysis in Sports, 20 0 (1): 0 37--50, 2024. doi:10.1515/jqas-2022-0107
-
[4]
B. S. Baumer, G. J. Matthews, and Q. Nguyen. Big ideas in sports analytics and statistical tools for their investigation. WIREs Computational Statistics, 15 0 (6): 0 e1612, 2023. doi:10.1002/wics.1612
-
[5]
R. Bender and S. Lange. Adjusting for multiple testing—when and how? Journal of Clinical Epidemiology, 54 0 (4): 0 343--349, 2001. doi:10.1016/s0895-4356(00)00314-0
-
[6]
Y. Benjamini and Y. Hochberg. Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society Series B: Statistical Methodology, 57 0 (1): 0 289--300, 1995. doi:10.1111/j.2517-6161.1995.tb02031.x
-
[7]
L. Breiman. Random forests. Machine Learning, 45 0 (1): 0 5--32, 2001. doi:10.1023/A:1010933404324
- [8]
-
[9]
S. Carl and B. Baldwin. nflfastR : Functions to Efficiently Access NFL Play by Play Data , 2024. URL https://CRAN.R-project.org/package=nflfastR. R package version 5.0.0
work page 2024
-
[10]
Y. H. Chang, R. Maheswaran, J. Su, S. Kwok, T. Levy, A. Wexler, and K. Squire. Quantifying Shot Quality in the NBA . In Proceedings of the 2014 MIT Sloan Sports Analytics Conference, 2014
work page 2014
-
[11]
T. Chen, T. He, M. Benesty, V. Khotilovich, Y. Tang, H. Cho, K. Chen, R. Mitchell, I. Cano, T. Zhou, M. Li, J. Xie, M. Lin, Y. Geng, Y. Li, and J. Yuan. xgboost: Extreme Gradient Boosting , 2025. URL https://CRAN.R-project.org/package=xgboost. R package version 1.7.9.1
work page 2025
-
[12]
Double/debiased/neyman machine learning of treatment effects
V. Chernozhukov, D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, and W. Newey. Double/Debiased/Neyman Machine Learning of Treatment Effects . American Economic Review, 107 0 (5): 0 261--65, 2017. doi:10.1257/aer.p20171038
-
[13]
A. M. Christgau, L. Petersen, and N. R. Hansen. Nonparametric Conditional Local Independence Testing . The Annals of Statistics, 51 0 (5): 0 2116--2144, 2023. doi:10.1214/23-AOS2323
-
[14]
C. Cinelli, A. Forney, and J. Pearl. A crash course in good and bad controls. Sociological Methods & Research, 53 0 (3): 0 1071--1104, 2024. doi:10.1177/00491241221099552
-
[15]
S. Corsaro, G. Dello Ioio, and Z. Marino. The evaluation of football players: an in-depth look at the Expected Goal metric . Annals of Operations Research, 2025. doi:10.1007/s10479-025-06606-8
-
[16]
D. Daly-Grafstein and L. Bornn. Rao-Blackwellizing field goal percentage . Journal of Quantitative Analysis in Sports, 15 0 (2): 0 85--95, 2019. doi:doi:10.1515/jqas-2018-0064
-
[17]
J. Davis and P. Robberechts. Expected Metrics as a Measure of Skill: Reflections on Finishing in Soccer . In Workshop on Machine Learning and Data Mining for Sports Analytics at ECML/PKDD 2023, MLSA. Springer, 2023
work page 2023
-
[18]
J. Davis and P. Robberechts. Biases in Expected Goals Models Confound Finishing Ability , 2024. URL https://arxiv.org/abs/2401.09940
-
[19]
J. Davis, L. Bransen, L. Devos, A. Jaspers, W. Meert, P. Robberechts, J. Van Haaren, and M. Van Roy. Methodology and evaluation in sports analytics: challenges, approaches, and lessons learned. Machine Learning, 113 0 (9): 0 6977--7010, 2024. doi:10.1007/s10994-024-06585-0
-
[20]
A. P. Dawid. Conditional Independence in Statistical Theory . Journal of the Royal Statistical Society B, 41 0 (1): 0 1--15, 1979. doi:10.1111/j.2517-6161.1979.tb01052.x
-
[21]
J. Fern \'a ndez, L. Bornn, and D. Cervone. A framework for the fine-grained evaluation of the instantaneous expected value of soccer possessions. Machine Learning, 110 0 (6): 0 1389--1427, 2021. doi:10.1007/s10994-021-05989-6
-
[22]
M. Fern \'a ndez-Delgado, E. Cernadas, S. Barro, and D. Amorim. Do we need hundreds of classifiers to solve real world classification problems? Journal of Machine Learning Research, 15 0 (90): 0 3133--3181, 2014. URL http://jmlr.org/papers/v15/delgado14a.html
work page 2014
-
[23]
S. Gilani. hoopR : Access Men's Basketball Play by Play Data , 2023. URL https://CRAN.R-project.org/package=hoopR. R package version 2.1.0
work page 2023
-
[24]
A. Groll, C. Ley, G. Schauberger, and H. V. Eetvelde. A hybrid random forest to predict soccer matches in international tournaments. Journal of Quantitative Analysis in Sports, 15 0 (4): 0 271--287, 2019. doi:doi:10.1515/jqas-2018-0060
-
[25]
J. H. Hewitt and O. Karakuş. A machine learning approach for player and position adjusted expected goals in football (soccer). Franklin Open, 4: 0 100034, 2023. doi:10.1016/j.fraope.2023.100034
-
[26]
T. Hothorn, K. Hornik, M. A. van de Wiel , and A. Zeileis. Implementing a class of permutation tests: The coin package. Journal of Statistical Software, 28 0 (8): 0 1--23, 2008. doi:10.18637/jss.v028.i08
-
[27]
D. Karlis and I. Ntzoufras. Analysis of sports data by using bivariate Poisson models . Journal of the Royal Statistical Society: Series D (The Statistician), 52 0 (3): 0 381--393, 2003. doi:https://doi.org/10.1111/1467-9884.00366
-
[28]
E. H. Kennedy. Semiparametric doubly robust targeted double machine learning: a review. In Handbook of statistical methods for precision medicine, pages 207--236. Chapman and Hall/CRC, 2024. doi:10.1201/9781003216223
-
[29]
J. P. Klein, H. C. Van Houwelingen, J. G. Ibrahim, and T. H. Scheike. Handbook of survival analysis. CRC Press Boca Raton, 2014
work page 2014
-
[30]
L. Kook and A. R. Lundborg. Algorithm-agnostic significance testing in supervised learning with multimodal data. Briefings in Bioinformatics, 25 0 (6), 2024. doi:10.1093/bib/bbae475
-
[31]
L. Kook, S. Saengkyongam, A. R. Lundborg, T. Hothorn, and J. Peters. Model-based causal feature selection for general response types. Journal of the American Statistical Association, 120 0 (550): 0 1090--1101, 2025. doi:10.1080/01621459.2024.2395588
-
[32]
R. Metulini and M. L. Carre. Measuring sport performances under pressure by classification trees with application to basketball shooting. Journal of Applied Statistics, 47 0 (12): 0 2120--2135, 2020. doi:10.1080/02664763.2019.1704702
-
[33]
J. Nunnally. The place of statistics in psychology. Educational and Psychological Measurement, 20 0 (4): 0 641--650, 1960. doi:10.1177/001316446002000401
-
[34]
R. Pollard and C. Reep. Measuring the effectiveness of playing strategies at soccer. Journal of the Royal Statistical Society: Series D (The Statistician), 46 0 (4): 0 541--550, 1997. doi:10.1111/1467-9884.00108
-
[35]
R: A Language and Environment for Statistical Computing
R Core Team . R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2025. URL https://www.R-project.org/
work page 2025
-
[36]
C. R. Rao. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. Mathematical Proceedings of the Cambridge Philosophical Society, 44 0 (1): 0 50–57, 1948. doi:10.1017/S0305004100023987
-
[37]
P. Robberechts and J. Davis. How Data Availability Affects the Ability to Learn Good xG Models . In U. Brefeld, J. Davis, J. Van Haaren, and A. Zimmermann, editors, Machine Learning and Data Mining for Sports Analytics, pages 17--27, Cham, 2020. Springer International Publishing
work page 2020
-
[38]
P. Scarf, A. Khare, and N. Alotaibi. On skill and chance in sport. IMA Journal of Management Mathematics, 33 0 (1): 0 53--73, 2021. doi:10.1093/imaman/dpab026
-
[39]
R. D. Shah and J. Peters. The hardness of conditional independence testing and the generalised covariance measure . The Annals of Statistics, 48 0 (3): 0 1514 -- 1538, 2020. doi:10.1214/19-AOS1857
-
[40]
T. M. Therneau, P. M. Grambsch, and T. R. Fleming. Martingale-based residuals for survival models. Biometrika, 77 0 (1): 0 147--160, 1990. ISSN 1464-3510. doi:10.1093/biomet/77.1.147
-
[41]
S. Vansteelandt and O. Dukes. Assumption-lean Inference for Generalised Linear Model Parameters . Journal of the Royal Statistical Society Series B: Statistical Methodology, 84 0 (3): 0 657--685, 2022. doi:10.1111/rssb.12504
-
[42]
M. N. Wright and A. Ziegler. ranger : A fast implementation of random forests for high dimensional data in C++ and R . Journal of Statistical Software, 77 0 (1): 0 1--17, 2017. doi:10.18637/jss.v077.i01
-
[43]
D. Yam. StatsBombR : Cleans and pulls StatsBomb data from the API , 2025. URL https://github.com/statsbomb/StatsBombR. R package version 0.1.0
work page 2025
-
[44]
L. Zumeta Olaskoaga . injurytools : A Toolkit for Sports Injury Data Analysis , 2023. URL https://CRAN.R-project.org/package=injurytools. R package version 1.0.3
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.