Learning-Based vs Human-Derived Congestion Control: An In-Depth Experimental Study
Pith reviewed 2026-05-18 03:51 UTC · model grok-4.3
The pith
Learning-based congestion control acquires full bandwidth with low latency but fairness fails to generalize and performance drops when bandwidth or latency changes dynamically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
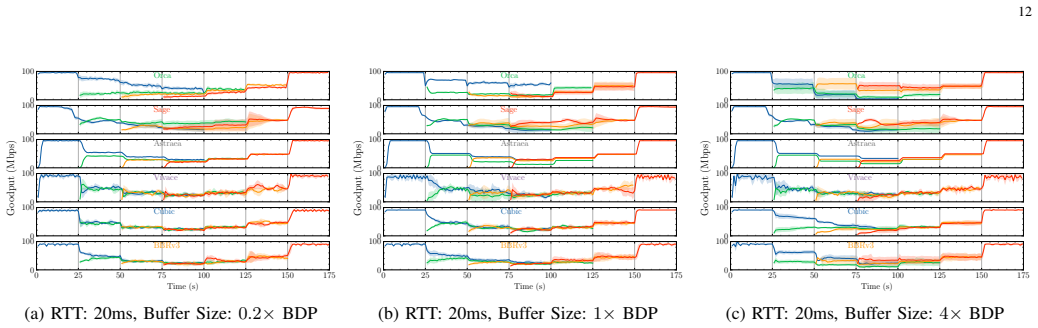
RL learning-based approaches can acquire all available bandwidth while largely maintaining low latency. Embedding fairness directly into reward functions is effective; however, the fairness properties do not generalise into unseen conditions. Existing approaches under-perform when the available bandwidth and end-to-end latency dynamically change while remaining resistant to non-congestive loss.
What carries the argument
Large-scale reproducible experimentation that directly contrasts publicly available learning-based CC implementations against TCP Cubic and BBR version 3 across controlled variations in bandwidth, latency, and loss.
If this is right
- Fairness achieved by direct reward engineering remains effective only inside the training distribution.
- Learning-based methods saturate bandwidth while preserving low latency in stable network settings.
- Performance degrades when bandwidth and latency vary dynamically over time.
- Resistance to non-congestive loss persists across the tested scenarios.
- A reproducible evaluation methodology and public codebase enable direct comparison of future learning-based CC proposals.
Where Pith is reading between the lines
- Training on a broader set of traces that include abrupt bandwidth and latency shifts could strengthen generalization.
- The observed resistance to non-congestive loss may give learning-based methods an edge in wireless or error-prone links.
- Hybrid designs that fall back to traditional rules during detected transitions might combine the strengths of both approaches.
- Standardized benchmarks should explicitly include sudden parameter changes to expose generalization gaps.
Load-bearing premise
The publicly available learning-based CC implementations and the chosen simulation scenarios are representative of both state-of-the-art methods and the range of conditions encountered in real networks.
What would settle it
A new learning-based CC implementation that maintains both fairness and high performance after sudden drops in available bandwidth combined with increases in end-to-end latency would directly challenge the reported limitations.
Figures











read the original abstract
Learning-based congestion control (CC), including Reinforcement-Learning, promises efficient CC in a fast-changing networking landscape, where evolving communication technologies, applications and traffic workloads pose severe challenges to human-derived, static CC algorithms. Learning-based CC is in its early days and substantial research is required to understand existing limitations, identify research challenges and, eventually, yield deployable solutions for real-world networks. In this paper, we extend our prior work and present a reproducible and systematic study of learning-based CC with the aim to highlight strengths and uncover fundamental limitations of the state-of-the-art. We directly contrast said approaches with widely deployed, human-derived CC algorithms, namely TCP Cubic and BBR (version 3). We identify challenges in evaluating learning-based CC, establish a methodology for studying said approaches and perform large-scale experimentation with learning-based CC approaches that are publicly available. We show that embedding fairness directly into reward functions is effective; however, the fairness properties do not generalise into unseen conditions. We then show that RL learning-based approaches existing approaches can acquire all available bandwidth while largely maintaining low latency. Finally, we highlight that existing the latest learning-based CC approaches under-perform when the available bandwidth and end-to-end latency dynamically change while remaining resistant to non-congestive loss. As with our initial study, our experimentation codebase and datasets are publicly available with the aim to galvanise the research community towards transparency and reproducibility, which have been recognised as crucial for researching and evaluating machine-generated policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper extends prior work to present a systematic, reproducible experimental study comparing learning-based congestion control (CC) algorithms, including reinforcement learning (RL) approaches, with human-derived algorithms such as TCP Cubic and BBR version 3. Through large-scale experimentation using publicly available implementations, the authors show that RL-based methods can acquire all available bandwidth while maintaining low latency, that embedding fairness in reward functions is effective but the fairness properties do not generalize to unseen conditions, and that these learning-based approaches under-perform when bandwidth and end-to-end latency change dynamically, although they remain resistant to non-congestive loss. The study also discusses challenges in evaluating learning-based CC and provides public code and datasets.
Significance. If the results hold, the paper makes a significant contribution by empirically demonstrating the strengths and limitations of state-of-the-art learning-based congestion control in comparison to traditional methods. The identification of generalization failures and dynamic adaptation issues is valuable for guiding future research. The public availability of the codebase and datasets is a key strength that promotes transparency and reproducibility in the field.
major comments (1)
- The headline finding that existing learning-based CC approaches under-perform when available bandwidth and end-to-end latency dynamically change is central to the paper's assessment of limitations. This relies on the simulation scenarios being representative of real networks. The paper should provide more details on the specific traces used for dynamic changes, including their range, variation frequency, and how they compare to real-world network conditions, to address potential concerns that the results may be testbed-specific.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for major revision. We address the major comment below and will revise the manuscript to incorporate additional details on the simulation traces.
read point-by-point responses
-
Referee: The headline finding that existing learning-based CC approaches under-perform when available bandwidth and end-to-end latency dynamically change is central to the paper's assessment of limitations. This relies on the simulation scenarios being representative of real networks. The paper should provide more details on the specific traces used for dynamic changes, including their range, variation frequency, and how they compare to real-world network conditions, to address potential concerns that the results may be testbed-specific.
Authors: We thank the referee for highlighting this point. To strengthen the paper, we will add a dedicated subsection in the evaluation methodology describing the dynamic traces in detail. This will specify the bandwidth ranges (typically 1-100 Mbps), latency ranges (10-200 ms), variation frequencies and patterns, and direct comparisons to real-world conditions using public datasets such as those from CAIDA and M-Lab. Our publicly released codebase and datasets already contain the exact traces, enabling full inspection and reproducibility. We believe these additions will confirm the scenarios are representative rather than testbed-specific while preserving the core findings on generalization failures. revision: yes
Circularity Check
No significant circularity in this experimental study
full rationale
The paper is an empirical experimental comparison of learning-based congestion control algorithms against human-derived ones (TCP Cubic, BBR v3), with all central claims about bandwidth acquisition, latency maintenance, fairness generalization failure, and under-performance under dynamic bandwidth/latency changes resting directly on simulation measurements rather than any mathematical derivation, fitted parameters, or first-principles results. Although the abstract notes that the work extends the authors' prior research, this self-reference does not bear the load of the findings, which are supported by new large-scale experiments, publicly available implementations, and datasets. No equations, ansatzes, uniqueness theorems, or reductions to inputs by construction appear; the analysis is self-contained against external benchmarks and reproducible artifacts.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The publicly available learning-based CC implementations accurately represent current state-of-the-art approaches.
- domain assumption The simulated network conditions and dynamic changes capture relevant real-world behaviors.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that embedding fairness directly into reward functions is effective; however, the fairness properties do not generalise into unseen conditions... RL learning-based approaches can acquire all available bandwidth while largely maintaining low latency... under-perform when the available bandwidth and end-to-end latency dynamically change
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Astraea... introduce fairness directly in its reward function, in combination with multi-agent RL
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wier- stra, and M. Riedmiller, “Playing atari with deep reinforcement learn- ing,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik et al., “Grandmaster level in StarCraft II using multi-agent reinforcement learning,”Nature, vol. 575, no. 7782, 2019
work page 2019
-
[3]
Mastering the game of go without human knowledge,
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guezet al., “Mastering the game of go without human knowledge,” Nature, vol. 550, no. 7676, 2017
work page 2017
-
[4]
A general reinforcement learning algorithm that masters chess, shogi, and go through self-play,
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez et al., “A general reinforcement learning algorithm that masters chess, shogi, and go through self-play,”Science, 2018
work page 2018
-
[5]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwrightet al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, 2022
work page 2022
-
[6]
Magnetic control of tokamak plasmas through deep reinforce- ment learning,
B. D. Tracey, A. Michi, Y . Chervonyi, I. Davies, C. Paduraru, N. Lazic et al., “Magnetic control of tokamak plasmas through deep reinforce- ment learning,”Nature, vol. 602, no. 7897, 2022
work page 2022
-
[7]
Reinforcement learning based routing in networks: Re- view and classification of approaches,
Z. Mammeri, “Reinforcement learning based routing in networks: Re- view and classification of approaches,”IEEE Access, vol. 7, 2019
work page 2019
-
[8]
T. Huang, R.-X. Zhang, C. Zhou, and L. Sun, “QARC: Video quality aware rate control for real-time video streaming based on deep rein- forcement learning,” inProc. of ACM MM, 2018
work page 2018
-
[9]
Neural adaptive video stream- ing with pensieve,
H. Mao, R. Netravali, and M. Alizadeh, “Neural adaptive video stream- ing with pensieve,” inProc. of ACM SIGCOMM, 2017
work page 2017
-
[10]
Deep reinforcement learning for dynamic multichannel access in wireless networks,
S. Wang, H. Liu, P. H. Gomeset al., “Deep reinforcement learning for dynamic multichannel access in wireless networks,”IEEE Transactions on Cognitive Communications and Networking, vol. 4, no. 2, 2018
work page 2018
-
[11]
Deep multi-user reinforcement learning for distributed dynamic spectrum access,
O. Naparstek and K. Cohen, “Deep multi-user reinforcement learning for distributed dynamic spectrum access,”IEEE Transactions on Wireless Communications, vol. 18, no. 1, 2018
work page 2018
-
[12]
Deep reinforcement learning for cyber security,
T. T. Nguyenet al., “Deep reinforcement learning for cyber security,” IEEE Transactions on Neural Networks and Learning Systems, 2019
work page 2019
-
[13]
Reinforcement learning for IoT security: A comprehensive survey,
A. Uprety and D. B. Rawat, “Reinforcement learning for IoT security: A comprehensive survey,”IEEE Internet of Things Journal, 2020
work page 2020
-
[14]
Deep reinforcement learning for mobile edge caching: Review, new features, and open issues,
H. Zhu, Y . Cao, W. Wang, T. Jiang, and S. Jin, “Deep reinforcement learning for mobile edge caching: Review, new features, and open issues,”IEEE Network, 2018
work page 2018
-
[15]
Y . He, N. Zhao, and H. Yin, “Integrated networking, caching, and com- puting for connected vehicles: A deep reinforcement learning approach,” IEEE Transactions on Vehicular Technology, vol. 67, no. 1, 2017
work page 2017
-
[16]
CUBIC: A New TCP-Friendly High-Speed TCP Variant,
S. Ha, I. Rhee, and L. Xu, “CUBIC: A New TCP-Friendly High-Speed TCP Variant,”SIGOPS Oper. Syst. Rev., 2008
work page 2008
-
[17]
N. Cardwell, Y . Cheng, C. S. Gunn, S. H. Yeganeh, and V . Jacob- son, “BBR: Congestion-based congestion control: Measuring bottleneck bandwidth and round-trip propagation time,”Queue, vol. 14, no. 5, 2016
work page 2016
-
[18]
Tcp ex machina: computer-generated congestion control,
K. Winstein and H. Balakrishnan, “Tcp ex machina: computer-generated congestion control,” ser. SIGCOMM ’13. Association for Computing Machinery, 2013. [Online]. Available: https://doi.org/10.1145/2486001. 2486020
-
[19]
Pcc: re-architecting congestion control for consistent high performance,
M. Dong, Q. Li, D. Zarchy, P. B. Godfrey, and M. Schapira, “Pcc: re-architecting congestion control for consistent high performance,” in Proceedings of the 12th USENIX Conference on Networked Systems Design and Implementation, ser. NSDI’15. USENIX Association, 2015
work page 2015
-
[20]
PCC Vivace: Online-learning congestion control,
M. Dong, T. Meng, D. Zarchy, E. Arslan, Y . Gilad, B. Godfrey, and M. Schapira, “PCC Vivace: Online-learning congestion control,” inProc. of USENIX NSDI, 2018
work page 2018
-
[21]
Experimental evaluation of TCP protocols for high-speed networks,
Y .-T. Li, D. Leith, and R. N. Shorten, “Experimental evaluation of TCP protocols for high-speed networks,”IEEE/ACM Transactions on Networking, vol. 15, no. 5, 2007
work page 2007
-
[22]
TCP-Drinc: Smart congestion control based on deep reinforcement learning,
K. Xiao, S. Mao, and J. K. Tugnait, “TCP-Drinc: Smart congestion control based on deep reinforcement learning,”IEEE Access, 2019
work page 2019
-
[23]
W. Li, H. Zhang, S. Gao, C. Xue, X. Wang, and S. Lu, “SmartCC: A reinforcement learning approach for multipath TCP congestion control in heterogeneous networks,”IEEE Journal on Selected Areas in Com- munications, vol. 37, no. 11, 2019
work page 2019
-
[24]
A deep reinforcement learning perspective on Internet congestion control,
N. Jay, N. Rotman, B. Godfreyet al., “A deep reinforcement learning perspective on Internet congestion control,” inProc. of ICML, 2019
work page 2019
-
[25]
Classic meets modern: A pragmatic learning-based congestion control for the Internet,
S. Abbasloo, C.-Y . Yen, and H. J. Chao, “Classic meets modern: A pragmatic learning-based congestion control for the Internet,” inProc. of ACM SIGCOMM, 2020
work page 2020
-
[26]
Astraea: Towards fair and efficient learning-based congestion control,
X. Liao, H. Tian, C. Zeng, X. Wan, and K. Chen, “Astraea: Towards fair and efficient learning-based congestion control,” inProc. of EuroSys 2024, 2024
work page 2024
-
[27]
Spine: an efficient DRL-based congestion control with ultra-low overhead,
H. Tian, X. Liao, C. Zenget al., “Spine: an efficient DRL-based congestion control with ultra-low overhead,” inProc. of ACM CoNEXT, 2022
work page 2022
-
[28]
Computers can learn from the heuristic designs and master internet congestion control,
C.-Y . Yen, S. Abbasloo, and H. J. Chao, “Computers can learn from the heuristic designs and master internet congestion control,” inProc. of ACM SIGCOMM, 2023
work page 2023
-
[29]
Reproducible network experiments using container-based emulation,
N. Handigol, B. Helleret al., “Reproducible network experiments using container-based emulation,” inProc. of CoNEXT, 2012
work page 2012
-
[30]
QTCP: Adaptive congestion control with reinforcement learning,
W. Li, F. Zhou, K. R. Chowdhury, and W. Meleis, “QTCP: Adaptive congestion control with reinforcement learning,”IEEE Transactions on Network Science and Engineering, vol. 6, no. 3, 2018
work page 2018
-
[31]
Learning in situ: a randomized experiment in video streaming,
F. Y . Yan, H. Ayers, C. Zhu, S. Fouladi, J. Hong, K. Zhang, P. Levis, and K. Winstein, “Learning in situ: a randomized experiment in video streaming,” inProc. of USENIX NSDI, 2020
work page 2020
-
[32]
RayNet: A simulation platform for developing reinforcement learning-driven network protocols,
L. Giacomoni, B. Benny, and G. Parisis, “RayNet: A simulation platform for developing reinforcement learning-driven network protocols,”CoRR, vol. abs/2302.04519, 2023
-
[33]
ns-3 meets OpenAI Gym: The playground for machine learning in networking research,
P. Gawłowicz and A. Zubow, “ns-3 meets OpenAI Gym: The playground for machine learning in networking research,” inACM MSWiM, 2019
work page 2019
-
[34]
L. Giacomoni and G. Parisis, “Reinforcement learning-based congestion control: A systematic evaluation of fairness, efficiency and responsive- ness,” inProc. of IEEE INFOCOM, 2024
work page 2024
-
[35]
Hybrid modeling of TCP congestion control,
J. P. Hespanha, S. Bohacek, K. Obraczka, and J. Lee, “Hybrid modeling of TCP congestion control,” inProc. of HSCC, 2001
work page 2001
-
[36]
Modelling TCP congestion control dynamics in drop-tail environments,
R. Shorten, C. King, F. Wirth, and D. Leith, “Modelling TCP congestion control dynamics in drop-tail environments,”Automatica, 2007
work page 2007
-
[37]
Towards a deeper understanding of TCP BBR congestion control,
D. Scholz, B. Jaeger, L. Schwaighofer, D. Raumer, F. Geyer, and G. Carle, “Towards a deeper understanding of TCP BBR congestion control,” inProc. of IFIP Networking, 2018
work page 2018
-
[38]
UDT: UDP-based data transfer for high- speed wide area networks,
Y . Gu and R. L. Grossman, “UDT: UDP-based data transfer for high- speed wide area networks,”Computer Networks, vol. 51, no. 7, 2007
work page 2007
-
[39]
Promises and potential of bbrv3,
D. Zeynali, E. N. Weyulu, S. Fathalli, B. Chandrasekaran, and A. Feldmann, “Promises and potential of bbrv3,” inPassive and Active Measurement: 25th International Conference, PAM 2024, Virtual Event, March 11–13, 2024, Proceedings, Part II, 2024. [Online]. Available: https://doi.org/10.1007/978-3-031-56252-5 12
-
[40]
Evaluating tcp bbrv3 performance in wired broadband networks,
J. Gomez, E. F. Kfoury, J. Crichigno, and G. Srivastava, “Evaluating tcp bbrv3 performance in wired broadband networks,”Computer Communications, vol. 222, pp. 198–208, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0140366424001658
work page 2024
-
[41]
Eagle: Refining congestion control by learning from the experts,
S. Emara, B. Li, and Y . Chen, “Eagle: Refining congestion control by learning from the experts,” inProc of IEEE INFOCOM, 2020
work page 2020
-
[42]
Pareto: Fair congestion control with online reinforcement learning,
S. Emara, F. Wang, B. Li, and T. Zeyl, “Pareto: Fair congestion control with online reinforcement learning,”IEEE Transactions on Network Science and Engineering, vol. 9, no. 5, 2022
work page 2022
- [43]
-
[44]
S. Hemminger, “TCP testing (tcpprobe),”The Linux Foundation, http://devresources.linuxfoundation.org/shemminger/tcp, 2011
work page 2011
-
[45]
S. Godard, “SYSSTAT home page,”Information and code available at http://sebastien.godard.pagesperso-orange.fr/index.html, 2015
work page 2015
-
[46]
A network in a laptop: Rapid prototyping for software-defined networks,
B. Lantz, B. Heller, and N. McKeown, “A network in a laptop: Rapid prototyping for software-defined networks,” inProc. of ACM HotNets, 2010
work page 2010
-
[47]
“BBR3 enabled kernel.” [Online]. Available: https://github.com/google/ bbr/blob/v3/net/ipv4/tcp bbr.c#L866
-
[48]
this dataset is used to generate the figures.” [Online]
“The dataset contains measurements collected from many experimentals, of various cc schemes including orca, sage, astraea, pcc vivace (kernel and userspace), cubic, and bbrv3 and bbrv1 in emulated dumbbell and parking-lot topologies. this dataset is used to generate the figures.” [Online]. Available: https://figshare.com/s/97c09c17972fb0ca56b4
-
[49]
Code repository for the experiment and plotting scripts
“Code repository for the experiment and plotting scripts.” [Online]. Available: https://github.com/Aruuni/mininettestbed
-
[50]
Bbrv3: Algorithm bug fixes and public internet deployment,
N. C. Y . C. K. Y . D. M. S. H. Y . P. J. Y . Seung, “Bbrv3: Algorithm bug fixes and public internet deployment,” 2023. [Online]. Available: https://datatracker.ietf.org/meeting/117/materials/ slides-117-ccwg-bbrv3-algorithm-bug-fixes-and-public-internet-deployment-00
work page 2023
-
[51]
Differentiated end-to-end internet services using a weighted proportional fair sharing tcp,
J. Crowcroft and P. Oechslin, “Differentiated end-to-end internet services using a weighted proportional fair sharing tcp,” 1998. 15
work page 1998
-
[52]
Mutant: learning congestion control from existing protocols via online reinforcement learning,
L. Pappone, A. Sacco, and F. Esposito, “Mutant: learning congestion control from existing protocols via online reinforcement learning,” ser. NSDI ’25. USENIX Association, 2025
work page 2025
-
[53]
Orc: Online reinforcement learning for congestion control with fast convergence,
Y . Li, J. Huang, C. Wu, X. Zhu, and J. Wang, “Orc: Online reinforcement learning for congestion control with fast convergence,” inProceedings of the 9th Asia-Pacific Workshop on Networking, ser. APNET ’25,
-
[54]
Available: https://doi.org/10.1145/3735358.3735381
[Online]. Available: https://doi.org/10.1145/3735358.3735381
-
[55]
Achieving fairness generalizability for learning-based congestion control with jury,
H. Tian, X. Liao, D. Sun, C. Zeng, Y . Jin, J. Zhang, X. Wan, Z. Wang, Y . Wang, and K. Chen, “Achieving fairness generalizability for learning-based congestion control with jury,” ser. EuroSys ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3689031.3696065
-
[56]
Experience-driven congestion control: When multi-path TCP meets deep reinforcement learning,
Z. Xu, J. Tang, C. Yin, Y . Wang, and G. Xue, “Experience-driven congestion control: When multi-path TCP meets deep reinforcement learning,”IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, 2019
work page 2019
-
[57]
Multi-objective congestion control,
Y . Ma, H. Tian, X. Liao, J. Zhang, W. Wang, K. Chen, and X. Jin, “Multi-objective congestion control,” inProc. of EuroSys, 2022
work page 2022
-
[58]
Wanna make your tcp scheme great for cellular networks? let machines do it for you!
S. Abbasloo, C.-Y . Yen, and H. J. Chao, “Wanna make your tcp scheme great for cellular networks? let machines do it for you!”IEEE Journal on Selected Areas in Communications, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.