Distributed Precoding for Cell-free Massive MIMO in O-RAN: A Multi-agent Deep Reinforcement Learning Framework
Pith reviewed 2026-05-18 03:48 UTC · model grok-4.3
The pith
A multi-agent reinforcement learning framework for precoding in cell-free massive MIMO achieves throughput similar to centralized methods with lower signaling overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
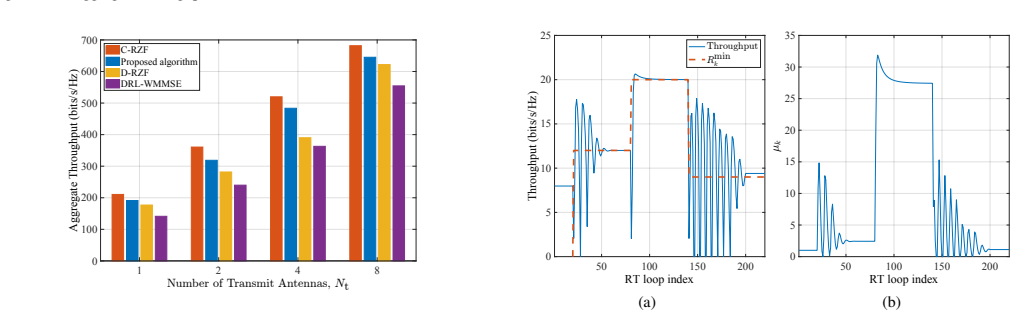
The proposed multi-timescale multi-agent DRL framework determines precoding matrices that achieve higher aggregate throughput than the distributed regularized zero-forcing scheme and the weighted minimum mean square error algorithm, while delivering aggregate throughput comparable to the centralized regularized zero-forcing scheme but with lower signaling overhead.
What carries the argument
Multi-agent deep reinforcement learning combined with expert insights from an iterative algorithm, which lets each agent learn effective precoding matrices from local data and limited shared information to limit inter-unit interference.
If this is right
- The framework scales to larger numbers of O-RUs, users, and antennas while retaining its throughput advantage over other distributed methods.
- It reduces signaling overhead relative to fully centralized precoding while preserving comparable performance.
- It delivers higher total throughput than existing distributed precoding schemes such as D-RZF and WMMSE.
Where Pith is reading between the lines
- The same limited-exchange learning structure could be applied to related O-RAN tasks such as dynamic resource allocation.
- Retraining the agents under time-varying channels would test whether the policies remain effective when users move.
- In very large deployments the reduced information exchange might further lower backhaul load beyond what centralized methods allow.
Load-bearing premise
Multi-agent DRL with expert insights from an iterative algorithm can efficiently solve the nonconvex precoding optimization using only limited information exchange among agents.
What would settle it
Simulations in which the proposed framework produces lower aggregate throughput than D-RZF or WMMSE, or requires higher signaling overhead than C-RZF while matching its throughput.
Figures









read the original abstract
Cell-free massive multiple-input multiple-output (MIMO) is a key technology for next-generation wireless systems. The integration of cell-free massive MIMO within the open radio access network (O-RAN) architecture addresses the growing need for decentralized, scalable, and high-capacity networks that can support different use cases. Precoding is a crucial step in the operation of cell-free massive MIMO, where O-RUs steer their beams towards the intended users while mitigating interference to other users. Current precoding schemes for cell-free massive MIMO are either fully centralized or fully distributed. Centralized schemes are not scalable, whereas distributed schemes may lead to a high inter-O-RU interference. In this paper, we propose a distributed and scalable precoding framework for cell-free massive MIMO that uses limited information exchange among precoding agents to mitigate interference. We formulate an optimization problem for precoding that maximizes the aggregate throughput while guaranteeing the minimum data rate requirements of users. The formulated problem is nonconvex. We propose a multi-timescale framework that combines multi-agent deep reinforcement learning (DRL) with expert insights from an iterative algorithm to determine the precoding matrices efficiently. We conduct simulations and compare the proposed framework with the centralized precoding and distributed precoding methods for different numbers of O-RUs, users, and transmit antennas. The results show that the proposed framework achieves a higher aggregate throughput than the distributed regularized zero-forcing (D-RZF) scheme and the weighted minimum mean square error (WMMSE) algorithm. When compared with the centralized regularized zero-forcing (C-RZF) scheme, the proposed framework achieves similar aggregate throughput performance but with a lower signaling overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-timescale distributed precoding framework for cell-free massive MIMO in O-RAN that combines multi-agent deep reinforcement learning with expert insights from an iterative algorithm. It formulates a non-convex optimization problem to maximize aggregate throughput subject to per-user minimum rate constraints under limited inter-O-RU information exchange. Simulations compare the approach against D-RZF, WMMSE, and C-RZF baselines for varying numbers of O-RUs, users, and antennas, claiming higher sum-rate than the distributed baselines and comparable performance to the centralized scheme with reduced signaling overhead.
Significance. If the performance claims are supported by fully specified and reproducible DRL components that strictly enforce the rate constraints, the work could provide a practical bridge between centralized and distributed precoding, enabling scalable O-RAN deployments with lower overhead while improving upon purely distributed methods.
major comments (3)
- [Problem formulation section] Problem formulation section: The optimization is explicitly stated as maximizing aggregate throughput subject to hard per-user rate lower bounds. The multi-agent DRL reward function and constraint-handling mechanism (e.g., projection, dual update, or soft penalty) are not specified, which is load-bearing because soft penalties common in wireless DRL could permit rate violations in some realizations and thereby inflate the reported throughput gains relative to baselines run under identical hard constraints.
- [Proposed framework section] Proposed framework section: The state and action spaces for the multi-agent DRL agents, the precise multi-timescale structure, the training procedure, and how expert insights from the iterative algorithm are injected are not detailed. These omissions prevent verification of whether the limited-information-exchange claim holds and whether the learned policies are robust outside the training distribution.
- [Simulation results section] Simulation results section: No constraint-violation statistics (e.g., fraction of realizations where any user falls below its minimum rate) are reported for the proposed method, while the central claim rests on satisfying the hard rate constraints. Without these statistics, the aggregate-throughput comparisons to D-RZF and WMMSE cannot be fully interpreted.
minor comments (2)
- [Abstract] The abstract states that simulations cover different numbers of O-RUs, users, and transmit antennas, but the specific parameter values and corresponding figure references should be stated explicitly in the text for clarity.
- [Figures] Figure captions would benefit from including the exact channel model, noise variance, and minimum-rate values used, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and insightful comments on our manuscript. We believe the suggested clarifications will strengthen the paper. We address each major comment below and will incorporate the necessary revisions in the updated version.
read point-by-point responses
-
Referee: [Problem formulation section] The optimization is explicitly stated as maximizing aggregate throughput subject to hard per-user rate lower bounds. The multi-agent DRL reward function and constraint-handling mechanism (e.g., projection, dual update, or soft penalty) are not specified, which is load-bearing because soft penalties common in wireless DRL could permit rate violations in some realizations and thereby inflate the reported throughput gains relative to baselines run under identical hard constraints.
Authors: We agree with the referee that the details of the multi-agent DRL reward function and the constraint-handling mechanism need to be more clearly specified to ensure the hard rate constraints are enforced. In the revised manuscript, we will provide a detailed description of these components in the problem formulation section, including how the reward is designed to penalize violations and the specific technique used to handle the constraints. This will confirm that the throughput comparisons are made under identical hard constraints. revision: yes
-
Referee: [Proposed framework section] The state and action spaces for the multi-agent DRL agents, the precise multi-timescale structure, the training procedure, and how expert insights from the iterative algorithm are injected are not detailed. These omissions prevent verification of whether the limited-information-exchange claim holds and whether the learned policies are robust outside the training distribution.
Authors: We acknowledge that the current description of the proposed framework lacks sufficient detail on these aspects. We will revise the proposed framework section to include comprehensive specifications of the state and action spaces, the multi-timescale operation, the training algorithm including hyperparameters, and the method for integrating expert insights from the iterative algorithm. This will allow readers to verify the limited information exchange and robustness claims. revision: yes
-
Referee: [Simulation results section] No constraint-violation statistics (e.g., fraction of realizations where any user falls below its minimum rate) are reported for the proposed method, while the central claim rests on satisfying the hard rate constraints. Without these statistics, the aggregate-throughput comparisons to D-RZF and WMMSE cannot be fully interpreted.
Authors: We agree that reporting constraint violation statistics is essential to substantiate the claims. In the revised simulation results section, we will add statistics showing the percentage of simulation realizations where the minimum rate constraints are violated for the proposed method. This will demonstrate that our approach maintains the hard constraints while achieving the reported performance gains. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper formulates a standard non-convex precoding optimization (max sum-rate subject to per-user rate minima) and proposes a multi-agent DRL plus expert-iteration hybrid as a practical solver under limited signaling. Central performance claims rest on explicit comparisons to independent baselines (D-RZF, WMMSE, C-RZF) run under the same simulation setup. No quoted equation reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the DRL training/evaluation loop is the standard supervised simulation methodology for such frameworks and does not constitute a self-definitional or fitted-input reduction. External benchmarks supply independent grounding, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate an optimization problem for precoding that maximizes the aggregate throughput while guaranteeing the minimum data rate requirements of users. The formulated problem is nonconvex. We reformulate it as an equivalent WMMSE problem... apply the BCD approach...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-agent deep reinforcement learning (DRL) with expert insights from an iterative algorithm to determine the precoding matrices efficiently
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. H. Shokouhi and V . W.S. Wong, “Distributed precoding for eMBB and URLLC traffic in cell-free O-RAN: A multi-agent reinforcement learning framework,” inProc. IEEE Int. Conf. Commun. (ICC), Mon- treal, Canada, Jun. 2025
work page 2025
-
[2]
Un- derstanding O-RAN: Architecture, interfaces, algorithms, security, and research challenges,
M. Polese, L. Bonati, S. D’Oro, S. Basagni, and T. Melodia, “Un- derstanding O-RAN: Architecture, interfaces, algorithms, security, and research challenges,”IEEE Commun. Surveys & Tuts., vol. 25, no. 2, pp. 1376–1411, second quarter 2023
work page 2023
-
[3]
O-RAN architecture description,
O-RAN Alliance, “O-RAN architecture description,” Technical Specifi- cation TS OAD WG1 R004 V13.0, Feb. 2025
work page 2025
-
[4]
O-RAN control, user and synchronization plane specification,
——, “O-RAN control, user and synchronization plane specification,” Technical Specification TS CUS WG4 R004 V17.01, Feb. 2025
work page 2025
-
[5]
Study on new radio access technology: Radio access architecture and interfaces (Release 14),
3GPP, “Study on new radio access technology: Radio access architecture and interfaces (Release 14),” Technical Report TR 38.801 V14.0.0, Mar. 2017
work page 2017
-
[6]
O-RAN near-RT RIC architecture,
O-RAN Alliance, “O-RAN near-RT RIC architecture,” Technical Spec- ification TS RICARCH WG3 R004 V7.0, Feb. 2025
work page 2025
-
[7]
dApps: Enabling real-time AI-based open RAN control,
A. Lacava, L. Bonati, N. Mohamadi, R. Gangula, F. Kaltenberger, P. Johari, S. D’Oro, F. Cuomo, M. Polese, and T. Melodia, “dApps: Enabling real-time AI-based open RAN control,”Comput. Netw., vol. 269, pp. 1–18, Sep. 2025
work page 2025
-
[8]
TailO-RAN: O-RAN control on scheduler parameters to tailor RAN performance,
N. Longhi, S. D’Oro, L. Bonati, M. Polese, R. Verdone, and T. Melodia, “TailO-RAN: O-RAN control on scheduler parameters to tailor RAN performance,”arXiv preprint arXiv:2508.12112, pp. 1–6, Aug. 2025
-
[9]
Coexistence of eMBB and URLLC in open radio access networks: A distributed learning framework,
M. Alsenwi, E. Lagunas, and S. Chatzinotas, “Coexistence of eMBB and URLLC in open radio access networks: A distributed learning framework,” inProc. IEEE Global Commun. Conf. (GLOBECOM), Rio de Janeiro, Brazil, Dec. 2022
work page 2022
-
[10]
Cell-free massive MIMO versus small cells,
H. Q. Ngo, A. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta, “Cell-free massive MIMO versus small cells,”IEEE Trans. Wireless Commun., vol. 16, no. 3, pp. 1834–1850, Mar. 2017
work page 2017
-
[11]
¨O. T. Demir, M. Masoudi, E. Bj ¨ornson, and C. Cavdar, “Cell-free massive MIMO in O-RAN: Energy-aware joint orchestration of cloud, fronthaul, and radio resources,”IEEE J. Sel. Areas Commun., vol. 42, no. 2, pp. 356–372, Feb. 2024
work page 2024
-
[12]
A decentralized pilot assignment algorithm for scalable O- RAN cell-free massive MIMO,
M. S. Oh, A. B. Das, S. Hosseinalipour, T. Kim, D. J. Love, and C. G. Brinton, “A decentralized pilot assignment algorithm for scalable O- RAN cell-free massive MIMO,”IEEE J. Sel. Areas Commun., vol. 42, no. 2, pp. 373–388, Feb. 2024
work page 2024
-
[13]
Q. Shi, M. Razaviyayn, Z.-Q. Luo, and C. He, “An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel,”IEEE Trans. Signal Process., vol. 59, no. 9, pp. 4331–4340, Sep. 2011
work page 2011
-
[14]
MIMO precoding design with QoS and per-antenna power constraints,
K. Chi, Y . Huang, Q. Yang, Z. Yang, and Z. Zhang, “MIMO precoding design with QoS and per-antenna power constraints,” inProc. IEEE Global Commun. Conf. (GLOBECOM), Kuala Lumpur, Malaysia, Dec. 2023
work page 2023
-
[15]
Deep reinforcement learning for distributed dynamic MISO downlink-beamforming coordination,
J. Ge, Y .-C. Liang, J. Joung, and S. Sun, “Deep reinforcement learning for distributed dynamic MISO downlink-beamforming coordination,” IEEE Trans. Commun., vol. 68, no. 10, pp. 6070–6085, Oct. 2020
work page 2020
-
[16]
Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems,
H. Lee and J. Jeong, “Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems,” inProc. IEEE Global Commun. Conf. (GLOBECOM), Madrid, Spain, Dec. 2021
work page 2021
-
[17]
Deep reinforcement learning for energy-efficient beamforming design in cell-free networks,
W. Li, W. Ni, H. Tian, and M. Hua, “Deep reinforcement learning for energy-efficient beamforming design in cell-free networks,” inProc. IEEE Wireless Commun. Netw. Conf. Workshops (WCNCW), Nanjing, China, Mar. 2021
work page 2021
-
[18]
End-to-end deep learning for TDD MIMO systems in the 6G upper midbands,
J. Park, F. Sohrabi, A. Ghosh, and J. G. Andrews, “End-to-end deep learning for TDD MIMO systems in the 6G upper midbands,”IEEE Trans. Wireless Commun., vol. 24, no. 3, pp. 2110–2125, Mar. 2025
work page 2025
-
[19]
Deep learning for multi-user MIMO systems: Joint design of pilot, limited feedback, and precoding,
J. Jang, H. Lee, I.-M. Kim, and I. Lee, “Deep learning for multi-user MIMO systems: Joint design of pilot, limited feedback, and precoding,” IEEE Trans. Commun., vol. 70, no. 11, pp. 7279–7293, Nov. 2022
work page 2022
-
[20]
Y . Huang, K. Chi, Q. Yang, Z. Yang, and Z. Zhang, “Soft actor-critic- based multi-user multi-TTI MIMO precoding in multi-modal real-time broadband communications,”IEEE Trans. Wireless Commun, vol. 23, no. 12, pp. 18 286–18 301, Dec. 2024
work page 2024
-
[21]
Q. Hu, Y . Cai, Q. Shi, K. Xu, G. Yu, and Z. Ding, “Iterative algorithm induced deep-unfolding neural networks: Precoding design for multiuser MIMO systems,”IEEE Trans. Wireless Commun., vol. 20, no. 2, pp. 1394–1410, Feb. 2021
work page 2021
-
[22]
J. Ge, Y .-C. Liang, L. Zhang, R. Long, and S. Sun, “Deep reinforcement learning for distributed dynamic coordinated beamforming in massive MIMO cellular networks,”IEEE Trans. Wireless Commun., vol. 23, no. 5, pp. 4155–4169, May 2024
work page 2024
-
[23]
Generalized reduced-WMMSE approach for cell-free massive MIMO with per-AP power constraints,
W. Yoo, D. Yu, H. Lee, and S.-H. Park, “Generalized reduced-WMMSE approach for cell-free massive MIMO with per-AP power constraints,” IEEE Wireless Commun. Letters, vol. 13, no. 10, pp. 2682–2686, Oct. 2024
work page 2024
-
[24]
Distributed pilot assignment, user association, and precoding for cell-free massive MIMO in O-RAN,
M. H. Shokouhi and V . W.S. Wong, “Distributed pilot assignment, user association, and precoding for cell-free massive MIMO in O-RAN,” submitted toIEEE Int. Conf. Comput. Commun. (INFOCOM), Tokyo, Japan, May 2026
work page 2026
-
[25]
WMMSE beamforming for user-centric cell-free networks with non-coherent joint transmission,
X. Wang, X. Zhao, J. Wang, and Q. Shi, “WMMSE beamforming for user-centric cell-free networks with non-coherent joint transmission,” inProc. IEEE Global Commun. Conf. (GLOBECOM), Kuala Lumpur, Malaysia, Dec. 2023
work page 2023
-
[26]
Joint spectrum, precoding, and phase shifts design for RIS-aided multiuser MIMO THz systems,
A. Mehrabian and V . W.S. Wong, “Joint spectrum, precoding, and phase shifts design for RIS-aided multiuser MIMO THz systems,”IEEE Trans. Commun., vol. 72, no. 8, pp. 5087–5101, Aug. 2024
work page 2024
-
[27]
D. P. Bertsekas,Nonlinear Programming, 3rd ed. Athena Scientific, 2016
work page 2016
-
[28]
S. P. Boyd and L. Vandenberghe,Convex Optimization. Cambridge Univ. Press, 2004
work page 2004
-
[29]
Downlink power control for cell-free massive MIMO with deep reinforcement learning,
L. Luo, J. Zhang, S. Chen, X. Zhang, B. Ai, and D. W. K. Ng, “Downlink power control for cell-free massive MIMO with deep reinforcement learning,”IEEE Trans. V eh. Technol., vol. 71, no. 6, pp. 6772–6777, Jun. 2022
work page 2022
-
[30]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inProc. Int. Conf. Mach. Learn. (ICML), Stockholm, Sweden, Jul. 2018
work page 2018
-
[31]
3GPP, “Evolved universal terrestrial radio access (E-UTRA); further ad- vancements for E-UTRA physical layer aspects (Release 9),” Technical Report TR 36.814 V9.2.0, Mar. 2017
work page 2017
-
[32]
BenchMARL: Benchmarking multi-agent reinforcement learning,
M. Bettini, A. Prorok, and V . Moens, “BenchMARL: Benchmarking multi-agent reinforcement learning,”J. Mach. Learn. Res., vol. 25, no. 217, pp. 1–10, Jul. 2024
work page 2024
-
[33]
TorchRL: A data-driven decision- making library for PyTorch,
A. Bou, M. Bettini, S. Dittert, V . Kumar, S. Sodhani, X. Yang, G. De Fabritiis, and V . Moens, “TorchRL: A data-driven decision- making library for PyTorch,” inProc. Int. Conf. Learn. Represent. (ICLR), Vienna, Austria, May 2024
work page 2024
-
[34]
Learning- based precoding-aware radio resource scheduling for cell-free mMIMO networks,
A. Girycki, M. A. Rahman, E. Vinogradov, and S. Pollin, “Learning- based precoding-aware radio resource scheduling for cell-free mMIMO networks,”IEEE Trans. Wireless Commun., vol. 23, no. 5, pp. 4876– 4888, May 2024
work page 2024
-
[35]
K. B. Petersen and M. S. Pedersen,The Matrix Cookbook, Technical University of Denmark, 2012. [Online]. Available: http://www2.compute.dtu.dk/pubdb/pubs/3274-full.html
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.