Joint Optimization of DNN Model Caching and Request Routing in Mobile Edge Computing
Pith reviewed 2026-05-18 02:00 UTC · model grok-4.3
The pith
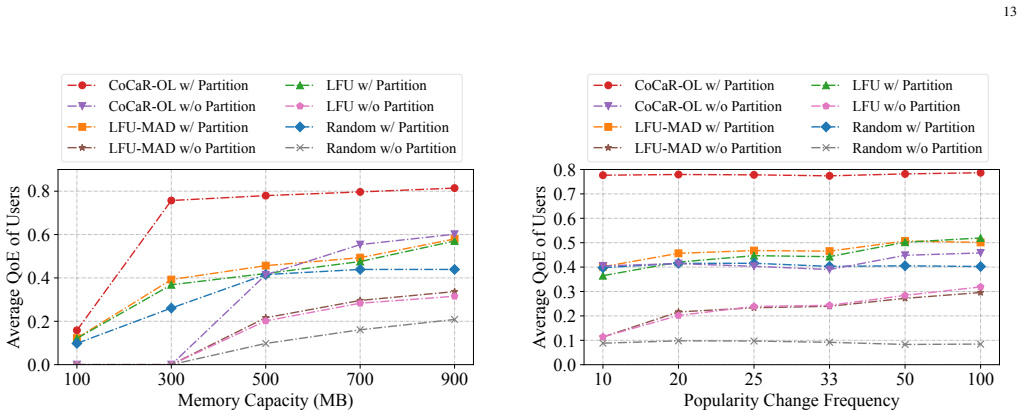
Disassembling DNNs into submodels for joint caching and routing in edge networks raises average inference precision by 46%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In mobile edge computing networks, disassembling complete DNN models into interrelated submodels enables fine-grained caching and request routing that maximizes user request inference precision subject to server resource, latency, and model loading time constraints. The CoCaR algorithm, based on linear programming and random rounding, achieves near-optimal performance offline, while its online variant CoCaR-OL adapts to unpredictable request patterns and delivers at least 32.3% higher user QoE than competitive baselines.
What carries the argument
Joint optimization of submodel caching and request routing for dynamic DNNs, solved by linear programming with random rounding in the CoCaR algorithm.
If this is right
- Average inference precision across user requests rises by 46% relative to prior approaches.
- Online scenarios achieve at least 32.3% improvement in user quality of experience.
- Caching becomes more efficient because only needed submodels occupy limited server storage.
- Routing can steer requests toward servers holding the submodels that deliver the highest feasible precision for each query.
- Solutions stay close to the theoretical optimum while respecting capacity, delay, and loading-time limits.
Where Pith is reading between the lines
- The same modular decomposition idea could apply to other model families such as transformers if they admit clean submodel boundaries.
- Real hardware testbeds would likely expose mobility and interference effects absent from the current simulations.
- Energy use at edge servers may drop when fewer parameters are loaded per request.
- Combining the optimizer with request forecasting could reduce loading events still further.
Load-bearing premise
Breaking full DNN models into interrelated submodels produces useful trade-offs between inference precision and loading latency without introducing unmodeled accuracy penalties or extra overheads.
What would settle it
A controlled measurement on real edge hardware showing that submodel-based inference yields no net precision gain or produces higher total latency than full-model baselines under identical request loads.
Figures










read the original abstract
Mobile edge computing (MEC) can pre-cache deep neural networks (DNNs) near end-users, providing low-latency services and improving users' quality of experience (QoE). However, caching all DNN models at edge servers with limited capacity is difficult, and the impact of model loading time on QoE remains underexplored. Hence, we introduce dynamic DNNs in edge scenarios, disassembling a complete DNN model into interrelated submodels for more fine-grained and flexible model caching and request routing solutions. This raises the pressing issue of jointly deciding request routing and submodel caching for dynamic DNNs to balance model inference precision and loading latency for QoE optimization. In this paper, we study the joint dynamic model caching and request routing problem in MEC networks, aiming to maximize user request inference precision under constraints of server resources, latency, and model loading time. To tackle this problem, we propose CoCaR, an offline algorithm based on linear programming and random rounding that leverages dynamic DNNs to optimize caching and routing schemes, achieving near-optimal performance. Furthermore, we develop an online variant of CoCaR, named CoCaR-OL, enabling effective adaptation to dynamic and unpredictable online request patterns. The simulation results demonstrate that the proposed CoCaR improves the average inference precision of user requests by 46% compared to state-of-the-art baselines. In addition, in online scenarios, CoCaR-OL achieves an improvement of no less than 32.3% in user QoE over competitive baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoCaR, an offline algorithm based on linear programming and random rounding, together with its online variant CoCaR-OL, for jointly optimizing submodel caching and request routing of dynamic DNNs in MEC networks. The goal is to maximize average inference precision subject to server capacity, latency, and model-loading-time constraints; the abstract reports that CoCaR yields a 46% gain in inference precision and CoCaR-OL yields at least 32.3% QoE improvement over baselines in simulations.
Significance. If the submodel precision model is accurate and the reported gains prove robust under proper statistical validation, the work would usefully extend MEC caching literature by exposing a controllable precision-latency trade-off that standard whole-model caching cannot exploit. The explicit treatment of loading latency as a first-class QoE factor is a constructive contribution.
major comments (2)
- [Abstract] Abstract: the headline claims of 46% precision improvement and 32.3% QoE improvement rest on simulation comparisons whose experimental setup, number of runs, statistical tests, baseline implementations, and sensitivity to the precision-latency trade-off weight are not described. Without these details the central performance assertions cannot be evaluated and may be sensitive to unstated parameter choices.
- [Problem Formulation] Problem Formulation (and the modeling of dynamic DNNs): the premise that disassembling a DNN into interrelated submodels yields a monotonic, controllable precision-versus-latency mapping free of unmodeled inter-submodel accuracy penalties or early-exit overheads is introduced without separate validation or sensitivity analysis. Because this mapping is directly encoded in the LP objective and constraints, any deviation in real submodel accuracy would render the reported gains artifacts of the simulation rather than evidence of effective joint decisions.
minor comments (1)
- [System Model] Clarify how the precision function for each submodel is obtained or fitted and whether it is treated as an input parameter or derived from the model architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for improving the clarity and robustness of our claims. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 46% precision improvement and 32.3% QoE improvement rest on simulation comparisons whose experimental setup, number of runs, statistical tests, baseline implementations, and sensitivity to the precision-latency trade-off weight are not described. Without these details the central performance assertions cannot be evaluated and may be sensitive to unstated parameter choices.
Authors: We agree that the abstract and experimental evaluation section require expanded details to support the reported gains. In the revised manuscript we will add a dedicated subsection on the simulation methodology. This will specify the number of independent runs (20 runs using distinct random seeds), the use of 95% confidence intervals and paired t-tests for statistical significance, the exact parameter settings and code-level implementations of all baselines, and a sensitivity study sweeping the precision-latency trade-off weight over [0.1, 10]. These additions will make the 46% precision and 32.3% QoE improvements reproducible and allow readers to assess robustness directly. revision: yes
-
Referee: [Problem Formulation] Problem Formulation (and the modeling of dynamic DNNs): the premise that disassembling a DNN into interrelated submodels yields a monotonic, controllable precision-versus-latency mapping free of unmodeled inter-submodel accuracy penalties or early-exit overheads is introduced without separate validation or sensitivity analysis. Because this mapping is directly encoded in the LP objective and constraints, any deviation in real submodel accuracy would render the reported gains artifacts of the simulation rather than evidence of effective joint decisions.
Authors: The monotonic precision-latency mapping follows from the modular structure of dynamic DNNs documented in the literature (e.g., early-exit and layer-wise decomposition papers). Nevertheless, we accept that explicit validation is needed. The revised manuscript will contain a new sensitivity-analysis subsection that perturbs the precision values with additive noise and multiplicative penalties simulating inter-submodel overheads. We will re-run CoCaR and CoCaR-OL under these perturbed models and report the resulting degradation (or retention) of the performance gains. This will quantify how sensitive the joint optimization remains when the ideal mapping is relaxed. revision: yes
Circularity Check
No significant circularity; claims rest on external simulation benchmarks
full rationale
The paper formulates a joint optimization problem for submodel caching and request routing in MEC using linear programming with random rounding for the offline CoCaR algorithm and an online variant CoCaR-OL. Central performance claims (46% precision gain, 32.3% QoE gain) are obtained via direct simulation comparisons against independent baselines rather than any quantity that reduces by the paper's own equations to a fitted parameter or self-citation. The submodel precision-latency tradeoff is introduced as a modeling premise when dynamic DNNs are defined, but it is not shown to be self-definitional or derived from the optimization output itself. No load-bearing self-citation chains, ansatz smuggling, or renaming of known results appear in the provided derivation steps; the work remains self-contained against the stated simulation benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- precision-latency trade-off weight
invented entities (1)
-
dynamic DNN submodels
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
max sum A_n,u,h · p_h s.t. memory, latency, loading-time constraints; CoCaR uses LP + multinoulli rounding on x† and ϕ† = A†/x†
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p_h values taken from trained ViT submodels (0.8417, 0.9413, 0.9894); no derivation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CoCaR: Enabling efficient dynamic DNN-based model caching and request routing in MEC,
S. Qiu, F. Dong, S. Tan, D. Shen, R. Zhou, and Q. Fan, “CoCaR: Enabling efficient dynamic DNN-based model caching and request routing in MEC,” inproc. IEEE INFOCOM, London, United Kingdom, May, 2025, pp. 1–10
work page 2025
-
[2]
DeepSniffer: A DNN model extraction framework based on learning architectural hints,
X. Hu, L. Liang, S. Li, L. Deng, P. Zuo, Y . Ji, X. Xie, Y . Ding, C. Liu, T. Sherwoodet al., “DeepSniffer: A DNN model extraction framework based on learning architectural hints,” inproc. ACM 25th ASPLOS, New York, USA, Mar, 2020, pp. 385–399
work page 2020
-
[3]
T. Wang, L. Shen, Q. Fan, T. Xu, T. Liu, and H. Xiong, “Joint admission control and resource allocation of virtual network embedding via hierarchical deep reinforcement learning,”IEEE Transactions on Services Computing, vol. 17, no. 03, pp. 1001–1015, 2024
work page 2024
-
[4]
Edge- assisted adaptive configuration for serverless-based video analytics,
Z. Wang, R. Zhang, S. Zhang, W. Cheng, W. Wang, and Y . Cui, “Edge- assisted adaptive configuration for serverless-based video analytics,” IEEE Transactions on Networking, vol. 33, no. 3, pp. 1144–1159, 2025
work page 2025
-
[5]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017
work page 2017
-
[6]
Advancing RNN transducer technology for speech recognition,
G. Saon, Z. Tüske, D. Bolanos, and B. Kingsbury, “Advancing RNN transducer technology for speech recognition,” inproc. IEEE ICASSP, Toronto, Canada, Jun, 2021, pp. 5654–5658
work page 2021
-
[7]
Confidence-aware reinforcement learning for self-driving cars,
Z. Cao, S. Xu, H. Peng, D. Yang, and R. Zidek, “Confidence-aware reinforcement learning for self-driving cars,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 7, pp. 7419–7430, 2021
work page 2021
-
[8]
Mobile edge computing and machine learning in the internet of unmanned aerial vehicles: a survey,
Z. Ning, H. Hu, X. Wang, L. Guo, S. Guo, G. Wang, and X. Gao, “Mobile edge computing and machine learning in the internet of unmanned aerial vehicles: a survey,”ACM Computing Surveys, vol. 56, no. 1, pp. 1–31, 2023
work page 2023
-
[9]
Rein- forcement learning for cost-effective IoT service caching at the edge,
B. Huang, X. Liu, Y . Xiang, D. Yu, S. Deng, and S. Wang, “Rein- forcement learning for cost-effective IoT service caching at the edge,” Journal of Parallel and Distributed Computing, vol. 168, pp. 120–136, 2022
work page 2022
-
[10]
R. Zhang, R. Zhou, Y . Wang, H. Tan, and K. He, “Incentive mechanisms for online task offloading with privacy-preserving in UA V-assisted mo- bile edge computing,”IEEE/ACM Transactions on Networking, vol. 32, no. 3, pp. 2646–2661, 2024
work page 2024
-
[11]
Mean field graph based D2D collab- oration and offloading pricing in mobile edge computing,
X. Wang, J. Ye, and J. C. Lui, “Mean field graph based D2D collab- oration and offloading pricing in mobile edge computing,”IEEE/ACM Transactions on Networking, vol. 32, no. 1, pp. 491–505, 2023
work page 2023
-
[12]
FEAT: Towards fast environment-adaptive task offloading and power allocation in MEC,
T. Ren, Z. Hu, H. He, J. Niu, and X. Liu, “FEAT: Towards fast environment-adaptive task offloading and power allocation in MEC,” inproc. IEEE INFOCOM, New York City, USA, May, 2023, pp. 1–10
work page 2023
-
[13]
Near-optimal and collaborative service caching in mobile edge clouds,
Z. Xu, L. Zhou, S. C.-K. Chau, W. Liang, H. Dai, L. Chen, W. Xu, Q. Xia, and P. Zhou, “Near-optimal and collaborative service caching in mobile edge clouds,”IEEE Transactions on Mobile Computing, vol. 22, no. 7, pp. 4070–4085, 2023
work page 2023
-
[14]
Asymptotically tight approximation for online file caching with delayed hits and bypassing,
H. Tan, Y . Wang, C. Zhang, G. Li, H. Du, Z. Han, S. H.-C. Jiang, and X.-Y . Li, “Asymptotically tight approximation for online file caching with delayed hits and bypassing,”IEEE Transactions on Networking, vol. 33, no. 4, pp. 1886–1899, 2025
work page 2025
-
[15]
Two time-scale joint service caching and task offloading for UA V-assisted mobile edge computing,
R. Zhou, X. Wu, H. Tan, and R. Zhang, “Two time-scale joint service caching and task offloading for UA V-assisted mobile edge computing,” inproc. IEEE INFOCOM, London, United Kingdom, May, 2022, pp. 1189–1198
work page 2022
-
[16]
Dynamic resource allocation for deep learning clusters with separated compute and storage,
M. Li, Z. Han, C. Zhang, R. Zhou, Y . Liu, and H. Tan, “Dynamic resource allocation for deep learning clusters with separated compute and storage,” inproc. IEEE INFOCOM, New York City, USA, May, 2023, pp. 1–10
work page 2023
-
[17]
Offloading tasks with dependency and service caching in mobile edge computing,
G. Zhao, H. Xu, Y . Zhao, C. Qiao, and L. Huang, “Offloading tasks with dependency and service caching in mobile edge computing,”IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 11, pp. 2777–2792, 2021
work page 2021
-
[18]
Joint optimization of base station clustering and service caching in user-centric MEC,
L. Qin, H. Lu, Y . Lu, C. Zhang, and F. Wu, “Joint optimization of base station clustering and service caching in user-centric MEC,”IEEE Transactions on Mobile Computing, vol. 23, no. 5, pp. 6455–6469, 2023
work page 2023
-
[19]
W. Chu, X. Jia, Z. Yu, J. C. Lui, and Y . Lin, “Joint service caching, re- source allocation and task offloading for MEC-based networks: A multi- layer optimization approach,”IEEE Transactions on Mobile Computing, vol. 23, no. 4, pp. 2958–2975, 2024
work page 2024
-
[20]
Toward deterministic wide-area networks via deadline-aware routing and scheduling,
J. Ren, W. Zhang, H. Wang, D. Yang, S. Wang, H. Zhang, and S. Cui, “Toward deterministic wide-area networks via deadline-aware routing and scheduling,”IEEE Transactions on Networking, vol. 33, no. 4, pp. 1762–1778, 2025
work page 2025
-
[21]
FlagVNE: A flexible and generalizable RL framework for network resource allocation,
T. Wang, Q. Fan, C. Wang, L. Ding, N. J. Yuan, and H. Xiong, “FlagVNE: A flexible and generalizable RL framework for network resource allocation,” inproc. 33rd IJCAI, 2024
work page 2024
-
[22]
K. Poularakis, J. Llorca, A. M. Tulino, I. Taylor, and L. Tassiulas, “Service placement and request routing in MEC networks with storage, computation, and communication constraints,”IEEE/ACM Transactions on Networking, vol. 28, no. 3, pp. 1047–1060, 2020
work page 2020
-
[23]
G. Zhang, S. Zhang, W. Zhang, Z. Shen, and L. Wang, “Joint service caching, computation offloading and resource allocation in mobile edge computing systems,”IEEE Transactions on Wireless Communications, vol. 20, no. 8, pp. 5288–5300, 2021
work page 2021
-
[24]
Deep reinforcement learning for task offloading in mobile edge computing systems,
M. Tang and V . W. Wong, “Deep reinforcement learning for task offloading in mobile edge computing systems,”IEEE Transactions on Mobile Computing, vol. 21, no. 6, pp. 1985–1997, 2020
work page 1985
-
[26]
K. Peng, L. Wang, J. He, C. Cai, and M. Hu, “Joint optimization of service deployment and request routing for microservices in mobile edge computing,”IEEE Transactions on Services Computing, vol. 17, no. 3, pp. 1016–1028, 2024
work page 2024
-
[27]
P. Wang, T. Ouyang, G. Liao, J. Gong, S. Yu, and X. Chen, “Edge intelligence in motion: Mobility-aware dynamic DNN inference service migration with downtime in mobile edge computing,”Journal of Systems Architecture, vol. 130, p. 102664, 2022
work page 2022
-
[28]
W. Lou, L. Xun, A. Sabet, J. Bi, J. Hare, and G. V . Merrett, “Dynamic- OFA: Runtime DNN architecture switching for performance scaling on heterogeneous embedded platforms,” inproc. IEEE/CVF CVPR, Nashville, USA, Jun, 2021, pp. 3110–3118
work page 2021
-
[29]
Distributing inference tasks over interconnected systems through dy- 16 namic DNNs,
C. Singhal, Y . Wu, F. Malandrino, M. Levorato, and C. F. Chiasserini, “Distributing inference tasks over interconnected systems through dy- 16 namic DNNs,”IEEE Transactions on Networking, vol. 33, no. 4, pp. 1717–1730, 2025
work page 2025
-
[30]
Z. Liu, H. Du, J. Lin, Z. Gao, L. Huang, S. Hosseinalipour, and D. Niyato, “Dnn partitioning, task offloading, and resource allocation in dynamic vehicular networks: A lyapunov-guided diffusion-based rein- forcement learning approach,”IEEE Transactions on Mobile Computing, vol. 24, no. 3, pp. 1945–1962, 2025
work page 1945
-
[31]
Distributed dnn inference with fine-grained model partitioning in mobile edge computing networks,
H. Li, X. Li, Q. Fan, Q. He, X. Wang, and V . C. Leung, “Distributed dnn inference with fine-grained model partitioning in mobile edge computing networks,”IEEE Transactions on Mobile Computing, vol. 23, no. 10, pp. 9060–9074, 2024
work page 2024
-
[32]
OA-Cache: Oracle approximation-based cache replacement at the network edge,
S. Qiu, Q. Fan, X. Li, X. Zhang, G. Min, and Y . Lyu, “OA-Cache: Oracle approximation-based cache replacement at the network edge,” IEEE Transactions on Network and Service Management, vol. 20, no. 3, pp. 3177–3189, 2023
work page 2023
-
[33]
Loading cost-aware model caching and request routing in edge-enabled wireless sensor networks,
M. Yao, L. Chen, Y . Wu, and J. Wu, “Loading cost-aware model caching and request routing in edge-enabled wireless sensor networks,”The Computer Journal, vol. 66, no. 10, pp. 2409–2425, 2023
work page 2023
-
[34]
Loading cost-aware model caching and request routing for cooperative edge inference,
M. Yao, L. Chen, J. Zhang, J. Huang, and J. Wu, “Loading cost-aware model caching and request routing for cooperative edge inference,” in proc. IEEE ICC, Seoul, Korea, Republic of, May, 2022, pp. 2327–2332
work page 2022
-
[35]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inproc. 9th ICLR. Virtual Event: OpenReview.net, May, 2021
work page 2021
-
[36]
T. Ouyang, K. Zhao, G. Hong, X. Zhang, Z. Zhou, and X. Chen, “Dy- namic edge-centric resource provisioning for online and offline services co-location via reactive and predictive approaches,”IEEE Transactions on Networking, vol. 33, no. 3, pp. 1388–1403, 2025
work page 2025
-
[37]
Collaborative service placement for edge computing in dense small cell networks,
L. Chen, C. Shen, P. Zhou, and J. Xu, “Collaborative service placement for edge computing in dense small cell networks,”IEEE Transactions on Mobile Computing, vol. 20, no. 2, pp. 377–390, 2019
work page 2019
-
[38]
Efficient inverse maintenance and faster algorithms for linear programming,
Y . T. Lee and A. Sidford, “Efficient inverse maintenance and faster algorithms for linear programming,” inproc. IEEE 56th FOCS, Berkeley, USA, Oct, 2015, pp. 230–249
work page 2015
-
[39]
M. Mitzenmacher and E. Upfal,Probability and computing: Random- ization and probabilistic techniques in algorithms and data analysis. Cambridge university press, 2017
work page 2017
-
[40]
Fast-response edge caching scheme for graph data,
P. Wang, S. Li, Y . Han, F. Ye, and Q. Zhang, “Fast-response edge caching scheme for graph data,”IEEE Transactions on Networking, vol. 33, no. 4, pp. 1962–1975, 2025
work page 1962
-
[41]
Multi-user layer- aware online container migration in edge-assisted vehicular networks,
Z. Tang, F. Mou, J. Lou, W. Jia, Y . Wu, and W. Zhao, “Multi-user layer- aware online container migration in edge-assisted vehicular networks,” IEEE/ACM Transactions on Networking, vol. 32, no. 2, pp. 1807–1822, 2023
work page 2023
-
[42]
On the evolution of random graphs,
P. Erd ˝os, A. Rényiet al., “On the evolution of random graphs,”Publ. math. inst. hung. acad. sci, vol. 5, no. 1, pp. 17–60, 1960
work page 1960
-
[43]
Swin Transformer: Hierarchical vision transformer using shifted win- dows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical vision transformer using shifted win- dows,” inproc. IEEE/CVF ICCV, Virtual Event, Oct, 2021, pp. 10 012– 10 022
work page 2021
-
[44]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,”Master’s thesis, Department of Computer Science, University of Toronto, 2009
work page 2009
-
[45]
FemtoCaching: Wireless content delivery through distributed caching helpers,
K. Shanmugam, N. Golrezaei, A. G. Dimakis, A. F. Molisch, and G. Caire, “FemtoCaching: Wireless content delivery through distributed caching helpers,”IEEE Transactions on Information Theory, vol. 59, no. 12, pp. 8402–8413, 2013
work page 2013
-
[46]
Z. Yao, S. Xia, Y . Li, and G. Wu, “Cooperative task offloading and service caching for digital twin edge networks: A graph attention multi- agent reinforcement learning approach,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 11, pp. 3401–3413, 2023
work page 2023
-
[47]
Improving proxy cache performance: Analysis of three replacement policies,
J. Dilley and M. Arlitt, “Improving proxy cache performance: Analysis of three replacement policies,”IEEE Internet Computing, vol. 3, no. 6, pp. 44–50, 2002
work page 2002
-
[48]
N. Atre, J. Sherry, W. Wang, and D. S. Berger, “Caching with delayed hits,” inproc. ACM SIGCOMM, Virtual Event USA, Jul, 2020, pp. 495– 513
work page 2020
-
[49]
S. Bi, L. Huang, and Y . J. A. Zhang, “Joint optimization of service caching placement and computation offloading in mobile edge comput- ing systems,”IEEE Transactions on Wireless Communications, vol. 19, no. 7, pp. 4947–4963, 2020
work page 2020
-
[50]
Mutu- alNet: Adaptive convnet via mutual learning from network width and resolution,
T. Yang, S. Zhu, C. Chen, S. Yan, M. Zhang, and A. Willis, “Mutu- alNet: Adaptive convnet via mutual learning from network width and resolution,” inproc. ECCV. Glasgow, UK: Springer, Aug, 2020, pp. 299–315
work page 2020
-
[51]
Multi-scale dense networks for resource efficient image classification,
G. Huang, D. Chen, T. Li, F. Wu, L. van der Maaten, and K. Weinberger, “Multi-scale dense networks for resource efficient image classification,” inproc. ICLR. Vancouver, Canada: OpenReview.net, Apr, 2018
work page 2018
-
[52]
Subflow: A dynamic induced-subgraph strategy toward real-time DNN inference and training,
S. Lee and S. Nirjon, “Subflow: A dynamic induced-subgraph strategy toward real-time DNN inference and training,” inproc. IEEE RTAS, Sydney, Australia, Apr, 2020, pp. 15–29
work page 2020
-
[53]
Z. Pan, J. Cai, and B. Zhuang, “Stitchable neural networks,” inproc. IEEE/CVF CVPR, Vancouver, Canada, Jun, 2023, pp. 16 102–16 112
work page 2023
-
[54]
Efficient stitchable task adaptation,
H. He, Z. Pan, J. Liu, J. Cai, and B. Zhuang, “Efficient stitchable task adaptation,” inproc. IEEE/CVF CVPR, Seattle, USA, Jun, 2024, pp. 28 555–28 565
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.