Five-Minute Rule 40 Years Later: A First-Principles Revisit for Modern Memory Hierarchy
Pith reviewed 2026-05-18 00:41 UTC · model grok-4.3
The pith
For modern GPU AI platforms with high-IOPS SSDs, the DRAM-flash caching threshold drops from minutes to seconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
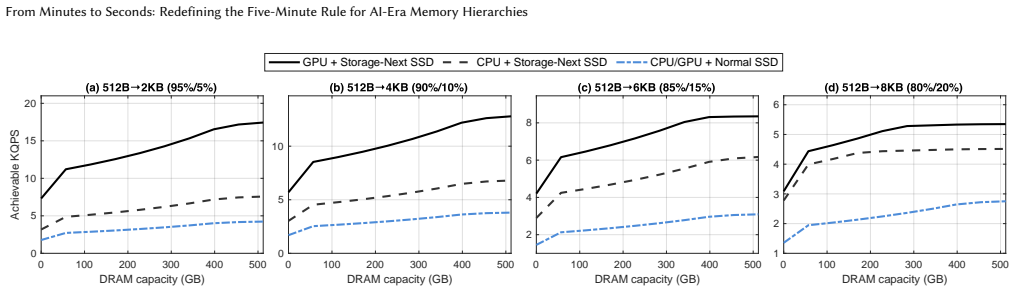
The central claim is that a first-principles model incorporating host costs, DRAM capacity and bandwidth constraints, and physics-grounded SSD performance and cost equations shows the DRAM to flash caching threshold collapsing from minutes to a few seconds on modern AI platforms, especially GPU hosts with ultra-high-IOPS SSDs engineered for fine-grained access.
What carries the argument
Constraint- and workload-aware framework that integrates host costs with physics-grounded SSD performance and cost models to compute the caching threshold.
If this is right
- NAND flash memory can be treated as an active data tier rather than passive cold storage in AI memory hierarchies.
- Provisioning guidance for AI platforms must now consider time scales of seconds instead of minutes when deciding data placement.
- Software systems gain a wider design space for data movement policies that exploit the lower threshold.
- Validation and sensitivity analysis become possible through the introduced MQSim-Next SSD simulator.
Where Pith is reading between the lines
- This shift may encourage hardware designers to optimize SSDs further for sub-second random access patterns typical in AI data reuse.
- The framework could extend to hybrid CPU-GPU setups or cloud environments where multiple hosts share the same storage tier.
- One testable extension is to vary SSD IOPS and DRAM prices in simulation to map how the threshold changes across different cost regimes.
Load-bearing premise
The physics-based SSD performance and cost models, together with the chosen workload behaviors and host cost structures, accurately represent real deployed AI systems.
What would settle it
Measure the actual cost-benefit crossover time for caching data between DRAM and flash while running representative AI training or inference workloads on a GPU server equipped with ultra-high-IOPS SSDs and compare the observed threshold to the predicted few-second value.
Figures









read the original abstract
In 1987, Jim Gray and Gianfranco Putzolu introduced the five-minute rule, a simple, storage-memory-economics-based heuristic for deciding when data should live in DRAM rather than on storage. Subsequent revisits to the rule largely retained that economics-only view, leaving host costs, feasibility limits, and workload behavior out of scope. This paper revisits the rule from first principles, integrating host costs, DRAM bandwidth/capacity, and physics-grounded models of SSD performance and cost, and then embedding these elements in a constraint- and workload-aware framework that yields actionable provisioning guidance. We show that, for modern AI platforms, especially GPU-centric hosts paired with ultra-high-IOPS SSDs engineered for fine-grained random access, the DRAM$\leftrightarrow$flash caching threshold collapses from minutes to a few seconds. This shift reframes NAND flash memory as an \emph{active data tier} and exposes a broad research space across the hardware-software stack. We further introduce MQSim-Next, a calibrated SSD simulator that supports validation and sensitivity analysis and facilitates future architectural and system research. Finally, we present two concrete case studies that showcase the software system design space opened by such memory hierarchy paradigm shift. Overall, we turn a classical heuristic into an actionable, feasibility-aware analysis and provisioning framework and set the stage for further research on AI-era memory hierarchy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper revisits the 1987 five-minute rule of Gray and Putzolo, which heuristically decides DRAM vs. storage residency based on economics. It integrates host costs, DRAM bandwidth/capacity limits, and physics-grounded SSD performance/cost models (via a new MQSim-Next simulator) into a constraint- and workload-aware framework. The central claim is that, for modern GPU-centric AI platforms using ultra-high-IOPS SSDs with fine-grained random access, the DRAM-flash caching threshold collapses from minutes to a few seconds; the work also presents two case studies on resulting software design implications.
Significance. If the SSD IOPS/latency/cost models and AI workload assumptions prove accurate for deployed systems, the result would be significant: it reframes NAND flash as an active data tier rather than a passive backing store, supplies concrete provisioning guidance for AI memory hierarchies, and opens a broad hardware-software research space. The introduction of MQSim-Next for calibration, validation, and sensitivity analysis is a concrete strength that supports reproducibility.
major comments (2)
- Abstract and modeling framework: the claim that the DRAM↔flash threshold collapses to seconds rests on the integrated host-cost, DRAM-bandwidth, and SSD-physics models, yet the manuscript provides no explicit break-even equation, no tabulated parameter values (e.g., IOPS, latency, per-GB cost coefficients), and no error or sensitivity analysis; without these the central quantitative result cannot be independently verified or stress-tested against plausible variations in real GPU-SSD deployments.
- Workload and validation section: the framework assumes fine-grained random-access patterns and access frequencies that are stated to be representative of LLM training/inference, but no quantitative comparison to measured traces from production AI platforms is shown; because the seconds-scale threshold is sensitive to these workload parameters, this assumption is load-bearing for the applicability claim.
minor comments (1)
- Abstract: the phrase 'physics-grounded models of SSD performance and cost' is used without a forward reference to the specific MQSim-Next calibration procedure or the data sources employed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions to improve verifiability and applicability while preserving the first-principles approach of the work.
read point-by-point responses
-
Referee: Abstract and modeling framework: the claim that the DRAM↔flash threshold collapses to seconds rests on the integrated host-cost, DRAM-bandwidth, and SSD-physics models, yet the manuscript provides no explicit break-even equation, no tabulated parameter values (e.g., IOPS, latency, per-GB cost coefficients), and no error or sensitivity analysis; without these the central quantitative result cannot be independently verified or stress-tested against plausible variations in real GPU-SSD deployments.
Authors: We agree that an explicit break-even equation, tabulated parameters, and expanded sensitivity analysis would strengthen independent verification. The current manuscript presents the integrated framework and results but consolidates the underlying equations and coefficients across sections for brevity. In the revised manuscript we will add a dedicated subsection deriving the full break-even equation from first principles (incorporating host costs, DRAM bandwidth limits, and SSD physics parameters) and include a consolidated table of all numerical coefficients with sources and units. We will also expand the MQSim-Next validation section with additional sensitivity plots and error bounds obtained from the simulator's hardware calibration, directly addressing stress-testing against parameter variations. revision: yes
-
Referee: Workload and validation section: the framework assumes fine-grained random-access patterns and access frequencies that are stated to be representative of LLM training/inference, but no quantitative comparison to measured traces from production AI platforms is shown; because the seconds-scale threshold is sensitive to these workload parameters, this assumption is load-bearing for the applicability claim.
Authors: We acknowledge that direct quantitative comparison against proprietary production traces would further support the workload assumptions. Such traces are not publicly available, and our analysis is deliberately first-principles rather than trace-driven to enable broad applicability. In the revision we will strengthen the workload section by citing additional published characterizations of LLM training and inference access patterns (including granularity and frequency statistics) and add a quantitative sensitivity study that varies random-access granularity and access frequency over ranges consistent with those characterizations. This will demonstrate the robustness of the seconds-scale threshold without relying on confidential data. revision: partial
Circularity Check
Derivation integrates independent models without reduction to inputs by construction
full rationale
The paper derives the seconds-scale DRAM-flash threshold by combining host cost structures, DRAM bandwidth/capacity limits, physics-grounded SSD performance and cost models, and workload behavior assumptions within a constraint-aware framework. MQSim-Next is introduced as a calibrated simulator for validation and sensitivity analysis rather than as the source of the target result. No equations or steps in the provided abstract reduce the claimed outcome to a fitted parameter renamed as prediction, a self-definitional loop, or a load-bearing self-citation chain. The framework remains externally falsifiable via real hardware traces and cost data outside the paper's fitted values, making the central claim self-contained against benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- SSD performance and cost model coefficients
- Host cost and DRAM bandwidth parameters
axioms (1)
- domain assumption Workload access patterns and request sizes are representative of modern AI training and inference jobs
Forward citations
Cited by 1 Pith paper
-
Economical and ecological impact of sector coupling applied to computing clusters
Simulations using German electricity data show that flexibly operating computing clusters on excess renewables can reduce carbon emissions and costs, after accounting for hardware acquisition and embedded emissions.
Reference graph
Works this paper leans on
- [1]
-
[2]
Redis — The Real-time Data Platform
2025. Redis — The Real-time Data Platform. https://redis.io
work page 2025
-
[3]
RocksDB — A Persistent Key-Value Store for Flash and RAM Storage
2025. RocksDB — A Persistent Key-Value Store for Flash and RAM Storage. https://rocksdb.org/
work page 2025
-
[4]
WiredTiger — High-Performance Storage Engine
2025. WiredTiger — High-Performance Storage Engine. https://github.com/ wiredtiger/wiredtiger
work page 2025
-
[5]
Raja Appuswamy, Goetz Graefe, Renata Borovica-Gajic, and Anastasia Ailamaki
-
[6]
The five-minute rule 30 years later and its impact on the storage hierarchy. Commun. ACM62, 11 (2019), 114–120
work page 2019
-
[7]
Ben Berg, Daniel Berger, Sara McAllister, Isaac Grosof, Sathya Gunasekar, Jimmy Lu, Michael Uhlar, Jim Carrig, Nathan Beckmann, Mor Harchol-Balter, , and Gregory Ganger. 2020. The CacheLib caching engine: Design and experiences at scale. InUSENIX Symposium on Operating Systems Design and Implementation (OSDI)
work page 2020
-
[8]
Badrish Chandramouli, Guna Prasaad, Donald Kossmann, Justin Levandoski, James Hunter, and Mike Barnett. 2018. Faster: A concurrent key-value store with in-place updates. InProceedings of the International Conference on Management of Data (SIGMOD). 275–290. https://doi.org/10.1145/3183713.3196898
-
[9]
Wooseong Cheong, Chanho Yoon, Seonghoon Woo, Kyuwook Han, Daehyun Kim, Chulseung Lee, Youra Choi, Shine Kim, Dongku Kang, and Geunyeong Yu
-
[10]
InIEEE International Solid-State Circuits Conference-(ISSCC)
A flash memory controller for 15𝜇s ultra-low-latency SSD using high-speed 3D NAND flash with 3 𝜇s read time. InIEEE International Solid-State Circuits Conference-(ISSCC). IEEE, 338–340
-
[11]
CMU-SAFARI. 2024. . Github. https://github.com/CMU-SAFARI/MQSim
work page 2024
-
[12]
Christian Monzio Compagnoni, Akira Goda, Alessandro S Spinelli, Peter Feeley, Andrea L Lacaita, and Angelo Visconti. 2017. Reviewing the evolution of the NAND flash technology.Proc. IEEE105, 9 (2017), 1609–1633
work page 2017
-
[13]
Sampath Deegalla and Henrik Bostrom. 2006. Reducing high-dimensional data by principal component analysis vs. random projection for nearest neighbor classification. InInternational Conference on Machine Learning and Applications (ICMLA). IEEE, 245–250. 12 From Minutes to Seconds: Redefining the Five-Minute Rule for AI-Era Memory Hierarchies
work page 2006
-
[14]
DigiTimes. [n. d.].Samsung revives Z-NAND after 7 years to supercharge AI with 15x speed gains. https://www.digitimes.com/news/a20250808VL210/samsung- 3d-nand-technology-ai.html
-
[15]
Siying Dong, Andrew Kryczka, Yanqin Jin, and Michael Stumm. 2021. Rocksdb: Evolution of development priorities in a key-value store serving large-scale applications.ACM Transactions on Storage (TOS)17, 4 (2021), 1–32
work page 2021
-
[16]
Mingjing Du, Shifei Ding, and Hongjie Jia. 2016. Study on density peaks clustering based on k-nearest neighbors and principal component analysis.Knowledge- Based Systems99 (2016), 135–145
work page 2016
-
[17]
Jianyang Gao and Cheng Long. 2023. High-dimensional approximate nearest neighbor search: with reliable and efficient distance comparison operations. Proceedings of the ACM on Management of Data1, 2 (2023), 1–27
work page 2023
-
[18]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, Amit Singh, and Harsha Vardhan Simhadri. 2023. Filtered- DiskANN: Graph algorithms for approximate nearest neighbor search with filters. InProceedings of the ACM Web Conference. 3406–3416
work page 2023
-
[19]
Goetz Graefe. 2007. The five-minute rule twenty years later, and how flash memory changes the rules. InProceedings of the International Workshop on Data Management on New Hardware. 1–9
work page 2007
-
[20]
Jim Gray and Goetz Graefe. 1997. The five-minute rule ten years later, and other computer storage rules of thumb.ACM Sigmod Record26, 4 (1997), 63–68
work page 1997
-
[21]
Jim Gray and Franco Putzolu. 1987. The 5 minute rule for trading memory for disc accesses and the 10 byte rule for trading memory for CPU time. InProceedings of the ACM international conference on Management of data (SIGMOD). 395–398
work page 1987
-
[22]
2013.Performance modeling and design of computer systems: queueing theory in action
Mor Harchol-Balter. 2013.Performance modeling and design of computer systems: queueing theory in action. Cambridge University Press
work page 2013
-
[23]
Zongliang Huo, Weihua Cheng, and Simon Yang. 2022. Unleash scaling potential of 3D NAND with innovative Xtacking®architecture. InIEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). 254–255
work page 2022
-
[24]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast accurate billion- point nearest neighbor search on a single node.Advances in neural information processing Systems32 (2019)
work page 2019
-
[25]
Gaewsky, Chang Wan Ha, Rezaul Haque, Owen W
Ali Khakifirooz, Sriram Balasubrahmanyam, Richard Fastow, Kristopher H. Gaewsky, Chang Wan Ha, Rezaul Haque, Owen W. Jungroth, Steven Law, Alias- gar S. Madraswala, Binh Ngo, Naveen Prabhu V, Shantanu Rajwade, Karthikeyan Ramamurthi, Rohit S. Shenoy, Jacqueline Snyder, Cindy Sun, Deepak Thim- megowda, Bharat M. Pathak, and Pranav Kalavade. 2021. A 1Tb 4b/...
work page 2021
-
[26]
Yousef A. Khalidi and Moti N. Thadani. 1995.An Efficient Zero-Copy I/O Frame- work for UNIX. Technical Report. USA
work page 1995
-
[27]
John FC Kingman. 1961. The single server queue in heavy traffic. InMathematical Proceedings of the Cambridge Philosophical Society, Vol. 57. Cambridge University Press, 902–904
work page 1961
-
[28]
Adam Kirsch, Michael Mitzenmacher, and Udi Wieder. 2010. More robust hashing: Cuckoo hashing with a stash.SIAM J. Comput.39, 4 (2010), 1543–1561
work page 2010
-
[29]
Leonard Kleinrock. 1975.Queueing Systems. Volume 1: Theory. Wiley- Interscience
work page 1975
-
[30]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. 2022. Matryoshka representation learning.Advances in Neural Information Processing Systems35 (2022), 30233–30249
work page 2022
-
[31]
Justin J. Levandoski, David B. Lomet, and Sudipta Sengupta. 2013. The Bw-Tree: A B-tree for new hardware platforms. InIEEE International Conference on Data Engineering (ICDE). 302–313
work page 2013
-
[32]
Hyeontaek Lim, Dongsu Han, David G Andersen, and Michael Kaminsky. 2014. MICA: A Holistic Approach to Fast In-Memory Key-Value Storage. InUSENIX Symposium on Networked Systems Design and Implementation (NSDI). 429–444
work page 2014
-
[33]
Shu Lin and Daniel J. Costello Jr. 1983.Error control coding - fundamentals and applications. Prentice Hall
work page 1983
-
[34]
Rey Luna. 2023. Introduction to JEDEC NAND Separate Command Address (SCA) Protocol. InFlash Memory Summit (FMS)
work page 2023
-
[35]
1977.The theory of error-correcting codes
Florence Jessie MacWilliams and Neil James Alexander Sloane. 1977.The theory of error-correcting codes. Vol. 16. Elsevier
work page 1977
-
[36]
Yu Malkov and Dmitry Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transac- tions on pattern analysis and machine intelligence42, 4 (2018), 824–836
work page 2018
-
[37]
2013.Inside solid state drives (SSDs)
Rino Micheloni, Alessia Marelli, and Kam Eshghi. 2013.Inside solid state drives (SSDs). Springer
work page 2013
-
[38]
CJ Newburn. 2024. GPUs as Data Access Engines. Future Memory & Storage Technologies Conference (FMST)
work page 2024
-
[39]
CJ Newburn, Prashant Prabhu, and Vikram Sharma Mailthody. 2025. Storage Next for AI: How to Eliminate the Memory Wall for GenAI and LLM Workloads. https://www.nvidia.com/en-us/on-demand/session/gtc25-s73012/. NVIDIA GTC 2025, Session S73012
work page 2025
-
[40]
Nikkei xTECH. [n. d.].Kioxia to Receive 100x Faster SSD for AI in 2027. https: //xtech.nikkei.com/atcl/nxt/column/18/00001/11065/
work page 2027
-
[41]
Open NAND Flash Interface Workgroup (ONFI). [n. d.]. ONFI Specifications. https://onfi.org/specs.html
-
[42]
Rasmus Pagh and Flemming Friche Rodler. 2004. Cuckoo hashing.Journal of Algorithms51, 2 (2004), 122–144
work page 2004
-
[43]
Jeongmin Brian Park, Vikram Sharma Mailthody, Zaid Qureshi, and Wen-mei Hwu. 2024. Accelerating Sampling and Aggregation Operations in GNN Frame- works with GPU Initiated Direct Storage Accesses.Proc. VLDB Endow.17, 6 (Feb. 2024), 1227–1240
work page 2024
-
[44]
Ted Pekny, Luyen Vu, Jeff Tsai, Dheeraj Srinivasan, Erwin Yu, Jonathan Pabus- tan, Joe Xu, Srinivas Deshmukh, Kim-Fung Chan, Michael Piccardi, Kevin Xu, Guan Wang, Kaveh Shakeri, Vipul Patel, Tomoko Iwasaki, Tongji Wang, Padma Musunuri, Carl Gu, Ali Mohammadzadeh, Ali Ghalam, Violante Moschiano, Tommaso Vali, Jaekwan Park, June Lee, and Ramin Ghodsi. 2022...
work page 2022
-
[45]
Zaid Qureshi, Vikram Sharma Mailthody, Isaac Gelado, Seungwon Min, Amna Masood, Jeongmin Park, Jinjun Xiong, Chris J Newburn, Dmitri Vainbrand, I-Hsin Chung, Michael Garland, William Dally, and Wen mei Hwu. 2023. GPU-initiated on-demand high-throughput storage access in the BaM system architecture. In Proceedings of the ACM International Conference on Arc...
work page 2023
-
[46]
SanDisk Corporation. 2025. The Diversification of Flash Storage: Unlocking the Full Potential of NAND in the AI Era. InKeynote Address, Flash Memory Summit (FMS): The Future of Memory and Storage. Santa Clara, CA, USA
work page 2025
-
[47]
Tatsuo Shiozawa, Hirotsugu Kajihara, Tatsuro Endo, and Kazuhiro Hiwada. 2020. Emerging usage and evaluation of low latency FLASH. InIEEE International Memory Workshop (IMW). IEEE, 1–4
work page 2020
-
[48]
Arash Tavakkol, Juan Gómez-Luna, Mohammad Sadrosadati, Saugata Ghose, and Onur Mutlu. 2018. MQSim: A framework for enabling realistic studies of modern Multi-Queue SSD devices. InUSENIX Conference on File and Storage Technologies (FAST 18). 49–66
work page 2018
-
[49]
Kilian Q Weinberger and Lawrence K Saul. 2009. Distance metric learning for large margin nearest neighbor classification.Journal of machine learning research 10, 2 (2009). 13
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.