Uncertainty-Aware Offline Data-Driven Multi-Objective Optimization
Pith reviewed 2026-05-18 00:18 UTC · model grok-4.3
The pith
Dual-ranking strategy prioritizes high-quality and reliable solutions by sorting on both predicted fitness and uncertainty estimates in offline multi-objective optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By performing non-dominated sorting on candidate solutions using both surrogate-based fitness values and uncertainty-aware fitness values, the proposed method prioritizes candidate solutions that are simultaneously high-quality and reliable.
What carries the argument
Dual-ranking strategy that conducts separate non-dominated sortings on predictive fitness and uncertainty-adjusted fitness to combine quality and reliability in selection.
Load-bearing premise
Uncertainty estimates from the surrogate models are sufficiently accurate and well-calibrated to correct dominance judgments without introducing new biases.
What would settle it
Test the method on benchmark problems using deliberately miscalibrated surrogate uncertainty estimates and check whether performance gains over baselines disappear.
Figures


read the original abstract
In offline data-driven multi-objective optimization (MOO), optimization is performed using surrogate models trained only on an offline dataset. These surrogate models contain inherent errors and uncertainty. This epistemic uncertainty can lead to incorrect dominance judgments, thereby misleading the search process. Existing methods mitigate this issue by incorporating uncertainty estimates from Gaussian Process Regression (GPR) to correct dominance judgments; however, they are restricted to GPR, and their optimization strategies cannot be scaled to other uncertainty quantification methods. In addition, GPR-based surrogates suffer from high computational cost. We propose a simple yet effective dual-ranking strategy that flexibly leverages both predictive results and uncertainty estimates from different surrogate models. By performing non-dominated sorting on candidate solutions using both surrogate-based fitness values and uncertainty-aware fitness values, the proposed method prioritizes candidate solutions that are simultaneously high-quality and reliable. Through extensive experimental evaluations, including ablation, sensitivity, and comparative experiments, we demonstrate the effectiveness and robustness of the proposed dual-ranking strategy working with different surrogates. Our dual-ranking framework offers more robust solutions for data-limited, real-world applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a dual-ranking strategy for offline data-driven multi-objective optimization. Surrogate models are trained on a fixed offline dataset; candidate solutions are then ranked via non-dominated sorting applied simultaneously to the surrogate predictions (fitness values) and to derived uncertainty-aware fitness values. The goal is to favor solutions that are both high-quality and reliable under epistemic uncertainty. The method is presented as flexible across surrogate types (unlike prior GPR-only approaches) and is evaluated via ablation, sensitivity, and comparative experiments.
Significance. If the uncertainty-aware ranking can be shown to preserve dominance semantics with respect to the unknown true Pareto front, the approach would supply a lightweight, surrogate-agnostic mechanism for uncertainty handling in data-limited MOO. The reported flexibility with multiple surrogate families and the inclusion of ablation/sensitivity studies are positive indicators of practical utility in evolutionary computation and surrogate-assisted optimization.
major comments (2)
- [§3] §3 (Method): The central claim rests on performing non-dominated sorting over both surrogate-based fitness and 'uncertainty-aware fitness values,' yet no explicit transformation is supplied that maps raw uncertainty estimates (from any surrogate) into these uncertainty-aware values. It is therefore impossible to verify whether the combined dominance relation penalizes unreliable points without distorting the original objective trade-offs or introducing new selection biases. This mapping is load-bearing for the stated advantage over existing GPR-restricted methods.
- [§4] §4 (Experiments): The comparative and ablation results are described as demonstrating robustness, but without an explicit definition of the uncertainty-aware fitness construction it is unclear whether the reported gains arise from the dual-ranking mechanism itself or from incidental properties of the chosen surrogates and uncertainty estimators. A controlled check (e.g., synthetic fronts with known epistemic uncertainty) would be required to substantiate the claim that the ranking remains consistent with the true Pareto front when uncertainty is high.
minor comments (2)
- [§3] Notation for the uncertainty-aware fitness vector should be introduced with a compact equation (e.g., Eq. (X)) rather than prose only; this would improve reproducibility across surrogate implementations.
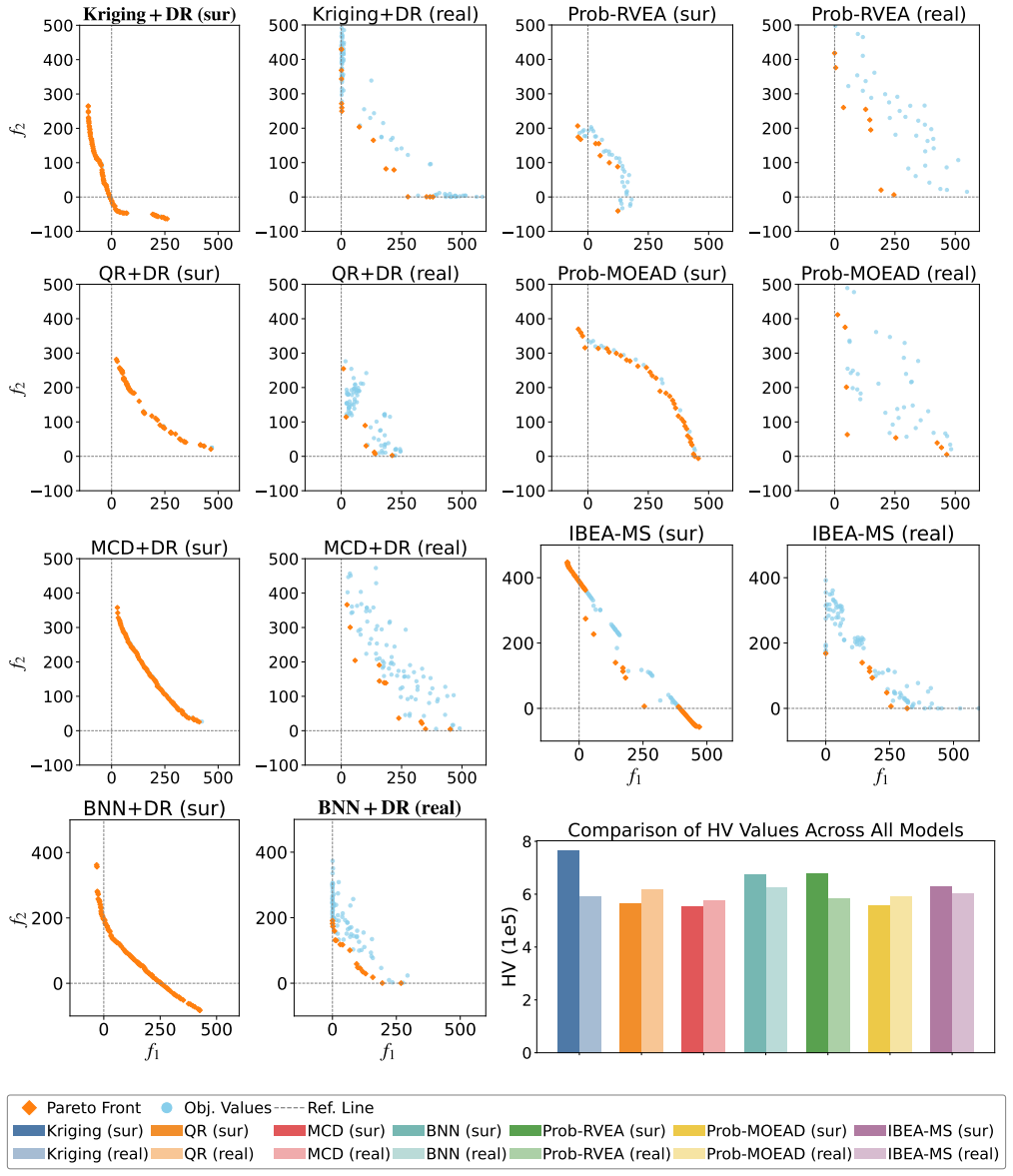
- [§4] Figure captions and axis labels in the experimental plots would benefit from explicit mention of which surrogate and uncertainty estimator are used in each panel.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments in detail below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: §3 (Method): The central claim rests on performing non-dominated sorting over both surrogate-based fitness and 'uncertainty-aware fitness values,' yet no explicit transformation is supplied that maps raw uncertainty estimates (from any surrogate) into these uncertainty-aware values. It is therefore impossible to verify whether the combined dominance relation penalizes unreliable points without distorting the original objective trade-offs or introducing new selection biases. This mapping is load-bearing for the stated advantage over existing GPR-restricted methods.
Authors: We appreciate the referee's emphasis on the need for an explicit mapping. In the original manuscript, the uncertainty-aware fitness is constructed by adjusting the surrogate predictions with the uncertainty estimates to favor reliable solutions, but we acknowledge that the description could be more precise. To address this, we will revise Section 3 to include a formal definition of the uncertainty-aware fitness values. For a general surrogate providing prediction ŷ_i and uncertainty σ_i for objective i, the uncertainty-aware value is defined as ŷ_i + β · σ_i (for minimization problems), where β is a hyperparameter that controls the penalty for uncertainty. This transformation is applied uniformly across surrogate types, ensuring the dual-ranking prioritizes both performance and reliability. We will also add a brief analysis showing that this does not introduce biases beyond the intended uncertainty penalization. revision: yes
-
Referee: §4 (Experiments): The comparative and ablation results are described as demonstrating robustness, but without an explicit definition of the uncertainty-aware fitness construction it is unclear whether the reported gains arise from the dual-ranking mechanism itself or from incidental properties of the chosen surrogates and uncertainty estimators. A controlled check (e.g., synthetic fronts with known epistemic uncertainty) would be required to substantiate the claim that the ranking remains consistent with the true Pareto front when uncertainty is high.
Authors: We agree that a more controlled validation would be beneficial to isolate the contribution of the dual-ranking strategy. Our current experimental setup uses real-world and benchmark problems with various surrogates to show robustness, but we recognize the value of synthetic tests. In the revised manuscript, we will add a new subsection in the experiments with synthetic multi-objective problems where we can control the level of epistemic uncertainty (e.g., by varying noise in the offline data). This will allow us to verify that the proposed ranking maintains alignment with the known true Pareto front under high uncertainty conditions. We believe this addition will directly address the concern and strengthen the empirical support for our claims. revision: yes
Circularity Check
No circularity detected in algorithmic proposal
full rationale
The paper presents a practical algorithmic strategy (dual-ranking via non-dominated sorting on surrogate fitness plus uncertainty-aware fitness) for offline MOO rather than any first-principles derivation or prediction that reduces to fitted inputs. No equations equate outputs to inputs by construction, no self-citation chains bear the central claim, and no ansatz or renaming is smuggled in. The method is evaluated empirically against external benchmarks, making the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Surrogate models trained on offline data can produce both point predictions and meaningful uncertainty estimates that can be used to adjust dominance relations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By performing non-dominated sorting on candidate solutions using both surrogate-based fitness values and uncertainty-aware fitness values, the proposed method prioritizes candidate solutions that are simultaneously high-quality and reliable.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gaussian Processes for Big Data
PMLR. Greene, W. H. 2003. Econometric analysis.Pretence Hall. Helton, J. C.; and Davis, F. J. 2003. Latin hypercube sam- pling and the propagation of uncertainty in analyses of com- plex systems.Reliability Engineering & System Safety, 81(1): 23–69. Hensman, J.; Fusi, N.; and Lawrence, N. D. 2013. Gaussian processes for big data.arXiv preprint arXiv:1309....
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[2]
Offline Model-Based Optimization: Compre- hensive Review
Data-driven evolutionary optimization: An overview and case studies.IEEE Transactions on Evolutionary Com- putation, 23(3): 442–458. Kim, M.; Gu, J.; Yuan, Y .; Yun, T.; Liu, Z.; Bengio, Y .; and Chen, C. 2025. Offline Model-Based Optimization: Com- prehensive Review.arXiv preprint arXiv:2503.17286. Kingma, D. P.; and Ba, J. 2014. Adam: A method for stoch...
-
[3]
Probabilistic selection approaches in decomposition- based evolutionary algorithms for offline data-driven multi- objective optimization.IEEE Transactions on Evolutionary Computation, 26(5): 1182–1191. Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. 2019. Pytorch: An imperativ...
work page 2019
-
[4]
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design
Gaussian process optimization in the bandit set- ting: No regret and experimental design.arXiv preprint arXiv:0912.3995. Steinwart, I.; and Christmann, A. 2011. Estimating condi- tional quantiles with the help of the pinball loss.Bernoulli, 17: 211–225. Wang, H.; Jin, Y .; Sun, C.; and Doherty, J. 2018. Offline data-driven evolutionary optimization using ...
work page internal anchor Pith review Pith/arXiv arXiv 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.