DMA-Latte: Expanding the Reach of DMA Offloads to Latency-bound ML Communication
Pith reviewed 2026-05-18 00:24 UTC · model grok-4.3
The pith
DMA offloads using untapped features in MI300X GPUs can compete with core-based libraries even for small latency-bound ML transfers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By exploiting hitherto untapped features available in the AMD Instinct MI300X GPUs, DMA communication offloads become competitive for latency-bound regions with transfer sizes from KB to low MB. Optimized offloads for ML collectives such as all-gather and all-to-all close up to 4.5 times the performance gap relative to the state-of-the-art GPU core-based library RCCL and deliver 3-10 percent additional power savings. The same approach accelerates full LLM inference workloads, achieving up to 1.5 times lower latency and up to 1.9 times higher throughput compared with the vLLM framework.
What carries the argument
Optimized DMA offloads that leverage specific untapped features in state-of-the-art AMD Instinct MI300X GPUs to support competitive performance in latency-bound communication.
If this is right
- ML collectives achieve up to 4.5 times better performance and 3-10 percent power savings versus core-based libraries.
- LLM inference sees up to 1.5 times lower latency and 1.9 times higher throughput than current frameworks.
- Computation and communication overlap improves for small transfer sizes that previously could not use DMA offloads.
- Runtime innovations can expose these GPU features for wider adoption in ML systems.
Where Pith is reading between the lines
- Similar untapped DMA features may exist on other GPU platforms and could be evaluated for comparable latency-bound gains.
- Targeted hardware-software co-design could push the technique to even smaller transfer sizes or additional collective patterns.
- Power reductions observed at scale could lower energy consumption in large ML training clusters.
Load-bearing premise
The untapped features in MI300X GPUs allow DMA offloads to handle latency-bound transfers competitively without introducing hidden overheads or workload-specific limitations.
What would settle it
Direct head-to-head latency and power measurements of all-gather and all-to-all collectives at KB to low-MB transfer sizes on MI300X hardware, checking whether DMA offloads close the stated performance gap to RCCL while avoiding any unaccounted slowdowns.
Figures






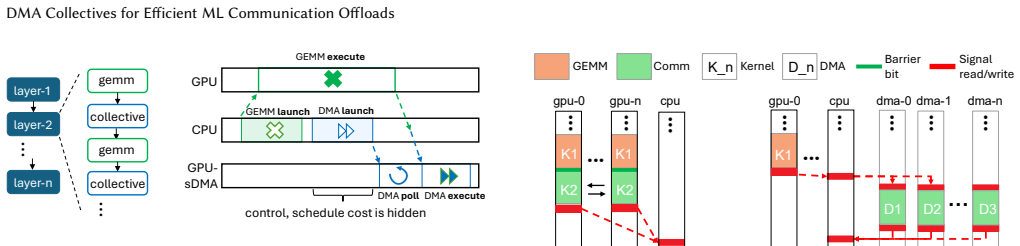


read the original abstract
Offloading communication to existing direct memory access (DMA) engines, available on most state-of-the-art commercial GPUs, has emerged as an interesting and low-cost solution to efficiently overlap computation and communication in machine learning (ML). That said, so far, the reach of DMA offloads has been limited to bandwidth-bound scenarios only (10s of MB to GB transfer sizes). In this work, we aim to break this barrier and expand the reach of DMA communication offloads to even latency-bound regions (KB to low MB). Specifically, we discuss in this work hitherto untapped features available in the state-of-the-art AMD Instinct$^{\mathrm{TM}}$ MI300X GPUs that render DMA communication offloads competitive even for latency-bound regions. We demonstrate the efficacy of these features at the operator-level (ML communication collectives such as all-gather and all-to-all), and also at the end-to-end workload-level (LLM inference). For the former, our optimized DMA offloads close up to 4.5$\times$ performance gap and deliver additional power savings (3-10%) for ML collectives as compared to state-of-the-art GPU core-based communication library, RCCL. For the latter, we demonstrate acceleration for LLM inference: up to 1.5$\times$ lower latency and up to 1.9$\times$ higher throughput over the state-of-the-art vLLM inference framework. We conclude with a discussion of AMD Instinct GPU runtime innovations that stand to expose these features and additionally identify future hardware-software co-design potential to further improve DMA offload efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hitherto untapped features in AMD Instinct MI300X GPUs enable DMA offloads to become competitive for latency-bound ML communication (KB to low-MB transfers). It reports up to 4.5× gap closure versus RCCL for collectives such as all-gather and all-to-all, accompanied by 3-10% power savings, plus up to 1.5× lower latency and 1.9× higher throughput for end-to-end LLM inference versus vLLM.
Significance. If the empirical claims are substantiated with transparent methodology, the work would meaningfully broaden the scope of low-overhead DMA offloading in distributed ML systems, reducing GPU-core contention for small messages and improving overlap and energy efficiency in both training and inference workloads.
major comments (1)
- [§5.1] §5.1 (microbenchmarks for 1–100 KB messages): the central claim that the new DMA features eliminate fixed setup overheads for latency-bound transfers requires an explicit isolation of setup latency versus pure transfer time, plus any extra synchronization or cache-flush costs; without this breakdown the reported gap closure for small messages cannot be verified as general rather than workload-specific.
minor comments (2)
- [Abstract] Abstract: concrete speedup numbers are given without any mention of message-size ranges, number of runs, or hardware configuration details; these should be added for reproducibility.
- [Figure 4] Figure 4 (LLM inference results): axis labels and error-bar conventions are inconsistent with the collective plots in Figure 3; standardize formatting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We appreciate the suggestion to strengthen the microbenchmark analysis and will revise the paper accordingly to improve clarity and verifiability of our results.
read point-by-point responses
-
Referee: [§5.1] §5.1 (microbenchmarks for 1–100 KB messages): the central claim that the new DMA features eliminate fixed setup overheads for latency-bound transfers requires an explicit isolation of setup latency versus pure transfer time, plus any extra synchronization or cache-flush costs; without this breakdown the reported gap closure for small messages cannot be verified as general rather than workload-specific.
Authors: We agree that an explicit breakdown isolating setup latency from pure transfer time, along with synchronization and cache-flush costs, would make the claims more transparent and easier to verify as general rather than workload-specific. In the revised manuscript we will expand §5.1 with additional microbenchmark data that separately reports DMA engine setup time, data transfer time, synchronization overhead, and any cache-flush costs for the 1–100 KB range. These measurements will be presented both for the baseline RCCL path and for our DMA-offload implementation, allowing direct comparison of the fixed overhead components. We believe this addition will substantiate that the untapped MI300X features are responsible for the observed gap closure. revision: yes
Circularity Check
No circularity: empirical systems paper with benchmark-driven claims
full rationale
The manuscript reports hardware-specific optimizations and micro-benchmark results for DMA offloads on MI300X GPUs, comparing against RCCL and vLLM. All performance claims (4.5× gap closure, 1.5–1.9× LLM gains) rest on direct measurements of latency, throughput, and power rather than any derivation, fitted-parameter prediction, or self-referential definition. No equations, uniqueness theorems, or ansatzes appear; the work is self-contained against external baselines and contains no load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Offloading communication to existing direct memory access (DMA) engines... hitherto untapped features available in the state-of-the-art AMD Instinct™ MI300X GPUs that render DMA communication offloads competitive even for latency-bound regions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
CompPow: A Case for Component-level GPU Power Management
CompPow makes the case that component-aware power management inside GPUs can yield 10% higher energy efficiency and 5% better performance for ML workloads.
Reference graph
Works this paper leans on
-
[1]
DMA Packets.https://people.freedesktop.org/~agd5f/dma_ packets.txt
2014. DMA Packets.https://people.freedesktop.org/~agd5f/dma_ packets.txt
work page 2014
-
[2]
HIP Documentation.https://rocm.docs.amd.com/_/downloads/ HIP/en/docs-6.1.2/pdf/
2024. HIP Documentation.https://rocm.docs.amd.com/_/downloads/ HIP/en/docs-6.1.2/pdf/
work page 2024
-
[3]
ROCR Documentation.https://rocm.docs.amd.com/_/ downloads/ROCR-Runtime/en/master/pdf/
2024. ROCR Documentation.https://rocm.docs.amd.com/_/ downloads/ROCR-Runtime/en/master/pdf/
work page 2024
-
[4]
AMD ROCm documentation.https://rocm.docs.amd.com/en/ latest/
2025. AMD ROCm documentation.https://rocm.docs.amd.com/en/ latest/
work page 2025
-
[5]
Tensile Documentation.https://rocm.docs.amd.com/_/ downloads/Tensile/en/latest/pdf/
2025. Tensile Documentation.https://rocm.docs.amd.com/_/ downloads/Tensile/en/latest/pdf/
work page 2025
-
[6]
2025. User Buffer Registration.https://docs.nvidia.com/deeplearning/ nccl/user-guide/docs/usage/bufferreg.html
work page 2025
-
[7]
Anirudha Agrawal, Shaizeen Aga, Suchita Pati, and Mahzabeen Islam
-
[8]
arXiv:2412.14335 [cs.AR]https://arxiv.org/ abs/2412.14335
Optimizing ML Concurrent Computation and Communication with GPU DMA Engines. arXiv:2412.14335 [cs.AR]https://arxiv.org/ abs/2412.14335
-
[9]
AMD. [n. d.].ROCm Runtime (ROCr).https://github.com/ROCm/ ROCR-Runtime
-
[10]
2025.ROCm Communication Collectives Library (RCCL).https: //github.com/ROCm/rccl
AMD. 2025.ROCm Communication Collectives Library (RCCL).https: //github.com/ROCm/rccl
work page 2025
-
[11]
AMD. 2025. ROCm/rocBLAS: Next generation BLAS implementation for ROCm platform.https://github.com/ROCm/rocBLAS
work page 2025
- [12]
-
[13]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. Mscclang: Microsoft collective communication language. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 502–514
work page 2023
-
[14]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Ali Hassani, Michael Isaev, Nic McDonald, Jie Ren, Vijay Thakkar, Haicheng Wu, and Humphrey Shi. 2024. Distributed GEMM
work page 2024
-
[16]
Horace He, Less Wright, Luca Wehrstedt, Tianyu Liu, Wan- chao Liang. 2024. Introducing Async Tensor Parallelism in PyTorch. "https://discuss.pytorch.org/t/distributed-w-torchtitan- introducing-async-tensor-parallelism-in-pytorch/209487"
work page 2024
-
[17]
Changho Hwang, KyoungSoo Park, Ran Shu, Xinyuan Qu, Peng Cheng, and Yongqiang Xiong. 2023. {ARK}:{GPU-driven} Code Execution for Distributed Deep Learning. In20th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 23). 87–101
work page 2023
-
[18]
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sa- bet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkow- icz, and Olli Saarikivi. 2022. Breaking the Computation and Commu- nication Abstraction Barrier in Distributed Machine Learning Work- loads. InProceedings of the 27th ACM International Conference on Architectural Support for Pr...
-
[19]
Benjamin Klenk, Nan Jiang, Greg Thorson, and Larry Dennison. 2020. An In-Network Architecture for Accelerating Shared-Memory Multi- processor Collectives. InACM/IEEE 47th Annual International Sympo- sium on Computer Architecture (ISCA). IEEE, IEEE Computer Society, Washington, DC, USA, 996–1009
work page 2020
-
[20]
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catan- zaro. 2023. Reducing activation recomputation in large transformer models.Proceedings of Machine Learning and Systems5 (2023), 341– 353
work page 2023
-
[21]
NVIDIA. [n. d.].NCCL.https://github.com/NVIDIA/nccl
-
[22]
Suchita Pati, Shaizeen Aga, Mahzabeen Islam, Nuwan Jayasena, and Matthew D Sinclair. 2024. T3: Transparent Tracking & Triggering for Fine-grained Overlap of Compute & Collectives. InProceedings 12 DMA Collectives for Efficient ML Communication Offloads of the 29th ACM International Conference on Architectural Support for Programming Languages and Operatin...
work page 2024
-
[23]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. Deepspeed-moe: Advancing mixture-of-experts infer- ence and training to power next-generation ai scale. InInternational conference on machine learning. PMLR, 18332–18346
work page 2022
-
[24]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[25]
InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis
Zero: Memory optimizations toward training trillion param- eter models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–16
-
[26]
Saeed Rashidi, Matthew Denton, Srinivas Sridharan, Sudarshan Srini- vasan, Amoghavarsha Suresh, Jade Nie, and Tushar Krishna. 2021. En- abling Compute-Communication Overlap in Distributed Deep Learn- ing Training Platforms. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, IEEE Press, Piscat- away, NJ, USA, 540–553...
-
[27]
Aashaka Shah, Abhinav Jangda, Binyang Li, Caio Rocha, Changho Hwang, Jithin Jose, Madan Musuvathi, Olli Saarikivi, Peng Cheng, Qinghua Zhou, Roshan Dathathri, Saeed Maleki, and Ziyue Yang
- [28]
-
[29]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. CoRRabs/1909.08053 (2019), 9 pages. arXiv:1909.08053 [cs.CL]http: //arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[30]
Varsha Singhania, Shaizeen Aga, and Mohamed Assem Ibrahim. 2025. FinGraV: Methodology for Fine-Grain GPU Power Visibility and In- sights. In2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 96–107
work page 2025
-
[31]
Alan Smith, Eric Chapman, Chintan Patel, Raja Swaminathan, John Wuu, Tyrone Huang, Wonjun Jung, Alexander Kaganov, Hugh McIn- tyre, and Ramon Mangaser. 2024. 11.1 AMD InstinctTM MI300 Series Modular Chiplet Package – HPC and AI Accelerator for Exa-Class Sys- tems. In2024 IEEE International Solid-State Circuits Conference (ISSCC), Vol. 67. 490–492. doi:10....
-
[32]
Alan Smith, Gabriel H. Loh, John Wuu, Samuel Naffziger, Tyrone Huang, Hugh McIntyre, Ramon Mangaser, Wonjun Jung, and Raja Swaminathan. 2024. AMD Instinct™MI300X Accelerator: Packaging and Architecture Co-Optimization. In2024 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). 1–8. doi:10. 1109/VLSITECHNOLOGYANDCIR46783.2024.10631545
-
[33]
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, Sameer Kumar, Tongfei Guo, Yuanzhong Xu, and Zongwei Zhou. 2022. Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models. In Proceedings of the 28th ACM International...
-
[34]
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wen- lei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li- Wen Chang, Quan Chen, and Xin Liu. 2025. Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts. arXiv:2502.19811 [cs.DC]https://arxiv.org/abs/2502.19811
-
[35]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. Py- Torch FSDP: Experiences on Scaling Fully Sharded Data Parallel. arXiv:2304.11277 [cs.DC]https://arxiv...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Size Zheng, Wenlei Bao, Qi Hou, Xuegui Zheng, Jin Fang, Chen- hui Huang, Tianqi Li, Haojie Duanmu, Renze Chen, Ruifan Xu, Yi- fan Guo, Ningxin Zheng, Ziheng Jiang, Xinyi Di, Dongyang Wang, Jianxi Ye, Haibin Lin, Li-Wen Chang, Liqiang Lu, Yun Liang, Jidong Zhai, and Xin Liu. 2025. Triton-distributed: Programming Overlap- ping Kernels on Distributed AI Syst...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.