Adversarial Attack on Black-Box Multi-Agent by Adaptive Perturbation
Pith reviewed 2026-05-17 21:01 UTC · model grok-4.3
The pith
AdapAM attacks black-box multi-agent systems by adaptively selecting a victim agent and using a learned proxy to generate stealthy perturbations that induce harmful actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdapAM incorporates an Adaptive Selection Policy that chooses the victim agent and the anticipated malicious action expected to produce the worst impact on the multi-agent system, together with Proxy-based Perturbation that applies generative adversarial imitation learning to build an approximation of the target MAS; this approximation supports the creation of perturbed observations in a white-box setting that induce the malicious action when applied to the black-box system.
What carries the argument
Adaptive Selection Policy paired with Proxy-based Perturbation via generative adversarial imitation learning, which identifies the target and approximates the unknown system to enable transferable perturbations.
If this is right
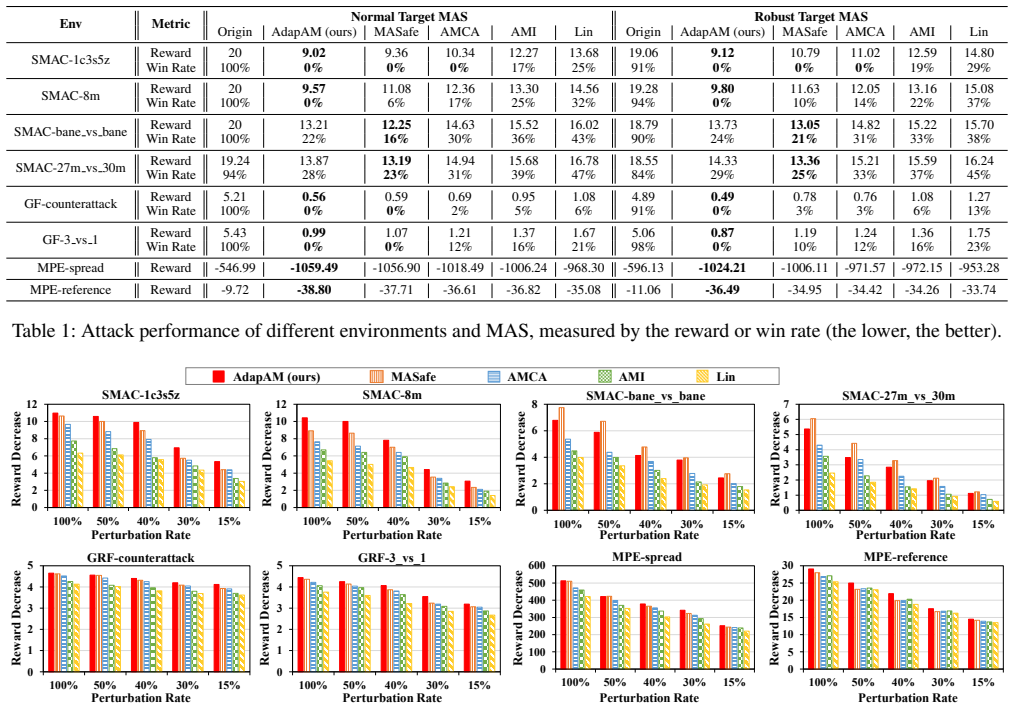
- AdapAM produces higher attack success rates than four baselines at multiple perturbation levels in all eight tested multi-agent environments.
- The perturbations created by AdapAM are less noisy and harder for detection methods to identify than those from previous techniques.
- The approach works without requiring white-box knowledge of the target models or authority over every agent in the system.
- Security assessments of multi-agent systems gain a practical tool for simulating realistic, targeted attacks.
Where Pith is reading between the lines
- Similar proxy-based imitation techniques could be applied to attack other types of black-box decision systems where only behavior traces are available.
- System designers might add observation noise or behavior monitoring to disrupt the training of such proxy models and reduce attack transfer.
- The method could be extended by testing whether the same adaptive selection remains effective when the number of agents grows or when communication between agents increases.
Load-bearing premise
A proxy model trained through imitation learning on observed actions can approximate the real black-box multi-agent system closely enough that perturbations crafted against the proxy will cause the intended malicious behavior in the actual system.
What would settle it
Deploying the generated perturbations in one of the eight evaluated environments and observing that the agents do not perform the expected malicious actions at rates significantly above random chance would indicate the proxy approximation is too inaccurate.
Figures



read the original abstract
Evaluating security and reliability for multi-agent systems (MAS) is urgent as they become increasingly prevalent in various applications. As an evaluation technique, existing adversarial attack frameworks face certain limitations, e.g., impracticality due to the requirement of white-box information or high control authority, and a lack of stealthiness or effectiveness as they often target all agents or specific fixed agents. To address these issues, we propose AdapAM, a novel framework for adversarial attacks on black-box MAS. AdapAM incorporates two key components: (1) Adaptive Selection Policy simultaneously selects the victim and determines the anticipated malicious action (the action would lead to the worst impact on MAS), balancing effectiveness and stealthiness. (2) Proxy-based Perturbation to Induce Malicious Action utilizes generative adversarial imitation learning to approximate the target MAS, allowing AdapAM to generate perturbed observations using white-box information and thus induce victims to execute malicious action in black-box settings. We evaluate AdapAM across eight multi-agent environments and compare it with four state-of-the-art and commonly-used baselines. Results demonstrate that AdapAM achieves the best attack performance in different perturbation rates. Besides, AdapAM-generated perturbations are the least noisy and hardest to detect, emphasizing the stealthiness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdapAM, a framework for adversarial attacks on black-box multi-agent systems (MAS). It consists of an Adaptive Selection Policy that chooses victim agents and anticipated malicious actions to balance effectiveness and stealth, and a Proxy-based Perturbation component that trains a proxy model via generative adversarial imitation learning (GAIL) on observed trajectories. This proxy enables white-box perturbation generation to induce malicious actions in the true black-box MAS. The approach is evaluated on eight multi-agent environments against four baselines, with claims of superior attack performance across perturbation rates and greater stealth (least noisy and hardest-to-detect perturbations).
Significance. If the results hold under proper validation, the work could meaningfully advance security evaluation techniques for MAS by addressing limitations of prior attacks that require white-box access, high control authority, or non-adaptive targeting. The combination of adaptive victim/malicious-action selection with a learned proxy offers a practical black-box method, and the emphasis on stealth is a useful contribution if empirically supported.
major comments (1)
- [Proxy-based Perturbation (method description)] The central claim that AdapAM reliably induces worst-case malicious actions via perturbed observations in black-box settings depends on the GAIL-trained proxy faithfully approximating the target MAS dynamics. No quantitative validation of proxy fidelity (e.g., policy divergence, value-function error, or held-out trajectory prediction accuracy) is reported in the method or experiments. This is load-bearing: without it, the adaptive perturbations may optimize against proxy artifacts rather than the true system, weakening both the effectiveness and stealth comparisons to baselines.
minor comments (1)
- [Abstract] The abstract asserts superior performance and stealth but provides no quantitative metrics, statistical significance, error bars, or implementation details for the baselines, making the empirical claims hard to assess without the full results section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights an important aspect of our method's validation. We address the major comment point by point below.
read point-by-point responses
-
Referee: The central claim that AdapAM reliably induces worst-case malicious actions via perturbed observations in black-box settings depends on the GAIL-trained proxy faithfully approximating the target MAS dynamics. No quantitative validation of proxy fidelity (e.g., policy divergence, value-function error, or held-out trajectory prediction accuracy) is reported in the method or experiments. This is load-bearing: without it, the adaptive perturbations may optimize against proxy artifacts rather than the true system, weakening both the effectiveness and stealth comparisons to baselines.
Authors: We agree that the fidelity of the GAIL-trained proxy is central to the reliability of the black-box attack claims. The manuscript evaluates AdapAM end-to-end by measuring attack success rates, perturbation norms, and detectability directly on the target black-box MAS across eight environments, which provides indirect evidence that the proxy enables effective perturbations. However, we acknowledge that explicit quantitative metrics of proxy approximation quality (such as held-out trajectory prediction error or policy divergence) are not reported. In the revised manuscript we will add a dedicated subsection under Experiments that reports these metrics on held-out trajectories collected from the black-box environments, thereby confirming that the proxy captures the relevant dynamics rather than artifacts. revision: yes
Circularity Check
No significant circularity; derivation relies on standard GAIL proxy training and empirical evaluation
full rationale
The paper's core method trains a proxy via generative adversarial imitation learning on observed trajectories to enable white-box perturbation generation against a black-box MAS, then evaluates attack success empirically across eight environments against baselines. This chain does not reduce any claimed result to its inputs by construction, nor does it invoke self-citations, uniqueness theorems, or fitted parameters renamed as predictions. The adaptive selection and proxy approximation are presented as standard techniques applied to external observations, with performance claims grounded in comparative experiments rather than tautological definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A generative adversarial imitation learning model trained on observed state-action pairs can approximate the policy of a black-box multi-agent system sufficiently for attack purposes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proxy-based Perturbation to Induce Malicious Action utilizes generative adversarial imitation learning to approximate the target MAS... C&W attack technique
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adaptive selection policy... modeled as an RL process that optimizes the objective based on reducing the reward
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ma, C.; Li, A.; Du, Y .; Dong, H.; and Yang, Y
Decentralized Policy Gradient Descent Ascent for Safe Multi-Agent Reinforcement Learning.Proceedings of the AAAI Conference on Artificial Intelligence, 35(10): 8767–8775. Ma, C.; Li, A.; Du, Y .; Dong, H.; and Yang, Y . 2024. Ef- ficient and scalable reinforcement learning for large-scale network control.Nature Machine Intelligence, 6(9): 1006– 1020. Mham...
work page 2024
-
[2]
Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Fo- erster, J.; and Whiteson, S
Adaptive multi-agents synchronization for collabora- tive driving of autonomous vehicles with multiple commu- nication delays.Transportation Research Part C: Emerging Technologies, 86: 372–392. Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Fo- erster, J.; and Whiteson, S. 2018. QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Re...
work page 2018
-
[3]
Zhang, H.; Chen, H.; Boning, D
Philadelphia, PA. Zhang, H.; Chen, H.; Boning, D. S.; and Hsieh, C.-J. 2021. Robust Reinforcement Learning on State Observations with Learned Optimal Adversary. InInternational Conference on Learning Representations. Zhang, H.; Chen, H.; Xiao, C.; Li, B.; Liu, M.; Boning, D.; and Hsieh, C.-J. 2020. Robust Deep Reinforcement Learning against Adversarial Pe...
work page 2021
-
[4]
Zhang, L.; Li, L.; Wei, W.; Song, H.; Yang, Y .; and Liang, J
Defending adversarial attacks in Graph Neural Net- works via tensor enhancement.Pattern Recognit., 158: 110954. Zhang, L.; Li, L.; Wei, W.; Song, H.; Yang, Y .; and Liang, J. 2024b. Scalable Constrained Policy Optimization for Safe Multi-agent Reinforcement Learning. InAdvances in Neu- ral Information Processing Systems, volume 37, 138698– 138730. Zhang, ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.