Multi-fidelity Gaussian process regression for noisy outputs and non-nested experimental designs: a comparison between the recursive and non-recursive formulations
Pith reviewed 2026-05-21 18:35 UTC · model grok-4.3
The pith
The recursive multi-fidelity Gaussian process trains faster than the non-recursive version by using decoupled EM optimization on noisy non-nested data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The recursive auto-regressive multi-fidelity Gaussian process model admits a decoupled optimization strategy based on the expectation-maximization algorithm; when the scaling factor between fidelity levels is modeled as a parametric linear predictor this yields closed-form update formulas, and benchmark experiments demonstrate that the resulting procedure reduces training time relative to the fully coupled likelihood maximization of the non-recursive formulation while maintaining competitive predictive accuracy and uncertainty estimation on noisy non-nested data.
What carries the argument
Decoupled expectation-maximization optimization of the recursive auto-regressive multi-fidelity Gaussian process model that supplies closed-form updates for the parametric linear scaling predictor.
If this is right
- Training time decreases significantly when large low-fidelity data sets are available.
- Predictive accuracy remains competitive with the non-recursive formulation.
- Uncertainty estimation quality is preserved across the tested applications.
- The method handles both noisy outputs and non-nested experimental designs without requiring special nesting assumptions.
Where Pith is reading between the lines
- The same decoupled EM structure might be adapted to other autoregressive multi-fidelity surrogate models that currently use coupled likelihoods.
- As low-fidelity data volumes continue to increase in practice the relative speed advantage would grow and could enable more frequent model retraining.
- The approach could be combined with active learning loops that decide when to acquire additional high-fidelity points.
Load-bearing premise
The scaling factor between fidelity levels can be modeled as a parametric linear predictor that permits closed-form EM update formulas and decoupled optimization.
What would settle it
A benchmark experiment on noisy non-nested data in which the recursive method shows no reduction in training time or substantially lower predictive accuracy and uncertainty quality would falsify the performance claims.
Figures




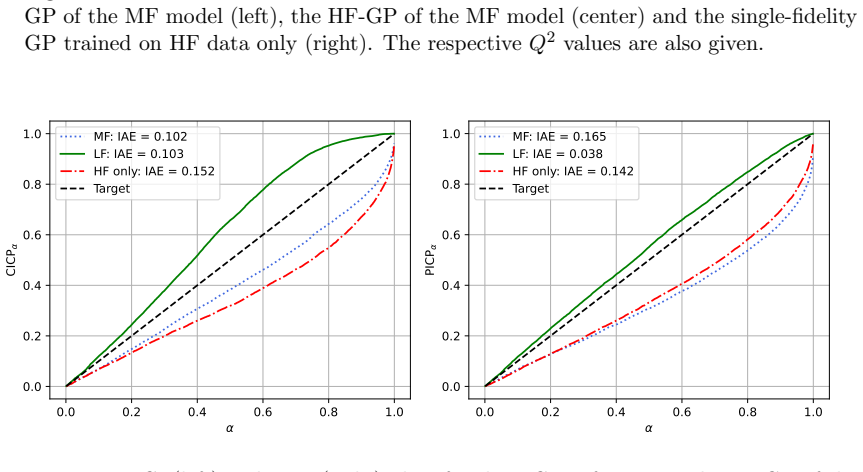





read the original abstract
This paper investigates a recursive formulation of auto-regressive multi-fidelity Gaussian process regression in the challenging setting of noisy and non-nested high- and low-fidelity data. We propose a decoupled optimization strategy based on the expectation-maximization algorithm, which exploits the structure of the recursive model. In particular, we derive closed-form update formulas when the scaling factor is modeled as a parametric linear predictor. This approach is compared with the fully coupled likelihood maximization of the classical non-recursive formulation introduced by Kennedy and O'Hagan. A series of benchmark experiments, covering applications of increasing complexity, highlights the performance of both approaches. The results demonstrate that the proposed recursive strategy significantly reduces training time, especially when large low-fidelity datasets are available, while maintaining competitive predictive accuracy and uncertainty estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a recursive auto-regressive formulation for multi-fidelity Gaussian process regression suited to noisy outputs and non-nested designs. It introduces a decoupled EM optimization strategy that yields closed-form M-step updates when the inter-fidelity scaling factor is represented by a parametric linear predictor, and compares this approach against the fully coupled Kennedy-O'Hagan non-recursive formulation. Benchmark experiments on problems of increasing complexity are used to demonstrate that the recursive method substantially reduces training time (particularly with large low-fidelity sets) while preserving competitive predictive accuracy and uncertainty calibration.
Significance. If the reported performance parity holds under the stated modeling assumptions, the work supplies a practical, computationally scalable route for multi-fidelity GP modeling when abundant low-fidelity data are available. The derivation of closed-form EM updates for the linear scaling case is a clear technical contribution that could be adopted in engineering and scientific applications where high-fidelity evaluations remain expensive.
major comments (2)
- [EM derivation and abstract] The central performance claims rest on the assumption that the scaling factor between fidelity levels admits a parametric linear predictor, which supplies the closed-form M-step and permits independent optimization of the low-fidelity GP and the scaling parameters. The manuscript does not derive approximation error bounds relative to the joint likelihood nor present a controlled misspecification study (e.g., synthetic nonlinear or input-dependent scaling) that would quantify bias in predictive accuracy or uncertainty calibration when this linearity is violated.
- [Benchmark experiments section] Benchmark experiments are invoked to support the time-accuracy trade-off, yet the description lacks explicit details on data splits, exact implementation of the non-recursive baseline, hyperparameter initialization, or the number of Monte Carlo repetitions used for uncertainty metrics. Without these, the strength of evidence for “maintaining competitive predictive accuracy and uncertainty estimation” cannot be fully verified.
minor comments (2)
- [Model formulation] Clarify the precise definition of the linear predictor coefficients for the scaling factor and their relation to the free-parameter count listed in the supplementary material.
- [Results] Add a short table summarizing wall-clock times, RMSE, and negative log predictive density for both methods across all benchmark problems to facilitate direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, proposing revisions where they strengthen the manuscript while maintaining its scope and focus on the linear scaling case for closed-form updates.
read point-by-point responses
-
Referee: [EM derivation and abstract] The central performance claims rest on the assumption that the scaling factor between fidelity levels admits a parametric linear predictor, which supplies the closed-form M-step and permits independent optimization of the low-fidelity GP and the scaling parameters. The manuscript does not derive approximation error bounds relative to the joint likelihood nor present a controlled misspecification study (e.g., synthetic nonlinear or input-dependent scaling) that would quantify bias in predictive accuracy or uncertainty calibration when this linearity is violated.
Authors: The paper deliberately restricts attention to the parametric linear predictor case for the scaling factor precisely because it yields closed-form M-step updates and enables the decoupled EM procedure described in Section 3. This modeling choice is stated explicitly in the abstract and is the basis for the computational advantages claimed relative to the fully coupled Kennedy-O'Hagan formulation (which can also employ a linear scaling). We agree that neither approximation error bounds nor a controlled misspecification study appear in the current manuscript. Adding rigorous bounds would constitute substantial new theoretical work outside the present scope; we therefore cannot supply them in a revision. We will, however, expand the discussion to include a qualitative assessment of the consequences of mild nonlinearity and to recommend more flexible scaling representations when the linearity assumption is in doubt. revision: partial
-
Referee: [Benchmark experiments section] Benchmark experiments are invoked to support the time-accuracy trade-off, yet the description lacks explicit details on data splits, exact implementation of the non-recursive baseline, hyperparameter initialization, or the number of Monte Carlo repetitions used for uncertainty metrics. Without these, the strength of evidence for “maintaining competitive predictive accuracy and uncertainty estimation” cannot be fully verified.
Authors: We accept that the current description of the benchmark experiments is insufficient for full reproducibility. In the revised manuscript we will augment the relevant section with: (i) explicit train/test splits and the precise construction of the non-nested designs for each example; (ii) implementation particulars of the non-recursive baseline, including the optimizer and any external libraries; (iii) the hyperparameter initialization protocol used for both the recursive EM and the coupled approaches; and (iv) the number of Monte Carlo repetitions performed to obtain the uncertainty calibration statistics. These additions will allow readers to verify the reported performance parity. revision: yes
- Deriving approximation error bounds relative to the joint likelihood for the recursive formulation when the linear scaling assumption is violated.
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The paper starts from the standard recursive auto-regressive multi-fidelity GP model, assumes a parametric linear form for the scaling factor between fidelities, and derives closed-form EM updates from that modeling choice. It then compares the resulting decoupled optimization against the fully coupled Kennedy-O'Hagan non-recursive formulation on benchmark data. No step reduces a claimed prediction or uniqueness result to a self-fit or self-citation by construction; the performance claims rest on external experimental comparison rather than internal redefinition. The linear-scaling assumption is an explicit modeling decision whose consequences are evaluated empirically, not smuggled in via prior self-work.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear predictor coefficients for scaling factor
axioms (1)
- domain assumption Auto-regressive structure linking high- and low-fidelity outputs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a decoupled optimization strategy based on the expectation-maximization algorithm, which exploits the structure of the recursive model. In particular, we derive closed-form update formulas when the scaling factor is modeled as a parametric linear predictor.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the recursive formulation of the auto-regressive model when the high-fidelity and low-fidelity data sets are noisy and not necessarily nested
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brian Andrews, Wayne Baldwin, Daniel Sampson, and William Schwab. Continuous bathymetry and elevation models of the Massachusetts coastal zone and continental shelf.U.S. Geological Survey data release, 12 2019.doi:10.5066/F72806T7
-
[2]
Anastasios N Angelopoulos, Stephen Bates, et al. Conformal prediction: A gentle introduction.Foundations and trends®in machine learning, 16(4):494–591, 2023. 25
work page 2023
-
[3]
H. Babaee, C. Bastidas, M. DeFilippo, C. Chryssostomidis, and G. E. Karni- adakis. A multifidelity framework and uncertainty quantification for sea surface temperature in the Massachusetts and Cape Cod bays.Earth and Space Science, 7(2):e2019EA000954, 2020.doi:10.1029/2019EA000954
-
[4]
Fran¸ cois Bachoc. Cross validation and maximum likelihood estimations of hyper- parameters of gaussian processes with model misspecification.Computational Statis- tics & Data Analysis, 66:55–69, 2013.doi:10.1016/j.csda.2013.03.016
-
[5]
Christophette Blanchet-Scalliet, Bruno Demory, Thierry Gonon, and C´ eline Hel- bert. Gaussian process regression on nested spaces.SIAM/ASA Journal on Uncer- tainty Quantification, 11(2):426–451, 2023.doi:10.1137/21M1445053
-
[6]
Dennis D Cox, Jeong-Soo Park, and Clifford E Singer. A statistical method for tuning a computer code to a data base.Computational Statistics & Data Analysis, 37(1):77–92, 2001.doi:10.1016/S0167-9473(00)00057-8
-
[7]
Deep Gaussian Processes for Multi-fidelity Modeling
Kurt Cutajar, Mark Pullin, Andreas Damianou, Neil Lawrence, and Javier Gonz´ alez. Deep gaussian processes for multi-fidelity modeling, 2019.arXiv: 1903.07320
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
Charles Demay, Bertrand Iooss, Loic Le Gratiet, and Amandine Marrel. Model selection based on validation criteria for Gaussian process regression: An applica- tion with highlights on the predictive variance.Quality and Reliability Engineering International, 38(3):1482–1500, 2022.doi:10.1002/qre.2973
-
[9]
B. Efron. Bootstrap Methods: Another Look at the Jackknife.The Annals of Statistics, 7(1):1 – 26, 1979.doi:10.1214/aos/1176344552
-
[10]
Alexander I.J Forrester, Andr´ as S´ obester, and Andy J Keane. Multi-fidelity op- timization via surrogate modelling.Proceedings of the Royal Society A: Math- ematical, Physical and Engineering Sciences, 463(2088):3251–3269, 2007.doi: 10.1098/rspa.2007.1900
-
[11]
Katerina Giannoukou, Stefano Marelli, and Bruno Sudret. Uncertainty-aware mul- tifidelity surrogate modeling with noisy data.ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part A: Civil Engineering, 11(3):04025037, 2025.doi:10.1061/AJRUA6.RUENG-1441
-
[12]
Giulio Gori, Olivier Le Maˆ ıtre, and Pietro M. Congedo. Debiased multifidelity approach to surrogate modeling in aerospace applications.Journal of Aircraft, 0(0):1–14, 2025.doi:10.2514/1.C037765
-
[13]
Gramacy.Surrogates: Gaussian Process Modeling, Design and Optimiza- tion for the Applied Sciences
Robert B. Gramacy.Surrogates: Gaussian Process Modeling, Design and Optimiza- tion for the Applied Sciences. Chapman Hall/CRC, Boca Raton, Florida, 2020. http://bobby.gramacy.com/surrogates/. 26
work page 2020
-
[14]
Mengyang Gu, Xiaojing Wang, and James Berger. Robust gaussian stochastic process emulation.Annals of Statistics, 46, 08 2017.doi:10.1214/17-AOS1648
-
[15]
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2 edition, 2012
work page 2012
-
[16]
Marc Kennedy and Anthony O’Hagan. Predicting the output from a complex computer code when fast approximations are available.Biometrika, 87, 10 2000. doi:10.1093/biomet/87.1.1
-
[18]
Loic Le Gratiet. Bayesian analysis of hierarchical multifidelity codes.SIAM/ASA Journal on Uncertainty Quantification, 1(1):244–269, 2013.doi:10.1137/ 120884122
work page 2013
-
[19]
PhD thesis, Universit´ e Paris-Diderot - Paris VII, October 2013
Loic Le Gratiet.Multi-fidelity Gaussian process regression for computer experi- ments. PhD thesis, Universit´ e Paris-Diderot - Paris VII, October 2013
work page 2013
-
[20]
Loic Le Gratiet and Claire Cannamela. Cokriging-based sequential design strategies using fast cross-validation techniques for multi-fidelity computer codes.Technomet- rics, 57(3):418–427, 2015.doi:10.1080/00401706.2014.928233
-
[21]
Loic Le Gratiet and Josselin Garnier. Recursive co-kriging model for design of computer experiments with multiple levels of fidelity.International Jour- nal for Uncertainty Quantification, 4(5):365–386, 2014.doi:10.1615/Int.J. UncertaintyQuantification.2014006914
-
[22]
Pulong Ma. Objective Bayesian analysis of a cokriging model for hierarchical multi- fidelity codes.SIAM/ASA Journal on Uncertainty Quantification, 8(4):1358–1382, January 2020.doi:10.1137/19m1289893
-
[23]
Amandine Marrel and Bertrand Iooss. Probabilistic surrogate modeling by Gaussian process: A review on recent insights in estimation and validation.Reliability Engi- neering & System Safety, 247:110094, 2024.doi:10.1016/j.ress.2024.110094
-
[24]
M. D. McKay, R. J. Beckman, and W. J. Conover. Comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics, 21(2):239–245, 1979.doi:10.1080/00401706.1979.10489755
-
[25]
Xuhui Meng and George Em Karniadakis. A composite neural network that learns from multi-fidelity data: Application to function approximation and inverse PDE problems.Journal of Computational Physics, 401:109020, January 2020.doi: 10.1016/j.jcp.2019.109020. 27
-
[26]
Hossein Mohammadi and Peter Challenor. Sequential adaptive design for emu- lating costly computer codes.Journal of Statistical Computation and Simulation, 95(3):654–675, 2025.doi:10.1080/00949655.2024.2436013
-
[27]
Rui Paulo. Default priors for Gaussian processes.The Annals of Statistics, 33(2):556 – 582, 2005.doi:10.1214/009053604000001264
-
[28]
P. Perdikaris, M. Raissi, A. Damianou, N. D. Lawrence, and G. E. Karniadakis. Nonlinear information fusion algorithms for data-efficient multi-fidelity modelling. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sci- ences, 473(2198):20160751, 2017.doi:10.1098/rspa.2016.0751
-
[29]
Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. The MIT Press, 11 2005.doi:10.7551/mitpress/3206.001. 0001
-
[30]
Lee W. Schruben. A coverage function for interval estimators of simulation response. Management Science, 26(1):18–27, 1980.doi:10.1287/mnsc.26.1.18
-
[31]
Shifeng Xiong, Peter Z. G. Qian, and C. F. Jeff Wu. Sequential design and analysis of high-accuracy and low-accuracy computer codes.Technometrics, 55(1):37–46, 2013.doi:10.1080/00401706.2012.723572
-
[32]
Yiming Yang, Deyu Ming, and Serge Guillas. Distribution of deep Gaussian process gradients and sequential design for simulators with sharp variations, 2025. URL: https://arxiv.org/abs/2503.16027
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
PhD thesis, Universit´ e Grenoble Alpes, October
Federico Zertuche.Assessment of uncertainty in computer experiments when work- ing with multifidelity simulators. PhD thesis, Universit´ e Grenoble Alpes, October
-
[34]
URL:https://theses.hal.science/tel-01240812
-
[35]
Byrd, Peihuang Lu, and Jorge Nocedal
Ciyou Zhu, Richard H. Byrd, Peihuang Lu, and Jorge Nocedal. Algorithm 778: L- BFGS-B: Fortran subroutines for large-scale bound-constrained optimization.ACM Trans. Math. Softw., 23(4):550–560, December 1997.doi:10.1145/279232.279236. 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.