HIRE: A Hybrid Learned Index for Robust and Efficient Performance under Mixed Workloads
Pith reviewed 2026-05-17 05:00 UTC · model grok-4.3
The pith
HIRE is a hybrid index that blends learned predictions with traditional structures to deliver high throughput and low tail latency under mixed workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
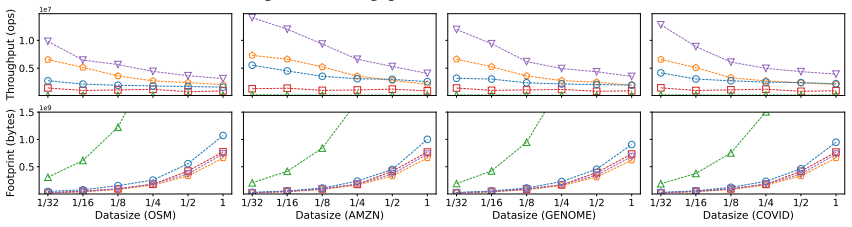
HIRE is a hybrid in-memory index structure that employs hybrid leaf nodes adaptive to data distributions and workloads, model-accelerated internal nodes augmented by log-based updates, a nonblocking cost-driven recalibration mechanism for dynamic data, and an inter-level optimized bulk-loading algorithm that accounts for leaf and internal-node errors. This combination produces efficient and stable performance that outperforms both state-of-the-art learned indexes and traditional structures in range-query throughput, tail latency, and overall stability on multiple real-world datasets, reaching up to 41.7 times higher throughput under mixed workloads and up to 98 percent lower tail latency.
What carries the argument
Hybrid leaf nodes paired with model-accelerated internal nodes that use log-based updates, supported by nonblocking recalibration and inter-level bulk loading, to combine predictive speed with worst-case structural guarantees.
If this is right
- Range-query throughput exceeds that of both learned and traditional indexes under mixed loads.
- Tail latency drops substantially across point, range, and update scenarios.
- Performance remains stable when data distributions and workload mixes change.
- The structure supports efficient dynamic updates without blocking recalibration.
Where Pith is reading between the lines
- The same hybrid pattern of learned prediction plus structural fallback could apply to other system components such as buffers or query planners.
- Testing the recalibration cost on extremely high-update-rate streams would reveal whether the nonblocking design scales to the most dynamic cases.
- If the bulk-loading step proves cheap enough, it might encourage periodic rebuilds in other learned data structures that currently avoid them.
Load-bearing premise
The particular mix of hybrid leaves, logged model internals, nonblocking recalibration, and error-aware bulk loading will keep delivering consistent robustness and speed across real data distributions without new overheads or failure modes.
What would settle it
Running HIRE on a fresh real-world dataset or mixed workload and finding that tail latency stays high or throughput fails to exceed both learned and traditional baselines would show the claimed consistent gains do not hold.
Figures











read the original abstract
Indexes are critical for efficient data retrieval and updates in modern databases. Recent advances in machine learning have led to the development of learned indexes, which model the cumulative distribution function of data to predict search positions and accelerate query processing. While learned indexes substantially outperform traditional structures for point lookups, they often suffer from high tail latency, suboptimal range query performance, and inconsistent effectiveness across diverse workloads. To address these challenges, this paper proposes HIRE, a hybrid in-memory index structure designed to deliver efficient performance consistently. HIRE combines the structural and performance robustness of traditional indexes with the predictive power of model-based prediction to reduce search overhead while maintaining worst-case stability. Specifically, it employs (1) hybrid leaf nodes adaptive to varying data distributions and workloads, (2) model-accelerated internal nodes augmented by log-based updates for efficient updates, (3) a nonblocking, cost-driven recalibration mechanism for dynamic data, and (4) an inter-level optimized bulk-loading algorithm accounting for leaf and internal-node errors. Experimental results on multiple real-world datasets demonstrate that HIRE outperforms both state-of-the-art learned indexes and traditional structures in range-query throughput, tail latency, and overall stability. Compared to state-of-the-art learned indexes and traditional indexes, HIRE achieves up to 41.7$\times$ higher throughput under mixed workloads, reduces tail latency by up to 98% across varying scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HIRE, a hybrid learned index structure for in-memory databases that combines traditional index robustness with machine learning-based predictions. It introduces hybrid leaf nodes adaptive to data distributions, model-accelerated internal nodes with log-based updates, a nonblocking cost-driven recalibration for dynamic data, and an inter-level optimized bulk-loading algorithm. Through experiments on real-world datasets, it claims to outperform state-of-the-art learned indexes and traditional structures, achieving up to 41.7× higher throughput under mixed workloads and up to 98% reduction in tail latency.
Significance. If the experimental results are reproducible and the mechanisms prove robust across diverse workloads, this work could significantly impact database indexing by addressing key limitations of pure learned indexes, such as high tail latency and poor range query performance. The hybrid approach and nonblocking recalibration represent a practical advancement for mixed workload scenarios in modern data systems.
major comments (2)
- [§4.3] §4.3: The nonblocking recalibration mechanism relies on a cost model comparing predicted search cost against rebuild cost. The paper reports only aggregate throughput and latency numbers without isolating recalibration events, providing sensitivity analysis to the cost-threshold hyper-parameter, or testing under update localities and data skew absent from training traces. This directly affects the central claim that the design delivers 98% tail-latency reduction without introducing new worst-case spikes under mixed workloads.
- [Experimental Evaluation] Experimental Evaluation: The performance claims (41.7× throughput, 98% tail-latency reduction) are presented without error bars, full dataset descriptions, workload-generation parameters, or outlier-exclusion criteria. Because these numbers are the primary evidence for outperformance over both learned and traditional baselines, the absence of these details makes the results difficult to interpret or reproduce.
minor comments (2)
- [Abstract] The abstract refers to 'multiple real-world datasets' without naming them; adding the specific dataset names would improve clarity.
- Figures comparing range-query throughput and tail latency should include explicit legends and consistent axis scaling to make the relative gains easier to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment below with our planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.3] The nonblocking recalibration mechanism relies on a cost model comparing predicted search cost against rebuild cost. The paper reports only aggregate throughput and latency numbers without isolating recalibration events, providing sensitivity analysis to the cost-threshold hyper-parameter, or testing under update localities and data skew absent from training traces. This directly affects the central claim that the design delivers 98% tail-latency reduction without introducing new worst-case spikes under mixed workloads.
Authors: We agree that isolating recalibration events and providing sensitivity analysis would better support the tail-latency claims. In the revision we will expand §4.3 with a dedicated breakdown of recalibration frequency and its measured contribution to tail latency, include sensitivity plots for the cost-threshold hyper-parameter, and add experiments that introduce update localities and data skew patterns absent from the original training traces. These additions will directly demonstrate that recalibration does not create new worst-case spikes under mixed workloads. revision: yes
-
Referee: The performance claims (41.7× throughput, 98% tail-latency reduction) are presented without error bars, full dataset descriptions, workload-generation parameters, or outlier-exclusion criteria. Because these numbers are the primary evidence for outperformance over both learned and traditional baselines, the absence of these details makes the results difficult to interpret or reproduce.
Authors: We acknowledge that the current experimental section lacks these reproducibility details. We will revise the Experimental Evaluation section to report error bars on all throughput and latency figures, provide complete dataset descriptions including sizes, distributions, and sources, specify the exact workload-generation parameters and seeds, and explicitly state the outlier-exclusion criteria used in the reported numbers. These changes will make the 41.7× throughput and 98% tail-latency results easier to interpret and reproduce. revision: yes
Circularity Check
No circularity: performance claims rest on external experimental comparisons
full rationale
The paper describes a hybrid index design (hybrid leaves, model-accelerated internals with logs, nonblocking cost-driven recalibration, inter-level bulk loading) and validates it through benchmarks on real-world datasets against learned and traditional baselines. No mathematical derivation chain, fitted-parameter predictions, or self-citation load-bearing steps appear in the provided abstract or design description; throughput and latency numbers are reported as measured outcomes rather than quantities defined in terms of the same fitted values. The cost model in recalibration is presented as a practical heuristic whose accuracy is assessed empirically, not derived from the target results themselves.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The decision to retrain should be made when the expected future performance gain outweighs the immediate, one-time cost of the retraining operation. ... C_gain ≈ Q_l · Δc ... Q_l · (c_buffer(B_th) − c_model) > C_retrain
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HIRE combines the structural and performance robustness of traditional indexes with the predictive power of model-based prediction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jason Ansel, Shoaib Kamil, Kalyan Veeramachaneni, Jonathan Ragan-Kelley, Jef- frey Bosboom, Una-May O’Reilly, and Saman P. Amarasinghe. 2014. OpenTuner: an extensible framework for program autotuning. InInternational Conference on Parallel Architectures and Compilation, PACT’14. 303–316
work page 2014
-
[2]
Pekala, Lev Kruglyak, and Stratos Idreos
Subarna Chatterjee, Mark F. Pekala, Lev Kruglyak, and Stratos Idreos. 2024. Limousine: Blending Learned and Classical Indexes to Self-Design Larger-than- Memory Cloud Storage Engines.Proceedings of the ACM on Management of Data 2, 1 (2024), 47:1–47:28
work page 2024
- [3]
-
[4]
Supawit Chockchowwat. 2022. Tuning Hierarchical Learned Indexes on Disk and Beyond. InACM SIGMOD International Conference on Management of Data. 2515–2517
work page 2022
-
[5]
Supawit Chockchowwat, Wenjie Liu, and Yongjoo Park. 2023. AirIndex: Versatile HIRE: A Hybrid Learned Index for Robust and Efficient Performance under Mixed Workloads SIGMOD ’26, May 31–June 05, 2026, Bengaluru, India Index Tuning Through Data and Storage.Proceedings of the ACM on Management of Data1, 3 (2023), 204:1–204:26
work page 2023
-
[6]
Minguk Choi, Seehwan Yoo, and Jongmoo Choi. 2024. Can Learned Indexes be Built Efficiently? A Deep Dive into Sampling Trade-offs.Proceedings of the ACM on Management of Data2, 3 (2024), 116
work page 2024
-
[7]
Douglas Comer. 1979. Ubiquitous B-tree.Comput. Surveys11, 2 (1979), 121–137
work page 1979
-
[8]
Lixiao Cui, Yijing Luo, Yusen Li, Gang Wang, and Xiaoguang Liu. 2024. When Learned Indexes Meet Persistent Memory: The Analysis and the Optimization. IEEE Trans. Knowl. Data Eng.36, 12 (2024), 9517–9531
work page 2024
-
[9]
Jialin Ding, Umar Farooq Minhas, Jia Yu, Chi Wang, Jaeyoung Do, Yinan Li, Hantian Zhang, Badrish Chandramouli, Johannes Gehrke, Donald Kossmann, et al. 2020. ALEX: An Updatable Adaptive Learned Index. InACM SIGMOD International Conference on Management of Data. 969–984
work page 2020
-
[10]
Paolo Ferragina, Fabrizio Lillo, and Giorgio Vinciguerra. 2020. Why Are Learned Indexes So Effective?. InProceedings of the 37th International Conference on Ma- chine Learning, ICML, Vol. 119. 3123–3132
work page 2020
-
[11]
Paolo Ferragina and Giorgio Vinciguerra. 2020. The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds.Proceedings of the VLDB Endowment13, 8 (2020), 1162–1175
work page 2020
-
[12]
Alex Galakatos, Michael Markovitch, Carsten Binnig, Rodrigo Fonseca, and Tim Kraska. 2019. FITing-Tree: A Data-aware Index Structure. InACM SIGMOD International Conference on Management of Data. 1189–1206
work page 2019
-
[13]
Jiake Ge, Huanchen Zhang, Boyu Shi, Yuanhui Luo, Yunda Guo, Yunpeng Chai, Yuxing Chen, and Anqun Pan. 2023. SALI: A Scalable Adaptive Learned Index Framework based on Probability Models.Proceedings of the ACM on Management of Data1, 4 (2023), 258:1–258:25
work page 2023
-
[14]
Leo J Guibas and Robert Sedgewick. 1978. A dichromatic framework for balanced trees. InAnnual Symposium on Foundations of Computer Science. IEEE, 8–21
work page 1978
-
[15]
Ali Hadian and Thomas Heinis. 2021. Shift-Table: A Low-latency Learned Index for Range Queries using Model Correction. InProceedings of the 24th International Conference on Extending Database Technology, EDBT. 253–264
work page 2021
-
[16]
1996.Statistical digital signal processing and modeling
Monson H Hayes. 1996.Statistical digital signal processing and modeling. John Wiley & Sons
work page 1996
-
[17]
Andreas Kipf, Ryan Marcus, Alexander van Renen, Mihail Stoian, Alfons Kemper, Tim Kraska, and Thomas Neumann. 2020. RadixSpline: a single-pass learned index. InProceedings of the Third International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, aiDM@SIGMOD 2020. 1–5
work page 2020
-
[18]
Tim Kraska, Alex Beutel, Ed H Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018. The Case for Learned Index Structures. InACM SIGMOD International Conference on Management of Data. 489–504
work page 2018
-
[19]
Hai Lan, Zhifeng Bao, J Shane Culpepper, Renata Borovica-Gajic, and Yu Dong
- [20]
-
[21]
Shane Culpepper, Renata Borovica-Gajic, and Yu Dong
Hai Lan, Zhifeng Bao, J. Shane Culpepper, Renata Borovica-Gajic, and Yu Dong
-
[22]
InIEEE International Conference on Data Engineering, ICDE 2024
A Fully On-Disk Updatable Learned Index. InIEEE International Conference on Data Engineering, ICDE 2024. 4856–4869
work page 2024
-
[23]
Pengfei Li, Yu Hua, Jingnan Jia, and Pengfei Zuo. 2021. FINEdex: A Fine-grained Learned Index Scheme for Scalable and Concurrent Memory Systems.Proceedings of the VLDB Endowment15, 2 (2021), 321–334
work page 2021
-
[24]
Pengfei Li, Hua Lu, Rong Zhu, Bolin Ding, Long Yang, and Gang Pan. 2023. DILI: A Distribution-Driven Learned Index.Proceedings of the VLDB Endowment16, 9 (2023), 2212–2224
work page 2023
-
[25]
Liang Liang, Guang Yang, Ali Hadian, Luis Alberto Croquevielle, and Thomas Hei- nis. 2024. SWIX: A Memory-efficient Sliding Window Learned Index.Proceedings of the ACM on Management of Data2, 1 (2024), 41:1–41:26
work page 2024
-
[26]
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2016. Continuous control with deep reinforcement learning. In4th International Conference on Learning Representations, ICLR’16
work page 2016
- [27]
-
[28]
Qiyu Liu, Maocheng Li, Yuxiang Zeng, Yanyan Shen, and Lei Chen. 2025. How good are multi-dimensional learned indexes? An experimental survey.VLDB J. 34, 2 (2025), 17
work page 2025
-
[29]
Baotong Lu, Jialin Ding, Eric Lo, Umar Farooq Minhas, and Tianzheng Wang. 2021. APEX: A High-Performance Learned Index on Persistent Memory.Proceedings of the VLDB Endowment15, 3 (2021), 597–610
work page 2021
-
[30]
Ryan Marcus, Andreas Kipf, Alexander van Renen, Mihail Stoian, Sanchit Misra, Alfons Kemper, Thomas Neumann, and Tim Kraska. 2020. Benchmarking Learned Indexes.Proceedings of the VLDB Endowment14, 1 (2020), 1–13
work page 2020
-
[31]
Paul E McKenney, Jonathan Appavoo, Andi Kleen, Orran Krieger, Rusty Russell, Dipankar Sarma, and Maneesh Soni. 2001. Read-copy update. InAUUG Conference Proceedings, Vol. 175
work page 2001
-
[32]
O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth J
Patrick E. O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth J. O’Neil. 1996. The Log-Structured Merge-Tree (LSM-Tree).Acta Informatica33, 4 (1996), 351– 385
work page 1996
-
[33]
Tobias Schmidt, Andreas Kipf, Dominik Horn, Gaurav Saxena, and Tim Kraska
-
[34]
InCompanion of the 2024 International Conference on Management of Data, SIGMOD/PODS 2024
Predicate Caching: Query-Driven Secondary Indexing for Cloud Data Warehouses. InCompanion of the 2024 International Conference on Management of Data, SIGMOD/PODS 2024. ACM, 347–359
work page 2024
-
[35]
Abraham Silberschatz, Henry F Korth, and Shashank Sudarshan. 2011. Database system concepts. (2011)
work page 2011
- [36]
-
[37]
Zhaoyan Sun, Xuanhe Zhou, and Guoliang Li. 2023. Learned Index: A Com- prehensive Experimental Evaluation.Proceedings of the VLDB Endowment16, 8 (2023), 1992–2004
work page 2023
-
[38]
Chuzhe Tang, Youyun Wang, Zhiyuan Dong, Gansen Hu, Zhaoguo Wang, Minjie Wang, and Haibo Chen. 2020. XIndex: a scalable learned index for multicore data storage. InACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 308–320
work page 2020
-
[39]
Taiyi Wang, Liang Liang, Guang Yang, Thomas Heinis, and Eiko Yoneki. 2025. A New Paradigm in Tuning Learned Indexes: A Reinforcement Learning Enhanced Approach.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
work page 2025
-
[40]
Youyun Wang, Chuzhe Tang, Zhaoguo Wang, and Haibo Chen. 2020. SIndex: a scalable learned index for string keys. InProceedings of the 11th ACM SIGOPS Asia-Pacific Workshop on Systems. 17–24
work page 2020
-
[41]
Zhonghua Wang, Chen Ding, Fengguang Song, Kai Lu, Jiguang Wan, Zhihu Tan, Changsheng Xie, and Guokuan Li. 2024. WIPE: A Write-Optimized Learned Index for Persistent Memory.ACM Transactions on Architecture and Code Optimization 21, 2 (2024), 1–25
work page 2024
-
[42]
Chaichon Wongkham, Baotong Lu, Chris Liu, Zhicong Zhong, Eric Lo, and Tianzheng Wang. 2022. Are Updatable Learned Indexes Ready?Proceedings of the VLDB Endowment15, 11 (2022), 3004–3017
work page 2022
-
[43]
Jiacheng Wu, Yong Zhang, Shimin Chen, Yu Chen, Jin Wang, and Chunxiao Xing
-
[44]
Updatable Learned Index with Precise Positions.Proceedings of the VLDB Endowment14, 8 (2021), 1276–1288
work page 2021
-
[45]
Guang Yang, Liang Liang, Ali Hadian, and Thomas Heinis. 2023. FLIRT: A Fast Learned Index for Rolling Time frames. InProceedings 26th International Conference on Extending Database Technology, EDBT. 234–246
work page 2023
-
[46]
Yifan Yang and Shimin Chen. 2024. LITS: An Optimized Learned Index for Strings. Proceedings of the VLDB Endowment17, 11 (2024), 3415–3427
work page 2024
-
[47]
Jiaoyi Zhang and Yihan Gao. 2022. CARMI: A Cache-Aware Learned Index with a Cost-based Construction Algorithm.Proceedings of the VLDB Endowment15, 11 (2022), 2679–2691
work page 2022
-
[48]
Jiaoyi Zhang, Kai Su, and Huanchen Zhang. 2024. Making In-Memory Learned Indexes Efficient on Disk.Proceedings of the ACM on Management of Data2, 3 (2024), 1–26
work page 2024
-
[49]
Rui Zhang, Yukai Huang, Sicheng Liang, Shangyi Sun, Shaonan Ma, Chengy- ing Huan, Lulu Chen, Zhihui Lu, Yang Xu, Ming Yan, et al . 2024. Revisiting Learned Index with Byte-addressable Persistent Storage. InProceedings of the 53rd International Conference on Parallel Processing. 929–938
work page 2024
-
[50]
Shunkang Zhang, Ji Qi, Xin Yao, and André Brinkmann. 2024. Hyper: A High- Performance and Memory-Efficient Learned Index via Hybrid Construction. Proceedings of the ACM on Management of Data2, 3 (2024), 1–26
work page 2024
-
[51]
Xun Zhong, Yong Zhang, Yu Chen, Chao Li, and Chunxiao Xing. 2022. Learned index on GPU. In2022 IEEE 38th International Conference on Data Engineering Workshops (ICDEW). IEEE, 117–122
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.