PystachIO: Efficient Distributed GPU Query Processing with PyTorch over Fast Networks & Fast Storage
Pith reviewed 2026-05-21 18:48 UTC · model grok-4.3
The pith
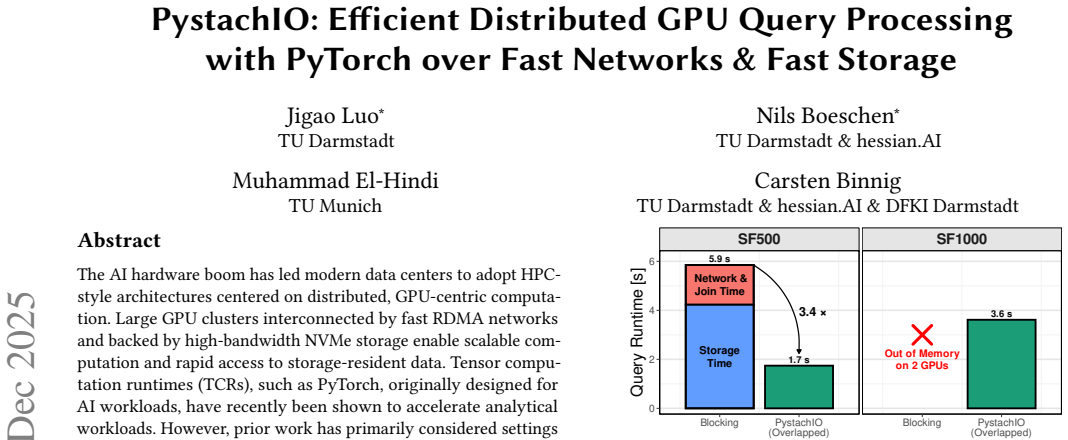
PystachIO optimizes PyTorch I/O overlap to deliver up to 3x speedups for distributed GPU query processing on storage-resident OLAP data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PystachIO is a PyTorch-based distributed OLAP engine that pairs fast RDMA network and high-bandwidth NVMe storage I/O with optimizations that maximize overlap between computation and data movement, thereby raising utilization of GPU, network, and storage resources and producing up to 3x end-to-end speedups over existing distributed GPU query processing approaches.
What carries the argument
A collection of PyTorch-level optimizations that enforce sufficient overlap of computation with network and storage transfers over RDMA and NVMe.
If this is right
- Up to 3x end-to-end speedups over prior distributed GPU approaches become attainable.
- Query processing scales to storage-resident data that exceeds total GPU memory.
- GPU, network, and storage bandwidth see higher utilization in distributed GPU clusters.
- AI tensor runtimes become practical bases for analytical database engines.
Where Pith is reading between the lines
- The same overlap techniques could allow AI training and analytics jobs to share GPU clusters and fast interconnects without separate infrastructure.
- Porting the approach to other tensor runtimes would test whether the gains are specific to PyTorch or more general.
- Measuring performance across query mixes with varying data skew or network latency would clarify which optimizations matter most in practice.
Load-bearing premise
The proposed optimizations will reliably increase bandwidth utilization across different workloads and hardware configurations without creating new bottlenecks.
What would settle it
Running the same queries and hardware with the PystachIO optimizations applied but measuring no improvement or a slowdown relative to naive PyTorch I/O would show the central performance claim does not hold.
Figures
















read the original abstract
The AI hardware boom has led modern data centers to adopt HPC-style architectures centered on distributed, GPU-centric computation. Large GPU clusters interconnected by fast RDMA networks and backed by high-bandwidth NVMe storage enable scalable computation and rapid access to storage-resident data. Tensor computation runtimes (TCRs), such as PyTorch, originally designed for AI workloads, have recently been shown to accelerate analytical workloads. However, prior work has primarily considered settings where the data fits in aggregated GPU memory. In this paper, we systematically study how TCRs can support scalable, distributed query processing for large-scale, storage-resident OLAP workloads. Although TCRs provide abstractions for network and storage I/O, naive use often underutilizes GPU and I/O bandwidth due to insufficient overlap between computation and data movement. As a core contribution, we present PystachIO, a prototype of a PyTorch-based distributed OLAP engine that combines fast network and storage I/O with key optimizations to maximize GPU, network, and storage utilization. Our evaluation shows up to 3x end-to-end speedups over existing distributed GPU-based query processing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PystachIO, a PyTorch-based prototype for distributed OLAP query processing on storage-resident data in GPU clusters equipped with RDMA networks and high-bandwidth NVMe storage. It argues that naive use of PyTorch I/O abstractions underutilizes GPU and bandwidth resources due to insufficient overlap of computation and data movement, and introduces optimizations (including custom CUDA streams for RDMA overlap and prefetch scheduling) to address this. The central empirical claim is that these techniques deliver up to 3x end-to-end speedups relative to prior distributed GPU query engines.
Significance. If the speedups prove robust and attributable to the described I/O-overlap techniques rather than implementation artifacts, the work would be significant for showing how tensor runtimes originally built for AI can be adapted to out-of-core analytical workloads at scale. This could help bridge the gap between ML frameworks and database systems in modern GPU-centric data centers, with potential for broader adoption of PyTorch-style abstractions in query engines.
major comments (1)
- [Evaluation] Evaluation section: The central claim of up to 3x end-to-end speedups is presented without reported details on workloads, data sizes, baselines, or measurement methodology. Without an ablation study that disables individual optimizations (e.g., RDMA overlap via custom CUDA streams or prefetch scheduling) while holding the rest of the PyTorch runtime fixed, or without re-implementing at least one baseline inside the identical PyTorch stack, it is impossible to attribute gains specifically to the proposed I/O fixes versus differences in query planning, data layout, or engineering effort.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a concise table or paragraph summarizing the exact set of proposed optimizations and how each targets a specific underutilization issue.
- [Methods] Notation for network and storage bandwidth utilization metrics should be defined explicitly before their first use in the methods or evaluation sections to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We agree that the evaluation section requires additional details and an ablation study to strengthen attribution of the reported speedups to the I/O optimizations. We will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central claim of up to 3x end-to-end speedups is presented without reported details on workloads, data sizes, baselines, or measurement methodology. Without an ablation study that disables individual optimizations (e.g., RDMA overlap via custom CUDA streams or prefetch scheduling) while holding the rest of the PyTorch runtime fixed, or without re-implementing at least one baseline inside the identical PyTorch stack, it is impossible to attribute gains specifically to the proposed I/O fixes versus differences in query planning, data layout, or engineering effort.
Authors: We agree that the current manuscript lacks sufficient detail in the evaluation section, which limits the ability to attribute gains specifically to the I/O-overlap techniques. In the revision we will expand this section to report the exact workloads and queries, data sizes and scale factors, baseline systems with versions and configurations, and the full measurement methodology including hardware, repetition counts, and timing procedures. We will also add an ablation study that disables RDMA overlap via custom CUDA streams and prefetch scheduling independently while holding the remainder of the PyTorch runtime fixed. This will quantify the incremental benefit of each optimization. Re-implementing an external baseline inside the PyTorch stack is outside the scope of the work and would require substantial unrelated engineering; the internal ablation study addresses the core attribution concern without that requirement. revision: yes
Circularity Check
No circularity: empirical system evaluation with independent benchmarks
full rationale
The paper describes a prototype system (PystachIO) and reports measured end-to-end speedups on storage-resident OLAP workloads. No mathematical derivation chain, fitted parameters, or equations appear in the abstract or context. The central claim rests on direct experimental comparison rather than any quantity defined in terms of itself or reduced via self-citation to the authors' prior inputs. The evaluation is therefore self-contained against external hardware and baseline systems.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PystachIO ... overlaps storage I/O, networking, and computation ... chunking ... deferred synchronization ... reader combining ... dynamic buffering
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
naive use of TCR I/O abstractions underutilizes GPU and I/O bandwidth
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Daniel Abadi. 2025. Parquet and ORC’s many shortfalls for machine learning (ML) workloads, and what should be done about them. https://www.starburst. io/blog/parquet-orc-machine-learning/
work page 2025
-
[2]
Azim Afroozeh, Lotte Felius, and Peter Boncz. 2024. Accelerating GPU Data Processing using FastLanes Compression. InProceedings of the 20th International Workshop on Data Management on New Hardware, DaMoN 2024, Santiago, Chile, 10 June 2024, Carsten Binnig and Nesime Tatbul (Eds.). ACM, 8:1–8:11. https: //doi.org/10.1145/3662010.3663450
-
[3]
Felipe Aramburú, William Malpica, Kaouther Abrougui, Amin Aramoon, Romulo Auccapuclla, Claude Brisson, Matthijs Brobbel, Colby Farrell, Pradeep Garigipati, Joost Hoozemans, Supun Kamburugamuve, Akhil Nair, Alexander Ocsa, Johan Peltenburg, Rubén Quesada López, Deepak Sihag, Ahmet Uyar, Dhruv Vats, Michael Wendt, Jignesh M. Patel, and Rodrigo Aramburú. 202...
-
[4]
Claude Barthels, Gustavo Alonso, Torsten Hoefler, Timo Schneider, and Ingo Müller. 2017. Distributed Join Algorithms on Thousands of Cores.Proc. VLDB Endow.10, 5 (2017), 517–528. https://doi.org/10.14778/3055540.3055545
-
[5]
Nils Boeschen, Tobias Ziegler, and Carsten Binnig. 2024. GOLAP: A GPU-in- Data-Path Architecture for High-Speed OLAP.Proc. ACM Manag. Data2, 6 (2024), 237:1–237:26. https://doi.org/10.1145/3698812
-
[6]
Sebastian Breß, Henning Funke, and Jens Teubner. 2016. Robust Query Processing in Co-Processor-accelerated Databases. InProceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, June 26 - July 01, 2016, Fatma Özcan, Georgia Koutrika, and Sam Madden (Eds.). ACM, 1891–1906. https://doi.org/10.114...
-
[7]
Jiashen Cao, Rathijit Sen, Matteo Interlandi, Joy Arulraj, and Hyesoon Kim. 2023. GPU Database Systems Characterization and Optimization.Proc. VLDB Endow. 17, 3 (2023), 441–454. https://doi.org/10.14778/3632093.3632107
-
[8]
NVIDIA Corporation. 2025. NVIDIA DGX A100 Hardware Overview. https://docs. nvidia.com/dgx/dgxa100-user-guide/introduction-to-dgxa100.html. Accessed: 2025-11-29
work page 2025
-
[9]
Microsoft Fabric. 2025. Understand V-Order for Microsoft Fabric Warehouse. https://learn.microsoft.com/en-us/fabric/data-warehouse/v-order. Accessed: 2025-11-27
work page 2025
-
[10]
Nuno Faria and Andrew Lamb with Apache DataFusion Contributors. 2025. DataFusion Pull Request: Cache Parquet metadata in built in parquet reader. https://github.com/apache/datafusion/pull/16971. Accessed: 2025-11-26
work page 2025
-
[11]
NumFOCUS Foundation. 2025. NumPy. https://numpy.org/
work page 2025
-
[12]
NumFOCUS Foundation and Wes McKinney. 2025. pandas - Python Data Analysis Library. https://pandas.pydata.org/
work page 2025
-
[13]
Hao Gao and Nikolai Sakharnykh. 2021. Scaling Joins to a Thousand GPUs. In International Workshop on Accelerating Analytics and Data Management Systems Using Modern Processor and Storage Architectures, ADMS@VLDB 2021, Copen- hagen, Denmark, August 16, 2021, Rajesh Bordawekar and Tirthankar Lahiri (Eds.). 55–64. http://www.adms-conf.org/2021-camera-ready/g...
work page 2021
-
[14]
Chengxin Guo, Hong Chen, Feng Zhang, and Cuiping Li. 2019. Distributed Join Algorithms on Multi-CPU Clusters with GPUDirect RDMA. InProceedings of the 48th International Conference on Parallel Processing, ICPP 2019, Kyoto, Japan, August 05-08, 2019. ACM, 65:1–65:10. https://doi.org/10.1145/3337821.3337862
-
[15]
Tushar Gupta. 2024. Evolution of Data Center Design to Handle AI Workloads. In34th International Telecommunication Networks and Applications Conference, ITNAC 2024, Sydney, Australia, November 27-29, 2024. IEEE, 1–8. https://doi.org/ 10.1109/ITNAC62915.2024.10815309
-
[16]
Xiangpeng Hao. 2024. Caching in DataFusion. https://blog.xiangpeng.systems/ posts/caching-datafusion/. Accessed: 2025-11-26
work page 2024
-
[17]
Xiangpeng Hao and Andrew Lamb. 2024. How Good is Parquet for Wide Tables (Machine Learning Workloads) Really? https://www.influxdata.com/blog/how- good-parquet-wide-tables/
work page 2024
-
[18]
Xiangpeng Hao, Andrew Lamb, Qi Zhu, Weston Pace, and Jigao Luo. 2025. Project idea: How good is well-configured parquet compared to proprietary file formats? https://github.com/XiangpengHao/liquid-cache/issues/227. Accessed: 2025-11- 27
work page 2025
-
[19]
Dong He, Supun Chathuranga Nakandala, Dalitso Banda, Rathijit Sen, Karla Saur, Kwanghyun Park, Carlo Curino, Jesús Camacho-Rodríguez, Konstanti- nos Karanasos, and Matteo Interlandi. 2022. Query Processing on Tensor Computation Runtimes.Proc. VLDB Endow.15, 11 (2022), 2811–2825. https: //doi.org/10.14778/3551793.3551833
-
[20]
Sven Hepkema, Azim Afroozeh, Charlotte Felius, Peter Boncz, and Stefan Manegold. 2025. G-ALP: Rethinking Light-weight Encodings for GPUs. In Proceedings of the 21st International Workshop on Data Management on New Hardware, DaMoN 2025, Berlin, Germany, June 22-27, 2025. ACM, 11:1–11:10. https://doi.org/10.1145/3736227.3736242
- [21]
-
[22]
Marko Kabic, Shriram Chandran, and Gustavo Alonso. 2025. Maximus: A Modular Accelerated Query Engine for Data Analytics on Heterogeneous Systems.Proc. ACM Manag. Data3, 3 (2025), 187:1–187:25. https://doi.org/10.1145/3725324
-
[23]
Greg Kimball, Zoltan Arnold Nagy, Devavret Makkar, Daniel Bauer, and Chengcheng Jin. 2025. Accelerating Large-Scale Data Analytics with GPU-Native Velox and NVIDIA cuDF. https://developer.nvidia.com/blog/accelerating-large- scale-data-analytics-with-gpu-native-velox-and-nvidia-cudf/#hybrid_cpu- gpu_execution_in_apache_spark Accessed: 2025-11-26
work page 2025
-
[24]
Greg Kimball and Karthikeyan Natarajan. 2025. Accelerating Velox with RAPIDS cuDF - VeloxCon 2025. https://prestodb.io/wp-content/uploads/presto-users/ Accelerating-Velox-with-RAPIDS-cuDF-VeloxCon-April-2025.pdf Accessed: 2025-11-26
work page 2025
-
[25]
Laurens Kuiper. 2025. Query Engines: Gatekeepers of the Parquet File Format. https://duckdb.org/2025/01/22/parquet-encodings. Accessed: 2025-11-27
work page 2025
-
[26]
Maximilian Kuschewski, David Sauerwein, Adnan Alhomssi, and Viktor Leis
-
[27]
BtrBlocks: Efficient Columnar Compression for Data Lakes.Proc. ACM Manag. Data1, 2 (2023), 118:1–118:26. https://doi.org/10.1145/3589263
-
[28]
Andrew Lamb. 2025. Apache Parquet Metadata Parsing Benchmarks. https: //github.com/alamb/parquet_footer_parsing. Accessed: 2025-11-26
work page 2025
-
[29]
Andrew Lamb, Yijie Shen, Daniël Heres, Jayjeet Chakraborty, Mehmet Ozan Kabak, Liang-Chi Hsieh, and Chao Sun. 2024. Apache Arrow DataFusion: A Fast, Embeddable, Modular Analytic Query Engine. InCompanion of the 2024 International Conference on Management of Data, SIGMOD/PODS 2024, Santiago, Chile, June 9-15, 2024, Pablo Barceló, Nayat Sánchez-Pi, Alexandr...
-
[30]
Yinan Li, Bailu Ding, Ziyun Wei, Lukas M. Maas, Momin Al-Ghosien, Spyros Blanas, Nicolas Bruno, Carlo Curino, Matteo Interlandi, Craig Peeper, Kaushik Rajan, Surajit Chaudhuri, and Johannes Gehrke. 2025. Scaling GPU-Accelerated Databases beyond GPU Memory Size.Proc. VLDB Endow.18, 11 (2025), 4518–4531. https://www.vldb.org/pvldb/vol18/p4518-li.pdf
work page 2025
-
[31]
Chunwei Liu, Anna Pavlenko, Matteo Interlandi, and Brandon Haynes. 2023. A Deep Dive into Common Open Formats for Analytical DBMSs.Proc. VLDB Endow.16, 11 (2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
-
[32]
Jigao Luo. 2025. cuDF Issue: Unstable pipelining performance in Parquet reading due to mis-sync. https://github.com/rapidsai/cudf/issues/18967. Accessed: 2025-11-26
work page 2025
-
[33]
Jigao Luo. 2025. [Story] Towards a faster Parquet reader with pipelining and mul- tistream optimization. https://github.com/rapidsai/cudf/issues/18892. Accessed: 2025-11-27
work page 2025
-
[34]
Jigao Luo and Muhammad Haseeb. 2025. cuDF POC Pull Request: Metadata caching prototype in Parquet reader. https://github.com/rapidsai/cudf/pull/18891. Accessed: 2025-11-26
work page 2025
-
[36]
Pump Up the Volume: Processing Large Data on GPUs with Fast In- terconnects. InProceedings of the 2020 International Conference on Manage- ment of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, David Maier, Rachel Pottinger, AnHai Doan, Wang-Chiew Tan, Abdussalam Alawini, and Hung Q. Ngo (Eds.). ACM, 1633–1649. http...
-
[37]
Clemens Lutz, Sebastian Breß, Steffen Zeuch, Tilmann Rabl, and Volker Markl
-
[38]
Triton Join: Efficiently Scaling to a Large Join State on GPUs with Fast Interconnects. InSIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM, 1017–1032. https://doi.org/10.1145/3514221.3517911
-
[39]
Linux Foundation Meta AI. 2025. PyTorch. https://pytorch.org/
work page 2025
- [40]
-
[41]
Hamish Nicholson, Konstantinos Chasialis, Antonio Boffa, and Anastasia Aila- maki. 2025. The Effectiveness of Compression for GPU-Accelerated Queries on Out-of-Memory Datasets. InProceedings of the 21st International Workshop on Data Management on New Hardware, DaMoN 2025, Berlin, Germany, June 22-27,
work page 2025
-
[42]
https://doi.org/10.1145/3736227.3736240
ACM, 10:1–10:10. https://doi.org/10.1145/3736227.3736240
-
[43]
Jesse Noffsinger, Maria Goodpaster, Mark Patel, Haley Chang, Pankaj Sachdeva, and Arjita Bhan. 2025. The cost of compute: A $ 7 trillion race to scale data centers. https://www.mckinsey.com/industries/technology-media-and- telecommunications/our-insights/the-cost-of-compute-a-7-trillion-dollar- race-to-scale-data-centers
work page 2025
-
[44]
NVIDIA. 2025. NCCL. https://developer.nvidia.com/nccl
work page 2025
-
[45]
NVIDIA. 2025. NVIDIA GPUDirect RDMA. https://docs.nvidia.com/cuda/ gpudirect-rdma/
work page 2025
-
[46]
NVIDIA. 2025. NVIDIA GPUDirect Storage. https://docs.nvidia.com/gpudirect- storage/
work page 2025
-
[47]
NVIDIA. 2025. RAPIDS Accelerator for Apache Spark. https://docs.nvidia.com/ spark-rapids/index.html. Accessed: 2025-11-28. 13
work page 2025
-
[48]
2025.CUB: Cooperative primitives for CUDA
NVIDIA Corporation. 2025.CUB: Cooperative primitives for CUDA. https: //nvidia.github.io/cccl/cub/ Accessed: 2025-11-26
work page 2025
-
[49]
2025.CUDA C Programming Guide: Concurrent Execution between Host and Device
NVIDIA Corporation. 2025.CUDA C Programming Guide: Concurrent Execution between Host and Device. https://docs.nvidia.com/cuda/cuda-c-programming- guide/index.html#concurrent-execution-host-device Accessed: 2025-11-26
work page 2025
-
[50]
2025.CUDA Runtime API: API Synchronization Behav- ior
NVIDIA Corporation. 2025.CUDA Runtime API: API Synchronization Behav- ior. https://docs.nvidia.com/cuda/cuda-runtime-api/api-sync-behavior.html# api-sync-behavior__memcpy-async Accessed: 2025-11-26
work page 2025
-
[51]
2025.Thrust: Parallel Algorithms Library
NVIDIA Corporation. 2025.Thrust: Parallel Algorithms Library. https://developer. nvidia.com/thrust Accessed: 2025-11-26
work page 2025
- [52]
-
[53]
NVIDIA NCCL Repository. 2025. NCCL Overlap Issue. https://github.com/ NVIDIA/nccl/issues/338
work page 2025
-
[54]
Anil Shanbhag, Samuel Madden, and Xiangyao Yu. 2020. A Study of the Funda- mental Performance Characteristics of GPUs and CPUs for Database Analytics. InProceedings of the 2020 International Conference on Management of Data, SIG- MOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, David Maier, Rachel Pottinger, AnHai Doan, Wang-C...
-
[55]
Amazon Staff. 2025. Amazon to invest up to $ 50 billion to ex- pand AI and supercomputing infrastructure for US Government agen- cies. https://www.aboutamazon.com/news/company-news/amazon-ai- investment-us-federal-agencies
work page 2025
-
[56]
Polars Team. 2024. GPU acceleration with Polars and NVIDIA RAPIDS. https: //pola.rs/posts/gpu-engine-release/. Accessed: 2025-11-28
work page 2024
-
[57]
RAPIDS Development Team. 2025. NVIDIA RAPIDS KvikIO. https://docs.rapids. ai/api/kvikio/stable/
work page 2025
-
[58]
RAPIDS Development Team. 2025. NVIDIA RAPIDS libcudf, pylibcudf and cuDF: GPU DataFrame Library. https://github.com/rapidsai/cudf
work page 2025
-
[59]
RAPIDS Development Team. 2025. NVIDIA RMM: RAPIDS Memory Manager. https://github.com/rapidsai/rmm
work page 2025
-
[60]
Lasse Thostrup, Gloria Doci, Nils Boeschen, Manisha Luthra, and Carsten Binnig
-
[61]
Distributed GPU Joins on Fast RDMA-capable Networks.Proc. ACM Manag. Data1, 1 (2023), 29:1–29:26. https://doi.org/10.1145/3588709
-
[62]
Deepak Vohra. 2016.Practical Hadoop Ecosystem: A Definitive Guide to Hadoop- Related Frameworks and Tools(1st ed.). Apress, USA. https://doi.org/10.1007/978- 1-4842-2199-0
-
[63]
Yunsong Wang. 2025. cuCollections Pull Request: Use pinned host memory for improved async performance. https://github.com/NVIDIA/cuCollections/pull/
work page 2025
-
[64]
Accessed: 2025-11-27
work page 2025
-
[65]
Jake Hemstad with NVIDIA CCCL Team. 2023. CCCL Issue: Universal 64-bit index type support in Thrust/CUB algorithms. https://github.com/NVIDIA/cccl/ issues/47. Accessed: 2025-11-26
work page 2023
-
[66]
Greg Kimball with RAPIDS cuDF Team. 2023. cuDF Issue: Add 64-bit size type option at build-time for libcudf. https://github.com/rapidsai/cudf/issues/13159. Accessed: 2025-11-26
work page 2023
-
[67]
Bowen Wu, Wei Cui, Carlo Curino, Matteo Interlandi, and Rathijit Sen. 2025. Terabyte-Scale Analytics in the Blink of an Eye.CoRRabs/2506.09226 (2025). https://doi.org/10.48550/ARXIV.2506.09226 arXiv:2506.09226
-
[68]
Zhisheng Ye, Wei Gao, Qinghao Hu, Peng Sun, Xiaolin Wang, Yingwei Luo, Tianwei Zhang, and Yonggang Wen. 2024. Deep Learning Workload Scheduling in GPU Datacenters: A Survey.ACM Comput. Surv.56, 6 (2024), 146:1–146:38. https://doi.org/10.1145/3638757
-
[69]
Bobbi Yogatama, Yifei Yang, Kevin Kristensen, Devesh Sarda, Abigale Kim, Adrian Cockcroft, Yu Teng, Joshua Patterson, Gregory Kimball, Wes McKinney, Weiwei Gong, and Xiangyao Yu. 2025. Rethinking Analytical Processing in the GPU Era.CoRRabs/2508.04701 (2025). https://doi.org/10.48550/ARXIV.2508.04701 arXiv:2508.04701
-
[70]
Ben Zaitlen, Peter Entschev, and Rick Zamora. 2024. Best Practices for Multi-GPU Data Analysis Using RAPIDS with Dask. https://developer.nvidia.com/blog/best- practices-for-multi-gpu-data-analysis-using-rapids-with-dask/. Accessed: 2025- 11-28
work page 2024
-
[71]
Xinyu Zeng, Yulong Hui, Jiahong Shen, Andrew Pavlo, Wes McKinney, and Huanchen Zhang. 2023. An Empirical Evaluation of Columnar Storage Formats. Proc. VLDB Endow.17, 2 (2023), 148–161. https://doi.org/10.14778/3626292. 3626298 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.