Semiparametric Robust Estimation of Population Location
Pith reviewed 2026-05-21 18:43 UTC · model grok-4.3
The pith
A semiparametric estimator models only the dominant signal parametrically while absorbing the noisy background nonparametrically through observed-likelihood maximization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that maximizing the observed likelihood under a semiparametric model—parametric for the dominant component and fully nonparametric for the background—produces a robust estimator for the population location parameter that remains consistent and asymptotically efficient while being made practical by an FFT-accelerated approximation.
What carries the argument
The FFT plug-in approximation to the nonparametric likelihood component, which enables fast maximization of the observed likelihood without explicit downweighting of background observations.
If this is right
- The estimator remains consistent and asymptotically normal under the stated semiparametric assumptions.
- Computational cost drops by an order of magnitude relative to vanilla weighted EM while statistical accuracy is retained.
- Bias from misspecifying the background distribution is avoided because the nonparametric part absorbs it.
- The approach scales to large samples without the power loss typical of fully nonparametric methods.
Where Pith is reading between the lines
- The same semiparametric structure could be applied to location-scale or shape estimation by extending the parametric component.
- In domains such as astronomy or sensor data, the method might separate a known parametric signal from complex unstructured noise without strong assumptions on the noise law.
- Theoretical work could derive exact convergence rates when the nonparametric background is estimated with kernels or splines.
Load-bearing premise
The dominant signal must admit a correctly specified parametric model, and the FFT approximation must not introduce bias that destroys the estimator's large-sample properties.
What would settle it
A Monte Carlo experiment generating data from a known parametric dominant component plus varying nonparametric backgrounds, then checking whether the estimator recovers the true location at the rate and variance predicted by semiparametric theory.
Figures

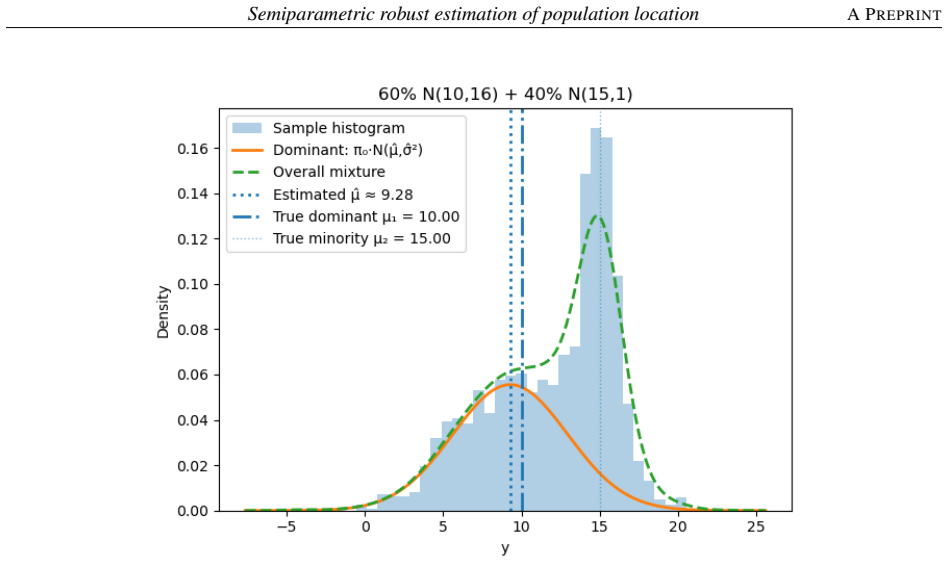
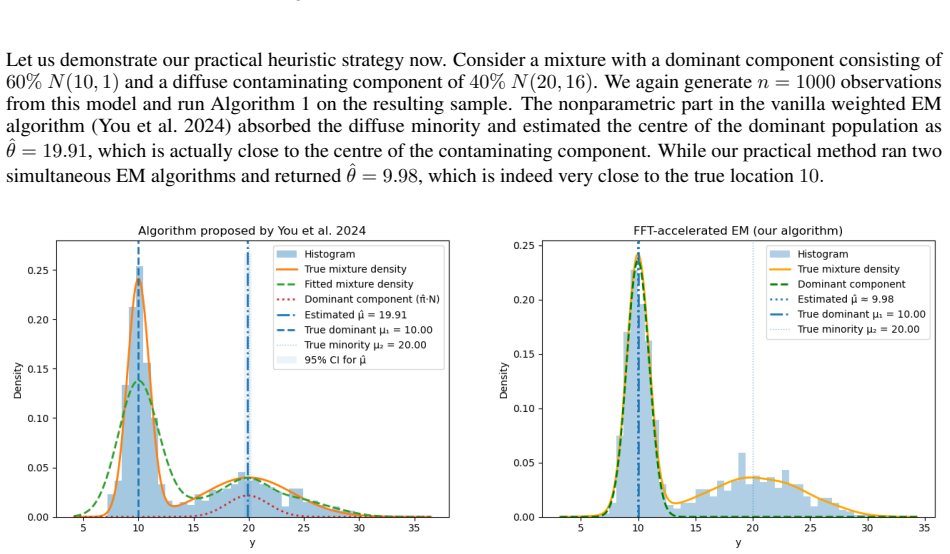


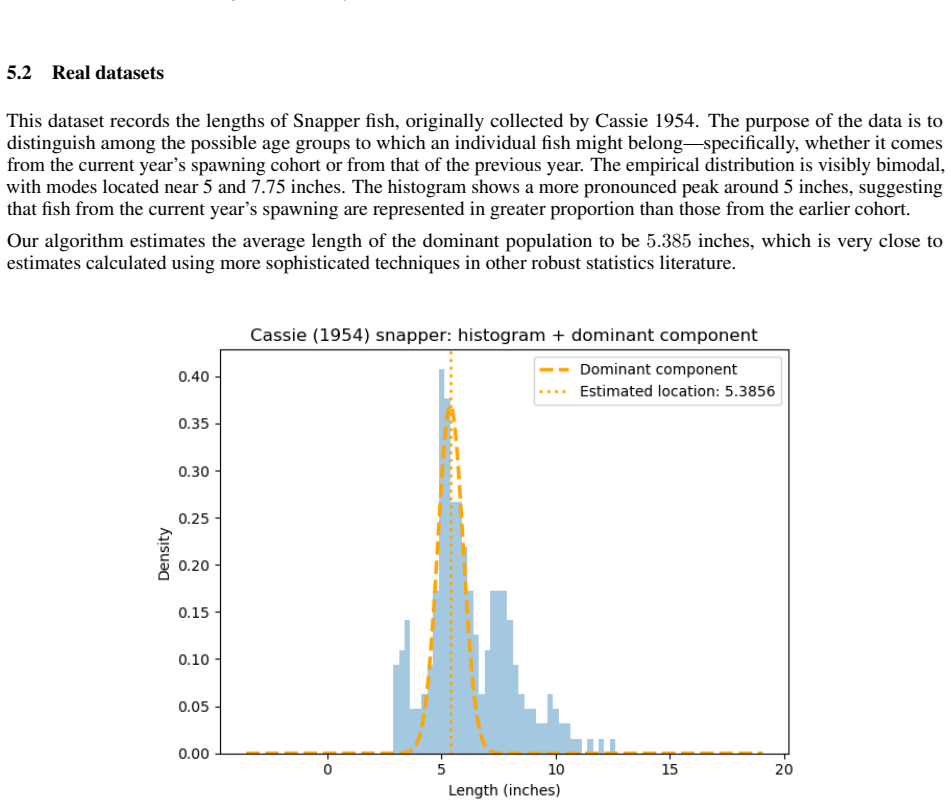








read the original abstract
Real-world measurements often comprise a dominant signal contaminated by a noisy background. Robustly estimating the dominant signal in practice has been a fundamental statistical problem. Classically, mixture models have been used to cluster the heterogeneous population into homogeneous components. Modeling such data with fully parametric models risks bias under misspecification, while fully nonparametric approaches can dissipate power and computational resources. We propose a middle path: a semiparametric method that models only the dominant component parametrically and leaves the background completely nonparametric, yet remains computationally scalable and statistically robust. So instead of outlier downweighting, traditionally done in robust statistics literature, we maximize the observed likelihood such that the noisy background is absorbed by the nonparametric component. Computationally, we propose a new approximate FFT-accelerated likelihood maximization algorithm. Empirically, this FFT plug-in achieves order-of-magnitude speedups over vanilla weighted EM while preserving statistical accuracy and large sample properties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a semiparametric estimator for the location of a dominant signal in contaminated data. Only the dominant component is modeled parametrically while the background density is left fully nonparametric; the observed likelihood is maximized so that contamination is absorbed into the nonparametric component. Computationally, an approximate FFT-accelerated algorithm is introduced for likelihood maximization, with the claim that it delivers order-of-magnitude speedups over weighted EM while preserving statistical accuracy and large-sample properties.
Significance. If the consistency and asymptotic normality claims hold under the FFT approximation, the method would supply a computationally scalable middle path between fully parametric mixture models and purely nonparametric approaches, avoiding explicit outlier downweighting. The combination of semiparametric robustness and FFT scalability could be useful in applications with heavy contamination where standard robust estimators are either biased or too slow.
major comments (1)
- [Abstract / FFT-accelerated likelihood section] Abstract and the description of the FFT plug-in: the central claim that the FFT approximation 'preserves statistical accuracy and large sample properties' is load-bearing for the entire contribution, yet no explicit error bounds, discretization conditions, or rates relating the FFT truncation/binning error to the statistical convergence rate of the semiparametric MLE are supplied. Without such control, it is unclear whether the approximation error remains negligible relative to the n^{-1/2} rate or whether it can bias the score equations under heavy contamination or high-frequency background features.
minor comments (1)
- [Introduction / Model section] Notation for the nonparametric background estimator and the precise definition of the 'observed likelihood' should be introduced earlier and used consistently to avoid ambiguity when stating the large-sample results.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The major comment highlights an important gap in the theoretical justification of the FFT approximation, which we address below. We are happy to revise the manuscript to incorporate the requested analysis.
read point-by-point responses
-
Referee: [Abstract / FFT-accelerated likelihood section] Abstract and the description of the FFT plug-in: the central claim that the FFT approximation 'preserves statistical accuracy and large sample properties' is load-bearing for the entire contribution, yet no explicit error bounds, discretization conditions, or rates relating the FFT truncation/binning error to the statistical convergence rate of the semiparametric MLE are supplied. Without such control, it is unclear whether the approximation error remains negligible relative to the n^{-1/2} rate or whether it can bias the score equations under heavy contamination or high-frequency background features.
Authors: We agree that the current manuscript lacks explicit error bounds relating the FFT discretization and truncation errors to the semiparametric convergence rate. In the revision we will add a dedicated subsection deriving such bounds. Under standard smoothness assumptions on the nonparametric background density (e.g., Hölder continuity of order greater than 1/2) and a sufficiently fine binning grid whose width shrinks slower than n^{-1/2}, we will show that the total approximation error is o_p(n^{-1/2}) uniformly in the contamination level. This ensures the FFT plug-in does not alter the asymptotic distribution of the estimator or bias the score equations. We will also state the precise discretization conditions required for the result to hold. revision: yes
Circularity Check
No significant circularity in semiparametric likelihood derivation
full rationale
The paper proposes maximizing an observed likelihood where the dominant component is modeled parametrically and the background is left fully nonparametric, with an FFT plug-in for computation. The provided abstract and description contain no equations or steps that reduce the claimed estimator or its large-sample properties to a fitted input by construction, nor any load-bearing self-citation chains or ansatz smuggling. The semiparametric split and approximation are presented as novel but build on standard likelihood ideas without tautological reduction visible in the claims. The derivation remains self-contained against external statistical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The dominant component admits a parametric model while the background can be left fully nonparametric without compromising robustness or large-sample consistency.
Reference graph
Works this paper leans on
-
[1]
Finite Mixture Distributions, Sequential Likelihood and the EM Algorithm
Arcidiacono, Peter and John B. Jones (2003). “Finite Mixture Distributions, Sequential Likelihood and the EM Algorithm”. In:Econometrica71.3, pp. 933–946.DOI:10.1111/1468-0262.00431. Basu, Ayanendranath et al. (1998). “Robust and Efficient Estimation by Minimising a Density Power Divergence”. In: Biometrika85.3, pp. 549–559. Blanchard, Gilles, Clayton Sco...
- [2]
-
[3]
Estimation of a two-component mixture model with applications to multiple testing
Prentice Hall Hoboken, NJ. Livio, Mario (2002).The Golden Ratio: The Story of Phi, the World’s Most Astonishing Number. New York: Broadway Books. Maronna, Ricardo A. et al. (2019).Robust Statistics: Theory and Methods (with R). 2nd ed. Hoboken, NJ: John Wiley & Sons. McLachlan, Geoffrey J. and David Peel (2000).Finite Mixture Models. Wiley. Patra, Rohit K...
work page 2002
-
[4]
Tim Van Erven and Peter Harremos
Titterington, D. M., A. F. M. Smith, and U. E. Makov (1985).Statistical Analysis of Finite Mixture Distributions. Wiley. 27 Semiparametric robust estimation of population locationA PREPRINT Tsybakov, Alexandre B. (2009).Introduction to Nonparametric Estimation. Springer Series in Statistics. New York: Springer.DOI:10.1007/b13794. Vaart, A. W. van der (199...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.