Testing the Significance of the Difference-in-Differences Coefficient via Doubly Randomised Inference
Pith reviewed 2026-05-17 00:59 UTC · model grok-4.3
The pith
A dual-randomization test for the difference-in-differences estimator controls type I error accurately even in small samples where standard methods fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors develop a doubly randomised inference procedure in which the treatment indicator and the time indicator are permuted independently to generate the reference distribution for the DiD estimator under the null of no effect. They characterise the resulting permutation space as larger than single-margin tests by a binomial factor and demonstrate through Monte Carlo experiments that the procedure achieves accurate empirical size for all considered sample sizes, in contrast to HC0 and cluster-robust t-tests that are anti-conservative at small n. The distortion in parametric methods is traced to leverage patterns in the regressor matrix rather than to heteroskedasticity per se.
What carries the argument
The dual-margin randomization procedure, which independently permutes the treatment and time indicators to form the null distribution for the difference-in-differences estimator.
If this is right
- The test maintains accurate empirical size at every sample size examined while HC0 and CRVE1 t-tests become substantially anti-conservative at small n.
- The procedure remains valid under non-Gaussian errors and heteroskedasticity by construction.
- Power is slightly lower than the jackknife standard-error benchmark but the gap narrows as n increases.
- The method expands the reference distribution by a factor of binom(n, n_T) relative to single-margin permutation tests.
Where Pith is reading between the lines
- Applied researchers working with small panel data sets may adopt the test as a robustness check when conventional methods are suspected of over-rejection.
- The finding that leverage drives the size distortion more than heteroskedasticity could prompt similar randomization strategies in other regression settings that rely on binary indicators.
- The procedure might be extended to staggered adoption or multi-period difference-in-differences designs that dominate recent empirical work.
Load-bearing premise
Independently permuting the treatment and time indicators produces a valid null distribution for the DiD estimator under the hypothesis of no treatment effect.
What would settle it
A Monte Carlo experiment with small n, a fixed design matrix that produces high leverage, a true null of no treatment effect, and repeated runs of the doubly randomised test showing rejection frequency substantially above five percent would falsify the central claim.
Figures



read the original abstract
This article develops a significance test for the Difference-in-Differences (DiD) estimator based on dual-margin randomization, in which both the treatment and time indicators are independently permuted to generate an empirical null distribution of the DiD estimator. We situate the proposal explicitly within the landscape of existing inference methods for the DiD estimator, including OLS-based $t$-tests, heteroskedasticity-robust standard errors, cluster-robust variance estimators (CRVE), and the recently proposed jackknife standard errors of Hansen (2025). We show that CRVE-based procedures can be severely anti-conservative in small samples, motivating a nonparametric alternative. We formally characterise the permutation space induced by dual randomization, showing that it expands by a factor of $\binom{n}{n_T}$ relative to single-margin permutation tests, and provide an information-theoretic justification for balanced Bernoulli reshuffling. A controlled simulation study, augmented with robustness experiments under non-Gaussian and heteroskedastic errors, demonstrates that the doubly randomised test maintains accurate empirical size at all sample sizes considered, while HC0 and CRVE1 $t$-tests are substantially anti-conservative at small $n$. Crucially, this parametric inflation is driven by the leverage structure of the regressor matrix rather than by the error variance: heteroskedasticity-robust standard errors do not directly address the leverage-driven finite-sample distortion documented here, whereas randomization-based inference is insulated from both error-distributional and variance-structural departures by construction. Power costs relative to the Hansen jackknife test are real but bounded, and become negligible as $n$ grows. The proposed procedure is implemented in the sigDD R package and validated on four empirical datasets from the applied economics literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper proposes a doubly randomised permutation test for the significance of the difference-in-differences (DiD) estimator. Both the treatment-group indicator and the post-period indicator are independently permuted to generate an empirical null distribution for the two-way fixed-effects DiD coefficient. The authors situate the procedure against OLS t-tests, HC0, CRVE1, and Hansen (2025) jackknife standard errors, arguing that the parametric methods are anti-conservative in small samples because of leverage in the regressor matrix rather than error heteroskedasticity. A formal characterisation of the dual-randomization permutation space (expanding by a factor of binom(n, n_T)) and an information-theoretic justification for balanced Bernoulli reshuffling are provided. Controlled Monte Carlo experiments, including robustness checks under non-Gaussian and heteroskedastic errors, show that the proposed test maintains accurate empirical size across sample sizes while power loss relative to the jackknife is bounded and vanishes with n. The method is implemented in the sigDD R package and demonstrated on four empirical applications.
Significance. If the dual-randomization procedure is shown to deliver a valid reference distribution for the two-way FE DiD estimator, the paper would supply a practical nonparametric alternative that is automatically robust to both error-distributional and design-matrix departures. The explicit diagnosis of leverage-driven finite-sample distortion in conventional robust standard errors, the provision of reproducible simulation code, and the open-source R implementation are concrete strengths that would increase the paper's usefulness to applied researchers working with small panels.
major comments (2)
- [§3.2] §3.2 (characterisation of the dual-randomization permutation space): the claim that independent permutation of the treatment and time indicators generates a valid null distribution for the DiD estimator under the sharp null requires demonstrating that the distribution of the interaction column, after partialling out the unit and time fixed effects, is preserved; the information-theoretic argument for balanced Bernoulli reshuffling does not directly establish this conditional equivalence, leaving open whether the test correctly accounts for the leverage structure identified as the source of size distortion in HC0 and CRVE1.
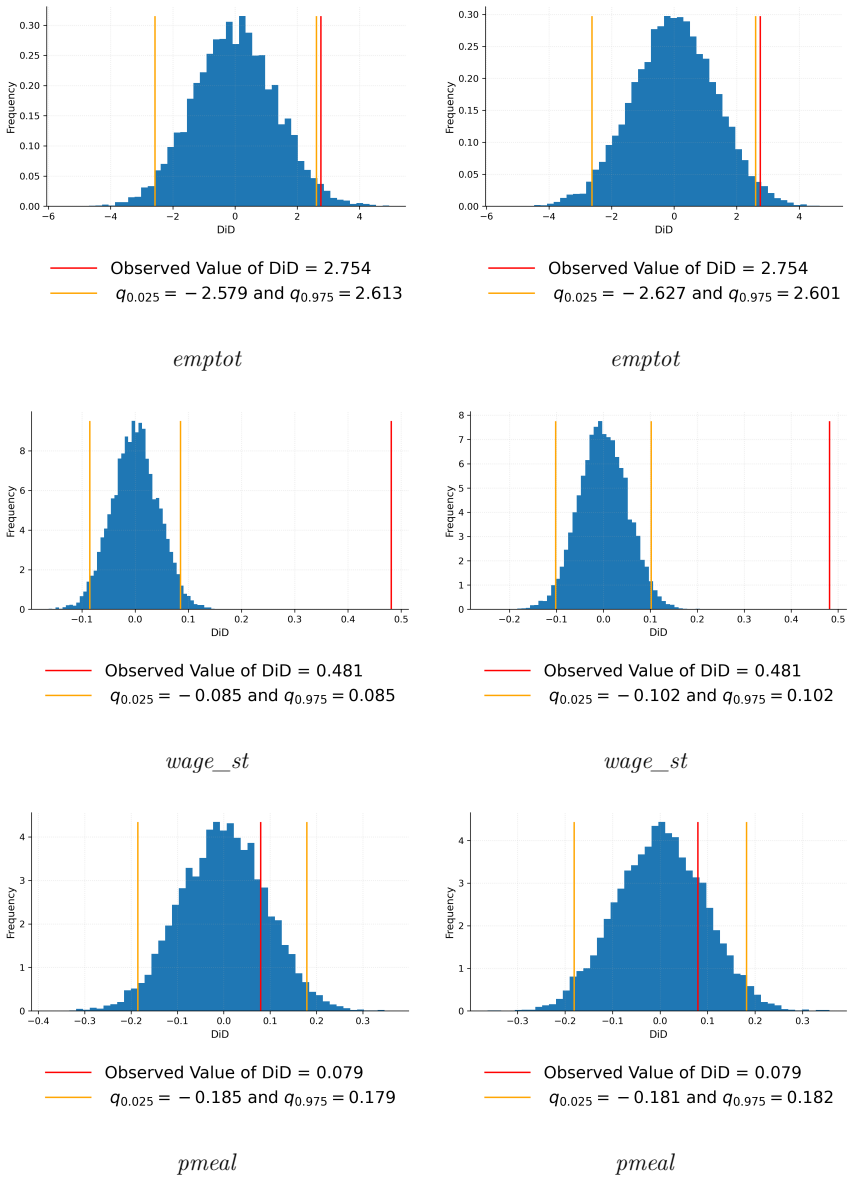
- [Section 5, Table 1] Simulation study (Section 5, Table 1): the reported accurate empirical size for the doubly randomised test at all sample sizes considered is encouraging, but the manuscript does not report the number of Monte Carlo replications, the precise construction of the leverage configurations across DGPs, or the number of permutations used to approximate the null; without these details it is difficult to judge whether the size control generalises beyond the specific designs examined.
minor comments (2)
- [Abstract] The abstract states that the procedure is validated on four empirical datasets but provides no indication of which studies or what the substantive conclusions were; a one-sentence summary of the applications would improve the abstract.
- [§3] Notation for the permutation operator and the balanced Bernoulli reshuffling probability could be introduced earlier and used consistently in the formal characterisation to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (characterisation of the dual-randomization permutation space): the claim that independent permutation of the treatment and time indicators generates a valid null distribution for the DiD estimator under the sharp null requires demonstrating that the distribution of the interaction column, after partialling out the unit and time fixed effects, is preserved; the information-theoretic argument for balanced Bernoulli reshuffling does not directly establish this conditional equivalence, leaving open whether the test correctly accounts for the leverage structure identified as the source of size distortion in HC0 and CRVE1.
Authors: We appreciate the referee drawing attention to this aspect of the theoretical argument in Section 3.2. Under the sharp null, the treatment and post-period indicators are independent of the outcomes, so independent permutation of each margin generates the correct reference distribution for the DiD coefficient. The formal characterisation of the expanded permutation space already encodes the relevant design features, including those that determine leverage after partialling out the fixed effects. To make the connection to the partialled-out interaction column fully explicit, we will add a short proposition deriving that the distribution of the demeaned interaction term is invariant under the dual randomization. This directly ties the procedure to the leverage structure that drives the finite-sample distortion in HC0 and CRVE1. The information-theoretic justification for balanced Bernoulli reshuffling is offered as a complementary rationale for the particular implementation, not as the sole justification for validity. We will expand the section accordingly. revision: yes
-
Referee: [Section 5, Table 1] Simulation study (Section 5, Table 1): the reported accurate empirical size for the doubly randomised test at all sample sizes considered is encouraging, but the manuscript does not report the number of Monte Carlo replications, the precise construction of the leverage configurations across DGPs, or the number of permutations used to approximate the null; without these details it is difficult to judge whether the size control generalises beyond the specific designs examined.
Authors: We agree that these implementation details are necessary for assessing reproducibility and the scope of the reported size control. In the revised manuscript we will add the missing information to Section 5: the number of Monte Carlo replications performed for each design, a precise description of how the leverage configurations were generated across the DGPs (including the specific values of n, n_T, and the structure of the design matrix), and the number of permutations used to approximate the null distribution in each test. We will also include a short robustness check varying these quantities to confirm that the size results are not sensitive to the particular choices. revision: yes
Circularity Check
No circularity: dual-randomization permutation test is constructed directly from data reshuffling
full rationale
The paper proposes a nonparametric test that generates the null distribution for the DiD estimator by independently permuting the treatment-group and post-period indicators on the observed data. This construction does not reduce to any fitted parameter, self-referential equation, or load-bearing self-citation. The characterization of the expanded permutation space (via the binomial factor) and the information-theoretic argument for balanced Bernoulli reshuffling are presented as independent mathematical steps that define the reference distribution, not as outputs derived from the target estimator itself. Simulation results are reported as separate empirical checks rather than predictions forced by the procedure. No step in the provided derivation chain equates the claimed result to its inputs by construction, and the method remains self-contained against standard permutation-test benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Under the null hypothesis of no treatment effect, the observed treatment and time indicators are exchangeable under independent permutation of both margins.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual randomization increases the number of admissible relabelings by a factor of binom(n,n_T), yielding an exponentially richer permutation universe... information-theoretic (entropy) interpretation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Exactness under the sharp null)... randomization p-value satisfies P_{H0}(p ≤ α) ≤ α
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abadie, A., Athey, S., Imbens, G. W. and Wooldridge, J. M. (2022). When should you adjust standard errors for clustering?*.The Quarterly Journal of Economics138: 1–35, doi:10.1093/qje/qjac038. Ahmad, R., Johansson, P. and Schultzberg, M. (2024). Is fisher inference inferior to neyman inference for policy analysis?Statistical Papers65: 3425–3445, doi:10.10...
-
[2]
27 Basse, G., Ding, P., Feller, A. and Toulis, P. (2024). Randomization tests for peer effects in group formation experiments.Econometrica92: 567–590, doi:https://doi.org/10.3982/ECTA20134. Bonnini, S., Assegie, G. M. and Trzcinska, K. (2024). Review about the permutation approach in hypothesis testing.Mathematics12, doi:10.3390/math12172617. Callaway, B....
-
[3]
Furquim, F., Corral, D. and Hillman, N. (2020). A primer for interpreting and design- ing difference-in-differences studies in higher education research. In Perna, L. W. (ed.), Higher Education: Handbook of Theory and Research: Volume
work page 2020
-
[4]
Cham: Springer In- ternational Publishing, 667–723, doi:10.1007/978-3-030-31365-4_5. Halkiewicz, S. M. S. (2023). Modele difference-in-differences w ewaluacji wpływu zdarzeń ekonomicznych na poprawę edukacji. In Stanimir, A. (ed.),Współczesne prob- lemy społeczno-ekonomiczne w ujęciu analitycznym. Wydawnictwo Uniwersytetu Eko- nomicznego we Wrocławiu,1, 7...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.