A Performance Analyzer for a Public Cloud's ML-Augmented VM Allocator
Pith reviewed 2026-05-17 00:07 UTC · model grok-4.3
The pith
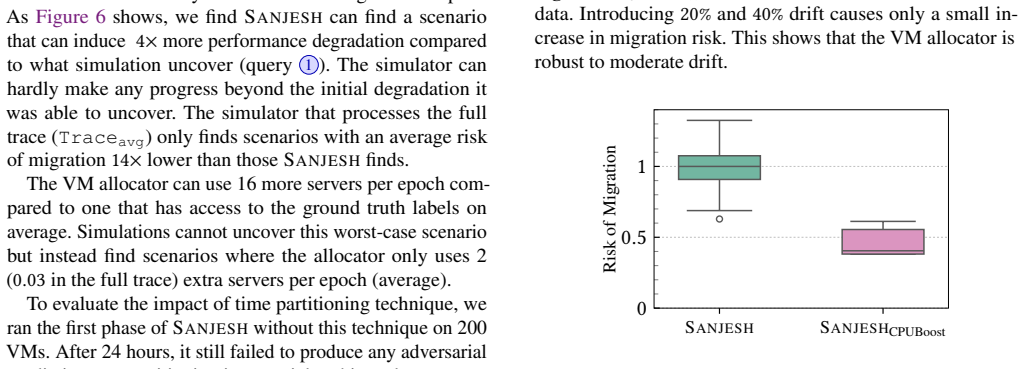
SANJESH uses bi-level optimization to expose how multiple ML predictors in VM allocation can compound into four times worse performance than existing tests find.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SANJESH formulates a bi-level optimization in which the outer level searches over distributional uncertainty in the ML models' predictions to locate adversarial input conditions, while the inner level evaluates the VM allocator's performance given those predictions, revealing scenarios in production traces that cause four times worse performance than the operator's existing evaluator detected.
What carries the argument
Bi-level optimization separating an outer search over possible ML prediction distributions under uncertainty from an inner performance evaluation of the VM allocator.
If this is right
- Cloud operators gain a concrete method to surface hidden performance risks before new ML models are rolled into allocation pipelines.
- The approach can be reused on any multi-model decision system where individual predictors feed a downstream optimizer.
- It quantifies the gap between single-model validation and joint worst-case behavior under realistic distributional shifts.
- Findings indicate that deterministic adversarial testing is insufficient for systems whose decisions depend on correlated probabilistic outputs.
Where Pith is reading between the lines
- Similar bi-level stress testing could be applied to other production ML pipelines such as auto-scaling or network routing where multiple predictors interact.
- The results suggest that retraining individual models with explicit awareness of downstream allocation effects may be necessary to close the observed performance gap.
- If the uncovered scenarios appear in live traffic, operators would face sustained higher server counts or migration overhead until the models are jointly recalibrated.
Load-bearing premise
The outer-level search over distributional uncertainty accurately represents the range of real-world prediction shifts that the production models can experience.
What would settle it
Re-running the operator's standard evaluator on the same traces while forcing the exact prediction distributions found by SANJESH should still produce only the milder degradation originally reported.
Figures












read the original abstract
Cloud operators increasingly deploy multiple ML models in their VM allocation pipelines. In such settings, individually benign predictions can shift and compound, severely degrading performance. In a cloud provider's VM placement pipeline, CPU, memory, and lifetime prediction models jointly determine server count, live migration frequency, and network utilization; yet no existing approach can systematically stress-test how these models adversely interact. Deterministic adversarial analyzers cannot capture probabilistic ML behavior, so operators miss failures that arise only from correlated distributional shifts across models In SANJESH, we formulate a bi-level optimization that captures how the ML models behave statistically and uncovers how they adversely interact. The outer level searches over what predictions the ML models could produce under distributional uncertainty to find adversarial conditions; the inner level evaluates how the VM allocator behaves given those predictions. When we applied it to the operator's production traces, SANJESH uncovered scenarios that cause $4\times$ worse performance than the operators' evaluator detected.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SANJESH, a bi-level optimization framework for stress-testing interactions among ML models (CPU, memory, and lifetime predictors) in a public cloud VM allocator. The outer level searches over predictions under distributional uncertainty to identify adversarial conditions, while the inner level evaluates allocator performance (server count, migrations, network use). On the operator's production traces, it reports uncovering scenarios with 4× worse performance than the existing evaluator detects.
Significance. If the outer-level uncertainty sets prove calibrated to actual model error distributions, the approach could offer a useful method for exposing compounding failures in ML-augmented cloud systems that deterministic analyzers miss. The bi-level formulation directly models statistical behavior rather than point estimates, which is a conceptual strength for this domain.
major comments (1)
- [Abstract] Abstract: The outer-level search is described only at a high level as operating 'under distributional uncertainty,' with no specification of how the uncertainty sets are constructed (moment bounds, support constraints, correlation structure, or empirical calibration to the traces' observed prediction errors). This detail is load-bearing for the 4× claim, because an overly permissive set can generate implausible adversarial predictions unrelated to real ML model shifts.
minor comments (1)
- [Abstract] Abstract: Selection criteria for the production traces and the precise definition of the performance metric used to compute the 4× factor are not stated, which limits immediate assessment of the result's robustness.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on our manuscript. We address the single major comment below and will incorporate revisions to strengthen the presentation of the outer-level uncertainty sets.
read point-by-point responses
-
Referee: [Abstract] Abstract: The outer-level search is described only at a high level as operating 'under distributional uncertainty,' with no specification of how the uncertainty sets are constructed (moment bounds, support constraints, correlation structure, or empirical calibration to the traces' observed prediction errors). This detail is load-bearing for the 4× claim, because an overly permissive set can generate implausible adversarial predictions unrelated to real ML model shifts.
Authors: We agree that the abstract presents the outer-level formulation at a high level and that additional detail on uncertainty-set construction would better support the 4× performance claim. The body of the manuscript (Section 3.2) defines the sets via an empirical Wasserstein ball whose radius is set to the 95th-percentile joint prediction error observed on the production traces; this choice encodes moment bounds through the empirical first- and second-order moments, support constraints from the observed min/max ranges, and correlation structure via the sample covariance of the CPU/memory/lifetime error vectors. We will revise the abstract to include a concise clause stating that the uncertainty sets are calibrated to the empirical error distribution of the production traces. This change will make explicit that the adversarial predictions remain within the statistical envelope of the deployed models rather than arbitrary shifts. revision: yes
Circularity Check
No circularity in bi-level optimization; inner evaluation independent of outer search
full rationale
The paper formulates SANJESH as a bi-level optimization in which the outer level searches over ML model predictions under distributional uncertainty to identify adversarial conditions, while the inner level directly evaluates the VM allocator's performance (server count, migration frequency, network utilization) given those predictions. The reported 4× performance degradation is measured by the inner allocator on production traces rather than being defined or fitted from the outer-level uncertainty sets themselves. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation; the uncertainty sets serve as exogenous inputs to the allocator model, keeping the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bi-level optimization that captures how the ML models behave statistically... outer level searches over what predictions the ML models could produce under distributional uncertainty
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
time-partitioning technique... bounded model checking and the small-scope hypothesis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marcos K Aguilera, Jeffrey C Mogul, Janet L Wiener, Patrick Reynolds, and Athicha Muthitacharoen. 2003. Performance debugging for dis- tributed systems of black boxes.ACM SIGOPS Operating Systems Review37, 5 (2003), 74–89
work page 2003
-
[2]
Guy Amir, Davide Corsi, Raz Yerushalmi, Luca Marzari, David Harel, Alessandro Farinelli, and Guy Katz. 2023. Verifying learning-based robotic navigation systems. InInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 607–627
work page 2023
-
[3]
Guy Amir, Michael Schapira, and Guy Katz. 2021. Towards scalable verification of deep reinforcement learning. In2021 formal methods in computer aided design (FMCAD). IEEE, 193–203
work page 2021
-
[4]
Daniel W Apley and Jingyu Zhu. 2020. Visualizing the effects of predictor variables in black box supervised learning models.Journal of the Royal Statistical Society Series B: Statistical Methodology82, 4 (2020), 1059–1086
work page 2020
-
[5]
Mina Tahmasbi Arashloo, Ryan Beckett, and Rachit Agarwal. 2023. Formal methods for network performance analysis. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 645–661
work page 2023
-
[6]
Venkat Arun, Mina Tahmasbi Arashloo, Ahmed Saeed, Mohammad Alizadeh, and Hari Balakrishnan. 2021. Toward formally verifying congestion control behavior(SIGCOMM ’21)
work page 2021
-
[7]
Behnaz Arzani, Sina Taheri, Pooria Namyar, Ryan Beckett, Siva Ke- sava Reddy Kakarla, and Elnaz Jallilipour. 2025. Raha: A General Tool to Analyze W AN Degradation. InProceedings of the 2025 ACM SIGCOMM Conference
work page 2025
-
[8]
Hugo Barbalho, Patricia Kovaleski, Beibin Li, Luke Marshall, Marco Molinaro, Abhisek Pan, Eli Cortez, Matheus Leao, Harsh Patwari, Zuzu Tang, et al. 2023. Virtual machine allocation with lifetime predictions. Proceedings of Machine Learning and Systems5 (2023)
work page 2023
-
[10]
Daniel S Berger. 2018. Towards lightweight and robust machine learn- ing for CDN caching. InProceedings of the 17th ACM Workshop on Hot Topics in Networks. 134–140
work page 2018
-
[11]
1997.Introduction to linear optimization
Dimitris Bertsimas and John N Tsitsiklis. 1997.Introduction to linear optimization. V ol. 6. Athena scientific Belmont, MA
work page 1997
-
[12]
Mark Brunelli. 2015. Downtime costs small businesses up to $427 per minute.https://www .carbonite.com/blog/2015/downtime-costs- small-businesses-up-to-427-per-minute/
work page 2015
-
[13]
George Casella and Roger Berger. 2024.Statistical inference. CRC press
work page 2024
-
[14]
Hongge Chen, Huan Zhang, Duane Boning, and Cho-Jui Hsieh. 2019. Robust Decision Trees Against Adversarial Examples. InProceedings of the 36th International Conference on Machine Learning. 1122– 1131
work page 2019
-
[15]
Hongge Chen, Huan Zhang, Si Si, Yang Li, Duane Boning, and Cho-Jui Hsieh. 2019. Robustness verification of tree-based models.Advances in Neural Information Processing Systems32 (2019)
work page 2019
-
[16]
Edmund Clarke, Orna Grumberg, Somesh Jha, Yuan Lu, and Helmut Veith. 2000. Counterexample-guided abstraction refinement. InCom- puter Aided Verification: 12th International Conference, CAV 2000, Chicago, IL, USA, July 15-19, 2000. Proceedings 12. Springer, 154– 169
work page 2000
-
[17]
Clarke, Armin Biere, Richard Raimi, and Yunshan Zhu
Edmund M. Clarke, Armin Biere, Richard Raimi, and Yunshan Zhu
-
[18]
Bounded Model Checking Using Satisfiability Solving.For- mal Methods in System Design19, 1 (2001), 7–34. doi:10 .1023/A: 1011254632723
work page 2001
-
[19]
Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Mar- cus Fontoura, and Ricardo Bianchini. 2017. Resource central: Under- standing and predicting workloads for improved resource management in large cloud platforms. InProceedings of the 26th Symposium on Operating Systems Principles. 153–167
work page 2017
-
[20]
Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: An efficient SMT solver. InInternational conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 337–340
work page 2008
-
[21]
Laurens Devos, Wannes Meert, and Jesse Davis. 2021. Versatile ver- ification of tree ensembles. InInternational Conference on Machine Learning. PMLR, 2654–2664
work page 2021
-
[22]
Gil Einziger, Maayan Goldstein, Yaniv Sa’ar, and Itai Segall. 2019. Verifying robustness of gradient boosted models. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty- First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelli- gence
work page 2019
-
[23]
Tomer Eliyahu, Yafim Kazak, Guy Katz, and Michael Schapira. 2021. Verifying learning-augmented systems. InProceedings of the 2021 ACM SIGCOMM 2021 Conference. 305–318
work page 2021
-
[24]
Matteo Fischetti and Jason Jo. 2018. Deep neural networks and mixed integer linear optimization.Constraints23, 3 (2018), 296–309
work page 2018
-
[25]
Rodrigo Fonseca, George Porter, Randy H Katz, and Scott Shenker
-
[26]
In4th USENIX Symposium on Networked Systems Design & Implementation (NSDI 07)
{X-Trace}: A pervasive network tracing framework. In4th USENIX Symposium on Networked Systems Design & Implementation (NSDI 07)
- [27]
-
[28]
Lexiang Huang and Timothy Zhu. 2021. tprof: Performance profiling via structural aggregation and automated analysis of distributed systems traces. InProceedings of the ACM Symposium on Cloud Computing. 76–91
work page 2021
- [29]
-
[30]
Siva Kesava Reddy Kakarla, Ryan Beckett, Behnaz Arzani, Todd Mill- stein, and George Varghese. 2020. Groot: Proactive verification of dns configurations. InProceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer communication. 310–328
work page 2020
-
[31]
Jonathan Kaldor, Jonathan Mace, Michał Bejda, Edison Gao, Wiktor Kuropatwa, Joe O’Neill, Kian Win Ong, Bill Schaller, Pingjia Shan, Brendan Viscomi, et al. 2017. Canopy: An end-to-end performance tracing and analysis system. InProceedings of the 26th symposium on operating systems principles. 34–50
work page 2017
-
[32]
Alex Kantchelian, J. D. Tygar, and Anthony Joseph. 2016. Evasion and Hardening of Tree Ensemble Classifiers. InProceedings of The 33rd International Conference on Machine Learning
work page 2016
-
[33]
Guy Katz, Clark Barrett, David L Dill, Kyle Julian, and Mykel J Kochenderfer. 2022. Reluplex: a calculus for reasoning about deep neural networks.Formal Methods in System Design60, 1 (2022), 87–116
work page 2022
-
[34]
Guy Katz, Derek A Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Alek- sandar Zelji´c, et al. 2019. The marabou framework for verification and analysis of deep neural networks. InComputer Aided Verification: 31st International Conference, CAV 2019, New York City, NY, USA, July 15-18, 2019, Pro...
work page 2019
-
[35]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Wei- dong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A highly efficient gradient boosting decision tree. InAdvances in neural informa- tion processing systems, V ol. 30. Curran Associates, Inc., 3146–3154
work page 2017
-
[36]
James C King. 1976. Symbolic execution and program testing.Com- mun. ACM19, 7 (1976), 385–394. 12
work page 1976
-
[37]
Arnd Christian König, Yi Shan, Karan Newatia, Luke Marshall, and Vivek Narasayya. 2023. Solver-In-The-Loop Cluster Resource Manage- ment for Database-as-a-Service.Proceedings of the VLDB Endowment 16, 13 (2023), 4254–4267
work page 2023
-
[38]
Sang Gyu Kwak and Jong Hae Kim. 2017. Central limit theorem: the cornerstone of modern statistics.Korean journal of anesthesiology70, 2 (2017), 144
work page 2017
-
[39]
Alessio Lomuscio and Lalit Maganti. 2017. An approach to reacha- bility analysis for feed-forward relu neural networks.arXiv preprint arXiv:1706.07351(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Scott Lundberg. 2017. A unified approach to interpreting model pre- dictions.arXiv preprint arXiv:1705.07874(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Hongzi Mao, Ravi Netravali, and Mohammad Alizadeh. 2017. Neural adaptive video streaming with pensieve. InProceedings of the con- ference of the ACM special interest group on data communication. 197–210
work page 2017
-
[42]
Luke Merrick and Ankur Taly. 2020. The explanation game: Explaining machine learning models using shapley values. InMachine Learning and Knowledge Extraction: 4th IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference, CD-MAKE 2020, Dublin, Ireland, August 25–28, 2020, Proceedings 4. Springer, 17–38
work page 2020
-
[43]
2020.Interpretable machine learning
Christoph Molnar. 2020.Interpretable machine learning. Lulu. com
work page 2020
-
[44]
Pooria Namyar, Behnaz Arzani, Ryan Beckett, Santiago Segarra, Hi- manshu Raj, and Srikanth Kandula. 2022. Minding the gap between fast heuristics and their optimal counterparts. InProceedings of the 21st ACM Workshop on Hot Topics in Networks (HotNets ’22)
work page 2022
-
[45]
Pooria Namyar, Behnaz Arzani, Ryan Beckett, Santiago Segarra, Hi- manshu Raj, Umesh Krishnaswamy, Ramesh Govindan, and Srikanth Kandula. 2024. Finding adversarial inputs for heuristics using multi- level optimization. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 927–949
work page 2024
-
[46]
Pooria Namyar, Michael Schapira, Ramesh Govindan, Santiago Segarra, Ryan Beckett, Siva Kesava Reddy Kakarla, and Behnaz Arzani
-
[47]
InProceedings of the 23rd ACM Workshop on Hot Topics in Networks
End-to-End Performance Analysis of Learning-enabled Systems. InProceedings of the 23rd ACM Workshop on Hot Topics in Networks. 86–94
-
[48]
Besmira Nushi, Ece Kamar, and Eric Horvitz. 2018. Towards account- able AI: Hybrid human-machine analyses for characterizing system failure. InProceedings of the AAAI Conference on Human Computation and Crowdsourcing, V ol. 6. 126–135
work page 2018
-
[49]
Maddy Osman. [n. d.]. How to calculate the true cost of ecommerce downtime and reduce its impact.https://www .nexcess.net/blog/ ecommerce-downtime/
-
[50]
Joo Pedro Pedroso. 2011. Optimization with gurobi and python.INESC Porto and Universidade do Porto„ Porto, Portugal1 (2011)
work page 2011
-
[51]
Yarin Perry, Felipe Vieira Frujeri, Chaim Hoch, Srikanth Kandula, Ishai Menache, Michael Schapira, and Aviv Tamar. 2023. {DOTE}: Rethinking (Predictive){W AN} Traffic Engineering. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 1557–1581
work page 2023
-
[52]
P Jonathon Phillips, P Jonathon Phillips, Carina A Hahn, Peter C Fontana, Amy N Yates, Kristen Greene, David A Broniatowski, and Mark A Przybocki. 2021. Four principles of explainable artificial intelligence. (2021)
work page 2021
-
[53]
Adam Ruprecht, Danny Jones, Dmitry Shiraev, Greg Harmon, Maya Spivak, Michael Krebs, Miche Baker-Harvey, and Tyler Sanderson
-
[54]
Vm live migration at scale.ACM SIGPLAN Notices53, 3 (2018), 45–56
work page 2018
- [55]
-
[56]
Benjamin H Sigelman, Luiz André Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan, and Chan- dan Shanbhag. 2010. Dapper, a large-scale distributed systems tracing infrastructure. (2010)
work page 2010
-
[57]
Zhenyu Song, Daniel S Berger, Kai Li, Anees Shaikh, Wyatt Lloyd, Soudeh Ghorbani, Changhoon Kim, Aditya Akella, Arvind Krishna- murthy, Emmett Witchel, et al . 2020. Learning relaxed belady for content distribution network caching. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). 529–544
work page 2020
-
[58]
Ryuichi Takanobu, Qi Zhu, Jinchao Li, Baolin Peng, Jianfeng Gao, and Minlie Huang. 2020. Is Your Goal-Oriented Dialog Model Perform- ing Really Well? Empirical Analysis of System-wise Evaluation. In 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue. 297
work page 2020
-
[59]
Pingdom Team. 2023. Average Cost of Downtime per In- dustry.https://www .pingdom.com/outages/average-cost-of- downtime-per-industry/
work page 2023
-
[60]
Vincent Tjeng, Kai Xiao, and Russ Tedrake. 2017. Evaluating ro- bustness of neural networks with mixed integer programming.arXiv preprint arXiv:1711.07356(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
John Törnblom and Simin Nadjm-Tehrani. 2019. An abstraction- refinement approach to formal verification of tree ensembles. InCom- puter Safety, Reliability, and Security: SAFECOMP 2019 Workshops, ASSURE, DECSoS, SASSUR, STRIVE, and WAISE, Turku, Finland, September 10, 2019, Proceedings 38. Springer, 301–313
work page 2019
-
[62]
John Törnblom and Simin Nadjm-Tehrani. 2020. Formal verification of input-output mappings of tree ensembles.Science of Computer Programming194 (2020), 102450
work page 2020
-
[63]
Yihan Wang, Huan Zhang, Hongge Chen, Duane Boning, and Cho-Jui Hsieh. 2020. On lp-norm robustness of ensemble decision stumps and trees. InProceedings of the 37th International Conference on Machine Learning
work page 2020
-
[64]
Doris Xin, Hui Miao, Aditya Parameswaran, and Neoklis Polyzotis
-
[65]
InProceedings of the 2021 international conference on management of data
Production machine learning pipelines: Empirical analysis and optimization opportunities. InProceedings of the 2021 international conference on management of data. 2639–2652
work page 2021
-
[66]
Chong Zhang, Huan Zhang, and Cho-Jui Hsieh. 2020. An efficient adversarial attack for tree ensembles.Advances in neural information processing systems33 (2020), 16165–16176. 13 APPENDIX A SANJESHsupported queries Table 4 summarizes the queries that SANJESHsupports. B Probabilities on finite samples In §5 we described how many queries in SANJESHrequire we ...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.