AugCodec: A Low-Bitrate Disentangled Neural Speech Codec via Data Augmentation
Pith reviewed 2026-06-26 11:36 UTC · model grok-4.3
The pith
AugCodec disentangles speech into semantic, speaker, and prosody tokens using data augmentation for low-bitrate coding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
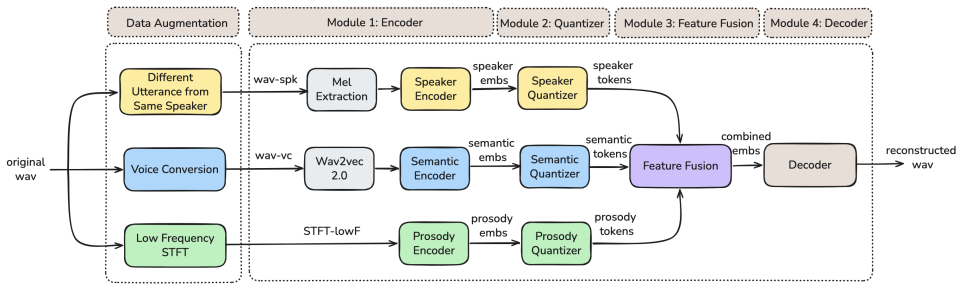
AugCodec decomposes speech into three distinct components—semantic, speaker, and prosody tokens—by applying tailored augmentation strategies to create input variants that preserve one target attribute while suppressing the others. An augmentation loss aligns semantic encoder outputs between source and voice-converted speech to encourage speaker-agnostic embeddings. This enables operation at only 12.5 Hz with three token streams while outperforming state-of-the-art methods in reconstruction quality and disentanglement on LibriSpeech test-clean.
What carries the argument
Tailored data augmentation strategies that generate distinct speech variants for isolating semantic, speaker, and prosody attributes in separate encoders.
If this is right
- Reduces token rate to 12.5 Hz while maintaining high reconstruction quality.
- Improves disentanglement between semantic, speaker, and prosody information compared to prior codecs.
- Allows three independent token streams without residual leakage.
- Supports voice conversion applications through the augmentation loss.
Where Pith is reading between the lines
- Similar augmentation tricks might separate other audio attributes such as emotion or accent.
- The low token rate could make real-time speech transmission more efficient on low-bandwidth links.
- Independent tokens open the door to editing one attribute without affecting the others in generation tasks.
Load-bearing premise
Tailored augmentation strategies can transform speech so each variant preserves exactly one target attribute while fully suppressing the other two.
What would settle it
Measuring whether semantic tokens change when only the speaker is altered in the input, or checking if the three token streams show measurable correlation after training.
Figures
read the original abstract
We propose AugCodec, a low-bitrate disentangled neural speech codec that leverages data augmentation to decompose speech into three distinct components: semantic, speaker, and prosody tokens. Specifically, we employ tailored augmenta tion strategies to transform speech into distinct variants, each serving as input for extracting tokens that preserve the target attribute while suppressing others. This disentanglement strategy enables substantial reduction in token rate. Further more, we introduce an augmentation loss that aligns semantic encoder outputs between source and voice-converted speech, encouraging speaker-agnostic embeddings while mitigating the acoustic mismatch induced by voice conversion. Experiments on LibriSpeech test-clean demonstrate that AugCodec significantly outperforms state-of-the-art methods in both reconstruction quality and disentanglement, while operating at only 12.5Hz with three token streams.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AugCodec, a neural speech codec that decomposes input speech into three disentangled token streams (semantic, speaker, and prosody) via tailored data augmentations (voice conversion, pitch shift, etc.). Each augmentation is designed to preserve one target attribute while suppressing the others; an augmentation loss further aligns semantic encoder outputs between original and voice-converted speech. The resulting model operates at 12.5 Hz (three token streams) and is reported to outperform prior codecs on LibriSpeech test-clean in both reconstruction quality and disentanglement metrics.
Significance. If the augmentation-based isolation of attributes proves robust, the approach offers a practical route to lower-bitrate disentangled codecs without requiring explicit supervision for each factor. The 12.5 Hz rate with three independent streams would be a notable efficiency gain over typical neural codecs, provided reconstruction and disentanglement metrics hold under controlled listening tests and downstream tasks.
major comments (2)
- [Abstract / Experiments] The central empirical premise—that each augmentation (voice conversion, pitch shift, etc.) isolates exactly one attribute while nulling the other two—receives no quantitative validation in the supplied abstract. Without ablation tables showing residual leakage (e.g., speaker classification accuracy on prosody tokens or prosody metrics on semantic tokens), the claim that the three streams are independent remains unverified and is load-bearing for the bitrate-reduction argument.
- [Method] The augmentation loss is described only at a high level (aligning semantic embeddings between source and voice-converted speech). No equation, weighting schedule, or comparison against a plain reconstruction loss is visible; therefore it is impossible to assess whether this term is necessary or merely cosmetic for the reported disentanglement gains.
minor comments (2)
- [Abstract] The abstract states “significantly outperforms state-of-the-art methods” but supplies neither the exact baselines nor the numerical deltas; a table comparing bitrate, PESQ/STOI, and disentanglement metrics (speaker classification error, prosody correlation) against EnCodec, SoundStream, and recent disentangled codecs is required.
- [Abstract] Token rate is given as 12.5 Hz with three streams; clarify whether this is the aggregate rate or per-stream rate and how frame shift and codebook sizes combine to reach the claimed total bitrate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical validation and methodological clarity. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central empirical premise—that each augmentation (voice conversion, pitch shift, etc.) isolates exactly one attribute while nulling the other two—receives no quantitative validation in the supplied abstract. Without ablation tables showing residual leakage (e.g., speaker classification accuracy on prosody tokens or prosody metrics on semantic tokens), the claim that the three streams are independent remains unverified and is load-bearing for the bitrate-reduction argument.
Authors: We agree that the abstract lacks explicit leakage ablations and that such metrics would strengthen the independence claim. The full manuscript reports superior disentanglement performance via standard metrics on LibriSpeech, but does not include the specific residual-leakage tables suggested. We will add a dedicated ablation subsection with speaker classification accuracy on prosody tokens, prosody metrics on semantic tokens, and similar cross-attribute evaluations, and will reference these results in a revised abstract. revision: yes
-
Referee: [Method] The augmentation loss is described only at a high level (aligning semantic embeddings between source and voice-converted speech). No equation, weighting schedule, or comparison against a plain reconstruction loss is visible; therefore it is impossible to assess whether this term is necessary or merely cosmetic for the reported disentanglement gains.
Authors: The description in the current manuscript is high-level. The full text formalizes the loss as an L2 alignment term but omits the explicit equation, the value of the weighting hyperparameter, and an ablation against reconstruction-only training. We will insert the precise loss equation, specify the weighting schedule used in experiments, and add a comparison table showing disentanglement metrics with and without the augmentation loss term. revision: yes
Circularity Check
No significant circularity; empirical method with no self-referential derivation
full rationale
The paper describes an empirical neural codec architecture that uses data augmentation to produce disentangled token streams for semantic, speaker, and prosody attributes. Performance is evaluated via experiments on LibriSpeech rather than derived from first principles or fitted parameters that are then renamed as predictions. No equations, uniqueness theorems, or self-citations are invoked to force the central result; the augmentation loss and token-rate reduction are design choices whose effectiveness is tested externally. The argument is therefore self-contained against external benchmarks and does not reduce to any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Beyond compression for transmission, neural speech codecs have been extensively explored in recent years as foundational building blocks for speech language models and multimodal models [1, 2, 3, 4, 5]. The research scope has expanded from an initial focus on reconstruction quality [1, 2, 3] to encompass a broader range of aspects, including ...
-
[2]
AugCodec We introduce AugCodec, a low-bitrate disentangled neural speech codec. By leveraging data augmentation strategies, AugCodec decomposes speech signals into three distinct token types: semantic tokens, speaker tokens, and prosody tokens. This thorough disentanglement enables each feature dimension to be represented with fewer tokens, facilitating t...
Pith/arXiv arXiv 2026
-
[3]
Experimental setup 3.1.1
Experimental results 3.1. Experimental setup 3.1.1. Datasets For training, we use the LibriLight-medium and LibriTTS datasets, resampled to 16kHz. For LibriLight-medium, we seg- ment the data using the provided V AD labels and retain only segments between 2s and 15s, yielding approximately 3000 hours of training data. For evaluation, we select samples be-...
2048
-
[4]
We achieved thorough feature disentanglement through tailored data augmentation that transforms speech into forms contain- ing only target features while minimizing others
Conclusion In this paper, we presented AugCodec, a low-bitrate disentan- gled speech codec comprising semantic, speaker, and prosody tokens, operating at a maximum frame rate of 12.5Hz. We achieved thorough feature disentanglement through tailored data augmentation that transforms speech into forms contain- ing only target features while minimizing others...
-
[5]
No AI tools were involved in the research design, experimentation, or data analysis
Generative AI Use Disclosure Generative AI was used solely for minor language polishing and editing of the manuscript. No AI tools were involved in the research design, experimentation, or data analysis
-
[6]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” inarXiv:2107.03312, 2021
arXiv 2021
-
[7]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,” inarXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[8]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” in Advances in Neural Information Processing Systems, NeurIPS, 2023
2023
-
[9]
Investigating neural au- dio codecs for speech language model-based speech generation,
J. Li, D. Wang, X. Wang, Y . Qianet al., “Investigating neural au- dio codecs for speech language model-based speech generation,” inIEEE Spoken Language Technology Workshop, SLT, Dec. 2024
2024
-
[10]
Dis- crete Audio Tokens: More Than a Survey!
P. Mousavi, G. Maimon, A. Moumen, D. Petermannet al., “Dis- crete Audio Tokens: More Than a Survey!”Transactions on Ma- chine Learning Research, Sep. 2025
2025
-
[11]
BigCodec: Pushing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “BigCodec: Pushing the limits of low-bitrate neural speech codec,” 2024
2024
-
[12]
SemantiCodec: An ultra low bitrate semanticaudio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumb- ley, “SemantiCodec: An ultra low bitrate semanticaudio codec for general sound,” inarXiv: 2405.00233, 2024
arXiv 2024
-
[13]
Moshi: a speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,” inarXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[14]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guo, X. Zhang, P. Zhang, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-tts technical report,”arXiv preprint arXiv:2601.15621, 2026
Pith/arXiv arXiv 2026
-
[15]
MiMo-Audio: Audio Language Models are Few-Shot Learners,
L.-C.-T. Xiaomi, “MiMo-Audio: Audio Language Models are Few-Shot Learners,” 2025
2025
-
[16]
Naturalspeech 3: Zero-shot speech synthesiswith factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xinet al., “Naturalspeech 3: Zero-shot speech synthesiswith factorized codec and diffusion models,” inarXiv:2403.03100, 2024
arXiv 2024
-
[17]
DisCo-Speech: Control- lable Zero-Shot Speech Generation with A Disentangled Speech Codec,
T. Li, W. Ge, Z. Wang, Z. Cuiet al., “DisCo-Speech: Control- lable Zero-Shot Speech Generation with A Disentangled Speech Codec,” inarXiv:2512.13251, 2025
arXiv 2025
-
[18]
Spark-TTS: An efficient llm-based text-to-speech model with single- stream decoupled speech tokens,
X. Wang, M. Jiang, Z. Ma, Z. Zhang, and et. al, “Spark-TTS: An efficient llm-based text-to-speech model with single- stream decoupled speech tokens,” 2025. [Online]. Available: https://arxiv.org/abs/2503.01710
Pith/arXiv arXiv 2025
-
[19]
FreeCodec: A disentangled neural speech codec with fewer tokens,
Y . Zheng, W. Tu, Y . Kanget al., “FreeCodec: A disentangled neural speech codec with fewer tokens,” inarXiv:2412.201053, 2025
arXiv 2025
-
[20]
TaDi- Codec: Text-aware diffusion speech tokenizer for speech lan- guage modeling,
Y . Wang, D. Chen, X. Zhang, J. Zhang, J. Li, and Z. Wur, “TaDi- Codec: Text-aware diffusion speech tokenizer for speech lan- guage modeling,” inAdvances in Neural Information Processing Systems, NeurIPS, 2025
2025
-
[21]
FlexiCodec: A dynamic neural audio codec for low frame rates,
J. Li, Y . Qian, Y . Hu, L. Zhanget al., “FlexiCodec: A dynamic neural audio codec for low frame rates,” inInternational Confer- ence on Learning Representations, ICLR, 2026
2026
-
[22]
Zero-shot voice conversion with diffusion transformers,
S. Liu, “Zero-shot voice conversion with diffusion transformers,” inarXiv:2411.09943, 2024
arXiv 2024
-
[23]
A ConvNet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie., “A ConvNet for the 2020s,” inIEEE/CVF conference on computer vision and pat-tern recognition, CVPR, June 2022
2022
-
[24]
ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification,
Brecht Desplanques, Jenthe Thienpondt, Kris Demuynck, “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification,” inInter- speech, Sep. 2020
2020
-
[25]
Neural dis- crete representation learning,
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural dis- crete representation learning,” inAdvances in Neural Information Processing Systems, NeurIPS, 2017
2017
-
[26]
Dfinite scalar quantization: Vq-vae made simple,
F. Mentzer, F. Mentzer, D. Minnen, E. Agustsson, and M. Tschan- nen, “Dfinite scalar quantization: Vq-vae made simple,” inInter- national Conference on Learning Representations, ICLR, 2024
2024
-
[27]
Scalable Diffusion Models with Trans- formers,
W. Peebles and S. Xie, “Scalable Diffusion Models with Trans- formers,” inIEEE/CVF conference on computer vision and pat- tern recognition, CVPR, Sep. 2023
2023
-
[28]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. C. Courville, “FiLM: Visual reasoning with a general conditioning layer,” in AAAI, 2018
2018
-
[29]
Neural Net- works Fail to Learn Periodic Functions and How to Fix It,
Liu Ziyin and Tilman Hartwig and Masahito Ueda, “Neural Net- works Fail to Learn Periodic Functions and How to Fix It,” inAd- vances in Neural Information Processing Systems, NeurIPS, 2020
2020
-
[30]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inInternational Conference on Learning Representations, ICLR, 2019
2019
-
[31]
Perceptual eval- uation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,
A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual eval- uation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in2001 IEEE In- ternational Conference on Acoustics, Speech, and Signal Process- ing. Proceedings (Cat. No.01CH37221), vol. 2, 2001, pp. 749– 752 vol.2
2001
-
[32]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inProc. Interspeech, 2022, pp. 4521– 4525
2022
-
[33]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inInternational Conference on Machine Learning, ICLR. PMLR, 2023, pp. 28 492–28 518
2023
-
[34]
WavLM: Large- scale self-supervised pre-training for full stack speech process- ing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liuet al., “WavLM: Large- scale self-supervised pre-training for full stack speech process- ing,” inarXiv:2110.13900, 2022
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.