Statistical Inference for Smoothed Support Vector Machines in High Dimensions: From Offline to Online Data
Pith reviewed 2026-05-20 15:51 UTC · model grok-4.3
The pith
Convolution smoothing of the hinge loss produces a debiased estimator for high-dimensional Lasso SVM that supports valid confidence intervals in both offline and online settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the offline case, by applying a convolution smoothing technique to the hinge loss, we construct a debiased estimator that eliminates the shrinkage bias, thereby building a valid confidence interval. For online streaming data, we develop a real-time estimator and inference procedure that relies only on summary statistics of historical data. Rigorous proofs are provided for the asymptotic normality of our offline and online debiased estimators.
What carries the argument
The convolution smoothing technique applied to the hinge loss in the Lasso-penalized SVM model, which enables debiasing to correct for shrinkage bias and supports asymptotic normality.
If this is right
- Valid confidence intervals can be built for the model coefficients in high-dimensional settings.
- The online procedure allows real-time inference without storing the entire dataset history.
- Improved computational efficiency is achieved by avoiding direct optimization of the non-smooth objective.
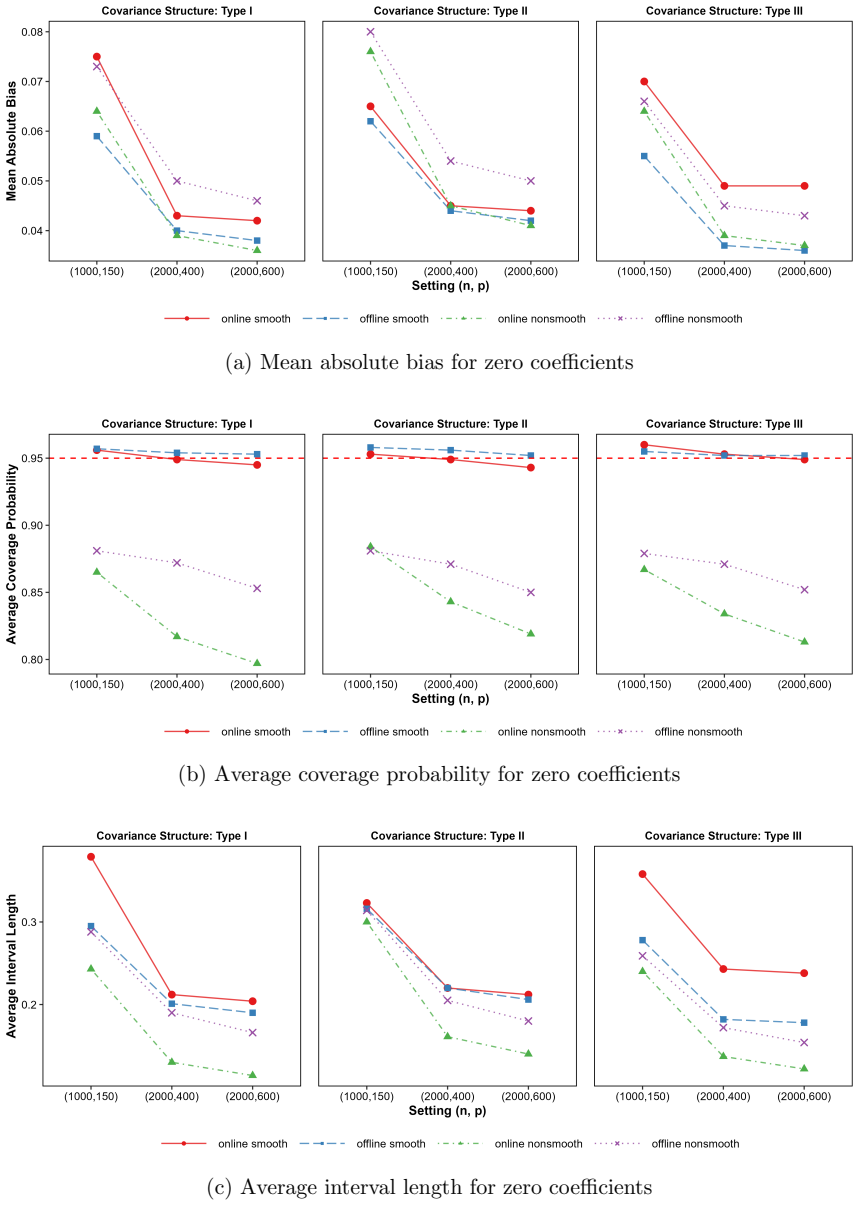
- Simulation studies confirm that the methods achieve valid statistical inference under the stated conditions.
Where Pith is reading between the lines
- This smoothing approach could be adapted to other loss functions that are non-differentiable in high-dimensional penalized models.
- Practitioners in fields like bioinformatics or finance using online SVM classification might benefit from real-time uncertainty estimates.
- Future work could explore the sensitivity to the choice of smoothing kernel or bandwidth parameter in finite samples.
Load-bearing premise
The convolution smoothing combined with debiasing yields estimators that satisfy asymptotic normality in high dimensions under sparsity and regularity conditions.
What would settle it
Observing that the empirical coverage of the constructed confidence intervals deviates significantly from the nominal level in repeated simulations with high-dimensional sparse data would indicate the claim does not hold.
Figures








read the original abstract
High-dimensional classification problems often rely on the Lasso-penalized linear Support Vector Machines (SVMs). However, the double non-smoothness induced by the hinge loss and Lasso penalty in this model makes statistical inference challenging and impedes computational efficiency. In this paper, we propose a unified inference framework in both offline and online settings. In the offline case, by applying a convolution smoothing technique to the hinge loss, we construct a debiased estimator that eliminates the shrinkage bias, thereby building a valid confidence interval. For online streaming data, we develop a real-time estimator and inference procedure that relies only on summary statistics of historical data. Theoretically, we provide rigorous proofs for the asymptotic normality of our offline and online debiased estimators. Simulation studies and real data applications demonstrate that our methods achieve valid statistical inference and improved computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a unified framework for statistical inference in high-dimensional Lasso-penalized SVMs. It applies convolution smoothing to the hinge loss to construct a debiased estimator that removes shrinkage bias and yields valid confidence intervals in the offline setting. For online streaming data, it proposes a real-time estimator and inference procedure based solely on recursive summary statistics. Rigorous proofs establish asymptotic normality of both the offline and online debiased estimators under standard high-dimensional sparsity and restricted-eigenvalue conditions, with supporting simulation studies and real-data examples.
Significance. If the asymptotic results hold, the work provides a practical route to valid inference for non-smooth high-dimensional classifiers, extending naturally to online settings without storing full historical data. The smoothing-plus-debiasing strategy is a clean way to handle the double non-smoothness of hinge loss and Lasso, and the online extension using only summary statistics is a notable computational advantage for large-scale applications.
major comments (2)
- [§3.2] §3.2 (or the main theorem on asymptotic normality): the required rate for the smoothing bandwidth h_n relative to n and p is stated only qualitatively; an explicit condition such as h_n = o(n^{-1/2} p^{-1/4}) or similar is needed to confirm that the bias term vanishes faster than the stochastic term in the high-dimensional regime.
- [Theorem 4.1] Theorem 4.1 (online estimator): the recursive update for the debiasing matrix is claimed to be consistent, but the proof sketch does not explicitly verify that the accumulated summary statistics preserve the restricted eigenvalue condition uniformly over time; a short additional argument or reference to a uniform RE lemma would strengthen the claim.
minor comments (3)
- [Abstract] The abstract asserts 'rigorous proofs' without naming the key assumptions (sparsity level, RE constant, etc.); adding one sentence would improve readability for a broad audience.
- [§2 and §4] Notation for the convolution kernel and its bandwidth is introduced in §2 but reused without re-definition in the online section; a brief reminder or table of symbols would reduce reader effort.
- [Figure 1] Figure 1 caption does not indicate the number of Monte Carlo replications or the exact value of the smoothing parameter used; this detail is needed to reproduce the coverage probabilities shown.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the insightful comments on our manuscript. We address the major comments point by point below and will incorporate the suggested clarifications in the revised version.
read point-by-point responses
-
Referee: [§3.2] §3.2 (or the main theorem on asymptotic normality): the required rate for the smoothing bandwidth h_n relative to n and p is stated only qualitatively; an explicit condition such as h_n = o(n^{-1/2} p^{-1/4}) or similar is needed to confirm that the bias term vanishes faster than the stochastic term in the high-dimensional regime.
Authors: We agree with the referee that making the rate condition on the smoothing bandwidth h_n explicit will strengthen the presentation. In the revised manuscript, we will specify the condition h_n = o(n^{-1/2} p^{-1/4}) in the statement of the main theorem in §3.2 and include a brief verification in the proof that this rate ensures the smoothing bias is o_p(n^{-1/2}) and thus does not affect the asymptotic normality in the high-dimensional setting where p may grow polynomially with n. This is a minor addition that clarifies the existing analysis without altering the results. revision: yes
-
Referee: [Theorem 4.1] Theorem 4.1 (online estimator): the recursive update for the debiasing matrix is claimed to be consistent, but the proof sketch does not explicitly verify that the accumulated summary statistics preserve the restricted eigenvalue condition uniformly over time; a short additional argument or reference to a uniform RE lemma would strengthen the claim.
Authors: We appreciate this observation. The current proof relies on the fact that the online estimator converges to the offline one, but we concur that explicitly addressing the uniform preservation of the restricted eigenvalue (RE) condition for the accumulated summary statistics would be beneficial. In the revision, we will add a short paragraph or lemma in the proof of Theorem 4.1, showing that under the initial RE condition and the recursive averaging, the RE constant holds uniformly over time with high probability, possibly by citing a relevant uniform RE result from the sequential estimation literature or providing a direct concentration argument. This will be a minor extension to the existing proof. revision: yes
Circularity Check
No significant circularity; derivation self-contained under standard asymptotics
full rationale
The paper defines a convolution-smoothed hinge loss, forms the Lasso-penalized estimator on that objective, and constructs a debiased estimator whose asymptotic normality is proved from first principles under high-dimensional sparsity and restricted-eigenvalue conditions. The online procedure updates via recursive summary statistics while preserving the same limiting distribution. No equation reduces the target result to a fitted parameter defined by the same procedure, no load-bearing uniqueness theorem is imported from self-citation, and the smoothing bandwidth rate is chosen explicitly to balance bias and variance rather than by ansatz smuggling. The central claims therefore rest on independent analytic derivations rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard regularity conditions for high-dimensional asymptotic normality of debiased Lasso-type estimators
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
by applying a convolution smoothing technique to the hinge loss, we construct a debiased estimator... lh(u) = (l ∗ Kh)(u)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanrecovery theorem (LogicNat ≃ Nat) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We have established the asymptotic normality of the debiased Lasso estimate in Theorem 3.3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , VOLUME =
Koo, Ja-Yong and Lee, Yoonkyung and Kim, Yuwon and Park, Changyi , TITLE =. Journal of Machine Learning Research , VOLUME =. 2008 , PAGES =
work page 2008
-
[2]
Annals of Mathematical Statistics , VOLUME =
Robbins, Herbert and Monro, Sutton , TITLE =. Annals of Mathematical Statistics , VOLUME =. 1951 , PAGES =
work page 1951
-
[3]
Wang, Kangning and Meng, Xiaoqing and Sun, Xiaofei , TITLE =. TEST , FJOURNAL =. 2025 , NUMBER =
work page 2025
-
[4]
Predicting risk from financial reports with regression , author=. Proceedings of human language technologies: the 2009 annual conference of the North American Chapter of the Association for Computational Linguistics , pages=
work page 2009
-
[5]
Journal of the Royal Statistical Society
Tan, Kean Ming and Wang, Lan and Zhou, Wen-Xin , TITLE =. Journal of the Royal Statistical Society. Series B. Statistical Methodology , VOLUME =. 2022 , NUMBER =
work page 2022
-
[6]
Journal of the American Statistical Association , VOLUME =
Cai, Leheng and Guo, Xu and Lian, Heng and Zhu, Liping , TITLE =. Journal of the American Statistical Association , VOLUME =. 2025 , NUMBER =
work page 2025
-
[7]
Online learning of convoluted rank regression with streaming data , journal =. 2026 , issn =
work page 2026
-
[8]
Journal of Computational and Graphical Statistics , volume =
Renewable l 1-regularized linear support vector machine with high-dimensional streaming data , author=. Journal of Computational and Graphical Statistics , volume =. 2026 , publisher=
work page 2026
-
[9]
Statistics and Computing , VOLUME =
Wang, Yidan and Zhang, Lingyun and Gai, Yujie , TITLE =. Statistics and Computing , VOLUME =. 2025 , NUMBER =
work page 2025
-
[10]
Journal of Econometrics , VOLUME =
Xie, Jinhan and Yan, Xiaodong and Jiang, Bei and Kong, Linglong , TITLE =. Journal of Econometrics , VOLUME =. 2025 , pages=
work page 2025
-
[11]
van der Vaart, Aad W. and Wellner, Jon A. , TITLE =. 1996 , PAGES =
work page 1996
-
[12]
Institute of Electrical and Electronics Engineers
Wang, Boxiang and Zhou, Le and Gu, Yuwen and Zou, Hui , TITLE =. Institute of Electrical and Electronics Engineers. Transactions on Information Theory , VOLUME =. 2023 , NUMBER =
work page 2023
-
[13]
Journal of the American Statistical Association , VOLUME =
Cai, Tony and Liu, Weidong and Luo, Xi , TITLE =. Journal of the American Statistical Association , VOLUME =. 2011 , NUMBER =
work page 2011
-
[14]
Electronic Journal of Statistics , VOLUME =
Luo, Lan and Han, Ruijian and Lin, Yuanyuan and Huang, Jian , TITLE =. Electronic Journal of Statistics , VOLUME =. 2023 , NUMBER =
work page 2023
-
[15]
The Annals of Statistics , VOLUME =
Shi, Chengchun and Song, Rui and Chen, Zhao and Li, Runze , TITLE =. The Annals of Statistics , VOLUME =. 2019 , NUMBER =
work page 2019
-
[16]
Journal of the American Statistical Association , VOLUME =
Zhang, Xianyang and Cheng, Guang , TITLE =. Journal of the American Statistical Association , VOLUME =. 2017 , NUMBER =
work page 2017
-
[17]
Computational Statistics & Data Analysis , VOLUME =
Vincent, Martin and Hansen, Niels Richard , TITLE =. Computational Statistics & Data Analysis , VOLUME =. 2014 , PAGES =
work page 2014
-
[18]
Journal of Business & Economic Statistics , VOLUME =
Fernandes, Marcelo and Guerre, Emmanuel and Horta, Eduardo , TITLE =. Journal of Business & Economic Statistics , VOLUME =. 2021 , NUMBER =
work page 2021
-
[19]
2010 IEEE international conference on data mining , pages=
NESVM: A fast gradient method for support vector machines , author=. 2010 IEEE international conference on data mining , pages=. 2010 , organization=
work page 2010
- [20]
-
[21]
SIAM Journal on Imaging Sciences , VOLUME =
Beck, Amir and Teboulle, Marc , TITLE =. SIAM Journal on Imaging Sciences , VOLUME =. 2009 , NUMBER =
work page 2009
-
[22]
Foundations and Trends in optimization , volume=
Proximal algorithms , author=. Foundations and Trends in optimization , volume=. 2014 , publisher=
work page 2014
-
[23]
Journal of Machine Learning Research , VOLUME =
Fang, Yixin and Xu, Jinfeng and Yang, Lei , TITLE =. Journal of Machine Learning Research , VOLUME =. 2018 , PAGES =
work page 2018
-
[24]
Journal of the American Statistical Association , VOLUME =
Chen, Haoyu and Lu, Wenbin and Song, Rui , TITLE =. Journal of the American Statistical Association , VOLUME =. 2021 , NUMBER =
work page 2021
-
[25]
Statistics and its Interface , VOLUME =
Wang, Chun and Chen, Ming-Hui and Schifano, Elizabeth and Wu, Jing and Yan, Jun , TITLE =. Statistics and its Interface , VOLUME =. 2016 , NUMBER =
work page 2016
- [26]
-
[27]
Journal of Computational and Graphical Statistics , VOLUME =
Chen, Xuerong and Yuan, Senlin , TITLE =. Journal of Computational and Graphical Statistics , VOLUME =. 2024 , NUMBER =
work page 2024
-
[28]
Han, Ruijian and Luo, Lan and Lin, Yuanyuan and Huang, Jian , TITLE =. Biometrika , VOLUME =. 2024 , NUMBER =
work page 2024
-
[29]
arXiv preprint arXiv:2405.18284 , year=
Adaptive debiased SGD in high-dimensional GLMs with streaming data , author=. arXiv preprint arXiv:2405.18284 , year=
- [30]
-
[31]
and Wu, Jing and Wang, Chun and Yan, Jun and Chen, Ming-Hui , TITLE =
Schifano, Elizabeth D. and Wu, Jing and Wang, Chun and Yan, Jun and Chen, Ming-Hui , TITLE =. Technometrics. A Journal of Statistics for the Physical, Chemical and Engineering Sciences , VOLUME =. 2016 , NUMBER =
work page 2016
-
[32]
The Canadian Journal of Statistics
Wang, Chun and Chen, Ming-Hui and Wu, Jing and Yan, Jun and Zhang, Yuping and Schifano, Elizabeth , TITLE =. The Canadian Journal of Statistics. La Revue Canadienne de Statistique , VOLUME =. 2018 , NUMBER =
work page 2018
- [33]
-
[34]
European Journal of Operational Research , VOLUME =
Ghaddar, Bissan and Naoum-Sawaya, Joe , TITLE =. European Journal of Operational Research , VOLUME =. 2018 , NUMBER =
work page 2018
-
[35]
Advances in Neural Information Processing Systems , volume=
Support vector machines and linear regression coincide with very high-dimensional features , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Journal of Machine Learning Research , year =
Peng, Bo and Wang, Lan and Wu, Yichao , TITLE =. Journal of Machine Learning Research , year =
-
[37]
Advances in neural information processing systems , volume=
1-norm support vector machines , author=. Advances in neural information processing systems , volume=
- [38]
-
[39]
Elastic SCAD as a novel penalization method for SVM classification tasks in high-dimensional data , author=. BMC bioinformatics , volume=. 2011 , publisher=
work page 2011
-
[40]
Chen, Xi and Lee, Jason D. and Tong, Xin T. and Zhang, Yichen , TITLE =. The Annals of Statistics , VOLUME =. 2020 , NUMBER =
work page 2020
-
[41]
Applied Soft Computing , volume=
Convolution smoothing and non-convex regularization for support vector machine in high dimensions , author=. Applied Soft Computing , volume=. 2024 , publisher=
work page 2024
-
[42]
Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher , title =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , month =. 2011 , address =
work page 2011
-
[43]
Statistics and Computing , VOLUME =
Wang, Kangning and Liu, Jin and Sun, Xiaofei , TITLE =. Statistics and Computing , VOLUME =. 2024 , NUMBER =
work page 2024
-
[44]
Forty-first International Conference on Machine Learning , year=
Finite smoothing algorithm for high-dimensional support vector machines and quantile regression , author=. Forty-first International Conference on Machine Learning , year=
-
[45]
Journal of the American Statistical Association , volume =
Canyi Chen and Nan Qiao and Liping Zhu , title =. Journal of the American Statistical Association , volume =. 2025 , publisher =
work page 2025
-
[46]
Journal of Machine Learning Research , YEAR =
Lian, Heng and Fan, Zengyan , TITLE =. Journal of Machine Learning Research , YEAR =
-
[47]
arXiv preprint arXiv:2106.05925 , year=
Online debiased lasso for streaming data , author=. arXiv preprint arXiv:2106.05925 , year=
-
[48]
Online learning for non-convex penalized support vector machine with convolution smoothing , author=. Neurocomputing , volume =. 2025 , publisher=
work page 2025
- [49]
-
[50]
Stochastic Proximal Gradient Descent with Acceleration Techniques , volume =
Nitanda, Atsushi , booktitle =. Stochastic Proximal Gradient Descent with Acceleration Techniques , volume =
- [51]
-
[52]
Journal of Econometrics , VOLUME =
He, Xuming and Pan, Xiaoou and Tan, Kean Ming and Zhou, Wen-Xin , TITLE =. Journal of Econometrics , VOLUME =. 2023 , NUMBER =
work page 2023
-
[53]
arXiv preprint arXiv:2006.12778 , year=
A revisit to de-biased lasso for generalized linear models , author=. arXiv preprint arXiv:2006.12778 , year=
- [54]
-
[55]
The Annals of Statistics , VOLUME =
van de Geer, Sara and B\"uhlmann, Peter and Ritov, Ya'acov and Dezeure, Ruben , TITLE =. The Annals of Statistics , VOLUME =. 2014 , NUMBER =
work page 2014
-
[56]
Journal of Machine Learning Research , VOLUME =
Javanmard, Adel and Montanari, Andrea , TITLE =. Journal of Machine Learning Research , VOLUME =. 2014 , PAGES =
work page 2014
-
[57]
Journal of Machine Learning Research , YEAR =
Rybak, Jakub and Battey, Heather and Zhou, Wen-Xin , TITLE =. Journal of Machine Learning Research , YEAR =
-
[58]
The Annals of Statistics , VOLUME =
Ning, Yang and Liu, Han , TITLE =. The Annals of Statistics , VOLUME =. 2017 , NUMBER =
work page 2017
-
[59]
The Econometrics Journal , VOLUME =
Fan, Jianqing and Liao, Yuan and Liu, Han , TITLE =. The Econometrics Journal , VOLUME =. 2016 , NUMBER =
work page 2016
-
[60]
Stochastic inequalities and applications , SERIES =
Bousquet, Olivier , TITLE =. Stochastic inequalities and applications , SERIES =. 2003 , ISBN =
work page 2003
-
[61]
Statistics and Computing , volume=
Robust and efficient sparse learning over networks: a decentralized surrogate composite quantile regression approach , author=. Statistics and Computing , volume=. 2025 , publisher=
work page 2025
-
[62]
Tony and Liu, Weidong and Zhou, Harrison H
Cai, T. Tony and Liu, Weidong and Zhou, Harrison H. , TITLE =. The Annals of Statistics , VOLUME =. 2016 , NUMBER =
work page 2016
-
[63]
Electronic Journal of Statistics , VOLUME =
van de Geer, Sara , TITLE =. Electronic Journal of Statistics , VOLUME =. 2019 , NUMBER =
work page 2019
-
[64]
Electronic Journal of Statistics , VOLUME =
Liu, Han and Wang, Lie , TITLE =. Electronic Journal of Statistics , VOLUME =. 2017 , NUMBER =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.