MAJIC: Leveraging Articulatory Motion for Speech-based Emotion Recognition
Pith reviewed 2026-06-26 22:29 UTC · model grok-4.3
The pith
MAJIC fuses jaw and facial motion features with audio to reach 93 percent accuracy in speech emotion recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
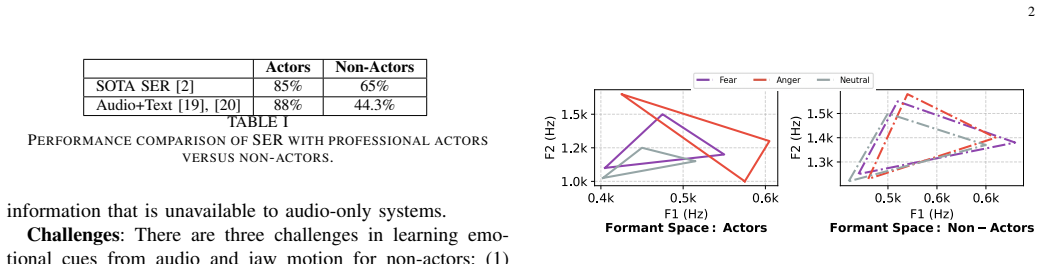
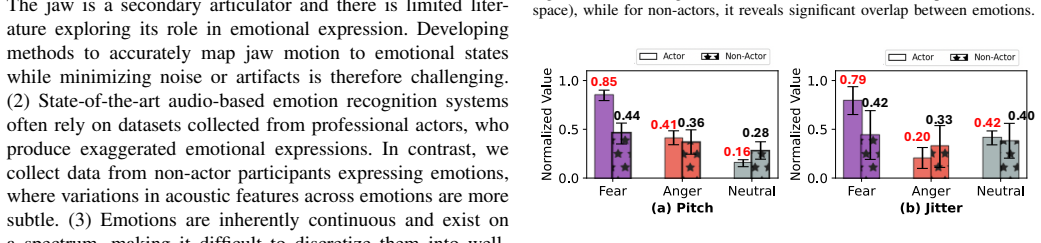
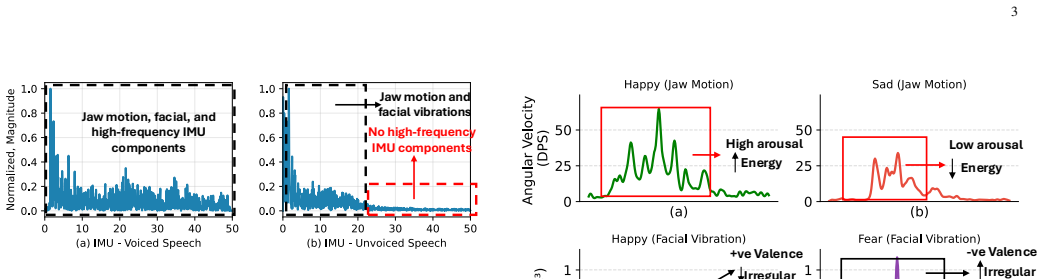
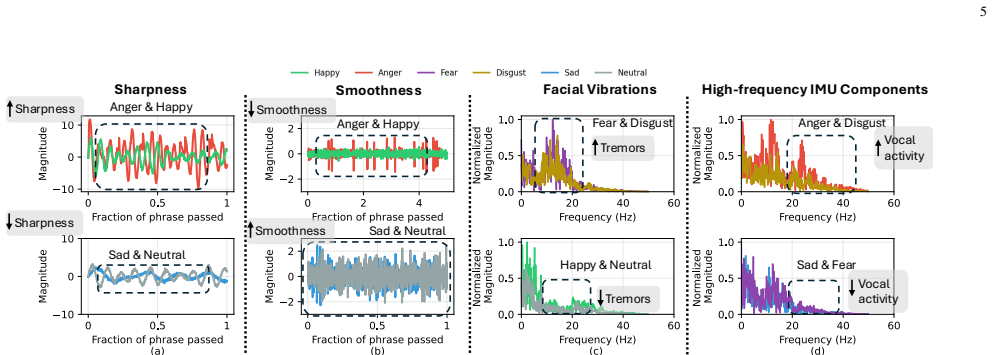
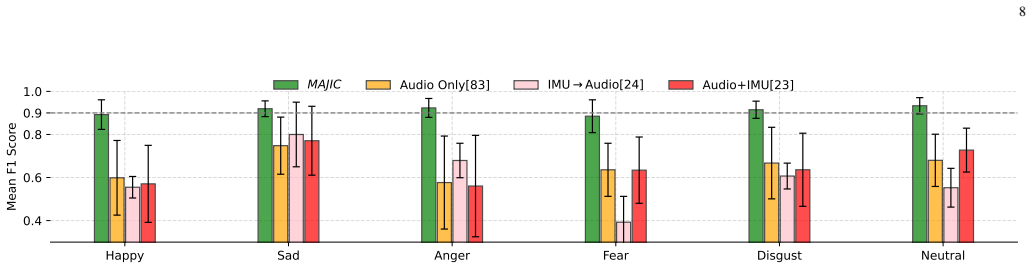
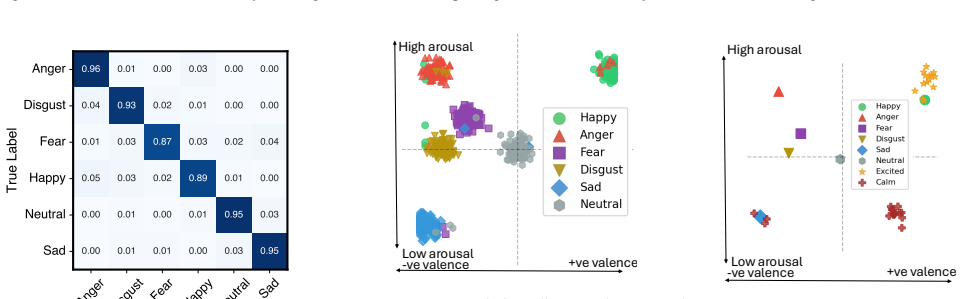
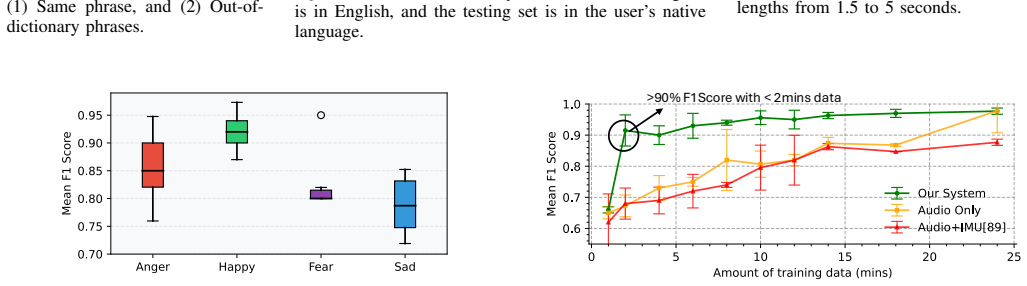
MAJIC shows that engineering features from articulatory motion of the jaw and facial muscles, then integrating them with audio features in a multi-task framework, produces 93 percent accuracy and 91 percent F1 score on emotion classification while outperforming audio-only baselines on a dataset collected from twenty participants across multiple sessions, ten languages, and both prompted and conversational speech.
What carries the argument
The multi-task learning framework that fuses engineered articulatory motion features (jaw movements, facial muscle vibrations, speech-induced vibrations) with audio features to capture complementary emotional signals.
If this is right
- The combined system maintains performance across twenty users, ten languages, prompted speech, and natural conversation.
- It exceeds the results of strong audio-based baselines on the collected data.
- Emotion in speech appears through both vocal traits and distinct physical motions of the jaw and face.
Where Pith is reading between the lines
- Sensor hardware that tracks jaw position could be added to existing voice interfaces to improve emotion detection when background noise degrades audio quality.
- The same fusion idea might apply to other subtle physiological signals such as breathing patterns or muscle tension during speech.
- Real-time versions of the system could support continuous affect monitoring in applications like remote mental health support.
Load-bearing premise
Articulatory motion supplies emotional information that is not already present in audio features alone.
What would settle it
An ablation study on the same dataset in which removing the articulatory motion features leaves accuracy and F1 score unchanged from the reported 93 percent and 91 percent.
Figures




read the original abstract
We introduce MAJIC, a multimodal emotion recognition system that leverages articulatory motion of the jaw and facial muscles for speech-based emotion recognition (SER). While most SER systems perform well on datasets with strongly expressed emotional speech of trained actors, their performance often degrades when emotional expressions become more subtle. We explore this challenge by engineering features from articulatory motion and integrating them with audio features using a multi-task learning framework. Our key insight is that emotion in speech manifests not only through vocal characteristics but also through distinct articulatory motions: jaw movements, facial muscle vibrations, and speech-induced vibrations. While audio captures features such as pitch and prosody, articulatory motion contains complementary information that is not present in audio alone. We evaluate our system on data collected from 20 participants across multiple sessions, 10 languages, and diverse scenarios, including prompted and conversational speech, showing its robustness across users and settings. MAJIC achieves 93% accuracy and 91% F1 score for emotion classification, outperforming strong audio-based baselines on our dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAJIC, a multimodal speech emotion recognition system that extracts features from articulatory motion (jaw and facial muscle vibrations) and fuses them with audio features via multi-task learning. It claims that articulatory motion supplies complementary information absent from audio alone, evaluates the system on a custom dataset from 20 participants across 10 languages and prompted/conversational scenarios, and reports 93% accuracy and 91% F1, outperforming audio baselines.
Significance. If the central performance claims can be substantiated with ablations and full experimental details, the work would offer a concrete demonstration that articulatory sensing can improve SER robustness for subtle expressions; the multi-session, multi-language collection is a positive aspect of the evaluation design.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation section: the claim that articulatory motion 'contains complementary information that is not present in audio alone' is presented as the key insight yet is unsupported by any audio-only ablation, feature-importance ranking, or statistical test that isolates the articulatory contribution.
- [Evaluation] Evaluation section: the headline figures (93% accuracy, 91% F1) are stated without any description of the validation procedure, train/test split, cross-validation scheme, baseline implementations, error bars, or participant demographics, rendering the numbers impossible to interpret or reproduce.
- [Dataset / Results] Dataset and results sections: all reported gains are obtained on a privately collected corpus with no external benchmark, pre-registered protocol, or public release, creating a circularity risk that the result is tuned to the authors' own collection and labeling choices.
minor comments (1)
- [Abstract] The abstract refers to 'strong audio-based baselines' without naming the specific models or feature sets used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify gaps in experimental transparency and substantiation of claims. We address each point below and will revise the manuscript to incorporate additional analyses, details, and clarifications where feasible.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the claim that articulatory motion 'contains complementary information that is not present in audio alone' is presented as the key insight yet is unsupported by any audio-only ablation, feature-importance ranking, or statistical test that isolates the articulatory contribution.
Authors: The manuscript reports that MAJIC outperforms audio-only baselines, which provides indirect evidence of complementarity. However, we agree that a direct ablation isolating the articulatory contribution (e.g., audio-only vs. fused, plus feature importance) would strengthen the claim. We will add these analyses, including statistical tests, to the revised Evaluation section. revision: yes
-
Referee: [Evaluation] Evaluation section: the headline figures (93% accuracy, 91% F1) are stated without any description of the validation procedure, train/test split, cross-validation scheme, baseline implementations, error bars, or participant demographics, rendering the numbers impossible to interpret or reproduce.
Authors: We acknowledge that the current manuscript provides insufficient detail on these aspects. In the revision we will expand the Evaluation section to fully describe the validation procedure (including leave-one-participant-out cross-validation), train/test splits, baseline implementations with references, error bars across runs, and participant demographics. revision: yes
-
Referee: [Dataset / Results] Dataset and results sections: all reported gains are obtained on a privately collected corpus with no external benchmark, pre-registered protocol, or public release, creating a circularity risk that the result is tuned to the authors' own collection and labeling choices.
Authors: The corpus is custom because it requires specialized hardware to capture articulatory motion, which is absent from existing public SER datasets. The collection protocol was designed to span 10 languages, multiple sessions, and prompted/conversational scenarios precisely to demonstrate robustness. We will add more details on the labeling process and internal protocol in the revision. Full public release is constrained by participant consent and privacy regulations for speech data; we will clarify this limitation and release code where possible. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical engineering system for multimodal emotion recognition with no equations, no fitted parameters renamed as predictions, and no derivation steps that reduce to inputs by construction. The central performance claim rests on evaluation of a described multi-task learning integration on a privately collected dataset, but this is a standard empirical reporting pattern with no self-definitional loop, no load-bearing self-citation chain, and no ansatz smuggled via prior work. The key insight about complementary information is presented as motivation rather than a derived result that collapses into its own premise. The derivation is therefore self-contained as an applied ML contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ai-powered chatbots as emotion-aware virtual assistants: Enhancing student support and engagement in higher education,
Y . Alnsour, “Ai-powered chatbots as emotion-aware virtual assistants: Enhancing student support and engagement in higher education,” 2026
2026
-
[2]
emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,” inFindings of the Association for Computational Linguistics ACL 2024, August 2024, pp. 15 747–15 760
2024
-
[3]
Enhancing speech emotion recognition through a cross-dataset analysis: Exploring improved models,
R. M. Ben-Sauod, R. S. Alshwehdi, and W. I. Eltarhouni, “Enhancing speech emotion recognition through a cross-dataset analysis: Exploring improved models,” in2024 IEEE 4th International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering (MI-STA). IEEE, 2024, pp. 706–711
2024
-
[4]
Exploring the potential of convolutional neural networks in sequential data analysis: A comparative study with lstms and bilstms,
S. Tyagi and S. Sz ´en´asi, “Exploring the potential of convolutional neural networks in sequential data analysis: A comparative study with lstms and bilstms,” in2024 IEEE 22nd World Symposium on Applied Machine Intelligence and Informatics (SAMI). IEEE, 2024, pp. 000 243–000 248
2024
-
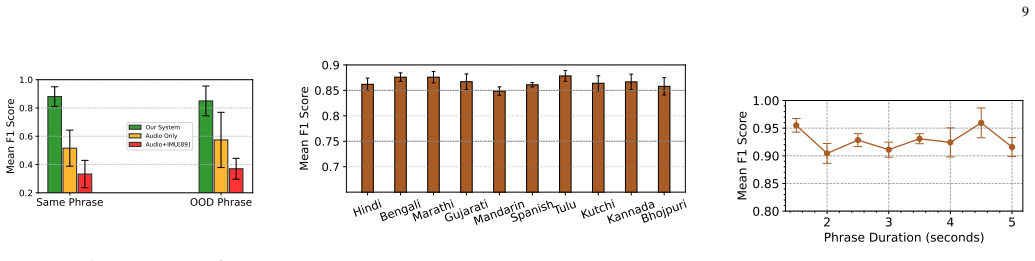
[5]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,” https://sail.usc.edu/iemocap/, 2008, accessed: [Insert Access Date]
2008
-
[6]
The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,
S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,”PloS one, vol. 13, no. 5, p. e0196391, 2018
2018
-
[7]
Text-based emo- tion detection: Advances, challenges, and opportunities,
F. A. Acheampong, C. Wenyu, and H. Nunoo-Mensah, “Text-based emo- tion detection: Advances, challenges, and opportunities,”Engineering Reports, vol. 2, no. 7, p. e12189, 2020
2020
-
[8]
A survey of state-of-the-art approaches for emotion recognition in text,
N. Alswaidan and M. E. B. Menai, “A survey of state-of-the-art approaches for emotion recognition in text,”Knowledge and Information Systems, vol. 62, no. 8, pp. 2937–2987, 2020
2020
-
[9]
Kjeldsen: Design issues for vision-based computer... - google scholar,
“Kjeldsen: Design issues for vision-based computer... - google scholar,” [Online; accessed 2024-12-09]. [Online]. Available: https://scholar.google.com/scholar?start=10&hl=en&as sdt= 5,33&sciodt=0,33&cites=5584770157155220716&scipsc=&authuser=3
2024
-
[10]
The limitations for expression recognition in computer vision introduced by facial masks,
A. F. Abate, L. Cimmino, B.-C. Mocanu, F. Narducci, and F. Pop, “The limitations for expression recognition in computer vision introduced by facial masks,”Multimedia Tools and Applications, vol. 82, no. 8, pp. 11 305–11 319, 2023
2023
-
[11]
M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues,
T. Mittal, U. Bhattacharya, R. Chandra, A. Bera, and D. Manocha, “M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 02, 2020, pp. 1359–1367
2020
-
[12]
Deap: A database for emotion analysis; using physiological signals,
S. Koelstra, C. Muhl, M. Soleymani, J.-S. Lee, A. Yazdani, T. Ebrahimi, T. Pun, A. Nijholt, and I. Patras, “Deap: A database for emotion analysis; using physiological signals,”IEEE transactions on affective computing, vol. 3, no. 1, pp. 18–31, 2011
2011
-
[13]
A multimodal database for affect recognition and implicit tagging,
M. Soleymani, J. Lichtenauer, T. Pun, and M. Pantic, “A multimodal database for affect recognition and implicit tagging,”IEEE transactions on affective computing, vol. 3, no. 1, pp. 42–55, 2011
2011
-
[14]
Decaf: Meg-based multimodal database for decoding affective physiological responses,
M. K. Abadi, R. Subramanian, S. M. Kia, P. Avesani, I. Patras, and N. Sebe, “Decaf: Meg-based multimodal database for decoding affective physiological responses,”IEEE Transactions on Affective Computing, vol. 6, no. 3, pp. 209–222, 2015
2015
-
[15]
Articulatory correlates of prosodic control: Emotion and emphasis,
D. Erickson, O. Fujimura, and B. Pardo, “Articulatory correlates of prosodic control: Emotion and emphasis,”Language and Speech, vol. 41, no. 3-4, pp. 399–417, 1998
1998
-
[16]
Measure- ments of articulatory variation in expressive speech for a set of swedish vowels,
M. Nordstrand, G. Svanfeldt, B. Granstr ¨om, and D. House, “Measure- ments of articulatory variation in expressive speech for a set of swedish vowels,”Speech Communication, vol. 44, no. 1-4, pp. 187–196, 2004
2004
-
[17]
Articu- lation constrained learning with application to speech emotion recogni- tion,
M. Shah, M. Tu, V . Berisha, C. Chakrabarti, and A. Spanias, “Articu- lation constrained learning with application to speech emotion recogni- tion,”EURASIP journal on audio, speech, and music processing, vol. 2019, pp. 1–17, 2019
2019
-
[18]
A study of emotional speech articulation using a fast magnetic resonance imaging technique
S. Lee, E. Bresch, J. Adams, A. Kazemzadeh, and S. S. Narayanan, “A study of emotional speech articulation using a fast magnetic resonance imaging technique.” inINTERSPEECH, vol. 2006, 2006, pp. 1792–1795
2006
-
[19]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision (arxiv: 2212.04356). arxiv,” 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
bert-base-uncased-emotion,
B. Savani, “bert-base-uncased-emotion,” https://huggingface.co/ bhadresh-savani/bert-base-uncased-emotion, 2021
2021
-
[21]
A circumplex model of affect
J. A. Russell, “A circumplex model of affect.”Journal of personality and social psychology, vol. 39, no. 6, p. 1161, 1980
1980
-
[22]
Muteit: Jaw motion based unvoiced command recognition using earable,
T. Srivastava, P. Khanna, S. Pan, P. Nguyen, and S. Jain, “Muteit: Jaw motion based unvoiced command recognition using earable,”Pro- ceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 6, no. 3, pp. 1–26, 2022
2022
-
[23]
Jawthenticate: Microphone-free speech-based authentication using jaw motion and facial vibrations,
T. Srivastava, S. Pan, P. Nguyen, and S. Jain, “Jawthenticate: Microphone-free speech-based authentication using jaw motion and facial vibrations,” inProceedings of the 21st ACM Conference on Embedded Networked Sensor Systems, 2023, pp. 209–222
2023
-
[24]
Unvoiced: Designing an llm-assisted unvoiced user interface using earables,
T. Srivastava, P. Khanna, S. Pan, P. Nguyen, and S. Jain, “Unvoiced: Designing an llm-assisted unvoiced user interface using earables,” in Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems, 2024, pp. 784–798
2024
-
[25]
Face-mic: inferring live speech and speaker identity via subtle facial dynamics captured by ar/vr motion sensors,
C. Shi, X. Xu, T. Zhang, P. Walker, Y . Wu, J. Liu, N. Saxena, Y . Chen, and J. Yu, “Face-mic: inferring live speech and speaker identity via subtle facial dynamics captured by ar/vr motion sensors,” inProceedings of the 27th Annual International Conference on Mobile Computing and Networking, 2021, pp. 478–490
2021
-
[26]
Prosody in Phonetics: Definition and Examples,
ThoughtCo., “Prosody in Phonetics: Definition and Examples,” n.d., accessed: 2024-12-05. [Online]. Available: https://www.thoughtco.com/ prosody-phonetics-1691693
2024
-
[27]
A new approach of audio emotion recognition,
C. S. Ooi, K. P. Seng, L.-M. Ang, and L. W. Chew, “A new approach of audio emotion recognition,”Expert systems with applications, vol. 41, no. 13, pp. 5858–5869, 2014
2014
-
[28]
The acoustic cue of fear: investigation of acoustic param- eters of speech containing fear,
T. ¨Ozseven, “The acoustic cue of fear: investigation of acoustic param- eters of speech containing fear,”Archives of Acoustics, vol. 43, no. 2, pp. 245–251, 2018
2018
-
[29]
Analysis of emotion recog- nition using facial expressions, speech and multimodal information,
C. Busso, Z. Deng, S. Yildirim, M. Bulut, C. M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, and S. Narayanan, “Analysis of emotion recog- nition using facial expressions, speech and multimodal information,” inProceedings of the 6th international conference on Multimodal interfaces, 2004, pp. 205–211
2004
-
[30]
Control of coarticulatory patterns of tongue and jaw movement in speech,
D. J. Ostry, D. M. Shiller, P. L. Gribble, and V . L. Gracco, “Control of coarticulatory patterns of tongue and jaw movement in speech,” 1999. [Online]. Available: https://api.semanticscholar.org/CorpusID:18681932 12
1999
-
[31]
An articu- latory study of emotional speech production
S. Lee, S. Yildirim, A. Kazemzadeh, and S. S. Narayanan, “An articu- latory study of emotional speech production.” inInterspeech, 2005, pp. 497–500
2005
-
[32]
Articulatory characteristics of expressive speech in activation-evaluation space,
T. Asai, A. Suemitsu, and M. Akagi, “Articulatory characteristics of expressive speech in activation-evaluation space,” in2017 RISP Inter- national Workshop on Nonlinear Circuits, Communications and Signal Processing (NCSP’17). Research Institute of Signal Processing, Japan, 2017
2017
-
[33]
Articulatory-acoustic analyses of mandarin words in emotional context speech for smart campus,
G. Ren, X. Zhang, and S. Duan, “Articulatory-acoustic analyses of mandarin words in emotional context speech for smart campus,”IEEE Access, vol. 6, pp. 48 418–48 427, 2018
2018
-
[34]
Emotion recog- nition involving physiological and speech signals: A comprehensive review,
M. Ali, A. H. Mosa, F. A. Machot, and K. Kyamakya, “Emotion recog- nition involving physiological and speech signals: A comprehensive review,”Recent Advances in Nonlinear Dynamics and Synchronization: With Selected Applications in Electrical Engineering, Neurocomputing, and Transportation, pp. 287–302, 2018
2018
-
[35]
Jawsense: recognizing unvoiced sound using a low-cost ear-worn system,
P. Khanna, T. Srivastava, S. Pan, S. Jain, and P. Nguyen, “Jawsense: recognizing unvoiced sound using a low-cost ear-worn system,” in Proceedings of the 22nd International Workshop on Mobile Computing Systems and Applications, 2021, pp. 44–49
2021
-
[36]
Y . Sui, M. Zhao, J. Xia, X. Jiang, and S. Xia, “Tramba: A hybrid transformer and mamba architecture for practical audio and bone conduction speech super resolution and enhancement on mobile and wearable platforms,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 8, no. 4, Nov. 2024. [Online]. Available: https://doi.org/10.1145/3699757
-
[37]
Rethinking gesture phases: Articulatory features of gestural movement?
J. Bressem and S. H. Ladewig, “Rethinking gesture phases: Articulatory features of gestural movement?” 2011
2011
-
[38]
Specific respiratory pat- terns distinguish among human basic emotions,
S. Bloch, M. Lemeignan, and N. Aguilera-T, “Specific respiratory pat- terns distinguish among human basic emotions,”International Journal of Psychophysiology, vol. 11, no. 2, pp. 141–154, 1991
1991
-
[39]
Evaluation of gait smoothness in patients with stroke undergoing rehabilitation: Comparison between two metrics,
M. Germanotta, C. Iacovelli, and I. Aprile, “Evaluation of gait smoothness in patients with stroke undergoing rehabilitation: Comparison between two metrics,”International Journal of Environmental Research and Public Health, vol. 19, no. 20, 2022. [Online]. Available: https://www.mdpi.com/1660-4601/19/20/13440
2022
-
[40]
Spectral arc length as a method to quantify pharyngeal high-resolution manometric curve smoothness,
A. J. Scholp, M. R. Hoffman, S. P. Rosen, S. M. Abdelhalim, C. A. Jones, J. J. Jiang, and T. M. McCulloch, “Spectral arc length as a method to quantify pharyngeal high-resolution manometric curve smoothness,” Neurogastroenterology & Motility, vol. 33, no. 10, p. e14122, 2021
2021
-
[41]
Affect bursts as evolutionary precursors of speech and music,
K. R. Scherer, “Affect bursts as evolutionary precursors of speech and music,” inStephen j. Gould: The scientific legacy. Springer, 2013, pp. 147–167
2013
-
[42]
Validity and reliability of nonverbal voice measures as indicators of stressor-provoked anxiety,
B. F. Fuller, Y . Horii, and D. A. Conner, “Validity and reliability of nonverbal voice measures as indicators of stressor-provoked anxiety,” Research in nursing & health, vol. 15, no. 5, pp. 379–389, 1992
1992
-
[43]
N. Gomes, B. M. Pause, M. A. M. Smeets, and G. R. Semin, “Comparing fear and anxiety chemosignals: Do they modulate facial muscle activity and facilitate identifying facial expressions?” Chemical Senses, vol. 48, p. bjad016, 05 2023. [Online]. Available: https://doi.org/10.1093/chemse/bjad016
-
[44]
Emotion recognition in the noise applying large acoustic feature sets,
B. Schuller, D. Arsic, F. Wallhoff, and G. Rigoll, “Emotion recognition in the noise applying large acoustic feature sets,” 2006
2006
-
[45]
opensmile–the munich versatile and fast open-source audio feature extractor,
F. Eyben, M. W ¨ollmer, and B. Schuller, “opensmile–the munich versatile and fast open-source audio feature extractor,” inProceedings of the 18th ACM International Conference on Multimedia. ACM, 2010, pp. 1459– 1462
2010
-
[46]
A comparison of machine learning algorithms and feature sets for automatic vocal emotion recognition in speech,
C. Do ˘gdu, T. Kessler, D. Schneider, M. Shadaydeh, and S. R. Schwein- berger, “A comparison of machine learning algorithms and feature sets for automatic vocal emotion recognition in speech,”Sensors (Basel), vol. 22, no. 19, p. 7561, 2022
2022
-
[47]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, vol. 364, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[48]
A survey on multi-task learning,
Y . Zhang and Q. Yang, “A survey on multi-task learning,”IEEE transactions on knowledge and data engineering, vol. 34, no. 12, pp. 5586–5609, 2021
2021
-
[49]
Whispering wearables: Multimodal approach to silent speech recognition with head-worn devices,
T. Srivastava, R. M. Winters, T. Gable, Y . T. Wang, T. LaScala, and I. J. Tashev, “Whispering wearables: Multimodal approach to silent speech recognition with head-worn devices,” inProceedings of the 26th International Conference on Multimodal Interaction, 2024, pp. 214–223
2024
-
[50]
Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning,
Z. Cheng, Z.-Q. Cheng, J.-Y . He, J. Sun, K. Wang, Y . Lin, Z. Lian, X. Peng, and A. Hauptmann, “Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning,”arXiv preprint arXiv:2406.11161, 2024
-
[51]
Fine-tuning the wav2vec2 model for automatic speech emotion recognition system,
D. Kayande, I. B. Sonowal, and R. K. Bhukya, “Fine-tuning the wav2vec2 model for automatic speech emotion recognition system,” in 2023 26th Conference of the Oriental COCOSDA International Com- mittee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA). IEEE, 2023, pp. 1–6
2023
-
[52]
Speech based emotion recognition using machine learning,
G. Deshmukh, A. Gaonkar, G. Golwalkar, and S. Kulkarni, “Speech based emotion recognition using machine learning,” in2019 3rd inter- national conference on computing methodologies and communication (ICCMC). IEEE, 2019, pp. 812–817
2019
-
[53]
A machine learning and deep learning based approach to generate a speech emotion recognition system,
K. Vaidehi, Q. Nishaet al., “A machine learning and deep learning based approach to generate a speech emotion recognition system,” in2024 11th International Conference on Computing for Sustainable Global Development (INDIACom). IEEE, 2024, pp. 573–577
2024
-
[54]
Speech emotion recognition using attention model,
J. Singh, L. B. Saheer, and O. Faust, “Speech emotion recognition using attention model,”International Journal of Environmental Research and Public Health, vol. 20, no. 6, p. 5140, 2023
2023
-
[55]
Lstm based feature learning and cnn based classification for speech emotion recognition,
H. Kalra, “Lstm based feature learning and cnn based classification for speech emotion recognition,” in2023 International Conference on Data Science and Network Security (ICDSNS). IEEE, 2023, pp. 1–6
2023
-
[56]
A deep learning approach for speech emotion recognition optimization using meta-learning,
L. T. C. Ottoni, A. L. C. Ottoni, and J. d. J. F. Cerqueira, “A deep learning approach for speech emotion recognition optimization using meta-learning,”Electronics, vol. 12, no. 23, p. 4859, 2023
2023
-
[57]
Toronto emotional speech set (tess)-younger talker happy,
K. Dupuis and M. K. Pichora-Fuller, “Toronto emotional speech set (tess)-younger talker happy,” 2010
2010
-
[58]
Speaker-dependent audio-visual emotion recognition
S. Haq, P. J. Jackson, and J. Edge, “Speaker-dependent audio-visual emotion recognition.” inAVSP, vol. 2009, 2009, pp. 53–58
2009
-
[59]
Emotional voice messages (emovome) database: emotion recognition in spontaneous voice messages,
L. G. Zaragoz ´a, R. del Amor, E. P. Vargas, V . Naranjo, M. A. Raya, and J. Mar´ın-Morales, “Emotional voice messages (emovome) database: emotion recognition in spontaneous voice messages,”arXiv preprint arXiv:2402.17496, 2024
-
[60]
End-to-end speech emotion recognition: challenges of real-life emergency call centers data recordings,
T. Deschamps-Berger, L. Lamel, and L. Devillers, “End-to-end speech emotion recognition: challenges of real-life emergency call centers data recordings,” in2021 9th International Conference on Affective Computing and Intelligent Interaction (ACII). IEEE, 2021, pp. 1–8
2021
-
[61]
Crema-d: Crowd-sourced emotional multimodal actors dataset,
H. Cao, D. G. Cooper, M. K. Keutmann, R. C. Gur, A. Nenkova, and R. Verma, “Crema-d: Crowd-sourced emotional multimodal actors dataset,”IEEE transactions on affective computing, vol. 5, no. 4, pp. 377–390, 2014
2014
-
[62]
Cmu- mosei: A multimodal dataset for sentiment and emotion analysis,
A. Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency, “Cmu- mosei: A multimodal dataset for sentiment and emotion analysis,” http://multicomp.cs.cmu.edu/resources/cmu-mosei-dataset/, 2018
2018
-
[63]
Audio-visual emotion recognition using k-means clustering and spatio-temporal cnn,
M. Sharafi, M. Yazdchi, and J. Rasti, “Audio-visual emotion recognition using k-means clustering and spatio-temporal cnn,” in2023 6th Interna- tional Conference on Pattern Recognition and Image Analysis (IPRIA). IEEE, 2023, pp. 1–6
2023
-
[64]
Sarcasm identification in textual data: systematic review, research challenges and open directions,
C. I. Eke, A. A. Norman, L. Shuib, and H. F. Nweke, “Sarcasm identification in textual data: systematic review, research challenges and open directions,”Artificial Intelligence Review, vol. 53, pp. 4215–4258, 2020
2020
-
[65]
Emotion recognition based on multi-modal physiological signals and transfer learning,
Z. Fu, B. Zhang, X. He, Y . Li, H. Wang, and J. Huang, “Emotion recognition based on multi-modal physiological signals and transfer learning,”Frontiers in Neuroscience, vol. 16, p. 1000716, 2022
2022
-
[66]
Emotion recognition with audio, video, eeg, and emg: a dataset and baseline approaches,
J. Chen, T. Ro, and Z. Zhu, “Emotion recognition with audio, video, eeg, and emg: a dataset and baseline approaches,”IEEE Access, vol. 10, pp. 13 229–13 242, 2022
2022
-
[67]
Multimodal emotion recognition from expressive faces, body gestures and speech,
G. Castellano, L. Kessous, and G. Caridakis, “Multimodal emotion recognition from expressive faces, body gestures and speech,”Doctoral Consortium of ACII, Lisbon, 2007
2007
-
[68]
Speech emotion based sentiment recognition using deep neural networks,
R. R. Choudhary, G. Meena, and K. K. Mohbey, “Speech emotion based sentiment recognition using deep neural networks,” inJournal of physics: conference series, vol. 2236, no. 1. IOP Publishing, 2022, p. 012003
2022
-
[69]
Emotion detection from multilingual audio using deep analysis,
S. Bhattacharya, S. Borah, B. K. Mishra, and A. Mondal, “Emotion detection from multilingual audio using deep analysis,”Multimedia Tools and Applications, vol. 81, no. 28, pp. 41 309–41 338, 2022
2022
-
[70]
Speech emotion recognition using mel-frequency cepstral coefficients & convolutional neural networks,
S. Kadam, J. Jani, A. Kudtarkar, and R. Koshy, “Speech emotion recognition using mel-frequency cepstral coefficients & convolutional neural networks,” in2024 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT). IEEE, 2024, pp. 1595–1602
2024
-
[71]
Multi-modal emotion recognition using eeg and speech signals,
Q. Wang, M. Wang, Y . Yang, and X. Zhang, “Multi-modal emotion recognition using eeg and speech signals,”Computers in Biology and Medicine, vol. 149, p. 105907, 2022
2022
-
[72]
MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihal- cea, “Meld: A multimodal multi-party dataset for emotion recognition in conversations,”arXiv preprint arXiv:1810.02508, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[73]
Surrey audio-visual expressed emotion (savee) database,
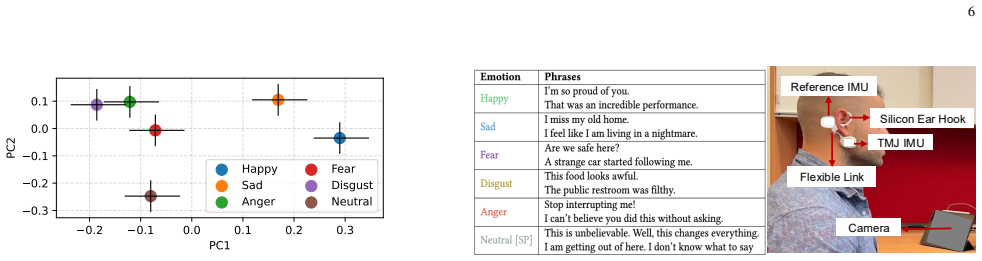
P. Jackson and S. Haq, “Surrey audio-visual expressed emotion (savee) database,”University of Surrey: Guildford, UK, 2014. 13 APPENDIX A. Participants and Study Protocol We conducted an IRB-approved study involving 20 partic- ipants (12 males and 8 females), who were fluent in English and one or more non-English native languages: Hindi (14), Bengali (4), ...
2014
-
[74]
This data was used to train the system for our primary emotion recognition task
Different Phrases:Users vocally expressed emotions while speaking 10 phrases (2–3 repetitions in each session) designed to elicit a specific emotional state. This data was used to train the system for our primary emotion recognition task
-
[75]
Same Phrase:Many phrases can be spoken with dif- ferent emotional tones, but text-only approaches often fail to capture this variability. To assess whether our system is content-agnostic, users were asked to vocally express various emotions while speaking the same set of 10 phrases for each emotion, ensuring that emotional variation was conveyed solely th...
-
[76]
This enabled us to evaluate whether the system is content- and language-agnostic
Native Language:Users were asked to speak two phrases of their choice for each emotion in a non-English native language. This enabled us to evaluate whether the system is content- and language-agnostic
-
[77]
This data was used to investigate how longer spoken sequences or snippets from familiar stories impact system performance
Paragraphs:Users vocally expressed emotions while reading aloud three paragraphs for each of the five target emotions (Happy, Sad, Anger, Fear, and Disgust). This data was used to investigate how longer spoken sequences or snippets from familiar stories impact system performance
-
[78]
These prompts were designed to encourage participants to express target emotions in a conversational setting while still relying on self-reported labels
Conversational Data:We conducted conversational prompts with five participants designed to elicit everyday emo- tional expressions. These prompts were designed to encourage participants to express target emotions in a conversational setting while still relying on self-reported labels. The conversations covered three topics: travel experiences, food prefer...
-
[79]
Each participant expressed each emotion 20 times
Motion and Acoustic Noise Data:We collected data from six participants in the presence of motion noise, wherein participants were free to walk around the room during data collection. Each participant expressed each emotion 20 times. In addition, we collected data with five users in the presence of acoustic noise, playing ambient restaurant sounds, rock mu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.