DRL-based Power Allocation in LiDAL-Assisted RLNC-NOMA OWC Systems
Pith reviewed 2026-05-16 14:27 UTC · model grok-4.3
The pith
A normalized advantage function deep reinforcement learning algorithm learns continuous power allocation policies that match exhaustive search performance in LiDAL-assisted RLNC-NOMA optical wireless systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a DRL-based normalized advantage function algorithm can maximize the average sum rate in a LiDAL-assisted RLNC-NOMA OWC system by learning continuous power-allocation policies that account for multiple users, RLNC decoding, and imperfect CSI from location estimation, achieving performance comparable to exhaustive search while remaining computationally tractable.
What carries the argument
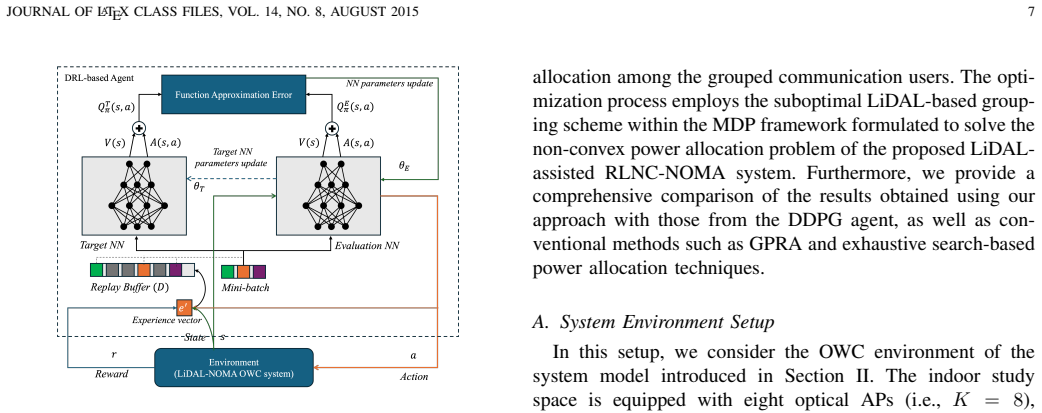
The normalized advantage function (NAF) algorithm, which parameterizes a deterministic policy and advantage function to handle continuous power-allocation actions inside the reinforcement-learning loop.
If this is right
- Power allocation in dense indoor NOMA optical links can be performed dynamically without prohibitive computation.
- RLNC provides measurable resilience gains during successive interference cancellation under imperfect CSI.
- Location estimation errors from LiDAL remain tolerable when the allocation policy is trained with realistic error statistics.
- The same framework can track changing user positions without requiring repeated exhaustive re-optimization.
Where Pith is reading between the lines
- The method may transfer to other continuous-control problems in optical or radio networks where channel estimates are noisy.
- Adding mobility models or outdoor scattering could test whether the learned policy remains stable outside the simulated indoor setting.
- Hybridizing NAF with model-based planning might further reduce training samples needed for new room geometries.
Load-bearing premise
The reinforcement-learning agent can discover near-optimal continuous power levels from simulated interactions among multiple users, RLNC decoding, and imperfect location-derived channel estimates in dense indoor rooms.
What would settle it
Running the learned NAF policy on real LiDAL hardware with several simultaneous users and comparing the resulting measured sum rate against an exhaustive-search benchmark performed on the same physical links would confirm or refute near-optimality.
Figures

read the original abstract
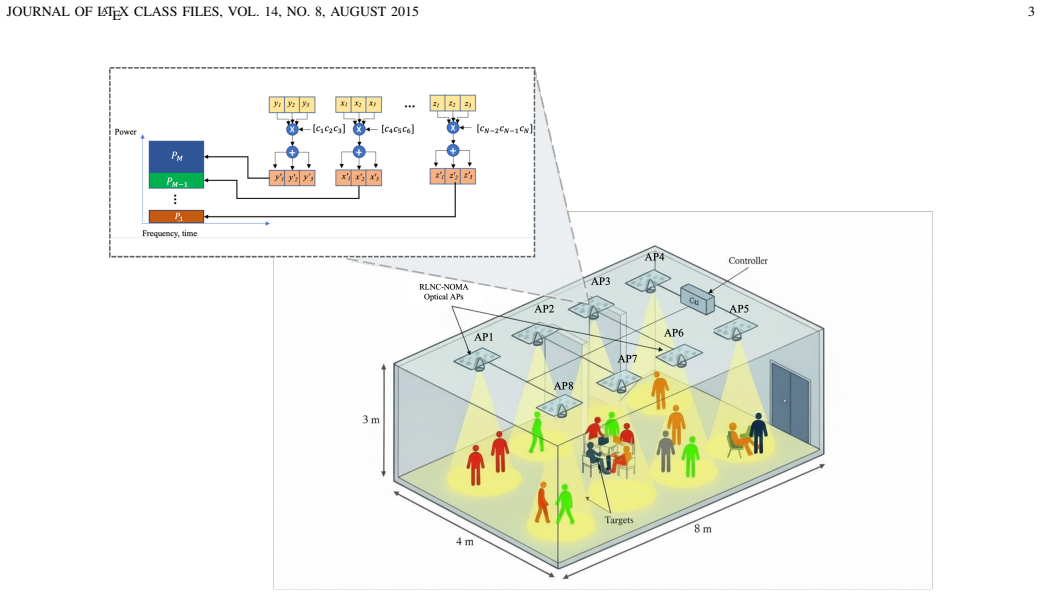
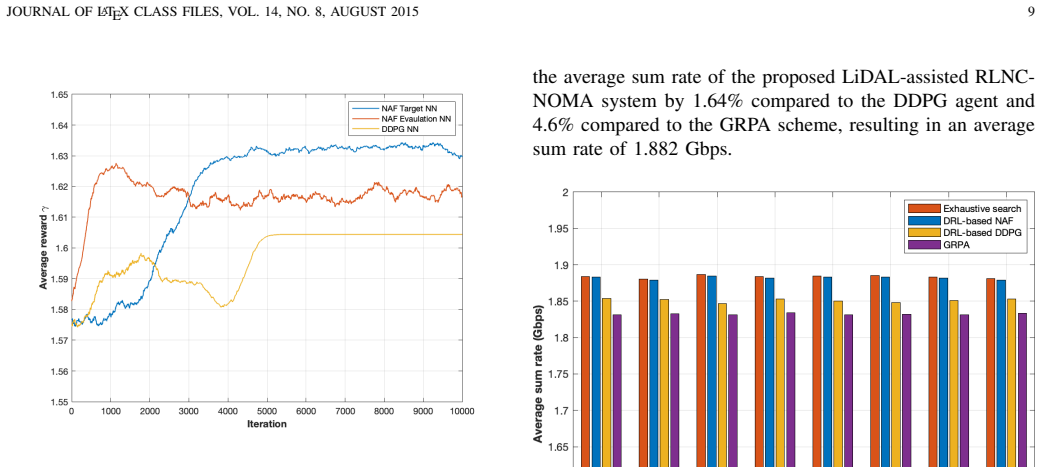
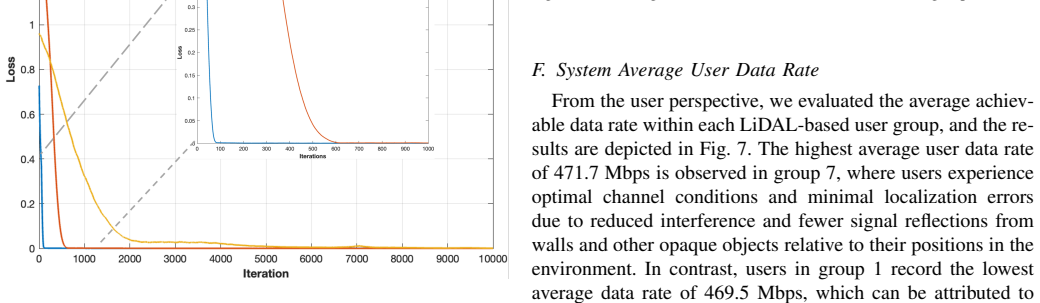
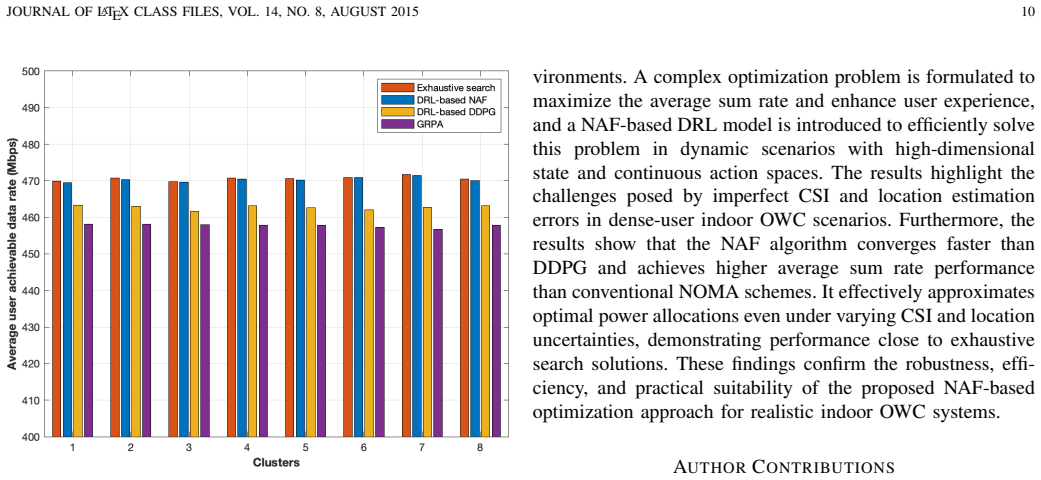
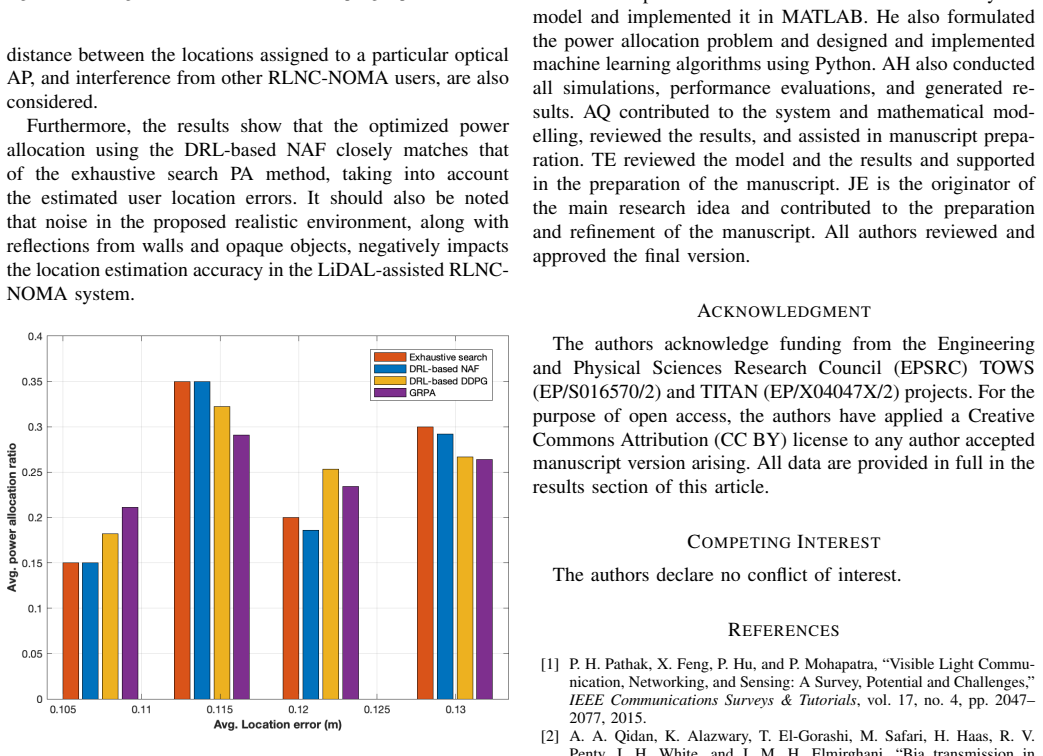
Non-orthogonal multiple access (NOMA) is a promising technique for optical wireless communication (OWC), enabling multiple users to share the optical spectrum simultaneously through the power domain. However, imperfect channel state information (CSI) and residual decoding errors deteriorate NOMA performance, especially in realistic dense-user indoor scenarios. In this work, we model an OWC system that integrates light detection and localization (LiDAL) and random linear network coding (RLNC) within a NOMA framework. LiDAL exploits spatio-temporal information to improve user CSI, while RLNC enhances data resilience in the successive decoding process, resulting in a LiDAL-assisted RLNC-NOMA OWC system. Power allocation (PA) is crucial in this system due to complex interactions between multiple users and the coding and detection processes, but optimizing continuous PA dynamically can be computationally prohibitive. To address this, we adopt a deep reinforcement learning (DRL) framework to efficiently learn near-optimal PA strategies. In particular, a DRL-based normalized advantage function (NAF) algorithm is proposed to maximize the average sum rate, and its performance is compared to deep deterministic policy gradient (DDPG), gain ratio PA (GRPA), and exhaustive search. The results indicate that NAF closely matches exhaustive search, is 39% faster than DDPG, and improves the average sum rate by 4.6% over GRPA, while accounting for user location estimation errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models a LiDAL-assisted RLNC-NOMA OWC system and proposes a DRL-based normalized advantage function (NAF) algorithm for continuous power allocation to maximize average sum rate. It compares NAF against DDPG, gain-ratio power allocation (GRPA), and exhaustive search, claiming that NAF closely matches exhaustive search, runs 39% faster than DDPG, delivers a 4.6% sum-rate improvement over GRPA, and remains effective under user location estimation errors.
Significance. If the reported gains and near-optimality hold for realistic user densities, the work would demonstrate a practical DRL approach to a computationally hard power-allocation problem in imperfect-CSI NOMA-OWC systems, with RLNC providing additional decoding resilience. The explicit handling of LiDAL-based location errors is a concrete strength.
major comments (2)
- [Abstract] Abstract: the headline claim that NAF 'closely matches exhaustive search' is load-bearing for the assertion of near-optimal policies, yet the manuscript itself notes that continuous PA optimization is computationally prohibitive in dense indoor settings with multiple users and RLNC interactions. The paper must state the exact user counts at which exhaustive search was feasible and show that the performance gap to NAF remains negligible in the higher-density regime where exhaustive search cannot be run.
- [Abstract] Abstract: the 4.6% sum-rate gain over GRPA and 39% speed-up versus DDPG are presented without any description of simulation parameters, number of users, modeling of location-estimation errors, number of Monte-Carlo runs, or error bars. These omissions prevent verification that the gains are statistically meaningful and not artifacts of a narrow operating point.
minor comments (1)
- The abstract would benefit from a brief statement of the state and action spaces used by the NAF agent and the precise reward formulation that incorporates RLNC decoding success.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract claims. We address each point below, indicating revisions where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that NAF 'closely matches exhaustive search' is load-bearing for the assertion of near-optimal policies, yet the manuscript itself notes that continuous PA optimization is computationally prohibitive in dense indoor settings with multiple users and RLNC interactions. The paper must state the exact user counts at which exhaustive search was feasible and show that the performance gap to NAF remains negligible in the higher-density regime where exhaustive search cannot be run.
Authors: We will revise the abstract and Section V to state that exhaustive search was feasible and run for 2-4 users, where the NAF-exhaustive gap is below 1%. For higher densities (6+ users), exhaustive search is intractable as noted in the paper; we cannot directly show the gap there. We will add discussion of scalability trends and consistent NAF advantages over DDPG/GRPA in those regimes to support the claim indirectly. revision: partial
-
Referee: [Abstract] Abstract: the 4.6% sum-rate gain over GRPA and 39% speed-up versus DDPG are presented without any description of simulation parameters, number of users, modeling of location-estimation errors, number of Monte-Carlo runs, or error bars. These omissions prevent verification that the gains are statistically meaningful and not artifacts of a narrow operating point.
Authors: We agree the abstract should reference key parameters for verifiability. These details appear in Section IV (8 users, Gaussian location errors with 0.2 m std. dev., 500 Monte-Carlo runs, error bars as one std. dev.). We will revise the abstract to briefly include 'for 8 users with location errors' and ensure figures' error bars are cross-referenced. revision: yes
- Direct demonstration of the NAF-exhaustive performance gap in high-density regimes, since exhaustive search cannot be executed there.
Circularity Check
No circularity: empirical simulation validation of DRL algorithm
full rationale
The paper proposes a DRL-based NAF algorithm for power allocation in a LiDAL-assisted RLNC-NOMA system and reports performance via direct simulation comparisons to DDPG, GRPA, and exhaustive search. No equations, derivations, or analytical predictions are visible that reduce to fitted parameters, self-citations, or input data by construction. The reported gains (e.g., 4.6% over GRPA) arise from empirical runs rather than any self-definitional or load-bearing analytical step. The derivation chain is therefore self-contained as an algorithmic proposal validated externally by simulation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Imperfect channel state information and residual decoding errors deteriorate NOMA performance in dense indoor scenarios
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A DRL-based normalized advantage function (NAF) algorithm is proposed to maximize the average sum rate... NAF closely matches exhaustive search, is 39% faster than DDPG
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
optimizing continuous PA dynamically can be computationally prohibitive
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Visible Light Commu- nication, Networking, and Sensing: A Survey, Potential and Challenges,
P. H. Pathak, X. Feng, P. Hu, and P. Mohapatra, “Visible Light Commu- nication, Networking, and Sensing: A Survey, Potential and Challenges,” IEEE Communications Surveys & Tutorials, vol. 17, no. 4, pp. 2047– 2077, 2015
work page 2047
-
[2]
Bia transmission in rate splitting-based optical wireless networks,
A. A. Qidan, K. Alazwary, T. El-Gorashi, M. Safari, H. Haas, R. V . Penty, I. H. White, and J. M. H. Elmirghani, “Bia transmission in rate splitting-based optical wireless networks,”IEEE Transactions on Communications, pp. 1–1, 2025
work page 2025
-
[3]
Multiple Access Design for Ultra-Dense VLC Networks: Orthogonal vs Non-Orthogonal,
S. Feng, R. Zhang, W. Xu, and L. Hanzo, “Multiple Access Design for Ultra-Dense VLC Networks: Orthogonal vs Non-Orthogonal,”IEEE Transactions on Communications, vol. 67, no. 3, pp. 2218–2232, Mar. 2019
work page 2019
-
[4]
A Survey of Rate-Optimal Power Domain NOMA With Enabling Technologies of Future Wireless Networks,
O. Maraqa, A. S. Rajasekaran, S. Al-Ahmadi, H. Yanikomeroglu, and S. M. Sait, “A Survey of Rate-Optimal Power Domain NOMA With Enabling Technologies of Future Wireless Networks,”IEEE Communi- cations Surveys Tutorials, vol. 22, no. 4, pp. 2192–2235, 2020. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11
work page 2020
-
[5]
Dynamic power allocation for noma-based transmission in 6g optical wireless networks,
A. A. Qidan, T. El-Gorashi, M. Safari, H. Haas, R. V . Penty, I. H. White, and J. M. H. Elmirghani, “Dynamic power allocation for noma-based transmission in 6g optical wireless networks,” 2025
work page 2025
-
[6]
Location- Based MIMO-NOMA: Multiple Access Regions and Low-Complexity User Pairing,
J. Wang, Y . Li, C. Ji, Q. Sun, S. Jin, and T. Q. S. Quek, “Location- Based MIMO-NOMA: Multiple Access Regions and Low-Complexity User Pairing,”IEEE Transactions on Communications, vol. 68, no. 4, pp. 2293–2307, Apr. 2020
work page 2020
-
[7]
Load balancing in hybrid vlc and rf networks based on blind interference alignment,
A. A. Qidan, M. Morales-Cespedes, and A. Garcia-Armad, “Load balancing in hybrid vlc and rf networks based on blind interference alignment,”IEEE Access, vol. 8, pp. 72 512–72 527, 2020
work page 2020
-
[8]
User- centric blind interference alignment design for visible light communi- cations,
A. A. Qidan, M. Morales-Cespedes, and A. Garcia-Armada, “User- centric blind interference alignment design for visible light communi- cations,”IEEE Access, vol. 7, pp. 21 220–21 234, 2019
work page 2019
-
[9]
Performance Evaluation of Short Packet Communications in NOMA VLC Systems With Imperfect CSI,
G. N. Tran and S. Kim, “Performance Evaluation of Short Packet Communications in NOMA VLC Systems With Imperfect CSI,”IEEE Access, vol. 10, pp. 49 781–49 793, 2022
work page 2022
-
[10]
LiDAL: Light Detection and Localization,
A. A. Al-Hameed, S. H. Younus, A. T. Hussein, M. T. Alresheed, and J. M. H. Elmirghani, “LiDAL: Light Detection and Localization,”IEEE Access, vol. 7, pp. 85 645–85 687, 2019
work page 2019
-
[11]
LiDAL- Assisted RLNC-NOMA in OWC Systems,
A. A. Hassan, A. A. Qidan, T. Elgorashi, and J. Elmirghani, “LiDAL- Assisted RLNC-NOMA in OWC Systems,” Apr. 2025
work page 2025
-
[12]
A. A. Hassan, A. Adnan Qidan, T. Elgorashi, and J. Elmirghani, “Random Linear Network Coding for Non-Orthogonal Multiple Access in Multicast Optical Wireless Systems,” in2023 23rd International Conference on Transparent Optical Networks (ICTON), Jul. 2023, pp. 1–5
work page 2023
-
[13]
Non-orthogonal multiple access (NOMA) for indoor visible light communications,
R. C. Kizilirmak, C. R. Rowell, and M. Uysal, “Non-orthogonal multiple access (NOMA) for indoor visible light communications,” in2015 4th International Workshop on Optical Wireless Communications (IWOW). Istanbul, Turkey: IEEE, Sep. 2015, pp. 98–101
work page 2015
-
[14]
Non-Orthogonal Multiple Access for Visible Light Communications,
H. Marshoud, V . M. Kapinas, G. K. Karagiannidis, and S. Muhaidat, “Non-Orthogonal Multiple Access for Visible Light Communications,” IEEE Photonics Technology Letters, vol. 28, no. 1, pp. 51–54, Jan. 2016
work page 2016
-
[15]
On the performance of non-orthogonal multiple access in visible light communication,
L. Yin, X. Wu, and H. Haas, “On the performance of non-orthogonal multiple access in visible light communication,” in2015 IEEE 26th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Aug. 2015, pp. 1354–1359
work page 2015
-
[16]
On the Performance of MIMO-NOMA-Based Visible Light Communication Systems,
C. Chen, W.-D. Zhong, H. Yang, and P. Du, “On the Performance of MIMO-NOMA-Based Visible Light Communication Systems,”IEEE Photonics Technology Letters, vol. 30, no. 4, pp. 307–310, Feb. 2018
work page 2018
-
[17]
H. Shen, Y . Wu, W. Xu, and C. Zhao, “Optimal power allocation for downlink two-user non-orthogonal multiple access in visible light communication,”Journal of Communications and Information Networks, vol. 2, no. 4, pp. 57–64, Dec. 2017
work page 2017
-
[18]
Fair Non-Orthogonal Multiple Access for Visible Light Communication Downlinks,
Z. Yang, W. Xu, and Y . Li, “Fair Non-Orthogonal Multiple Access for Visible Light Communication Downlinks,”IEEE Wireless Communica- tions Letters, vol. 6, no. 1, pp. 66–69, Feb. 2017
work page 2017
-
[19]
On the Achievable Max-Min User Rates in Multi-Carrier Centralized NOMA- VLC Networks,
O. Maraqa, U. F. Siddiqi, S. Al-Ahmadi, and S. M. Sait, “On the Achievable Max-Min User Rates in Multi-Carrier Centralized NOMA- VLC Networks,”Sensors, vol. 21, no. 11, p. 3705, Jan. 2021
work page 2021
-
[20]
Artificial neural network for resource allocation in laser-based optical wireless networks,
A. A. Qidan, T. El-Gorashi, and J. M. H. Elmirghani, “Artificial neural network for resource allocation in laser-based optical wireless networks,” inICC 2022 - IEEE International Conference on Communications, 2022, pp. 3009–3015
work page 2022
-
[21]
Cooperative artifi- cial neural networks for rate-maximization in optical wireless networks,
A. A. Qidan, T. El-Gorashi, and J. M. H. Elmirghani, “Cooperative artifi- cial neural networks for rate-maximization in optical wireless networks,” inICC 2023 - IEEE International Conference on Communications, 2023, pp. 1143–1148
work page 2023
-
[22]
Subcarrier and Power Al- location in OFDM-NOMA VLC Systems,
G. Wang, Y . Shao, L.-K. Chen, and J. Zhao, “Subcarrier and Power Al- location in OFDM-NOMA VLC Systems,”IEEE Photonics Technology Letters, vol. 33, no. 4, pp. 189–192, Feb. 2021
work page 2021
-
[23]
R. S. Sutton and A. G. Barto,Reinforcement learning: an introduction, second edition ed., ser. Adaptive computation and machine learning series. Cambridge, Massachusetts: The MIT Press, 2018
work page 2018
-
[24]
M. Gaballa, M. Abbod, and A. Aldallal, “A Study on the Impact of Integrating Reinforcement Learning for Channel Prediction and Power Allocation Scheme in MISO-NOMA System,”Sensors, vol. 23, no. 3, p. 1383, Jan. 2023
work page 2023
-
[25]
Resource Allocation for Low-Latency NOMA-V2X Networks Using Reinforcement Learning,
H. Ding and K.-C. Leung, “Resource Allocation for Low-Latency NOMA-V2X Networks Using Reinforcement Learning,” inIEEE IN- FOCOM 2021 - IEEE Conference on Computer Communications Work- shops (INFOCOM WKSHPS), May 2021, pp. 1–6
work page 2021
-
[26]
A Dynamic Power Allocation Scheme in Power-Domain NOMA using Actor-Critic Reinforcement Learning,
S. Zhang, L. Li, J. Yin, W. Liang, X. Li, W. Chen, and Z. Han, “A Dynamic Power Allocation Scheme in Power-Domain NOMA using Actor-Critic Reinforcement Learning,” in2018 IEEE/CIC International Conference on Communications in China (ICCC), Aug. 2018, pp. 719– 723
work page 2018
-
[27]
A NOMA- Based Q-Learning Random Access Method for Machine Type Commu- nications,
M. V . da Silva, R. D. Souza, H. Alves, and T. Abr ˜ao, “A NOMA- Based Q-Learning Random Access Method for Machine Type Commu- nications,”IEEE Wireless Communications Letters, vol. 9, no. 10, pp. 1720–1724, Oct. 2020
work page 2020
-
[28]
Q-learning algorithm for resource allocation in WDMA-based optical wireless communication networks,
A. S. Elgamal, O. Z. Aletri, A. A. Qidan, T. E. El-Gorashi, and J. M. H. Elmirghani, “Q-learning algorithm for resource allocation in WDMA-based optical wireless communication networks,” in2021 6th International Conference on Smart and Sustainable Technologies (SpliTech), Sep. 2021, pp. 1–5
work page 2021
-
[29]
Q-Learning for Sum-Throughput Optimization in Wireless Visible-Light UA V Networks,
Y . Long and N. Cen, “Q-Learning for Sum-Throughput Optimization in Wireless Visible-Light UA V Networks,” inIEEE INFOCOM 2023 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). Hoboken, NJ, USA: IEEE, May 2023, pp. 1–6
work page 2023
-
[30]
Continuous control with deep reinforcement learning,
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” Jul. 2019
work page 2019
-
[31]
Continuous Deep Q- Learning with Model-based Acceleration,
S. Gu, T. Lillicrap, I. Sutskever, and S. Levine, “Continuous Deep Q- Learning with Model-based Acceleration,” Mar. 2016
work page 2016
-
[32]
Dis- tributed Multi-Cell Power Control with NAF Reinforcement Learning,
Y . Sun, M. Chen, J. Zhao, H. Sun, Y . Pan, and Y . Cang, “Dis- tributed Multi-Cell Power Control with NAF Reinforcement Learning,” in2023 International Wireless Communications and Mobile Computing (IWCMC), Jun. 2023, pp. 1550–1555
work page 2023
-
[33]
Robust Power Allocation for Integrated Visible Light Positioning and Communication Networks,
S. Ma, R. Yang, C. Du, H. Li, Y . Wu, N. Al-Dhahir, and S. Li, “Robust Power Allocation for Integrated Visible Light Positioning and Communication Networks,”IEEE Transactions on Communications, vol. 71, no. 8, pp. 4764–4777, Aug. 2023
work page 2023
-
[34]
Tight Bounds on Channel Capacity for Dimmable Visible Light Communications,
J.-B. Wang, Q.-S. Hu, J. Wang, M. Chen, and J.-Y . Wang, “Tight Bounds on Channel Capacity for Dimmable Visible Light Communications,” Journal of Lightwave Technology, vol. 31, no. 23, pp. 3771–3779, Dec. 2013
work page 2013
-
[35]
A. A. Qidan, M. Morales-Cespedes, A. Garcia-Armad, and J. M. H.Elmirghani, “Resource allocation in user-centric optical wireless cellular networks based on blind interference alignment,”Journal of Lightwave Technology, vol. 39, no. 21, pp. 6695–6711, 2021
work page 2021
-
[36]
Adaptive Power Allocation Scheme for Mobile NOMA Visible Light Communication System,
Z. Dong, T. Shang, Q. Li, and T. Tang, “Adaptive Power Allocation Scheme for Mobile NOMA Visible Light Communication System,” Electronics, vol. 8, no. 4, p. 381, Mar. 2019
work page 2019
-
[37]
Deep Q-Learning-Based Resource Allocation in NOMA Visible Light Communications,
A. A. hammadi, L. Bariah, S. Muhaidat, M. Al-Qutayri, P. C. Sofo- tasios, and M. Debbah, “Deep Q-Learning-Based Resource Allocation in NOMA Visible Light Communications,”IEEE Open Journal of the Communications Society, vol. 3, pp. 2284–2297, 2022
work page 2022
-
[38]
S. Tao, H. Yu, Q. Li, and Y . Tang, “Performance analysis of gain ratio power allocation strategies for non-orthogonal multiple access in indoor visible light communication networks,”EURASIP Journal on Wireless Communications and Networking, vol. 2018, no. 1, p. 154, Dec. 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.