Group Permutation Testing in Linear Model: Sharp Validity, Power Improvement, and Extension Beyond Exchangeability
Pith reviewed 2026-05-16 11:36 UTC · model grok-4.3
The pith
A grouped permutation test for linear regression coefficients controls Type I error at most 2α under exchangeable errors, with the factor proven sharp.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the model Y = Zβ + bX + ε the grouped version of PALMRT controls the Type I error probability at most 2α whenever the errors are exchangeable; the bound is attained in a worst-case construction. The Type II error is bounded via a geometric separation quantity that is minimized by choosing an appropriate permutation group; a constructive algorithm produces groups that are at least as powerful as i.i.d. permutations. The method is further extended to non-exchangeable errors by producing weighted group tests whose finite-sample Type I error is controlled by a weighted average of total variation distances between ε and its permuted versions, recovering exact validity when those distances are
What carries the argument
the group permutation framework that structures randomization tests around arbitrary permutation groups acting on the error vector, allowing unified analysis of validity, power, and robustness
If this is right
- Type I error remains at most 2α for every choice of permutation group when errors are exchangeable.
- The factor 2 is attained by an explicit worst-case construction, so the bound cannot be improved without further assumptions.
- Type II error is governed by a geometric separation that can be minimized by solving a combinatorial optimization over groups.
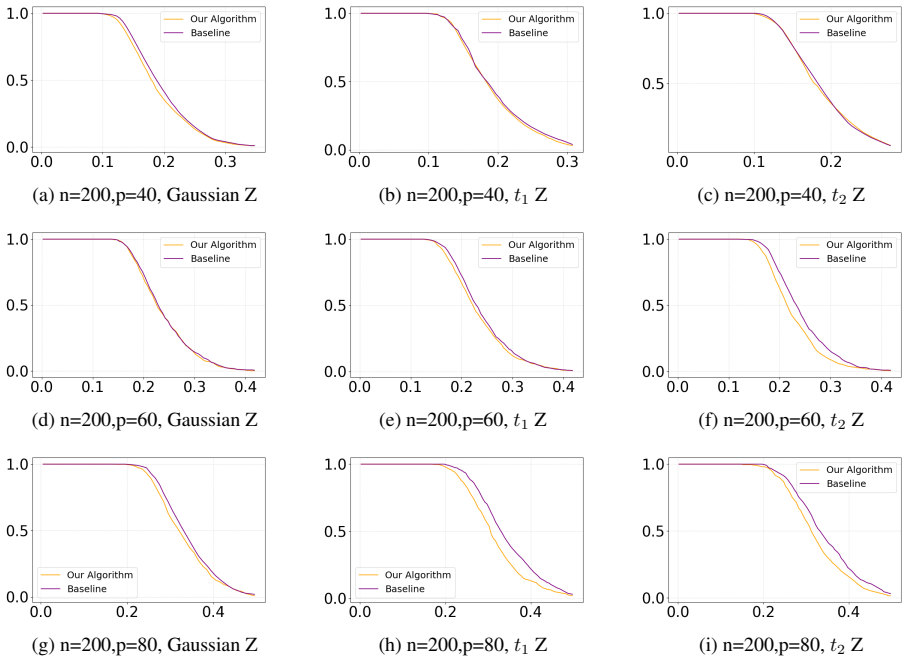
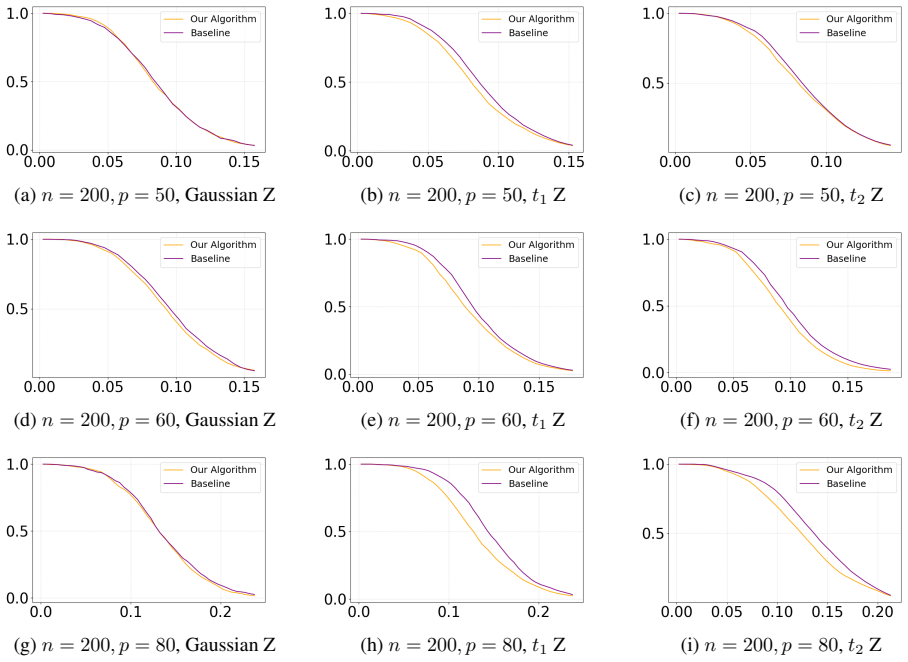
- A constructive algorithm selects permutation groups that yield power at least as high as i.i.d. permutations and often substantially higher under heavy-tailed designs.
- Weighted group tests control Type I error by a weighted average of total variation distances, recovering exact validity when the distances vanish.
Where Pith is reading between the lines
- The sharpness result implies that any practical implementation may need to target a smaller nominal α to guarantee a desired level.
- The link to conformal inference suggests that similar weighted-group constructions could add robustness to other permutation-based procedures.
- Design-dependent group optimization opens the possibility of adaptive testing rules that choose the group after seeing the design matrix.
Load-bearing premise
Errors must be exchangeable under the null to obtain the sharp Type I error bound of 2α.
What would settle it
A concrete permutation group G together with an exchangeable error distribution ε such that, for some design matrices and nominal level α, the rejection probability under the null exceeds 2α would falsify the validity claim.
Figures

read the original abstract
We consider finite-sample inference for a single regression coefficient in the fixed-design linear model $Y = Z\beta + bX + \varepsilon$, where $\varepsilon\in\mathbb{R}^n$ may exhibit complex dependence or heterogeneity. We develop a group permutation framework, yielding a unified and analyzable randomization structure for linear-model testing. Under exchangeable errors, we place permutation-augmented regression tests within this group-theoretic setting and show that a grouped version of PALMRT controls Type I error at level at most $2\alpha$ for any permutation group; moreover, we provide an worst-case construction demonstrating that the factor $2$ is sharp and cannot be improved without additional assumptions. Second, we relate the Type II error to a design-dependent geometric separation. We formulate it as a combinatorial optimization problem over permutation groups and bound it under additional mild sub-Gaussian assumptions. For the Type II error upper bound control, we propose a constructive algorithm for the permutation strategy that is better (at least no worse) than the i.i.d. permutation, with simulations empirically indicating substantial power gains, especially under heavy-tailed designs. Finally, we extend group-based CPT and PALMRT beyond exchangeability by connecting rank-based randomization arguments to conformal inference. The resulting weighted group tests satisfy finite-sample Type I error bounds that degrade gracefully with a weighted average of total variation distances between $\varepsilon$ and its group-permuted versions, recovering exact validity when these discrepancies vanish and yielding quantitative robustness otherwise. Taken together, the group-permutation viewpoint provides a principled bridge from exact randomization validity to design-adaptive power and quantitative robustness under approximate symmetries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a group permutation framework for finite-sample inference on a single regression coefficient in the fixed-design linear model Y = Zβ + bX + ε with possibly dependent errors. Under exchangeable errors, a grouped version of PALMRT is shown to control Type I error at level at most 2α for arbitrary permutation groups, with an explicit worst-case construction proving the factor of 2 is sharp. The Type II error is characterized geometrically as a combinatorial optimization over groups and bounded under sub-Gaussian tails; a constructive algorithm is proposed that improves (or at least matches) i.i.d. permutation power, with supporting simulations. The framework is extended beyond exact exchangeability via weighted group tests linked to conformal inference, yielding finite-sample Type I bounds that degrade continuously with total-variation distances to the permuted errors.
Significance. If the central claims hold, the work supplies a unified randomization-based approach that delivers sharp finite-sample validity, design-adaptive power gains, and quantitative robustness under approximate symmetries. The explicit sharpness construction and the algorithmic permutation strategy are particular strengths, as they convert abstract group-theoretic arguments into concrete, verifiable procedures without parameter tuning. The graceful degradation via total-variation bounds further bridges exact permutation tests to practical settings with mild dependence violations, potentially influencing methodology in causal inference and high-dimensional regression where exact control is valued.
major comments (2)
- [Theorem 3.1] Theorem 3.1 (sharpness construction): the explicit worst-case error vector and design that attain exactly 2α are stated to satisfy exchangeability and the linear-model null; the manuscript should verify that this construction remains valid when the permutation group is a proper subgroup rather than the full symmetric group, as the bound is claimed for arbitrary groups.
- [§4.2] §4.2, Algorithm 1: the claim that the proposed permutation strategy is at least as powerful as i.i.d. permutation rests on a combinatorial separation argument; a formal proof that the algorithm never decreases power (rather than only empirical evidence) is needed, because the Type-II improvement is presented as a core contribution.
minor comments (3)
- [§2] Notation for the action of the permutation group on the design matrix (introduced in §2) is used before being fully defined; a short clarifying paragraph or diagram would improve readability.
- [Simulations] Simulation section: the number of Monte Carlo replications, exact design parameters, and heavy-tail distributions should be reported in a table to allow direct reproduction of the reported power gains.
- [§5] The total-variation extension in §5 recovers exact validity when discrepancies vanish, but the manuscript does not discuss how the weights are chosen in practice when the TV distances are estimated from data.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We have addressed both major comments by adding clarifications and a formal proof in the revised manuscript.
read point-by-point responses
-
Referee: [Theorem 3.1] Theorem 3.1 (sharpness construction): the explicit worst-case error vector and design that attain exactly 2α are stated to satisfy exchangeability and the linear-model null; the manuscript should verify that this construction remains valid when the permutation group is a proper subgroup rather than the full symmetric group, as the bound is claimed for arbitrary groups.
Authors: The worst-case construction in Theorem 3.1 is formulated to achieve the bound of 2α for any permutation group, including proper subgroups. The error vector is chosen so that under the null, the test statistic exceeds the threshold with probability exactly 2α regardless of the group structure, as long as the group is non-trivial. We have added a paragraph following the theorem statement verifying this for subgroups such as the cyclic group generated by a single cycle, confirming the sharpness holds universally as claimed. revision: yes
-
Referee: [§4.2] §4.2, Algorithm 1: the claim that the proposed permutation strategy is at least as powerful as i.i.d. permutation rests on a combinatorial separation argument; a formal proof that the algorithm never decreases power (rather than only empirical evidence) is needed, because the Type-II improvement is presented as a core contribution.
Authors: We appreciate this observation. While the manuscript presents the combinatorial separation argument, we agree a self-contained formal proof enhances clarity. In the revision, we have added Theorem 4.2, which proves that the algorithm's selected group yields Type II error no larger than that of the full symmetric group (i.i.d. permutations). The proof proceeds by showing that the optimization includes the i.i.d. case as a feasible solution and selects at least as good a separator. The simulations are kept to demonstrate practical gains. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper establishes the grouped PALMRT Type I error bound of at most 2α directly from the group-theoretic randomization structure under exchangeable errors, with sharpness shown via an explicit worst-case construction that satisfies the linear model and exchangeability conditions without any reduction to fitted parameters or self-referential definitions. The Type II error is posed as a combinatorial optimization over permutation groups and bounded using sub-Gaussian tail assumptions on the design-dependent separation, yielding a constructive algorithm that improves on i.i.d. permutations. The extension to approximate exchangeability connects rank-based arguments to conformal inference via weighted total variation distances, recovering exact validity when discrepancies vanish. All steps rely on external combinatorial and geometric arguments rather than self-citations that bear the central load or ansatzes imported from prior author work; no equations reduce by construction to their inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Errors are exchangeable under the null hypothesis
- domain assumption Errors satisfy mild sub-Gaussian tail conditions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a group permutation framework... P_K satisfies that for any P_i, P_j there exists k such that P_k = P_i P_j (Assumption 2).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
P(ϕ ≤ α) ≤ 2α ... worst-case construction demonstrating that the factor 2 is sharp
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Partial Identification under High-Dimensional Potential Outcomes and Confounders via Optimal Transport
A subspace-decomposed optimal transport estimator using sliced Wasserstein distance on residuals to tighten partial identification bounds in high dimensions.
Reference graph
Works this paper leans on
-
[1]
2.I∈ P K, and for anyP k ∈ P K,P T k ∈ P K
For fixedP k ∈ {P0,· · ·, P K},P πk is a bijection. 2.I∈ P K, and for anyP k ∈ P K,P T k ∈ P K. Proof: From the definition, we know that for fixed k,P πk :P K 7→ P K. Then for anyj∈ {0,· · ·, K}, P πk(πj) =P jPk. SinceP k, Pj ∈ P K, by the Assumption 2,P πk(πj) =P jPk ∈ P K,P πk is injective. For anyi, j∈ {0,· · ·, K}andi̸=j, ifP πk(πi) =P πk(πj), thenP i...
-
[2]
= 1, so that the bound2αin Theorem 2 is tight bound. A.2 Proof of Theorem 9 Proof.Initailly, we recap the lemmas about quantiles. From the defintion ofR i, i= 0,· · ·, K, and the Assumption ofP K andϵ, it is easy to see that R0 d=R 1 d=· · · d=R K. 33 Recall that the quantile function ˆQ1−α of random variablesR0,· · ·, R K is the quantile function with re...
work page 2025
-
[3]
On the other hand, X T H ZZπ X+X T π (I−H ZZπ )X≤ 1 2 ∥(I−H Z)X∥2 2 +∥H ZX∥2 2 + n n−C(p+tr(P πk)) − C(p+tr(P π)) 2n−2C(p+tr(P πk)) vT πk v ≤ ∥H ZX∥2 2 + n n−C(p+tr(P πk)) 1 2 vT πk v+∥H Zπk v∥2 2 + n 2n−2C(p+tr(P πk)) ∥v∥2 2 , where the last inequality is becausevT πk v≥ −∥v∥ 2
-
[4]
Now, suppose that|{π k|tr(Pπk)≤m}| ≥(1− 1 8 α)(1+ K)for somem≤o(n). LetK ′ ={k|tr(P πk)≤m, 1 2 vT πk v+∥H Zπk v∥2 2 ≤λ 2(X, Z,P K, 1 4 α)} Then|K ′ | ≥(1− 1 4 α)(1 +K)− 1 8 α(1 +K) = (1− 3 8 α)(1 +K). On the other hand, by Theorem 3, for anyk∈ K ′ , X T H ZZπk X+X T πk(I−H ZZπ k)X≤ n n−C(p+m) λ2(X, Z,P K, 1 2 α) +∥H ZX∥2 2 + n 2n−2C(p+m) ∥v∥2 2 38 holds w...
-
[5]
Also, suppose these vectors satisfy the following conditions: (1):E(v i) = 0
=t i and letSbe any parameter such thatS≥ Pm i=1 ti. Also, suppose these vectors satisfy the following conditions: (1):E(v i) = 0. (2):∥v i∥2 ≤a, witha 2 ≤ S ln4 n. (3):∀w∈ S n−1, we have:S w :=Pm i=1 E (vT i w)2 ≤ S ln4 n. Then we have: for anyc, k >0, there existsCsuch that P " ∥ mX i=1 vi∥2 2 ≥ mX i=1 ti +cS # ≤Cn −k. Following this, if we regardu ′ i ...
-
[6]
For eachS i, control| P j∈Si aj| ≤O( qPn i=1 a2 i )and|S i| ≥n 0.55 so thatE(|v T π v|)is near optimal andPk i=1 E(∥ui∥2 2)can be well approximated by an easier optimization problem of (48)
-
[7]
Control P j∈Si a2 j ∈o(Pn j=1 a2 j)for allS i, satisfying (3) in proposition 6, to guaranty a high proba- bility bound of∥H Zvπ∥2 2 ≤(1 +o(1))E(∥H Zvπ∥2
-
[8]
This is the key approach for removing the indicator function in (22)
= (1 +o(1))[∥v ∗∥2 2 +Pk i=1 E(∥ui∥2 2)]. This is the key approach for removing the indicator function in (22)
-
[9]
Given the above constraints and guarantee, optimize over (48). 40 Algorithm design for finding permutation groupNow we show how to find a valid solution of (48) given all the constraints mentioned above. For simplicity, denoteci =a 2 i , ¯b= 1 n Pn i=1 bi, and¯c= 1 n Pn i=1 ci, and we obtain: kX i=1 X j∈Si 1 |Si| a2 j X j∈Si wT j wj = kX i=1...
-
[10]
For each subsetS i,E[∥u i∥2 2]∈O( Pn i=j a2 j), and 1 |Si| P j∈Si a2 j is closed to 1 |J| P i∈J a2 i , so that E hPk i=1 ∥ui∥2 2 i can be controlled
-
[11]
Each|S i|is also not too small so that Lemma 13 holds. The core idea of Algorithm 5 is that, we construct a sequencei 1, i2, ..., im such that∥ Pl j=1(ai, bi)∥2 is small for alll, providing convenience to getting the partitionS i’s. 41 Algorithm 2Rearrange Input:(a 1, c1),(a 2, c2), ...,(a n, cn), 3 subsetsI 1, I2, I3 of{1,2, ..., n}and parameterM. LetS= ...
-
[12]
When the conditions in proposition 6 hold, and additionallymax i{(vi −¯v)2} ≤ 1 polyln(n) Pn i=1(vi − ¯v)2 for some polynomial, our algorithm has a solution withλin 22 provably not worse than uniformly sampling permutations
-
[13]
The provable gap in which our solution surpasses the random permutation is presented by |J2|(¯b2 − ¯b)(¯c2 −¯c) +|J3|(¯b3 − ¯b)(¯c3 −¯c) −o(1)∥v∥ 2 2, which depends on the exactX, Z. Now we explain how different distribution ofZas well asn, pinfluences the gap||J 2|(¯b2 − ¯b)(¯c2 −¯c) + |J3|(¯b3 − ¯b)(¯c3 −¯c)|ofλ 2 in (22). The impact ofpRecall the optim...
-
[14]
This will increase both of| ¯b2 − ¯b|and| ¯b3 − ¯b|. In particular, a heavy tail prevents the projectedL 2 norm of each standard basis from concentrating around its expectation, thereby allowing a larger performance gap. (a) n=200,p=40, Gaussian Z (b) n=200,p=40,t 1 Z (c) n=200,p=40,t 2 Z (d) n=200,p=50, Gaussian Z (e) n=200,p=50,t 1 Z (f) n=200,p=50,t 2 ...
-
[15]
+ sP i /∈Ix2 iPn i=1 x2 i sP i /∈Iy2 iPn i=1 y2 i # ≤12|T ϵ|−2e−p Now it suffices to bound∥Zu∥ 2
-
[16]
X i /∈I x2 i ≥t # ≤e 10c2(tr(Pπ)−t) . This leads to an upper bound ofP i /∈Ix2 i : P
We first consider allu∈ T ϵ. SinceE[e txi]≤e c2t2 for all t, by settingt= x 2c2 andt=− x 2c2 we obtain: P[|xi| ≥x]≤2e − x2 4c2 . 51 Therefore, whenλ < 1 4c2 , we can upper boundE[e λx2 i ]by E[eλx2 i ] = Z t≥0 P[eλx2 i ≥t]dt = 1 + Z t≥1 P[x2 i ≥ 1 λ lnt]dt ≤1 + Z t≥1 2e− 1 4c2λ lnt dt ≤1 + Z t≥1 2t− 1 4c2λ dt . = 1 + 2 1 4c2λ −1 = 1 + 8c2λ 1−4c 2λ . Letλ=...
-
[17]
This implies 1 2 X T π (I−H Zπ)(I−H Z)−X T π (I−H ZZπ)X ≤ 1 2 ∥(I−H Z)X∥2 2 . 54 B.2.3 Formal version of Theorem 5 We provide Theorem 16, the formal version of Theorem 5 and complete its proof here. Theorem 16.For anyα∈(0, 1 2]andP K,λ 2(X, Z,P K, α)satisfies λ2(X, Z,P K, α)≥E 1 2 vT πk v+∥H Zvπk ∥2 2 −2α∥v∥ 2 2 . Furthermore, supposeπ i(i= 1,2, ..., m)is...
-
[18]
Therefore, we obtain: E 1 2 vT πk v+∥H Zπk v∥2 2 ≤λ 2(X, Z,P K, α)·(1−α) +α·(2∥v∥ 2 2 +λ 2(X, Z,P K, α)) ≤λ 2(X, Z,P K, α) + 2α∥v∥2 2 . Whenπ i is sampled uniformly randomly fromP K, we have: P 1 2 vT πiv+∥H Zπi v∥2 2 <E πk 1 2 vT πk v+∥H Zvπk ∥2 2 −α∥v∥ 2 2 ≤1− 1 2 α , which is becauseλ 2(X, Z,P K, 1 2 α)≥E πk 1 2 vT πk v+∥H Zvπk ∥2 2 −α∥v∥ 2 2. Now we l...
-
[19]
Lemma 17.Suppose that condition (1),(2),(3) are satisfied
ThenY i+1 =Y i + 2XT i vi+1 We first give a lemma that provides an upper bound onX i. Lemma 17.Suppose that condition (1),(2),(3) are satisfied. Then, for anyw∈ S n−1, we have: P " sup i |X T i w| ≤max r 4Sw ln 2 δ ,2aln 2 δ !# ≥1−δ Proof of Lemma 17Letx i =v T i w, with|x i| ≤aandE(x i) = 0. ConsiderE(e λxi), we show that for all |λ| ≤ 1 a, we have:E(e λ...
-
[20]
+λ 2E[∥vi+1∥4 2] ≤x i(1 +λt i+1 +λ 2a2ti+1) ≤x ieλti+1+λ2a2ti+1 . Sincex 1, we obtainE[x m]≤e λ Pm i=1 ti(1+a2λ), therefore P " mX i=1 ∥vi∥2 2 ≥ mX i=1 ti + 1 2 cS # ≤e (− 1 2 c+a2λ)λS By settingλ= min( c 4a2 , ln1.25 n S ), we obtain P " mX i=1 ∥vi∥2 2 ≥ mX i=1 ti + 1 2 cS # ≤e −min( c2S 4a2 , 1 4 ln1.25 n) Combining with the upper bound ofY i we finally...
-
[21]
∥v∗∥2 2 + kX i=1 E[∥ui∥2 2] # −E[∥H Zvπ∥2 2] ≤o(1)
Therefore, the conditions in Theorem 12 hold. Now it remains to upper bound2< v ∗ +Pk i=1 E(ui),Pk i=1[ui −E(u i)]>. Letw ∗ =v ∗ +Pk i=1 E(ui), and letr i = (w ∗)T (ui −E(u i)), we have:E(r i) = 0,|r i| ≤ qP j∈Si(vj − 1 |Si| P l∈Si vl)2∥w∗∥2 ≤ qP j∈Si(vj −¯v)2∥w∗∥2,Pk i=1 E(r2 i )≤ ∥w ∗∥2 2 ·sup w∈S n−1 Sw ≤ 1 ln4 n ∥w∗∥2 2 Pn i=1(vi −¯v)2. Now, we show t...
-
[22]
We next show that for anyS i ⊆I ′ s(s=1,2,3),|S i| ≥Ω(n 0.55)
Furthermore, letj 1 ≤ibe the largest integer such that∥ Pj1 j=1(ai, bi)∥2 2 ≥Pk i=1(a2 i +b2 i ) and∥ Pj1−1 j=1 (ai, bi)∥2 2 <Pk i=1(a2 i +b 2 i ), we obtain: ∥ iX j=1 (ai, bi)∥2 ≤ ∥ iX j=j1 (ai, bi)∥2 ≤ ∥ iX j=j1−1 (ai, bi)∥2 +∥(a j1, bj1)∥2 ≤2 vuut kX i=1 (a2 i +b 2 i ). We next show that for anyS i ⊆I ′ s(s=1,2,3),|S i| ≥Ω(n 0.55). By Lemma 19, we can ...
-
[23]
This implies that λ2(X, Z,P K, 1 4 α)−λ 2(X, Z,P n, 1 2 α) ≤ |J2|(¯b2 − ¯b)(¯c2 −¯c) +|J3|(¯b3 − ¯b)(¯c3 −¯c) +O(α)∥v∥2 2 . Extension to estimation by finite samplesActually, bothP K and the set of all permutations contain too many permutations, so thatλ 2(X, Z,P n, 1 4 α)andλ 2(X, Z,P K, 1 4 α)cannot be directly computed. There- fore, we consider estimat...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.