Syncopate: Efficient Multi-GPU AI Kernels via Automatic Chunk-Centric Compute-Communication Overlap
Pith reviewed 2026-05-16 10:03 UTC · model grok-4.3
The pith
Syncopate overlaps compute and communication at chunk granularity inside a single fused kernel for multi-GPU AI workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a local Triton kernel and a chunk schedule, Syncopate performs automatic transformations that fuse operations and overlap communication at chunk boundaries inside one kernel, decoupling the communication plan from kernel structure and backend details.
What carries the argument
The communication chunk abstraction that decouples communication granularity from kernel structure, allowing plans to be supplied from compilers, users, or templates and then aligned with computation.
If this is right
- Fewer kernel launches and device-wide synchronizations at boundaries.
- Chunk plans become portable across kernels without rewriting communication code.
- Slack from the slowest tile or kernel is reduced because overlap happens at finer scale.
- Average end-to-end speedup of 1.3x and up to 4.7x on multi-GPU workloads.
Where Pith is reading between the lines
- The same chunk abstraction could be adapted to other GPU languages if the transformation engine is reimplemented.
- Automatic generation of chunk schedules might further reduce the need for manual input.
- Benefits are likely to grow with larger models where the ratio of communication to compute increases.
Load-bearing premise
Chunk schedules can be supplied without introducing correctness errors or excessive transformation overhead while the resulting fused kernel preserves original semantics on real hardware.
What would settle it
Execute the transformed fused kernel alongside the original version on multi-GPU hardware and check whether outputs match exactly while total runtime decreases due to better overlap.
Figures








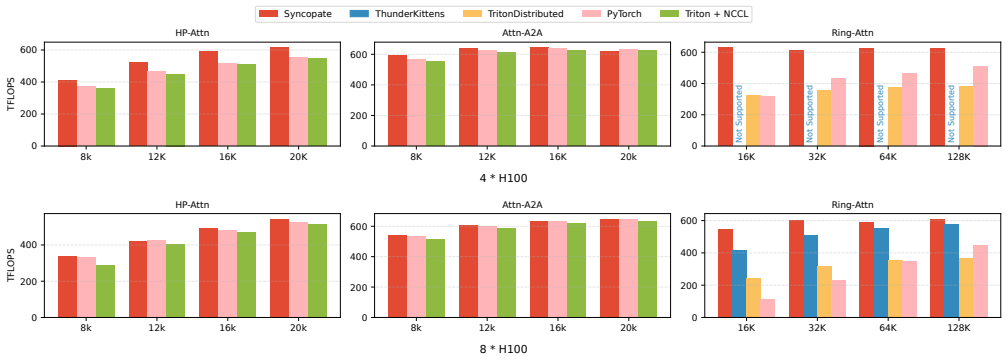


read the original abstract
Communication has become a first-order bottleneck in large-cale GPU workloads, and existing distributed compilers address it mainly by overlapping whole compute and communication kernels at the stream level. This coarse granularity incurs extra kernel launches, forces device-wide synchronizations at kernel boundaries, and leaves substantial slack when the slowest tile or kernel stretches the communication tail. We present Syncopate, a compiler and runtime that enables automatic fine-grained overlap inside a single fused kernel. Syncopate introduces a communication chunk abstraction that decouples communication granularity from kernel structure and backend mechanisms, allowing chunk-level plans to be ported from existing distributed compilers, written directly by users, or instantiated from reusable templates. Given a local Triton kernel and a chunk schedule, Syncopate performs transformations to align computation with chunk availability. Implemented as a source-to-source compiler on Triton, Syncopate delivers an average end-to-end speedup of 1.3$\times$ and up to 4.7$\times$ on multi-GPU workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Syncopate, a source-to-source compiler and runtime built on Triton that enables automatic fine-grained compute-communication overlap inside a single fused kernel for multi-GPU AI workloads. It defines a communication chunk abstraction to decouple granularity from kernel structure, allowing chunk schedules to be supplied from compilers, users, or templates, then performs transformations to align computation with chunk availability. The central claim is an average end-to-end speedup of 1.3× and up to 4.7× on multi-GPU workloads compared to existing stream-level overlap approaches.
Significance. If the speedups are reproducible across diverse workloads with proper baselines, this work could meaningfully advance distributed compiler design by addressing communication slack at finer granularity than current kernel-boundary methods, reducing device-wide synchronizations and extra launches. The practical engineering focus on reusing existing chunk plans and Triton integration is a strength, though significance hinges on whether the chunk abstraction introduces hidden overheads or correctness risks on real hardware.
major comments (2)
- [Evaluation section (implied by performance claims)] The abstract and evaluation claims (1.3× average, 4.7× peak) lack any description of workloads, hardware configuration, baselines, number of runs, or error bars, making it impossible to assess whether the reported speedups are load-bearing or sensitive to specific conditions.
- [§3 (system design)] The central transformation relies on externally supplied chunk schedules preserving semantics; no formal argument or test is given showing that the fused kernel always matches the original multi-kernel behavior under chunk misalignment or varying tile sizes.
minor comments (2)
- [§2] Notation for chunk schedules and the source-to-source passes could be clarified with a small example in pseudocode to show input Triton kernel versus transformed output.
- [Evaluation] The paper should include a table comparing kernel launch counts and synchronization points before/after Syncopate to quantify the claimed reduction in overhead.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify clear gaps in the evaluation presentation and the rigor of the semantic claims in the system design. We respond to each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: The abstract and evaluation claims (1.3× average, 4.7× peak) lack any description of workloads, hardware configuration, baselines, number of runs, or error bars, making it impossible to assess whether the reported speedups are load-bearing or sensitive to specific conditions.
Authors: We agree that the current manuscript provides insufficient detail on the experimental methodology. In the revised version we will expand the evaluation section with explicit descriptions of the workloads (specific models, layer sizes, and input dimensions), hardware configurations (GPU models, counts, and interconnect), baselines (including stream-level overlap, NCCL, and other distributed kernels), the number of runs per measurement, and error bars or standard deviations. These additions will make the speedups reproducible and allow assessment of sensitivity to conditions. revision: yes
-
Referee: The central transformation relies on externally supplied chunk schedules preserving semantics; no formal argument or test is given showing that the fused kernel always matches the original multi-kernel behavior under chunk misalignment or varying tile sizes.
Authors: The design assumes chunk schedules are supplied by trusted sources (upstream compilers, users, or templates) that derive from the original kernel structure, thereby preserving semantics by construction. However, we acknowledge the manuscript lacks an explicit argument or dedicated tests for misalignment and tile-size variation. We will revise §3 to include a detailed informal explanation of how the alignment transformations maintain equivalence, and add empirical tests in the evaluation demonstrating behavioral matching under different tile sizes and controlled misalignment cases. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an engineering compiler system (source-to-source transformations on Triton) that fuses compute with externally supplied chunk schedules for fine-grained overlap. No equations, fitted parameters, predictions, or self-citation chains appear in the abstract or described mechanism. The central claims are empirical speedups from implementation, not a derivation that reduces to its own inputs by construction. The system is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Triton kernel semantics are preserved under the described chunk-aligned transformations
invented entities (1)
-
communication chunk
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Syncopate introduces a communication chunk abstraction that decouples communication granularity from kernel structure... Given a local Triton kernel and a chunk schedule, Syncopate performs transformations to align computation with chunk availability.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Partir: Composing spmd partitioning strategies for ma- chine learning
Sami Alabed, Daniel Belov, Bart Chrzaszcz, Juliana Franco, Dominik Grewe, Dougal Maclaurin, James Mol- loy, Tom Natan, Tamara Norman, Xiaoyue Pan, et al. Partir: Composing spmd partitioning strategies for ma- chine learning. In Proceedings of the 30th ACM Inter- national Conference on Architectural Support for Pro- gramming Languages and Operating Systems...
work page 2025
-
[2]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Des- maison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michae...
work page 2024
-
[3]
Flux: fast software-based communication overlap on gpus through kernel fusion
Li-Wen Chang, Wenlei Bao, Qi Hou, Chengquan Jiang, Ningxin Zheng, Yinmin Zhong, Xuanrun Zhang, Zuquan Song, Chengji Yao, Ziheng Jiang, et al. Flux: fast software-based communication overlap on gpus through kernel fusion. arXiv preprint arXiv:2406.06858, 2024
-
[4]
Chang Chen, Xiuhong Li, Qianchao Zhu, Jiangfei Duan, Peng Sun, Xingcheng Zhang, and Chao Yang. Cen- tauri: Enabling efficient scheduling for communication- computation overlap in large model training via commu- nication partitioning. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Sy...
work page 2024
-
[5]
{TVM}: An automated {End-to-End} optimizing compiler for deep learning
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In 13th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 18), pages 578–594, 2018
work page 2018
-
[6]
Learning to optimize tensor programs
Tianqi Chen, Lianmin Zheng, Eddie Yan, Ziheng Jiang, Thierry Moreau, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. Learning to optimize tensor programs. In Proceedings of the 32nd International Conference on Neural Information Processing Systems , NIPS’18, page 3393–3404, Red Hook, NY , USA, 2018. Curran Associates Inc
work page 2018
-
[7]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Flashattention: Fast and memory- efficient exact attention with io-awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information processing systems , 35:16344– 16359, 2022
work page 2022
-
[9]
Tensorir: An abstraction for auto- matic tensorized program optimization
Siyuan Feng, Bohan Hou, Hongyi Jin, Wuwei Lin, Junru Shao, Ruihang Lai, Zihao Ye, Lianmin Zheng, Cody Hao Yu, Yong Yu, et al. Tensorir: An abstraction for auto- matic tensorized program optimization. In Proceedings of the 28th ACM International Conference on Architec- tural Support for Programming Languages and Operat- ing Systems, Volume 2, pages 804–817, 2023
work page 2023
-
[10]
Tokenweave: Efficient compute-communication overlap for distributed llm inference, 2025
Raja Gond, Nipun Kwatra, and Ramachandran Ramjee. Tokenweave: Efficient compute-communication overlap for distributed llm inference, 2025
work page 2025
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Loongtrain: Effi- cient training of long-sequence llms with head-context parallelism
Diandian Gu, Peng Sun, Qinghao Hu, Ting Huang, Xun Chen, Yingtong Xiong, Guoteng Wang, Qiaoling Chen, Shangchun Zhao, Jiarui Fang, et al. Loongtrain: Effi- cient training of long-sequence llms with head-context parallelism. arXiv preprint arXiv:2406.18485, 2024
-
[13]
Mercury: Unlocking multi- gpu operator optimization for llms via remote memory scheduling
Yue Guan, Xinwei Qiang, Zaifeng Pan, Daniels John- son, Yuanwei Fang, Keren Zhou, Yuke Wang, Wanlu Li, Yufei Ding, and Adnan Aziz. Mercury: Unlocking multi- gpu operator optimization for llms via remote memory scheduling. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 1046–1061, New York, NY , USA, 2025. As...
work page 2025
-
[14]
Flashoverlap: A lightweight design for efficiently overlapping communication and computation
Ke Hong, Xiuhong Li, Minxu Liu, Qiuli Mao, Tianqi Wu, Zixiao Huang, Lufang Chen, Zhong Wang, Yichong Zhang, Zhenhua Zhu, et al. Flashoverlap: A lightweight design for efficiently overlapping communication and computation. arXiv preprint arXiv:2504.19519, 2025. 13
-
[15]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajb- handari, and Yuxiong He. Deepspeed ulysses: Sys- tem optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sabet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkowicz, and Olli Saarikivi. Breaking the computation and commu- nication abstraction barrier in distributed machine learning workloads. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming L...
work page 2022
-
[17]
Reducing activation re- computation in large transformer models
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation re- computation in large transformer models. Proceedings of Machine Learning and Systems, 5:341–353, 2023
work page 2023
-
[18]
Ringat- tention with blockwise transformers for near-infinite context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ringat- tention with blockwise transformers for near-infinite context. In The Twelfth International Conference on Learning Representations
-
[19]
NVIDIA H100 Tensor Core GPU Architec- ture
NVIDIA. NVIDIA H100 Tensor Core GPU Architec- ture. Technical report, NVIDIA, mar 2022. White paper
work page 2022
-
[20]
NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) Rev 3.0.0, 2024
NVIDIA. NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) Rev 3.0.0, 2024. Ac- cessed: 2025-02-10
work page 2024
-
[21]
Nvidia nvlink high-speed inter- connect: Application performance
NVIDIA Corporation. Nvidia nvlink high-speed inter- connect: Application performance. Technical report, NVIDIA Corporation, 2015. Accessed: 2025-04-16
work page 2015
-
[22]
NVIDIA Collective Communica- tions Library (NCCL), 2025
NVIDIA Corporation. NVIDIA Collective Communica- tions Library (NCCL), 2025. Version 2.26.2
work page 2025
-
[23]
Openmp appli- cation programming interface
OpenMP Architecture Review Board. Openmp appli- cation programming interface. https://www.openmp. org/specifications/, 2023
work page 2023
-
[24]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Day- iheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Ke- qin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao...
work page 2025
-
[25]
Distir: An intermediate representation and simulator for efficient neural network distribution
Keshav Santhanam, Siddharth Krishna, Ryota Tomioka, Tim Harris, and Matei Zaharia. Distir: An intermediate representation and simulator for efficient neural network distribution. arXiv preprint arXiv:2111.05426, 2021
-
[26]
Flashattention- 3: Fast and accurate attention with asynchrony and low- precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention- 3: Fast and accurate attention with asynchrony and low- precision. Advances in Neural Information Processing Systems, 37:68658–68685, 2024
work page 2024
-
[27]
Tensor program opti- mization with probabilistic programs
Junru Shao, Xiyou Zhou, Siyuan Feng, Bohan Hou, Rui- hang Lai, Hongyi Jin, Wuwei Lin, Masahiro Masuda, Cody Hao Yu, and Tianqi Chen. Tensor program opti- mization with probabilistic programs. Advances in Neu- ral Information Processing Systems, 35:35783–35796, 2022
work page 2022
-
[28]
Mesh- tensorflow: Deep learning for supercomputers, 2018
Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, Ryan Sepassi, and Blake Hechtman. Mesh- tensorflow: Deep learning for supercomputers, 2018
work page 2018
-
[29]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism. arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[30]
Spector, Simran Arora, Aaryan Singhal, Daniel Y
Benjamin F. Spector, Simran Arora, Aaryan Singhal, Daniel Y . Fu, and Christopher Ré. Thunderkittens: Sim- ple, fast, and adorable ai kernels, 2024
work page 2024
-
[31]
Stuart H. Sul, Simran Arora, Benjamin F. Spector, and Christopher Ré. Parallelkittens: Systematic and practical simplification of multi-gpu ai kernels, 2025
work page 2025
-
[32]
Philippe Tillet, H. T. Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL 2019, page 10–19, New York, NY , USA, 2019. Association for Computing Machinery
work page 2019
-
[33]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[34]
Domino: Eliminating commu- nication in llm training via generic tensor slicing and overlapping, 2024
Guanhua Wang, Chengming Zhang, Zheyu Shen, Ang Li, and Olatunji Ruwase. Domino: Eliminating commu- nication in llm training via generic tensor slicing and overlapping, 2024. 14
work page 2024
-
[35]
Primepar: Efficient spatial- temporal tensor partitioning for large transformer model training
Haoran Wang, Lei Wang, Haobo Xu, Ying Wang, Yum- ing Li, and Yinhe Han. Primepar: Efficient spatial- temporal tensor partitioning for large transformer model training. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS ’24, page 801–817, New York, NY , USA, 202...
work page 2024
-
[36]
Overlap communication with dependent computation via decomposition in large deep learning models
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, et al. Overlap communication with dependent computation via decomposition in large deep learning models. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Langu...
work page 2022
-
[37]
Overlap communication with dependent computation via decomposition in large deep learning models
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, Sameer Kumar, Tongfei Guo, Yuanzhong Xu, and Zongwei Zhou. Overlap communication with dependent computation via decomposition in large deep learning models. In Proceedings of the 28th ACM International Confe...
work page 2023
-
[38]
Tacos: Topology-aware collective algorithm synthesizer for distributed machine learning
William Won, Midhilesh Elavazhagan, Sudarshan Srini- vasan, Swati Gupta, and Tushar Krishna. Tacos: Topology-aware collective algorithm synthesizer for distributed machine learning. In Proceedings of the 2024 57th IEEE/ACM International Symposium on Mi- croarchitecture, MICRO ’24, page 856–870. IEEE Press, 2024
work page 2024
-
[39]
Mirage: A {Multi- Level} superoptimizer for tensor programs
Mengdi Wu, Xinhao Cheng, Shengyu Liu, Chunan Shi, Jianan Ji, Man Kit Ao, Praveen Velliengiri, Xupeng Miao, Oded Padon, and Zhihao Jia. Mirage: A {Multi- Level} superoptimizer for tensor programs. In 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 21–38, 2025
work page 2025
-
[40]
Gspmd: General and scalable parallelization for ml computation graphs, 2021
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, Ruom- ing Pang, Noam Shazeer, Shibo Wang, Tao Wang, Yonghui Wu, and Zhifeng Chen. Gspmd: General and scalable parallelization for ml computation graphs, 2021
work page 2021
-
[41]
Comet: Fine-grained computation-communication overlapping for mixture- of-experts
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wenlei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li-Wen Chang, et al. Comet: Fine-grained computation-communication overlapping for mixture- of-experts. arXiv preprint arXiv:2502.19811, 2025
-
[42]
Ansor: Generating {High-Performance} tensor programs for deep learn- ing
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, et al. Ansor: Generating {High-Performance} tensor programs for deep learn- ing. In 14th USENIX symposium on operating systems design and implementation (OSDI 20), pages 863–879, 2020
work page 2020
-
[43]
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, Joseph E. Gonzalez, and Ion Stoica. Ansor: generating high-performance ten- sor programs for deep learning. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation, OSDI’20, USA, 2020. USENIX Association
work page 2020
-
[44]
Alpa: Automating inter-and {Intra-Operator} parallelism for distributed deep learning
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P Xing, et al. Alpa: Automating inter-and {Intra-Operator} parallelism for distributed deep learning. In 16th USENIX Sympo- sium on Operating Systems Design and Implementation (OSDI 22), pages 559–578, 2022
work page 2022
-
[45]
Size Zheng, Wenlei Bao, Qi Hou, Xuegui Zheng, Jin Fang, Chenhui Huang, Tianqi Li, Haojie Duanmu, Renze Chen, Ruifan Xu, et al. Triton-distributed: Programming overlapping kernels on distributed ai systems with the triton compiler. arXiv preprint arXiv:2504.19442, 2025
-
[46]
Size Zheng, Jin Fang, Xuegui Zheng, Qi Hou, Wen- lei Bao, Ningxin Zheng, Ziheng Jiang, Dongyang Wang, Jianxi Ye, Haibin Lin, et al. Tilelink: Gen- erating efficient compute-communication overlapping kernels using tile-centric primitives. arXiv preprint arXiv:2503.20313, 2025
-
[47]
Nanoflow: Towards optimal large lan- guage model serving throughput, 2025
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Tian Tang, Qinyu Xu, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. Nanoflow: Towards optimal large lan- guage model serving throughput, 2025. 15
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.