Recognition: no theorem link
Spatiotemporal Continual Learning for Mobile Edge UAV Networks: Mitigating Catastrophic Forgetting
Pith reviewed 2026-05-16 09:36 UTC · model grok-4.3
The pith
The STCL framework with G-MAPPO prevents catastrophic forgetting in UAV networks by decoupling policies and orthogonalizing gradients to adapt to shifting user loads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the spatiotemporal continual learning framework, realized by the group-decoupled multi-agent proximal policy optimization algorithm, integrates group-decoupled policy optimization, gradient orthogonalization, dynamic z-score normalization, and gradient projection to mitigate conflicts among heterogeneous objectives and thereby prevents catastrophic forgetting during spatiotemporal task transitions without requiring offline resets.
What carries the argument
Group-decoupled multi-agent proximal policy optimization (G-MAPPO), which separates policy updates across objective groups and projects gradients to avoid destructive interference while using 3D UAV mobility as spatial compensation.
If this is right
- UAV swarms can maintain coverage and fairness when user counts rise or fall without pausing for retraining.
- Energy consumption remains controlled while the system absorbs new traffic patterns through online adaptation.
- Policy stagnation is avoided even under saturation loads, producing measurable capacity gains over standard multi-agent baselines.
- Aerial edge services become viable for environments whose user distributions evolve faster than offline retraining cycles allow.
Where Pith is reading between the lines
- The same decoupling and projection steps could be applied to other multi-agent control problems that face non-stationary reward landscapes.
- Adding explicit latency or channel-fading models to the state space might further stabilize the spatial compensation layer in outdoor settings.
- The reported 20 percent capacity gain suggests a route to smaller UAV fleets for equivalent service levels if the method generalizes beyond the simulated topology.
Load-bearing premise
The combination of group decoupling, orthogonalization, and z-score normalization will keep objectives balanced and prevent forgetting when real-world spatiotemporal changes exceed the patterns tested in simulation.
What would settle it
A real-world UAV deployment in which service reliability falls below 0.8 during rapid user-density shifts that were not present in the simulation scenarios.
Figures






read the original abstract
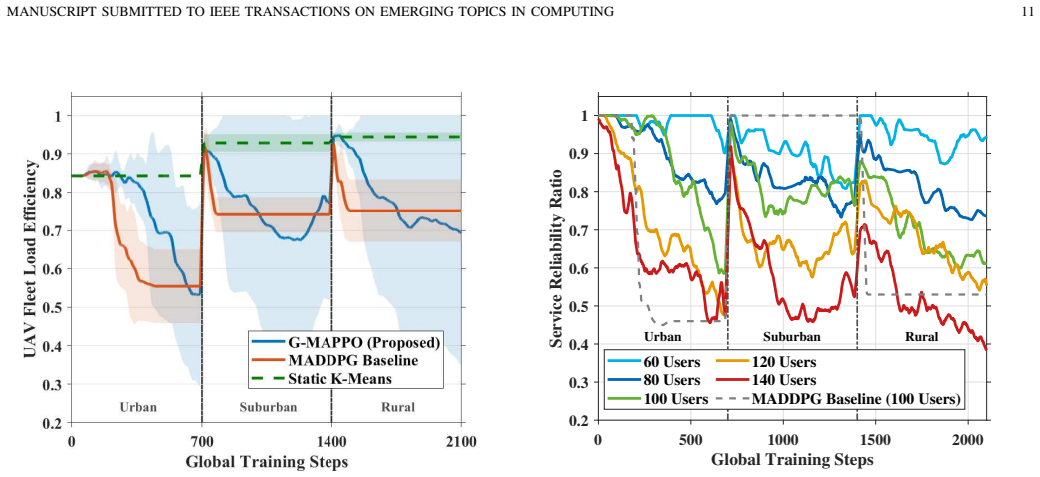
This paper addresses catastrophic forgetting in mobile edge UAV networks within dynamic spatiotemporal environments. Conventional deep reinforcement learning often fails during task transitions, necessitating costly retraining to adapt to new user distributions. We propose the spatiotemporal continual learning (STCL) framework, realized through the group-decoupled multi-agent proximal policy optimization (G-MAPPO) algorithm. The core innovation lies in the integration of a group-decoupled policy optimization (GDPO) mechanism with a gradient orthogonalization layer to balance heterogeneous objectives including energy efficiency, user fairness, and coverage. This combination employs dynamic z-score normalization and gradient projection to mitigate conflicts without offline resets. Furthermore, 3D UAV mobility serves as a spatial compensation layer to manage extreme density shifts. Simulations demonstrate that the STCL framework ensures resilience, with service reliability recovering to over 0.9 for moderate loads of up to 100 users. Even under extreme saturation with 140 users, G-MAPPO maintains a significant performance lead over the multi-agent deep deterministic policy gradient (MADDPG) baseline by preventing policy stagnation. The algorithm delivers an effective capacity gain of 20 percent under high traffic loads, validating its potential for scalable aerial edge swarms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Spatiotemporal Continual Learning (STCL) framework, realized via the Group-decoupled Multi-Agent Proximal Policy Optimization (G-MAPPO) algorithm, to mitigate catastrophic forgetting in deep reinforcement learning for mobile edge UAV networks. It integrates group-decoupled policy optimization (GDPO), a gradient orthogonalization layer, dynamic z-score normalization, and 3D UAV mobility to balance heterogeneous objectives (energy efficiency, user fairness, coverage) during spatiotemporal task transitions without offline retraining. Simulations are reported to demonstrate resilience, with service reliability recovering above 0.9 for loads up to 100 users, a sustained performance lead over MADDPG at 140 users, and an effective 20% capacity gain under high traffic.
Significance. If the reported simulation outcomes prove robust and reproducible, the work provides a targeted contribution to continual learning in multi-agent systems for dynamic UAV edge networks by showing how GDPO combined with gradient projection and normalization can prevent policy stagnation. The explicit quantitative results under moderate and extreme loads (up to 140 users) offer concrete evidence of practical capacity improvements, which could inform scalable aerial swarm designs where environments change rapidly.
major comments (2)
- [Abstract / Simulation Results] Abstract and Simulation Results section: the central empirical claims (service reliability >0.9 for ≤100 users, 20% capacity gain, sustained lead over MADDPG at 140 users) are presented without any description of the simulation environment parameters, number of independent runs, statistical significance tests, hyperparameter values, or exact MADDPG baseline implementation details. This absence makes the quantitative outcomes unverifiable from the manuscript.
- [Method] Method section (GDPO and gradient orthogonalization description): the manuscript asserts that the combination of GDPO, gradient orthogonalization, dynamic z-score normalization, and 3D mobility balances objectives and prevents forgetting, yet provides no formal analysis, convergence argument, or ablation isolating each component's contribution; all support for the claim rests on the simulation outcomes whose setup is undescribed.
minor comments (1)
- [Notation / Algorithm] Ensure all acronyms (STCL, G-MAPPO, GDPO, MADDPG) are defined at first use and used consistently; clarify any undefined symbols in the algorithm pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve the reproducibility and analytical depth of our work on the STCL framework with G-MAPPO. We will revise the manuscript to address the concerns about missing simulation details and methodological justification while preserving the core empirical contributions.
read point-by-point responses
-
Referee: [Abstract / Simulation Results] Abstract and Simulation Results section: the central empirical claims (service reliability >0.9 for ≤100 users, 20% capacity gain, sustained lead over MADDPG at 140 users) are presented without any description of the simulation environment parameters, number of independent runs, statistical significance tests, hyperparameter values, or exact MADDPG baseline implementation details. This absence makes the quantitative outcomes unverifiable from the manuscript.
Authors: We agree that these details are essential for verifiability. In the revised manuscript, we will add a dedicated 'Simulation Setup' subsection (and update the abstract if needed for consistency) that explicitly lists: environment parameters including UAV altitude range (50-200m), maximum speed (20 m/s), user spatial distributions (Poisson point process with varying densities), channel models (Rician fading with path loss exponent 2.5), energy consumption coefficients, and task transition schedules; number of independent runs (10 runs with distinct random seeds, reporting mean ± std); statistical significance (paired t-tests with p<0.05 for key comparisons); all hyperparameter values (actor/critic learning rates 3e-4, discount factor 0.99, clip ratio 0.2, batch size 256, etc.); and the precise MADDPG baseline implementation (following the original MADDPG paper with adaptations for our 3D mobility and multi-objective reward, using the same network architectures and training steps). These additions will directly support the reported outcomes such as reliability recovery above 0.9 for ≤100 users, the 20% capacity gain, and sustained lead at 140 users. revision: yes
-
Referee: [Method] Method section (GDPO and gradient orthogonalization description): the manuscript asserts that the combination of GDPO, gradient orthogonalization, dynamic z-score normalization, and 3D mobility balances objectives and prevents forgetting, yet provides no formal analysis, convergence argument, or ablation isolating each component's contribution; all support for the claim rests on the simulation outcomes whose setup is undescribed.
Authors: We acknowledge the absence of formal analysis and ablations. In the revision, we will expand the Method section with: (i) a high-level convergence sketch noting that GDPO decouples group updates while the orthogonalization layer projects gradients to be orthogonal to prior task directions (preserving PPO's policy improvement guarantee within each group), and (ii) a new ablation study subsection that isolates each component by comparing full G-MAPPO against variants without orthogonalization, without z-score normalization, without 3D mobility compensation, and without GDPO. This will quantify their individual roles in mitigating catastrophic forgetting. A complete end-to-end theoretical convergence proof for the spatiotemporal continual learning setting is beyond the scope of this applied paper, but the added discussion and ablations will provide stronger empirical grounding for the claims. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents the STCL framework and G-MAPPO algorithm as a combination of group-decoupled policy optimization, gradient orthogonalization, dynamic z-score normalization, and 3D mobility to address catastrophic forgetting. All central claims are scoped to simulation results (service reliability >0.9 up to 100 users, lead over MADDPG at 140 users, 20% capacity gain) rather than any closed-form derivations or equations. No load-bearing steps reduce predictions to fitted inputs by construction, no self-definitional relations appear, and no uniqueness theorems or ansatzes are imported via self-citation in the provided text. The empirical demonstration stands independently on simulation comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A tutorial on uavs for wireless networks: Applications, chal lenges, and open problems,
M. Mozaffari, W. Saad, M. Bennis, Y .-H. Nam, and M. Debbah , “A tutorial on uavs for wireless networks: Applications, chal lenges, and open problems,” IEEE Communications Surveys & Tutorials , vol. 21, no. 3, pp. 2334–2360, 2019
work page 2019
-
[2]
Optimal la p altitude for maximum coverage,
A. Al-Hourani, S. Kandeepan, and S. Lardner, “Optimal la p altitude for maximum coverage,” IEEE Wireless Communications Letters , vol. 3, no. 6, pp. 569–572, 2014
work page 2014
-
[3]
C.-C. Lai, C.-T. Chen, and L.-C. Wang, “On-demand densit y-aware uav base station 3d placement for arbitrarily distributed u sers with guaranteed data rates,” IEEE Wireless Communications Letters , vol. 8, no. 3, pp. 913–916, 2019
work page 2019
-
[4]
J. Liang, J. Zhao, C. Wang, X. Y ang, K. Y ue, and W. Li, “Enha ncing the robustness of uav search path planning based on deep rein force- ment learning for complex disaster scenarios,” IEEE Transactions on V ehicular Technology, vol. 75, no. 1, pp. 392–404, 2026
work page 2026
-
[5]
X. Zheng, G. Sun, J. Li, J. Wang, Q. Wu, D. Niyato, and A. Jam alipour, “Uav swarm-enabled collaborative post-disaster communic ations in low altitude economy via a two-stage optimization approach,” IEEE Trans- actions on Mobile Computing , vol. 24, no. 11, pp. 11 833–11 851, 2025
work page 2025
-
[6]
T. Do-Duy, L. D. Nguyen, T. Q. Duong, S. R. Khosravirad, an d H. Claussen, “Joint optimisation of real-time deployment a nd resource allocation for uav-aided disaster emergency communicatio ns,” IEEE Journal on Selected Areas in Communications , vol. 39, no. 11, pp. 3411– 3424, 2021
work page 2021
-
[7]
S. Troia, G. Sheng, R. Alvizu, G. A. Maier, and A. Pattavin a, “Identifi- cation of tidal-traffic patterns in metro-area mobile netwo rks via matrix factorization based model,” in 2017 IEEE International Conference on Pervasive Computing and Communications W orkshops (PerC om W orkshops), 2017, pp. 297–301
work page 2017
-
[8]
Overco ming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. V eness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwins ka, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overco ming catastrophic forgetting in neural networks,” Proceedings of the National Academy of Sciences , vol. 114, no. 13, pp. 3521–3526, 2017
work page 2017
-
[9]
Multiobjective reinforcement l earning: A comprehensive overview,
C. Liu, X. Xu, and D. Hu, “Multiobjective reinforcement l earning: A comprehensive overview,” IEEE Transactions on Systems, Man, and Cybernetics: Systems , vol. 45, no. 3, pp. 385–398, 2015
work page 2015
-
[10]
Continuous transfer learning for uav communica tion-aware trajectory design,
C. Sun, G. Fontanesi, S. B. Chetty, X. Liang, B. Canberk, and H. Ahmadi, “Continuous transfer learning for uav communica tion-aware trajectory design,” in 2024 11th International Conference on Wireless Networks and Mobile Communications (WINCOM) , 2024, pp. 1–7
work page 2024
-
[11]
M. Alzenad, A. El-Keyi, F. Lagum, and H. Y anikomeroglu, “3-d place- ment of an unmanned aerial vehicle base station (uav-bs) for energy- efficient maximal coverage,” IEEE Wireless Communications Letters , vol. 6, no. 4, pp. 434–437, 2017
work page 2017
-
[12]
Efficie nt de- ployment of multiple unmanned aerial vehicles for optimal w ireless coverage,
M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Efficie nt de- ployment of multiple unmanned aerial vehicles for optimal w ireless coverage,” IEEE Communications Letters, vol. 20, no. 8, pp. 1647–1650, 2016
work page 2016
-
[13]
The coverage overlap ping problem of serving arbitrary crowds in 3d drone cellular networks,
C.-C. Lai, L.-C. Wang, and Z. Han, “The coverage overlap ping problem of serving arbitrary crowds in 3d drone cellular networks,” IEEE Transactions on Mobile Computing , vol. 21, no. 3, 2022
work page 2022
-
[14]
Energy-efficient uav communicati on with tra- jectory optimization,
Y . Zeng and R. Zhang, “Energy-efficient uav communicati on with tra- jectory optimization,” IEEE Transactions on Wireless Communications , vol. 16, no. 6, pp. 3747–3760, 2017
work page 2017
-
[15]
Adaptive and fair deployment approach to balance offload traffic in multi-uav c ellular networks,
C.-C. Lai, Bhola, A.-H. Tsai, and L.-C. Wang, “Adaptive and fair deployment approach to balance offload traffic in multi-uav c ellular networks,” IEEE Transactions on V ehicular Technology, vol. 72, no. 3, pp. 3724–3738, 2023
work page 2023
-
[16]
Energy-efficient 3-d uav g round node accessing using the minimum number of uavs,
H. Gong, B. Huang, and B. Jia, “Energy-efficient 3-d uav g round node accessing using the minimum number of uavs,” IEEE Transactions on Mobile Computing , vol. 23, no. 12, pp. 12 046–12 060, 2024
work page 2024
-
[17]
Interferenc e management for cellular-connected uavs: A deep reinforcement learning ap proach,
U. Challita, W. Saad, and C. Bettstetter, “Interferenc e management for cellular-connected uavs: A deep reinforcement learning ap proach,” IEEE Transactions on Wireless Communications , vol. 18, no. 4, pp. 2125– 2140, 2019
work page 2019
-
[18]
Evolving collabora tive differential evolution for dynamic multi-objective uav pa th planning,
R. Xu, Z. Huang, C. Wang, and H. Y an, “Evolving collabora tive differential evolution for dynamic multi-objective uav pa th planning,” IEEE Transactions on V ehicular Technology, pp. 1–13, 2025
work page 2025
-
[19]
Aura-green: Aerial ut ility-driven route adaptation for green cooperative networks,
I. Aryendu, S. Arya, and Y . Wang, “Aura-green: Aerial ut ility-driven route adaptation for green cooperative networks,” IEEE Transactions on V ehicular Technology, pp. 1–18, 2025
work page 2025
-
[20]
Multi- agent actor-critic for mixed cooperative-competitive env ironments,
R. Lowe, Y . Wu, A. Tamar, J. Harb, P . Abbeel, and I. Mordat ch, “Multi- agent actor-critic for mixed cooperative-competitive env ironments,” in Proceedings of the 31st International Conference on Neural Information Processing Systems , Long Beach, California, USA, 2017, pp. 6382– 6393
work page 2017
-
[21]
J. Liu, X. Zhao, P . Qin, F. Du, Z. Chen, H. Zhou, and J. Li, “ Joint uav 3d trajectory design and resource scheduling for space- air-ground integrated power iort: A deep reinforcement learning appro ach,” IEEE Transactions on Network Science and Engineering , vol. 11, no. 3, pp. 2632–2646, 2024
work page 2024
-
[22]
S. Wu, W. Xu, F. Wang, G. Li, and M. Pan, “Distributed fede rated deep reinforcement learning based trajectory optimizatio n for air-ground cooperative emergency networks,” IEEE Transactions on V ehicular Technology, vol. 71, no. 8, pp. 9107–9112, 2022
work page 2022
-
[23]
The surprising effectiveness of ppo in cooperative multi-agen t games,
C. Y u, A. V elu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agen t games,” in Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 2022
work page 2022
-
[24]
Hierarchical multi-agent drl-based dynami c cluster reconfiguration for uav mobility management,
I. A. Meer, K.-L. Besser, M. Ozger, D. A. Schupke, H. V . Po or, and C. Cavdar, “Hierarchical multi-agent drl-based dynami c cluster reconfiguration for uav mobility management,” IEEE Transactions on Cognitive Communications and Networking , vol. 12, pp. 4957–4971, 2026
work page 2026
-
[25]
G. Chen, G. Zhao, C. Xu, Z. Han, and S. Y u, “Spatiotempora l- aware deep reinforcement learning for multi-uav cooperati ve coverage in emergency deterministic communications,” IEEE Transactions on V ehicular Technology, vol. 75, no. 1, pp. 1310–1321, 2026
work page 2026
-
[26]
Multi-agent reinfo rcement learning- based resource allocation for uav networks,
J. Cui, Y . Liu, and A. Nallanathan, “Multi-agent reinfo rcement learning- based resource allocation for uav networks,” IEEE Transactions on Wireless Communications, vol. 19, no. 2, pp. 729–743, 2020
work page 2020
-
[27]
L. T. Hoang, C. T. Nguyen, H. D. Le, and A. T. Pham, “Adapti ve 3d placement of multiple uav-mounted base stations in 6g air borne small cells with deep reinforcement learning,” IEEE Transactions on Networking, vol. 33, no. 4, pp. 1989–2004, 2025
work page 1989
-
[28]
Deep t ransfer learning for intelligent cellular traffic prediction based on cross-domain big data,
C. Zhang, H. Zhang, J. Qiao, D. Y uan, and M. Zhang, “Deep t ransfer learning for intelligent cellular traffic prediction based on cross-domain big data,” IEEE Journal on Selected Areas in Communications , vol. 37, no. 6, pp. 1389–1401, 2019
work page 2019
-
[29]
C. H. Liu, Z. Chen, J. Tang, J. Xu, and C. Piao, “Energy-ef ficient uav control for effective and fair communication coverage: A deep reinforcement learning approach,” IEEE Journal on Selected Areas in Communications, vol. 36, no. 9, pp. 2059–2070, 2018
work page 2059
-
[30]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
S.-Y . Liu, X. Dong, X. Lu, S. Diao, P . Belcak, M. Liu, M.-H . Chen, H. Yin, Y .-C. F. Wang, K.-T. Cheng, Y . Choi, J. Kautz, and P . Molchanov, “Gdpo: Group reward-decoupled normaliza tion policy optimization for multi-reward rl optimization,” 20 26. [Online]. Available: https://arxiv.org/abs/2601.05242
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
H. Peng, Y .-T. Lin, C.-Y . Ho, and L.-C. Wang, “Energy effi ciency optimization for iot systems with reconfigurable intellige nt surfaces: A self-supervised reinforcement learning approach,” IEEE Transactions on Wireless Communications, vol. 24, no. 9, pp. 7761–7776, 2025
work page 2025
-
[32]
A. M. Huroon, Y .-C. Huang, and L.-C. Wang, “Uav-ris assi sted mul- tiuser communications through transmission strategy opti mization: Gbd application,” IEEE Transactions on V ehicular Technology, vol. 73, no. 6, pp. 8584–8597, 2024. Chuan-Chi Lai (Member, IEEE) received the Ph.D. degree in Computer Science and Information En- gineering from the National ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.