MSAO: Adaptive Modality Sparsity-Aware Offloading with Edge-Cloud Collaboration for Efficient Multimodal LLM Inference
Pith reviewed 2026-05-13 18:22 UTC · model grok-4.3
The pith
MSAO uses a lightweight sparsity metric to dynamically split multimodal LLM workloads between edge devices and the cloud, cutting latency by 30 percent and raising throughput up to 2.3 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MSAO first runs a lightweight heterogeneous modality-aware module that performs spatial-temporal-modal joint analysis to produce a Modality Activation Sparsity score for each input modality, then feeds those scores together with live system measurements into an adaptive speculative edge-cloud offloading scheduler that decides which layers or tokens to execute locally or remotely while hiding communication cost through confidence-guided speculation.
What carries the argument
The Modality Activation Sparsity (MAS) metric, produced by fine-grained spatial-temporal-modal analysis in a lightweight module, that drives real-time decisions on what to keep on the edge versus offload to the cloud.
If this is right
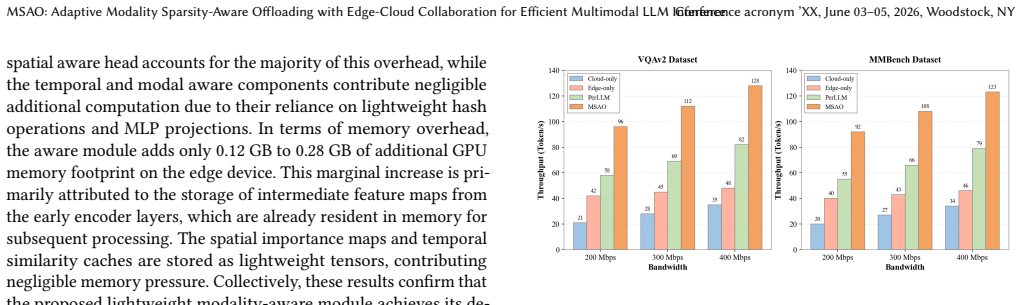
- End-to-end latency falls by about 30 percent on VQAv2 and MMBench.
- Resource overhead drops between 30 and 65 percent.
- Inference throughput rises between 1.5 and 2.3 times.
- Answer accuracy remains competitive with full local or full cloud baselines.
Where Pith is reading between the lines
- The same sparsity signal could be reused to prune model layers during training rather than only at inference time.
- The scheduling logic might extend to chains of multiple edge devices instead of a single edge-cloud pair.
- If the MAS scores prove stable across model families, they could become a standard lightweight feature attached to any multimodal backbone.
Load-bearing premise
The lightweight module can compute accurate sparsity scores for each modality with very low added cost and that live system measurements remain reliable enough to make good offloading choices without introducing new errors.
What would settle it
Deploy MSAO on a new multimodal task whose modality importance changes rapidly and unpredictably, then check whether the reported 30 percent latency cut and throughput gains disappear while accuracy stays the same.
Figures







read the original abstract
Multimodal large language models (MLLMs) enable powerful cross-modal reasoning capabilities but impose substantial computational and latency burdens, posing critical challenges for deployment on resource-constrained edge devices. In this paper, we propose MSAO, an adaptive modality sparsity-aware offloading framework with edge-cloud collaboration for efficient MLLM Inference. First, a lightweight heterogeneous modality-aware via fine-grained sparsity module performs spatial-temporal-modal joint analysis to compute the Modality Activation Sparsity (MAS) metric, which quantifies the necessity of each modality with minimal computational overhead. Second, an adaptive speculative edge-cloud collaborative offloading mechanism dynamically schedules workloads between edge and cloud based on the derived MAS scores and real-time system states, leveraging confidence-guided speculative execution to hide communication latency. Extensive experiments on VQAv2 and MMBench benchmarks demonstrate that MSAO achieves a 30% reduction in end-to-end latency and 30%-65% decrease in resource overhead, while delivering a throughput improvement of 1.5x to 2.3x compared to traditional approaches, all without compromising competitive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MSAO, an adaptive modality sparsity-aware offloading framework for efficient multimodal LLM inference via edge-cloud collaboration. It introduces a lightweight heterogeneous modality-aware module that performs spatial-temporal-modal joint analysis to compute the Modality Activation Sparsity (MAS) metric quantifying each modality's necessity with low overhead, followed by an adaptive speculative edge-cloud scheduler that dynamically offloads workloads based on MAS scores and real-time system states while using confidence-guided execution to hide latency. Experiments on VQAv2 and MMBench claim 30% end-to-end latency reduction, 30-65% resource overhead savings, and 1.5x-2.3x throughput gains versus traditional approaches without accuracy loss.
Significance. If the performance claims hold under rigorous validation, the work would be significant for practical edge deployment of MLLMs, as it directly addresses computational and latency bottlenecks through modality sparsity and speculative collaboration, potentially enabling real-time multimodal applications on constrained devices with lower resource demands.
major comments (2)
- [Experiments / §4] The central performance claims (30% latency reduction, 30-65% resource savings, 1.5x-2.3x throughput) rest on the MAS metric accurately identifying skippable modalities, but the manuscript provides no correlation analysis, ablation on MAS thresholds, or comparison of MAS-driven decisions versus oracle modality necessity (e.g., in the experiments section or §4).
- [Abstract / Results] Reported results on VQAv2 and MMBench lack any information on baselines, number of runs, variance, statistical significance, or exact accuracy measurement protocol, making it impossible to assess whether the 'competitive accuracy' claim is supported (abstract and results section).
minor comments (2)
- [§3] Clarify the exact definition and computation of the MAS metric in the lightweight module to ensure it is independent of final performance numbers.
- [§4] Add explicit discussion of potential error introduction from speculative execution in the scheduler.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the experimental validation and reporting.
read point-by-point responses
-
Referee: [Experiments / §4] The central performance claims (30% latency reduction, 30-65% resource savings, 1.5x-2.3x throughput) rest on the MAS metric accurately identifying skippable modalities, but the manuscript provides no correlation analysis, ablation on MAS thresholds, or comparison of MAS-driven decisions versus oracle modality necessity (e.g., in the experiments section or §4).
Authors: We agree that additional analyses would strengthen the validation of the MAS metric. In the revised manuscript, we will add: (1) a correlation analysis between MAS scores and ground-truth modality necessity (measured via accuracy impact when skipping each modality), (2) ablations varying MAS thresholds to show the trade-off between sparsity and accuracy, and (3) a direct comparison of MSAO decisions against an oracle that knows the optimal set of skippable modalities. These will be included in §4 with new figures/tables. revision: yes
-
Referee: [Abstract / Results] Reported results on VQAv2 and MMBench lack any information on baselines, number of runs, variance, statistical significance, or exact accuracy measurement protocol, making it impossible to assess whether the 'competitive accuracy' claim is supported (abstract and results section).
Authors: We acknowledge the reporting gaps. The revised manuscript will: specify all baselines (full cloud inference, edge-only, random sparsity, etc.), report results as mean ± std over 5 independent runs, include statistical significance tests (paired t-tests with p-values), and detail the accuracy protocol (e.g., VQA accuracy for VQAv2, exact MMBench scoring). These details will be added to the results section and reflected concisely in the abstract. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, derivations, or self-citations. The MAS metric is introduced as an independent computation from a lightweight module performing joint analysis, and performance claims (latency reduction, throughput gains) are presented as outcomes of experiments on VQAv2 and MMBench rather than reductions to fitted inputs or self-referential definitions. No load-bearing step reduces by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Modality Activation Sparsity (MAS) metric
no independent evidence
-
MSAO framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Xinye Cao, Hongcan Guo, Guoshun Nan, Jiaoyang Cui, Haoting Qian, Yihan Lin, Yilin Peng, Diyang Zhang, Yanzhao Hou, Huici Wu, Xiaofeng Tao, and Tony Q. S. Quek. 2025. Advancing Compositional LLM Reasoning With Structured Task Relations in Interactive Multimodal Communications.IEEE Journal on Selected Areas in Communications43, 12 (2025), 4231–4246
work page 2025
-
[3]
Daoyuan Chen, Yilun Huang, Zhijian Ma, Hesen Chen, Xuchen Pan, Ce Ge, Dawei Gao, Yuexiang Xie, Zhaoyang Liu, Jinyang Gao, et al. 2024. Data-juicer: A one-stop data processing system for large language models. InCompanion of the 2024 International Conference on Management of Data. 120–134
work page 2024
-
[4]
Yucheng Ding, Chaoyue Niu, Fan Wu, Shaojie Tang, Chengfei Lyu, and Guihai Chen. 2024. Enhancing on-device llm inference with historical cloud-based llm interactions. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 597–608
work page 2024
-
[5]
Xin Dong, Sen Jia, Ming Rui Wang, Yan Li, Zhenheng Yang, Bingfeng Deng, and Hongyu Xiong. 2025. Coef-vq: Cost-efficient video quality understanding through a cascaded multimodal llm framework. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4387–4395
work page 2025
-
[6]
Zhiqi Ge, Hongzhe Huang, Mingze Zhou, Juncheng Li, Guoming Wang, Siliang Tang, and Yueting Zhuang. 2024. Worldgpt: Empowering llm as multimodal world model. InProceedings of the 32nd ACM International Conference on Multimedia. 7346–7355
work page 2024
-
[7]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
-
[8]
InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6904–6913
-
[9]
Samuel Hsia, Alicia Golden, Bilge Acun, Newsha Ardalani, Zachary DeVito, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu. 2024. Mad-max beyond single- node: Enabling large machine learning model acceleration on distributed systems. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). 818–833
work page 2024
-
[10]
Wenbo Hu, Yifan Xu, Yi Li, Weiyue Li, Zeyuan Chen, and Zhuowen Tu. 2024. Bliva: A simple multimodal llm for better handling of text-rich visual questions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 2256–2264
work page 2024
-
[11]
Xinyi Hu, Zihan Chen, Kun Guo, Meng Zhang, and Howard Hao Yang. 2025. Adaptlink: A heterogeneity-aware adaptive framework for distributed mllm infer- ence. InAAAI 2025 Workshop on Artificial Intelligence for Wireless Communications and Networking
work page 2025
- [12]
- [13]
-
[14]
Yaqi Hu, Dongdong Ye, Jiawen Kang, Maoqiang Wu, and Rong Yu. 2024. A cloud–edge collaborative architecture for multimodal LLM-based advanced driver assistance systems in IoT networks.IEEE Internet of Things Journal12, 10 (2024), 13208–13221
work page 2024
-
[15]
Wen Ji, Bing Liang, Yuqin Wang, Rui Qiu, and Zheming Yang. 2020. Crowd V-IoE: Visual internet of everything architecture in AI-driven fog computing.IEEE Wireless Communications27, 2 (2020), 51–57
work page 2020
-
[16]
Yizhang Jin, Jian Li, Tianjun Gu, Yexin Liu, Bo Zhao, Jinxiang Lai, Zhenye Gan, Yabiao Wang, Chengjie Wang, Xin Tan, et al. 2025. Efficient multimodal large language models: A survey.Visual Intelligence3, 1 (2025), 27
work page 2025
-
[17]
Zuodong Jin, Dan Tao, Peng Qi, and Ruipeng Gao. 2024. An adaptive cloud resource quota scheme based on dynamic portraits and task-resource matching. IEEE Transactions on Cloud Computing12, 4 (2024), 996–1010
work page 2024
-
[18]
Jing Yu Koh, Daniel Fried, and Russ R Salakhutdinov. 2023. Generating images with multimodal language models.Advances in Neural Information Processing Systems36 (2023), 21487–21506
work page 2023
-
[19]
Xiangchen Li, Dimitrios Spatharakis, Saeid Ghafouri, Jiakun Fan, Hans Vandieren- donck, Deepu John, Bo Ji, and Dimitrios S Nikolopoulos. 2025. Sled: A speculative llm decoding framework for efficient edge serving. InProceedings of the Tenth ACM/IEEE Symposium on Edge Computing. 1–8
work page 2025
-
[20]
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. 2025. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 5334–5342
work page 2025
-
[21]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al . 2024. Mmbench: Is your multi-modal model an all-around player?. InEuropean Conference on Computer Vision. 216–233
work page 2024
-
[22]
Haoxiang Luo, Yinqiu Liu, Ruichen Zhang, Jiacheng Wang, Gang Sun, Dusit Niyato, Hongfang Yu, Zehui Xiong, Xianbin Wang, and Xuemin Shen. 2025. Toward Edge General Intelligence With Multiple-Large Language Model (Multi- LLM): Architecture, Trust, and Orchestration.IEEE Transactions on Cognitive Communications and Networking11, 6 (2025), 3563–3585
work page 2025
-
[23]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, Tianqi Chen, and Zhihao Jia. 2025. Towards efficient generative large language model serving: A survey from algorithms to systems.Comput. Surveys58, 1 (2025), 1–37
work page 2025
-
[24]
Hyungjun Oh, Kihong Kim, Jaemin Kim, Sungkyun Kim, Junyeol Lee, Du-seong Chang, and Jiwon Seo. 2024. Exegpt: Constraint-aware resource scheduling for llm inference. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume
work page 2024
-
[25]
Guanqiao Qu, Qiyuan Chen, Wei Wei, Zheng Lin, Xianhao Chen, and Kaibin Huang. 2025. Mobile Edge Intelligence for Large Language Models: A Contempo- rary Survey.IEEE Communications Surveys & Tutorials27, 6 (2025), 3820–3860
work page 2025
- [26]
-
[27]
Liang Tong, Yong Li, and Wei Gao. 2016. A hierarchical edge cloud architecture for mobile computing. In35th Annual IEEE International Conference on Computer Communications. 1–9
work page 2016
-
[28]
Guanqun Wang, Jiaming Liu, Chenxuan Li, Yuan Zhang, Junpeng Ma, Xinyu Wei, Kevin Zhang, Maurice Chong, Renrui Zhang, Yijiang Liu, et al. 2024. Cloud-device collaborative learning for multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12646–12655
work page 2024
-
[29]
Yabing Wang, Le Wang, Qiang Zhou, Zhibin Wang, Hao Li, Gang Hua, and Wei Tang. 2024. Multimodal llm enhanced cross-lingual cross-modal retrieval. In Proceedings of the 32nd ACM International Conference on Multimedia. 8296–8305
work page 2024
-
[30]
Zhiquan Wen, Mingkui Tan, Yaowei Wang, Qingyao Wu, and Qi Wu. 2025. En- hanced Reasoning via Multimodal LLMs and Collaborative Inference.IEEE Transactions on Multimedia27 (2025), 7166–7178
work page 2025
-
[31]
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Philip S Yu
-
[32]
In2023 IEEE International Conference on Big Data
Multimodal large language models: A survey. In2023 IEEE International Conference on Big Data. 2247–2256
-
[33]
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. 2024. NExT- GPT: Any-to-Any Multimodal LLM. InForty-first International Conference on Machine Learning. 53366–53397
work page 2024
-
[34]
Zhiyuan Wu, Sheng Sun, Yuwei Wang, Min Liu, Bo Gao, Jinda Lu, Tingting Wu, Zheming Yang, and Tian Wen. 2025. Recursive Offloading for LLM Serving in Multi-tier Networks.IEEE Transactions on Mobile Computing(2025), 1–16
work page 2025
-
[35]
Xinyi Xu, Gang Feng, Yijing Liu, Shuang Qin, Jian Wang, and Yunxiang Wang
-
[36]
Joint Inference Offloading and Model Caching for Small and Large Language Model Collaboration.IEEE Transactions on Mobile Computing25, 2 (2026), 2691– 2706
work page 2026
-
[37]
Xingyu Xu, Yuan Song, Bo Hu, Peng Zheng, Zihan Zou, Xin Si, and Bo Liu. 2025. SparCIM: A Heterogeneous CIM-Based Accelerator for Large Language Models with Contextual and Unstructured Bit Sparsity. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 1–9
work page 2025
- [38]
-
[39]
Zheming Yang, Wen Ji, Qi Guo, and Zhi Wang. 2023. Javp: Joint-aware video processing with edge-cloud collaboration for dnn inference. InProceedings of the 31st ACM International Conference on Multimedia. 9152–9160
work page 2023
-
[40]
Zheming Yang, Wen Ji, Qi Guo, Jian Zhao, Chang Zhao, Xingzhou Zhang, Yangyu Zhang, Zhicheng Li, and Yang You. 2026. CLAP: Cross-Layer Adaptive Pipelining Conference acronym ’XX, June 03–05, 2026, Woodstock, NY Trovato et al. Inference Scheduling for Resource-Efficient Edge-Cloud Vision Systems.ACM Transactions on Architecture and Code Optimization(2026)
work page 2026
-
[41]
Zheming Yang, Bing Liang, and Wen Ji. 2021. An intelligent end–edge–cloud architecture for visual IoT-assisted healthcare systems.IEEE Internet of Things Journal8, 23 (2021), 16779–16786
work page 2021
-
[42]
Zheming Yang, Yuanhao Yang, Chang Zhao, Qi Guo, Wenkai He, and Wen Ji
- [43]
-
[44]
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Chi Chen, Haoyu Li, Weilin Zhao, et al. 2025. Efficient GPT-4V level multi- modal large language model for deployment on edge devices.Nature Communi- cations16, 1 (2025), 5509
work page 2025
-
[45]
Zixuan Yi, Zijun Long, Iadh Ounis, Craig Macdonald, and Richard Mccreadie
-
[46]
Enhancing recommender systems: Deep modality alignment with large multi-modal encoders.ACM Transactions on Recommender Systems3, 4 (2025), 1–25
work page 2025
-
[47]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2024. A survey on multimodal large language models.National Science Review11, 12 (2024), 403
work page 2024
-
[48]
Cheng Yuan, Zhening Liu, Jiashu Lv, Jiawei Shao, Yufei Jiang, Jun Zhang, and Xuelong Li. 2026. Task-Oriented Feature Compression for Multimodal Under- standing via Device-Edge Co-Inference.IEEE Transactions on Mobile Computing 25, 4 (2026), 4762–4775
work page 2026
-
[49]
Xingyu Yuan and He Li. 2026. Video Language Model Inference Offloading in Cloud-Edge Collaboration: A Decoupled Approach. In2026 20th International Conference on Ubiquitous Information Management and Communication (IMCOM). IEEE, 1–7
work page 2026
-
[50]
Xingyu Yuan, He Li, Mianxiong Dong, and Kaoru Ota. 2026. Adaptive Scheduling of Multimodal Large Language Model in Intelligent Edge Computing. 21, 1, Article 4 (2026), 22 pages
work page 2026
-
[51]
Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. 2024. Mm-llms: Recent advances in multimodal large language models. Findings of the Association for Computational Linguistics(2024), 12401–12430
work page 2024
-
[52]
Shuoming Zhang, Jiacheng Zhao, Siqi Li, Xiyu Shi, Yangyu Zhang, Shuaijiang Li, Donglin Yu, Zheming Yang, Yuan Wen, Huimin Cui, et al. 2025. SpaceServe: Spatial Multiplexing of Complementary Encoders and Decoders for Multimodal LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[53]
Wenlun Zhang, Haoran Pang, Yucai Zhou, Shixiao Wang, and Luking Li. 2025. GSMM: Efficient Global Sparsification for Resource-Conscious Multimodal Mod- els. In2025 IEEE International Conference on Acoustics, Speech and Signal Processing. 1–5
work page 2025
-
[54]
Xinyuan Zhang, Jiangtian Nie, Yudong Huang, Gaochang Xie, Zehui Xiong, Jiang Liu, Dusit Niyato, and Xuemin Shen. 2024. Beyond the cloud: Edge inference for generative large language models in wireless networks.IEEE Transactions on Wireless Communications24, 1 (2024), 643–658
work page 2024
-
[55]
Xixi Zheng, You Li, Baokun Zheng, Chuan Zhang, and Liehuang Zhu. 2026. EdgeNetLLM: Cloud–Edge Collaborative Adaptation of Large Language Models for Mobile Networking.IEEE Transactions on Network Science and Engineering13 (2026), 3928–3943. doi:10.1109/TNSE.2025.3624100
-
[56]
Yue Zheng, Yuhao Chen, Bin Qian, Xiufang Shi, Yuanchao Shu, and Jiming Chen. 2025. A review on edge large language models: Design, execution, and applications.Comput. Surveys57, 8 (2025), 1–35
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.