String Representation in Suffixient Set Size Space
Pith reviewed 2026-05-10 20:04 UTC · model grok-4.3
The pith
Every string admits a string representation of size O(χ(w)) using substring equation systems
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We answer this question affirmatively by presenting the first such representation scheme. Our construction is based on a new model, the substring equation system (SES), and we show that every string admits an SES of size O(χ(w)).
What carries the argument
The substring equation system (SES), a model that represents a string via equations relating its substrings, carrying the argument by achieving total size O(χ(w)) for any input string.
If this is right
- String representations and indexing structures can be parameterized directly by χ(w).
- The reachability problem for the χ measure is resolved in the affirmative.
- Compressed data structures based on repetitiveness can now use χ as a space bound without exceptions.
Where Pith is reading between the lines
- The SES construction suggests a template that could be tested on related repetitiveness measures such as the number of runs.
- Practical string algorithms in domains like text search may achieve better space bounds if SES can be implemented efficiently.
Load-bearing premise
The newly introduced substring equation system can serve as a valid string representation whose total size is O(χ(w)) for every string without hidden additive terms or additional assumptions not stated in the abstract.
What would settle it
A concrete string w where every substring equation system has size not O(χ(w)), or a counterexample exposing an unaccounted additive term in the construction.
Figures


read the original abstract
Repetitiveness measures quantify how much repetitive structure a string contains and serve as parameters for compressed representations and indexing data structures. We study the measure $\chi$, defined as the size of the smallest suffixient set. Although $\chi$ has been studied extensively, its reachability, whether every string $w$ admits a string representation of size $O(\chi(w))$ words, has remained an important open problem. We answer this question affirmatively by presenting the first such representation scheme. Our construction is based on a new model, the substring equation system (SES), and we show that every string admits an SES of size $O(\chi(w))$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the open problem of reachability for the repetitiveness measure χ(w), the size of the smallest suffixient set. It introduces the substring equation system (SES) model and constructs, for every string w, an SES of size O(χ(w)) derived directly from a minimum suffixient set S. Variables are assigned to positions in S, and equations encode the necessary overlaps and extensions; the resulting system has size linear in |S| and is solvable in linear time to recover w uniquely.
Significance. If the construction holds, the result is significant for stringology and compressed data structures: it affirmatively resolves whether χ admits an O(χ(w))-size representation, the first such scheme. Credit is due for the explicit, parameter-free derivation (linear in |S| with no hidden n- or alphabet-dependent factors) and the linear-time reconstruction guarantee, both of which strengthen the claim beyond the abstract.
minor comments (2)
- [Abstract] The abstract states the O(χ(w)) bound but does not mention the linear-time solvability; adding one sentence would better convey the efficiency of the representation scheme.
- [Section 3 (SES definition)] A short worked example (e.g., a periodic string of length 10–15) illustrating variable assignment and the resulting equations would help readers verify that the SES size is indeed linear in |S| and that reconstruction is unique.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions, and the recommendation for minor revision. We are pleased that the explicit linear-size construction, parameter-free nature, and linear-time reconstruction were highlighted as strengthening the result.
Circularity Check
No significant circularity; explicit construction from prior measure
full rationale
The paper defines a new substring equation system (SES) model explicitly constructed from any suffixient set S of size χ(w). It proves by direct counting that the resulting SES has O(χ(w)) equations/variables and that the system uniquely determines w (solvable in linear time). No step reduces the claimed O(χ(w)) bound to a fitted parameter, self-definition, or unverified self-citation chain; the size analysis follows from the explicit encoding of overlaps/extensions already present in S. The derivation is therefore self-contained and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
substring equation system (SES)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We answer this question affirmatively by presenting the first such representation scheme. Our construction is based on a new model, the substring equation system (SES), and we show that every string admits an SES of size O(χ(w)).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Smallest suffixient set maintenance in near-real-time
The smallest suffixient set can be maintained online in polyloglog time per letter in either left-to-right or right-to-left direction via Weiner's suffix tree primitives.
Reference graph
Works this paper leans on
-
[1]
A separation ofγand b via thue-morse words
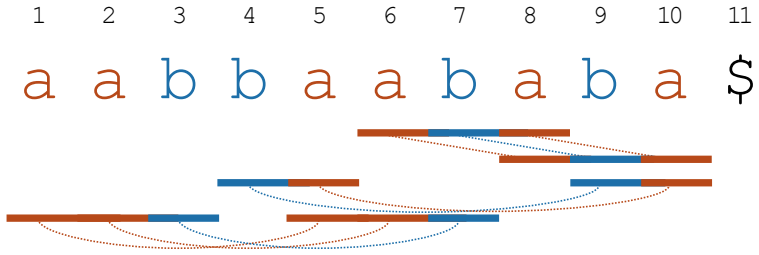
Hideo Bannai, Mitsuru Funakoshi, Tomohiro I, Dominik K¨ oppl, Takuya Mieno, and Takaaki Nishimoto. A separation ofγand b via thue-morse words. In Thierry Lecroq and H´ el` ene Touzet, editors,String 8 ba aa a 1 11107 9865432 bb a a b $ Figure 3: An example of a substring equation system (SES) constructed from the reverse compacted trie induced by the supe...
-
[2]
Michael Burrows and David J. Wheeler. A block-sorting lossless data compression algorithm. InTech- nical Report 124. Digital SRC Research Report, 1994
work page 1994
-
[3]
Davide Cenzato, Lore Depuydt, Travis Gagie, Sung-Hwan Kim, Giovanni Manzini, Francisco Olivares, Nicola Prezza, and Lore Depuydt. Suffixient arrays: a new efficient suffix array compression technique. CoRR, abs/2407.18753, 2023. URL:https://doi.org/10.48550/arXiv.2407.18753,arXiv:2407. 18753,doi:10.48550/ARXIV.2407.18753
-
[4]
On computing the smallest suffixient set
Davide Cenzato, Francisco Olivares, and Nicola Prezza. On computing the smallest suffixient set. In Zsuzsanna Lipt´ ak, Edleno Silva de Moura, Karina Figueroa, and Ricardo Baeza-Yates, editors,String Processing and Information Retrieval - 31st International Symposium, SPIRE 2024, Puerto Vallarta, Mexico, September 23-25, 2024, Proceedings, volume 14899 of...
-
[5]
Suf- fixient sets.arXiv preprint 2312.01359v3, 2024
Lore Depuydt, Travis Gagie, Ben Langmead, Giovanni Manzini, and Nicola Prezza. Suffixient sets. CoRR, abs/2312.01359, 2023. URL:https://doi.org/10.48550/arXiv.2312.01359,arXiv:2312. 01359,doi:10.48550/ARXIV.2312.01359
-
[6]
Optimal suffix tree construction with large alphabets
Martin Farach. Optimal suffix tree construction with large alphabets. In38th Annual Symposium on Foundations of Computer Science, FOCS 1997, Miami Beach, Florida, USA, October 19-22, 1997, pages 137–143. IEEE Computer Society, 1997.doi:10.1109/SFCS.1997.646102
-
[7]
Universal reconstruction of a string.Theor
Pawel Gawrychowski, Tomasz Kociumaka, Jakub Radoszewski, Wojciech Rytter, and Tomasz Walen. Universal reconstruction of a string.Theor. Comput. Sci., 812:174–186, 2020. URL:https://doi.org/ 10.1016/j.tcs.2019.10.027,doi:10.1016/J.TCS.2019.10.027
-
[8]
At the roots of dictionary compression: String attractors
Dominik Kempa and Nicola Prezza. At the roots of dictionary compression: String attractors. In Ilias Diakonikolas, David Kempe, and Monika Henzinger, editors,Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, STOC 2018, Los Angeles, CA, USA, June 25-29, 2018, pages 827–840. ACM, 2018.doi:10.1145/3188745.3188814. 9
-
[9]
A linear-time algorithm for seeds computation.ACM Trans
Tomasz Kociumaka, Marcin Kubica, Jakub Radoszewski, Wojciech Rytter, and Tomasz Walen. A linear-time algorithm for seeds computation.ACM Trans. Algorithms, 16(2):27:1–27:23, 2020.doi: 10.1145/3386369
-
[10]
Towards a definitive measure of repetitiveness
Tomasz Kociumaka, Gonzalo Navarro, and Nicola Prezza. Towards a definitive measure of repetitiveness. In Yoshiharu Kohayakawa and Fl´ avio Keidi Miyazawa, editors,LATIN 2020: Theoretical Informatics - 14th Latin American Symposium, S˜ ao Paulo, Brazil, January 5-8, 2021, Proceedings, volume 12118 of Lecture Notes in Computer Science, pages 207–219. Spring...
-
[11]
On repetitiveness measures of thue-morse words
Kanaru Kutsukake, Takuya Matsumoto, Yuto Nakashima, Shunsuke Inenaga, Hideo Bannai, and Masayuki Takeda. On repetitiveness measures of thue-morse words. In Christina Boucher and Sharma V. Thankachan, editors,String Processing and Information Retrieval - 27th International Symposium, SPIRE 2020, Orlando, FL, USA, October 13-15, 2020, Proceedings, Lecture N...
-
[12]
Indexing highly repetitive string collections, part I: repetitiveness measures.ACM Comput
Gonzalo Navarro. Indexing highly repetitive string collections, part I: repetitiveness measures.ACM Comput. Surv., 54(2):29:1–29:31, 2022.doi:10.1145/3434399
-
[13]
On the approximation ratio of ordered parsings
Gonzalo Navarro, Carlos Ochoa, and Nicola Prezza. On the approximation ratio of ordered parsings. IEEE Trans. Inf. Theory, 67(2):1008–1026, 2021.doi:10.1109/TIT.2020.3042746
-
[14]
Smallest suffixient sets as a repetitiveness measure
Gonzalo Navarro, Giuseppe Romana, and Cristian Urbina. Smallest suffixient sets as a repetitiveness measure. In Golnaz Badkobeh, Jakub Radoszewski, Nicola Tonellotto, and Ricardo Baeza-Yates, editors, String Processing and Information Retrieval - 32nd International Symposium, SPIRE 2025, London, UK, September 8-11, 2025, Proceedings, volume 16073 ofLectur...
-
[15]
James A. Storer and Thomas G. Szymanski. The macro model for data compression (extended abstract). In Richard J. Lipton, Walter A. Burkhard, Walter J. Savitch, Emily P. Friedman, and Alfred V. Aho, editors,Proceedings of the 10th Annual ACM Symposium on Theory of Computing, May 1-3, 1978, San Diego, California, USA, pages 30–39. ACM, 1978.doi:10.1145/8001...
-
[16]
A universal algorithm for sequential data compression.IEEE Trans
Jacob Ziv and Abraham Lempel. A universal algorithm for sequential data compression.IEEE Trans. Inf. Theory, 23(3):337–343, 1977.doi:10.1109/TIT.1977.1055714. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.