Adaptive LSQR Preconditioning from One Small Sketch
Pith reviewed 2026-05-10 18:53 UTC · model grok-4.3
The pith
One small sketch computed once enables an adaptive preconditioner that refines itself during iterations for large least-squares problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
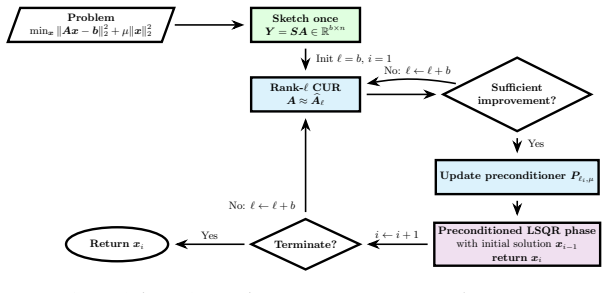
The paper shows that a CUR-based preconditioner started from a single small sketch can be improved incrementally by interleaving its updates with the steps of the Krylov solver, and that the resulting convergence guarantees do not depend on the sketch size even for general matrices.
What carries the argument
The incrementally refined CUR-based preconditioner initialized from one small sketch and updated during the solve.
Load-bearing premise
A single small sketch computed at the start is enough to support incremental refinement of the preconditioner that keeps convergence guarantees independent of the sketch size for any general matrix.
What would settle it
A counterexample where reducing the sketch size below 250 causes a clear increase in iteration count or loss of convergence for a standard general matrix would show the claim does not hold.
Figures















read the original abstract
We propose APLICUR, an adaptive preconditioning framework for large-scale linear least-squares (LLS) problems. Using a single small sketch computed once at initialization, APLICUR incrementally refines a CUR-based preconditioner throughout the Krylov solve, interleaving preconditioning with iteration. This enables early convergence without the need to construct a costly high-quality preconditioner upfront. With a modest sketch dimension (typically 5 - 250), largely independent of both the problem size and numerical rank, APLICUR achieves convergence guarantees that are likewise independent of the sketch size. The method is applicable to general matrices without structural assumptions (e.g. need not be heavily overdetermined) and is well suited to large, sparse, or numerically low-rank problems. We conduct extensive numerical studies to examine the behavior of the proposed framework and guide the effective algorithmic design choices. Across a range of test problems, \mainalg{} achieves competitive or improved time-to-accuracy performance compared with established randomized preconditioners, including Blendenpik and Nystr\"om PCG, while maintaining low setup cost and robustness across problem regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes APLICUR, an adaptive preconditioning framework for large-scale linear least-squares problems. Using a single small sketch computed once at initialization, it incrementally refines a CUR-based preconditioner throughout the LSQR Krylov iterations. The central claim is that modest sketch dimensions (typically 5-250), largely independent of problem size and numerical rank, yield convergence guarantees likewise independent of sketch size for general matrices without structural assumptions, while delivering competitive time-to-accuracy versus Blendenpik and Nyström PCG in extensive numerical studies.
Significance. If the sketch-size-independent convergence guarantees are rigorously established, the work would represent a practical advance for randomized preconditioning of least-squares problems, emphasizing low setup cost and robustness for large, sparse, or numerically low-rank matrices. The extensive numerical studies and broad applicability without strong assumptions on A are notable strengths.
major comments (2)
- [Abstract] Abstract: The headline claim of convergence guarantees independent of sketch size is load-bearing. Standard CUR error bounds scale with sketch dimension s and singular-value gaps, yet the abstract asserts that the single-sketch adaptive CUR refinement cancels this dependence for arbitrary matrices. No explicit theorem isolating an s-independent iteration bound is referenced; the analysis must demonstrate that incremental updates from the fixed sketch preserve the claimed rate without additional assumptions on A.
- The weakest link is the assumption that one small sketch computed at initialization suffices for on-the-fly CUR factor updates interleaved with LSQR to maintain the s-independent guarantees throughout the solve. If a supporting theorem or derivation exists, it should be stated clearly with the precise conditions under which the preconditioner quality becomes independent of s; otherwise the numerical studies alone cannot establish the guarantee for general matrices.
minor comments (2)
- The acronym APLICUR should be expanded on first use in the abstract or introduction.
- Numerical studies would be strengthened by a dedicated table or plot of iteration counts versus sketch size (holding other parameters fixed) to directly illustrate the claimed independence.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the sketch-size-independent convergence claim is central and requires explicit theoretical support. We have revised the manuscript to strengthen the references to the relevant theorems, clarify the conditions, and add a dedicated subsection on the independence from sketch size. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of convergence guarantees independent of sketch size is load-bearing. Standard CUR error bounds scale with sketch dimension s and singular-value gaps, yet the abstract asserts that the single-sketch adaptive CUR refinement cancels this dependence for arbitrary matrices. No explicit theorem isolating an s-independent iteration bound is referenced; the analysis must demonstrate that incremental updates from the fixed sketch preserve the claimed rate without additional assumptions on A.
Authors: We agree that an explicit reference is needed. Theorem 3.1 (Section 3) establishes the LSQR convergence bound under the adaptive CUR preconditioner and isolates the iteration count as independent of s. The proof proceeds by showing that each interleaved update reduces the effective preconditioner error in the directions spanned by the current Krylov subspace, using only the fixed initial sketch; the s-dependence that appears in static CUR bounds is canceled by the adaptive refinement. No further assumptions on A are required beyond it being a general real matrix. We have added a direct citation to Theorem 3.1 in the abstract and expanded the introduction to state the precise conditions. revision: yes
-
Referee: [—] The weakest link is the assumption that one small sketch computed at initialization suffices for on-the-fly CUR factor updates interleaved with LSQR to maintain the s-independent guarantees throughout the solve. If a supporting theorem or derivation exists, it should be stated clearly with the precise conditions under which the preconditioner quality becomes independent of s; otherwise the numerical studies alone cannot establish the guarantee for general matrices.
Authors: The supporting derivation appears in the proof of Theorem 3.1 together with Lemma 3.3. The single sketch initializes the CUR factors; subsequent updates are formed by projecting the current LSQR residual onto the sketch and adjusting the C and R factors accordingly. This process keeps the preconditioner quality improving (rather than degrading) with iteration count, yielding an s-independent bound on the number of LSQR steps needed for a prescribed accuracy. The only explicit condition is that the sketch dimension exceeds the numerical rank by a modest oversampling factor (standard for range approximation); once this holds, the iteration bound itself does not grow with s. We have added a new subsection 3.4 that isolates this argument and states the minimal sketch-size requirement explicitly. The numerical experiments are presented only as corroboration, not as the primary evidence. revision: yes
Circularity Check
No circularity: new adaptive CUR-LSQR construction with independent guarantees
full rationale
The paper introduces APLICUR as a novel framework that computes one fixed small sketch at initialization and then interleaves incremental CUR updates with LSQR iterations. Convergence bounds are asserted to hold independently of sketch dimension s for general matrices, derived from the adaptive refinement mechanism rather than by redefining any quantity in terms of itself or by fitting parameters to the target rate. No self-citation chain is invoked to establish uniqueness or to smuggle an ansatz; the central claim rests on the explicit construction and its analysis, which the abstract presents as holding without structural assumptions on A. Numerical experiments are used only for validation, not as the source of the claimed s-independence. This is the standard case of a self-contained algorithmic derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Properties of random sketches and CUR decompositions from prior randomized numerical linear algebra hold for the initial sketch and incremental updates.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
With a modest sketch dimension (typically 5–250), largely independent of both the problem size and numerical rank, APLICUR achieves convergence guarantees that are likewise independent of the sketch size.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We establish bounds on the condition number and convergence rate of the preconditioned system that depend on the CUR approximation quality, but not on the sketch dimension.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
N. Ailon and B. Chazelle, The fast Johnson–Lindenstrauss transform and approximate near- est neighbors, SIAM J. Comput., 39 (2009), pp. 302–322
work page 2009
-
[2]
A. Alaoui and M. W. Mahoney , Fast randomized kernel ridge regression with statistical guarantees, Adv. Neural Inf. Process. Syst., 28 (2015)
work page 2015
-
[3]
S. F. Ashby, Polynomial preconditioning for conjugate gradient methods, University of Illinois at Urbana-Champaign, 1988
work page 1988
- [4]
-
[5]
Balabanov , Randomized Cholesky QR factorizations , arXiv preprint arXiv:2210.09953, (2022)
O. Balabanov , Randomized Cholesky QR factorizations , arXiv preprint arXiv:2210.09953, (2022)
-
[6]
S. Barthelm´e and K. Usevich , Spectral properties of kernel matrices in the flat limit , SIAM J. Matrix Anal. Appl., 42 (2021), pp. 17–57. 28
work page 2021
- [7]
-
[8]
Benzi, Preconditioning techniques for large linear systems: a survey , J
M. Benzi, Preconditioning techniques for large linear systems: a survey , J. Comput. Phys., 182 (2002), pp. 418–477
work page 2002
-
[9]
M. Benzi and M. T˘uma, A robust incomplete factorization preconditioner for positive definite matrices, Numer. Lin. Alg. Appl., 10 (2003), pp. 385–400
work page 2003
-
[10]
Bj¨orck, Numerical Methods for Least Squares Problems , SIAM, 1996
˚A. Bj¨orck, Numerical Methods for Least Squares Problems , SIAM, 1996
work page 1996
-
[11]
C. Boutsidis, P. Drineas, and M. Magdon-Ismail , Near-optimal column-based matrix re- construction, SIAM J. Comput., 43 (2014), pp. 687–717
work page 2014
- [12]
- [13]
- [14]
-
[15]
J. Chiu and L. Demanet, Sublinear randomized algorithms for skeleton decompositions, SIAM J. Matrix Anal. Appl., 34 (2013), pp. 1361–1383
work page 2013
-
[16]
K. L. Clarkson and D. P. Woodruff , Low-rank approximation and regression in input sparsity time, J. ACM, 63 (2017), pp. 1–45
work page 2017
-
[17]
M. B. Cohen, Nearly tight oblivious subspace embeddings by trace inequalities , in Proc. ACM- SIAM Sympos. Discrete Alg., SIAM, 2016, pp. 278–287
work page 2016
-
[18]
A. Cortinovis and D. Kressner, Low-rank approximation in the Frobenius norm by column and row subset selection , SIAM J. Matrix Anal. Appl., 41 (2020), pp. 1651–1673
work page 2020
-
[19]
O. Coulaud, L. Giraud, P. Ramet, and X. Vasseur , Deflation and augmentation tech- niques in Krylov subspace methods for the solution of linear systems , arXiv preprint arXiv:1303.5692, (2013)
-
[20]
K. Cutajar, M. Osborne, J. Cunningham, and M. Filippone , Preconditioning kernel ma- trices, in Proc. Int. Conf. Mach. Learn., vol. 48, PMLR, 2016, pp. 2529–2538
work page 2016
-
[21]
C. Daskalakis, P. Dellaportas, and A. Panos , How good are low-rank approximations in Gaussian process regression?, in Proc. AAAI Conf. Artif. Intell., vol. 36, 2022, pp. 6463– 6470
work page 2022
-
[22]
M. Derezinski and M. W. Mahoney, Determinantal point processes in randomized numerical linear algebra, Notices Am. Math. Soc., 68 (2021), pp. 34–45
work page 2021
-
[23]
M. Derezi´nski, C. Musco, and J. Yang , Faster linear systems and matrix norm approxima- tion via multi-level sketched preconditioning , in Proc. ACM-SIAM Sympos. Discrete Alg., SIAM, 2025, pp. 1972–2004
work page 2025
-
[24]
M. Derezi´nski and J. Yang, Solving dense linear systems faster than via preconditioning , in Proc. ACM Sympos. Theory Comput., 2024, pp. 1118–1129
work page 2024
-
[25]
A. Deshpande and L. Rademacher , Efficient volume sampling for row/column subset selec- tion, in Proc. IEEE Sympos. Found. Comput. Sci., IEEE, 2010, pp. 329–338
work page 2010
-
[26]
A. Deshpande, L. Rademacher, S. S. Vempala, and G. Wang , Matrix approximation and projective clustering via volume sampling , Theory Comput., 2 (2006), pp. 225–247
work page 2006
- [27]
-
[28]
Y. Dong and P.-G. Martinsson, Simpler is better: A comparative study of randomized pivot- ing algorithms for CUR and interpolative decompositions, Adv. Comput. Math., 49 (2023), p. 66
work page 2023
-
[29]
P. Drineas and M. W. Mahoney, RandNLA: Randomized numerical linear algebra, Commun. ACM, 59 (2016), pp. 80–90
work page 2016
-
[30]
P. Drineas, M. W. Mahoney, and S. Muthukrishnan , Relative-error CUR matrix decom- positions, SIAM J. Matrix Anal. Appl., 30 (2008), pp. 844–881
work page 2008
-
[31]
J. A. Duersch and M. Gu , Randomized projection for rank-revealing matrix factorizations and low-rank approximations, SIAM Review, 62 (2020), pp. 661–682
work page 2020
-
[32]
C. Eckart and G. Young , The approximation of one matrix by another of lower rank , Psy- chometrika, 1 (1936), pp. 211–218
work page 1936
-
[33]
M. Eiermann, W. Niethammer, and R. S. Varga , A study of semiiterative methods for nonsymmetric systems of linear equations , Numer. Math., 47 (1985), pp. 505–533
work page 1985
- [34]
-
[35]
E. N. Epperly, M. Meier, and Y. Nakatsukasa , Fast randomized least-squares solvers can be just as accurate and stable as classical direct solvers , Comm. Pure Appl. Math., 79 29 (2026), pp. 293–339
work page 2026
-
[36]
Fischer, Polynomial Based Iteration Methods for Symmetric Linear Systems , SIAM, 2011
B. Fischer, Polynomial Based Iteration Methods for Symmetric Linear Systems , SIAM, 2011
work page 2011
-
[37]
Z. Frangella, J. A. Tropp, and M. Udell , Randomized Nystr¨ om preconditioning, SIAM J. Matrix Anal. Appl., 44 (2023), pp. 718–752
work page 2023
- [38]
-
[39]
A. Gaul, M. H. Gutknecht, J. Liesen, and R. Nabben , A framework for deflated and augmented Krylov subspace methods, SIAM J. Matrix Anal. Appl., 34 (2013), pp. 495–518
work page 2013
-
[40]
T. Gergelits and Z. Strakoˇs, Composite convergence bounds based on Chebyshev polynomi- als and finite precision conjugate gradient computations , Numer. Algorithms, 65 (2014), pp. 759–782
work page 2014
-
[41]
G. H. Golub and C. F. Van Loan , Matrix computations, JHU press, 2013
work page 2013
- [42]
- [43]
-
[44]
M. H. Gutknecht , Spectral deflation in Krylov solvers: A theory of coordinate space based methods, Electron. Trans. Numer. Anal, 39 (2012), pp. 156–185
work page 2012
-
[45]
N. Halko, P.-G. Martinsson, and J. A. Tropp , Finding structure with randomness: Proba- bilistic algorithms for constructing approximate matrix decompositions , SIAM Review, 53 (2011), pp. 217–288
work page 2011
-
[46]
M. R. Hestenes, E. Stiefel, et al., Methods of conjugate gradients for solving linear systems, J. Res. Natl. Bur. Stand., 49 (1952), pp. 409–436
work page 1952
-
[47]
Y. P. Hong and C.-T. Pan , Rank-revealing QR factorizations and the singular value decom- position, Math. Comp., 58 (1992), pp. 213–232
work page 1992
- [48]
-
[49]
P. Indyk and R. Motwani , Approximate nearest neighbors: towards removing the curse of dimensionality, in Proc. ACM Sympos. Theory Comput., 1998, pp. 604–613
work page 1998
-
[50]
D. M. Kane and J. Nelson , Sparser Johnson-Lindenstrauss transforms, J. ACM, 61 (2014), pp. 1–23
work page 2014
-
[51]
J. Lacotte and M. Pilanci , Effective dimension adaptive sketching methods for faster regu- larized least-squares optimization , Adv. Neural Inf. Process. Syst., 33 (2020), pp. 19377– 19387
work page 2020
-
[52]
E. Liberty, F. Woolfe, P.-G. Martinsson, V. Rokhlin, and M. Tygert , Randomized algorithms for the low-rank approximation of matrices , Proc. Natl. Acad. Sci., 104 (2007), pp. 20167–20172
work page 2007
-
[53]
D. G. Luenberger , Introduction to Linear and Nonlinear Programming , Addison-Wesley, 1973
work page 1973
-
[54]
M. W. Mahoney and P. Drineas , CUR matrix decompositions for improved data analysis , Proc. Natl. Acad. Sci., 106 (2009), pp. 697–702
work page 2009
-
[55]
M. W. Mahoney et al., Randomized algorithms for matrices and data , Found. Trends Mach. Learn., 3 (2011), pp. 123–224
work page 2011
-
[56]
P.-G. Martinsson and J. A. Tropp , Randomized numerical linear algebra: Foundations and algorithms, Acta Numer., 29 (2020), pp. 403–572
work page 2020
-
[57]
M. Meier and Y. Nakatsukasa, Fast randomized numerical rank estimation for numerically low-rank matrices, Linear Algebra Appl., 686 (2024), pp. 1–32
work page 2024
-
[58]
X. Meng and M. W. Mahoney , Low-distortion subspace embeddings in input-sparsity time and applications to robust linear regression, in Proc. ACM Sympos. Theory Comput., 2013, pp. 91–100
work page 2013
-
[59]
X. Meng, M. A. Saunders, and M. W. Mahoney , LSRN: A parallel iterative solver for strongly over-or underdetermined systems , SIAM J. Sci. Comput., 36 (2014), pp. C95– C118
work page 2014
-
[60]
Y. Nakatsukasa, Fast and stable randomized low-rank matrix approximation , arXiv preprint arXiv:2009.11392, (2020)
-
[61]
J. Nelson and H. L. Nguyˆen, OSNAP: Faster numerical linear algebra algorithms via sparser subspace embeddings, in Proc. IEEE Sympos. Found. Comput. Sci., IEEE, 2013, pp. 117– 126
work page 2013
-
[62]
D. Oglic and T. G ¨artner, Nystr¨ om method with kernel k-means++ samples as landmarks, in Proc. Int. Conf. Mach. Learn., PMLR, 2017, pp. 2652–2660. 30
work page 2017
-
[63]
A. I. Osinsky , Close to optimal column approximation using a single SVD , Linear Algebra Appl., 725 (2025), pp. 359–377
work page 2025
-
[64]
C. C. Paige and M. A. Saunders, LSQR: An algorithm for sparse linear equations and sparse least squares, ACM Trans. Math. Soft., 8 (1982), pp. 43–71
work page 1982
-
[65]
C.-T. Pan, On the existence and computation of rank-revealing LU factorizations , Linear Al- gebra Appl., 316 (2000), pp. 199–222
work page 2000
-
[66]
T. Park and Y. Nakatsukasa, Accuracy and stability of CUR decompositions with oversam- pling, SIAM J. Matrix Anal. Appl., 46 (2025), pp. 780–810
work page 2025
-
[67]
N. Pritchard, T. Park, Y. Nakatsukasa, and P.-G. Martinsson, Fast rank adaptive CUR via a recycled small sketch , arXiv preprint arXiv:2509.21963, (2025)
-
[68]
V. Rokhlin and M. Tygert , A fast randomized algorithm for overdetermined linear least- squares regression, Proc. Natl. Acad. Sci., 105 (2008), pp. 13212–13217
work page 2008
-
[69]
K. Schiefermayr, Estimates for the asymptotic convergence factor of two intervals , arXiv preprint arXiv:1306.5866, (2013)
-
[70]
D. C. Sorensen and M. Embree, A DEIM induced CUR factorization, SIAM J. Sci. Comput., 38 (2016), pp. A1454–A1482
work page 2016
-
[71]
G. W. Stewart, Matrix Algorithms, SIAM, 1998
work page 1998
-
[72]
L. N. Trefethen and D. Bau , Numerical linear algebra, SIAM, 2022
work page 2022
-
[73]
J. A. Tropp , Improved analysis of the subsampled randomized Hadamard transform , Adv. Adapt. Data Anal., 3 (2011), pp. 115–126
work page 2011
-
[74]
J. A. Tropp, A. Yurtsever, M. Udell, and V. Cevher , Practical sketching algorithms for low-rank matrix approximation, SIAM J. Matrix Anal. Appl., 38 (2017), pp. 1454–1485
work page 2017
-
[75]
J. A. Tropp, A. Yurtsever, M. Udell, and V. Cevher , Streaming low-rank matrix approx- imation with an application to scientific simulation , SIAM J. Sci. Comput., 41 (2019), pp. A2430–A2463
work page 2019
-
[76]
S. Voronin and P.-G. Martinsson , Efficient algorithms for CUR and interpolative matrix decompositions, Adv. Comput. Math., 43 (2017), pp. 495–516
work page 2017
-
[77]
D. P. Woodruff et al. , Sketching as a tool for numerical linear algebra , Found. Trends Theor. Comput. Sci., 10 (2014), pp. 1–157
work page 2014
- [78]
-
[79]
N. Zamarashkin and A. Osinsky, On the existence of a nearly optimal skeleton approximation of a matrix in the Frobenius norm , in Dokl. Math., vol. 97, Springer, 2018, pp. 164–166
work page 2018
-
[80]
S. Zhao, T. Xu, H. Huang, E. Chow, and Y. Xi , An adaptive factorized Nystr¨ om precondi- tioner for regularized kernel matrices, SIAM J. Sci. Comput., 46 (2024), pp. A2351–A2376. Appendix A. Proofs. This appendix provides proofs of the theoretical results supporting the main text A.1. Proof of Theorem 4.1. Proof. We first analyze the idealized system bas...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.