Recognition: no theorem link
Semantic Trimming and Auxiliary Multi-step Prediction for Generative Recommendation
Pith reviewed 2026-05-10 19:44 UTC · model grok-4.3
The pith
STAMP trims redundant semantic tokens and adds multi-step predictions to speed up generative recommendation training while cutting memory use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STAMP shows that effective semantic-ID learning requires joint treatment of low input density and sparse output supervision: Semantic Adaptive Pruning converts noise-laden sequences into compact representations during the forward pass, while Multi-step Auxiliary Prediction densifies the learning signal to strengthen long-range dependency capture, yielding both lower training overhead and more reliable performance.
What carries the argument
Semantic Adaptive Pruning (SAP), which dynamically filters redundant tokens in the forward pass, paired with Multi-step Auxiliary Prediction (MAP), which replaces single-token objectives with multi-token supervision to amplify feedback density.
If this is right
- Sequence lengths shrink during training, directly lowering both compute time and peak VRAM.
- Multi-token objectives supply denser gradients, reducing non-monotonic accuracy swings.
- The same dual strategy works across different backbone architectures without architecture-specific redesign.
- Higher-granularity semantic IDs become practical because the dilution penalty is removed.
- Industrial-scale datasets exhibit the same efficiency gains observed on public benchmarks.
Where Pith is reading between the lines
- Similar input-trimming plus auxiliary-objective pairs could be tested on other long-sequence generative tasks that suffer token redundancy.
- The method might enable online adaptation of semantic granularity during training rather than fixing it in advance.
- If the pruning decisions prove stable across random seeds, they could be pre-computed once and reused for multiple recommendation heads.
Load-bearing premise
Redundant semantic tokens act mainly as noise whose removal leaves critical item information intact and whose presence is the root cause of both overhead and accuracy fluctuations.
What would settle it
Train an identical semantic-ID model with and without the proposed pruning step on the same Amazon dataset split; if the pruned version shows a statistically significant drop in NDCG@10 or Recall@10 relative to the unpruned baseline, the claim that pruning discards only noise is falsified.
Figures








read the original abstract
Generative Recommendation (GR) has recently transitioned from atomic item-indexing to Semantic ID (SID)-based frameworks to capture intrinsic item relationships and enhance generalization. However, the adoption of high-granularity SIDs leads to two critical challenges: prohibitive training overhead due to sequence expansion and unstable performance reliability characterized by non-monotonic accuracy fluctuations. We identify that these disparate issues are fundamentally rooted in the Semantic Dilution Effect, where redundant tokens waste massive computation and dilute the already sparse learning signals in recommendation. To counteract this, we propose STAMP (Semantic Trimming and Auxiliary Multi-step Prediction), a framework utilizing a dual-end optimization strategy. We argue that effective SID learning requires simultaneously addressing low input information density and sparse output supervision. On the input side, Semantic Adaptive Pruning (SAP) dynamically filters redundancy during the forward pass, converting noise-laden sequences into compact, information-rich representations. On the output side, Multi-step Auxiliary Prediction (MAP) employs a multi-token objective to densify feedback, strengthening long-range dependency capture and ensuring robust learning signals despite compressed inputs. Unifying input purification and signal amplification, STAMP enhances both training efficiency and representation capability. Experiments on public Amazon and large-scale industrial datasets show STAMP achieves 1.23--1.38$\times$ speedup and 17.2\%--54.7\% VRAM reduction while maintaining or improving performance across multiple architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STAMP, a framework for generative recommendation systems based on Semantic IDs (SIDs). It posits that the Semantic Dilution Effect causes both high training overhead from sequence expansion and unstable performance in high-granularity SID setups. The proposed solution combines Semantic Adaptive Pruning (SAP) to dynamically trim redundant tokens in the input during the forward pass and Multi-step Auxiliary Prediction (MAP) to provide denser supervision signals on the output side. The authors report that this dual approach leads to 1.23-1.38× training speedup and 17.2%-54.7% VRAM savings on Amazon and industrial datasets while maintaining or improving recommendation performance across various architectures.
Significance. If the central claims hold under rigorous validation, this work could meaningfully advance the practicality of SID-based generative recommenders by reducing compute and memory demands in large-scale training without accuracy trade-offs. The dual strategy of input purification via dynamic pruning and output signal densification via auxiliary prediction is a coherent response to the identified challenges. Strengths include the explicit linkage of efficiency gains to sequence compression and the use of both public and industrial datasets.
major comments (2)
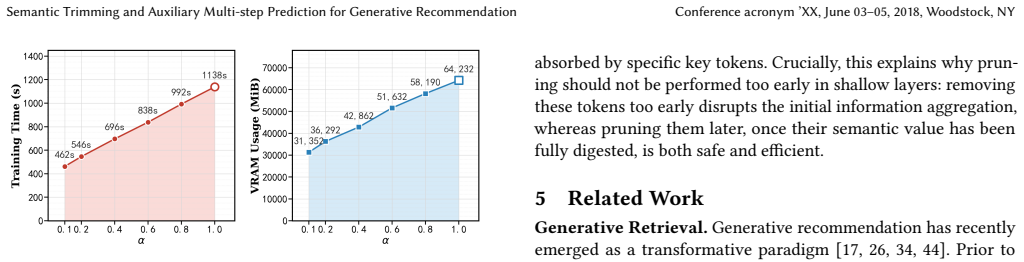
- [§3.1] §3.1 (Semantic Adaptive Pruning): The pruning criterion is described as attention-based and dynamic, but the manuscript does not demonstrate that the learned or heuristic threshold prioritizes predictive utility over token frequency. If pruning correlates with frequency, low-frequency discriminative tokens for tail items could be removed, directly undermining the 'maintains or improves performance' claim that underpins the reported 1.23–1.38× speedup and VRAM reductions.
- [Experiments section] Experiments section, performance tables and ablations: Overall metrics are reported, but there are no frequency-stratified results (head vs. tail items), sequence-length breakdowns, or ablation on pruning aggressiveness. This is load-bearing because the efficiency numbers derive from shorter pruned sequences; without these checks, it remains possible that gains come at the cost of hidden regressions on subsets, falsifying the joint efficiency-quality claim.
minor comments (2)
- [Introduction] The term 'Semantic Dilution Effect' is introduced as a root cause but lacks a formal definition or quantitative measure (e.g., an equation for dilution as a function of sequence length or token entropy); this makes it harder to compare against prior sequence-length analyses in transformer-based recommenders.
- Notation for multipliers in the abstract (1.23--1.38×) should be consistently rendered in the main text and tables; also ensure all baselines are cited with exact references and hyperparameter settings for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and commit to revisions that strengthen the empirical validation of our claims.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Semantic Adaptive Pruning): The pruning criterion is described as attention-based and dynamic, but the manuscript does not demonstrate that the learned or heuristic threshold prioritizes predictive utility over token frequency. If pruning correlates with frequency, low-frequency discriminative tokens for tail items could be removed, directly undermining the 'maintains or improves performance' claim that underpins the reported 1.23–1.38× speedup and VRAM reductions.
Authors: We agree that explicit validation of the pruning criterion is important. SAP computes token importance via attention weights produced by the model during the forward pass; these weights are task-optimized and context-dependent rather than static frequency counts. Consequently, a low-frequency token that is highly relevant to the current user sequence can receive high attention and be retained. To directly address the referee’s concern, we will add (i) a quantitative analysis of the correlation between pruning decisions and token frequency and (ii) qualitative examples of retained versus pruned tokens for tail items in the revised manuscript. revision: yes
-
Referee: [Experiments section] Experiments section, performance tables and ablations: Overall metrics are reported, but there are no frequency-stratified results (head vs. tail items), sequence-length breakdowns, or ablation on pruning aggressiveness. This is load-bearing because the efficiency numbers derive from shorter pruned sequences; without these checks, it remains possible that gains come at the cost of hidden regressions on subsets, falsifying the joint efficiency-quality claim.
Authors: We acknowledge that the current experimental section relies on aggregate metrics. While these aggregates already include tail items and show maintained or improved performance, we will add the requested breakdowns in the revision: (a) head versus tail item performance stratification, (b) accuracy and efficiency as functions of original sequence length, and (c) ablation tables varying the pruning aggressiveness (different attention thresholds). These additions will confirm that efficiency gains do not mask regressions on any subset. revision: yes
Circularity Check
No significant circularity; empirical engineering proposal with independent experimental validation
full rationale
The paper presents STAMP as a practical framework combining Semantic Adaptive Pruning (SAP) and Multi-step Auxiliary Prediction (MAP) to mitigate the Semantic Dilution Effect in SID-based generative recommendation. No equations, derivations, or first-principles results are shown that reduce claimed speedups or performance gains to quantities defined by fitted parameters or self-referential inputs. The central claims rest on experimental results across public and industrial datasets rather than closed-form identities or load-bearing self-citations. The derivation chain is self-contained as an applied engineering solution without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang
-
[2]
InProceedings of the Computer Vision and Pattern Recognition Conference
Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference. 9392–9401
- [3]
-
[4]
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichten- hofer, and Judy Hoffman. 2022. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461(2022)
work page internal anchor Pith review arXiv 2022
-
[5]
Lei Chen, Chen Gao, Xiaoyi Du, Hengliang Luo, Depeng Jin, Yong Li, and Meng Wang. 2025. Enhancing ID-based recommendation with large language models. ACM Transactions on Information Systems43, 5 (2025), 1–30
2025
-
[6]
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, and Jiawei Chen. 2024. Distillation matters: empowering sequential recommenders to match the performance of large language models. InProceedings of the 18th ACM Conference on Recommender Systems. 507–517
2024
-
[7]
Shuangrui Ding, Peisen Zhao, Xiaopeng Zhang, Rui Qian, Hongkai Xiong, and Qi Tian. 2023. Prune spatio-temporal tokens by semantic-aware temporal accu- mulation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 16945–16956
2023
-
[8]
Xinyan Fan, Zheng Liu, Jianxun Lian, Wayne Xin Zhao, Xing Xie, and Ji-Rong Wen. 2021. Lighter and better: low-rank decomposed self-attention networks for next-item recommendation. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 1733–1737
2021
-
[9]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Kairui Fu, Tao Zhang, Shuwen Xiao, Ziyang Wang, Xinming Zhang, Chenchi Zhang, Yuliang Yan, Junjun Zheng, Yu Li, Zhihong Chen, Jian Wu, Xiangheng Kong, Shengyu Zhang, Kun Kuang, Yuning Jiang, and Bo Zheng. 2025. FORGE: Forming Semantic Identifiers for Generative Retrieval in Industrial Datasets. arXiv:2509.20904 [cs.IR] https://arxiv.org/abs/2509.20904
-
[11]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quantization.IEEE transactions on pattern analysis and machine intelligence36, 4 (2013), 744–755
2013
-
[12]
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. 2024. Better & faster large language models via multi-token prediction. InProceedings of the 41st International Conference on Machine Learning. 15706–15734
2024
- [13]
-
[14]
Zhiyu Guo, Hidetaka Kamigaito, and Taro Watanabe. 2024. Attention Score is not All You Need for Token Importance Indicator in KV Cache Reduction: Value Also Matters. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 21158–21166
2024
-
[15]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[16]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating long semantic ids in parallel for recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 956–966
2025
-
[17]
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. 2025. Generative Recommendation with Seman- tic IDs: A Practitioner’s Handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM)
2025
-
[18]
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, and Chanyoung Park. 2024. Large language models meet collaborative filtering: An efficient all-round llm-based recommender system. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1395–1406
2024
-
[19]
Sehoon Kim, Sheng Shen, David Thorsley, Amir Gholami, Woosuk Kwon, Joseph Hassoun, and Kurt Keutzer. 2022. Learned token pruning for transformers. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 784–794
2022
-
[20]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11523–11532
2022
- [21]
-
[22]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, Zhiyang Zhang, Yu Zhou, Guoping Tang, Yiqing Yang, Chengcheng Guo, Si Dong, Kuo Cai, Pengyue Jia, Maolin Wang, Wanyu Wang, Shiyao Wang, Xinchen Luo, Qigen Hu, Qiang Luo, Xiao Lv, Chaoyi Ma, Ruiming Tang, Kun Gai, Guorui Zhou, and Xiangyu Zhao. 202...
-
[23]
Zida Liang, Changfa Wu, Dunxian Huang, Weiqiang Sun, Ziyang Wang, Yuliang Yan, Jian Wu, Yuning Jiang, Bo Zheng, Ke Chen, et al. 2025. Tbgrecall: A generative retrieval model for e-commerce recommendation scenarios. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5863–5870
2025
-
[24]
Jianghao Lin, Xinyi Dai, Rong Shan, Bo Chen, Ruiming Tang, Yong Yu, and Weinan Zhang. 2025. Large language models make sample-efficient recommender systems.Frontiers of Computer Science19, 4 (2025), 194328
2025
-
[25]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: Activation-aware weight quantization for on-device llm compression and accel- eration.Proceedings of machine learning and systems6 (2024), 87–100
2024
-
[26]
Xinyu Lin, Haihan Shi, Wenjie Wang, Fuli Feng, Qifan Wang, See-Kiong Ng, and Tat-Seng Chua. 2025. Order-agnostic identifier for large language model-based generative recommendation. InProceedings of the 48th international ACM SIGIR conference on research and development in information retrieval. 1923–1933
2025
-
[27]
Xinyu Lin, Wenjie Wang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua
-
[28]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Bridging items and language: A transition paradigm for large language model-based recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1816–1826
- [29]
-
[30]
Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, Weizhu Chen, et al. 2024. Not all tokens are what you need for pretraining.Advances in Neural Information Processing Systems37 (2024), 29029–29063
2024
-
[31]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao
-
[33]
InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Generative recommender with end-to-end learnable item tokenization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 729–739
- [34]
-
[35]
Langming Liu, Liu Cai, Chi Zhang, Xiangyu Zhao, Jingtong Gao, Wanyu Wang, Yifu Lv, Wenqi Fan, Yiqi Wang, Ming He, et al. 2023. Linrec: Linear attention mechanism for long-term sequential recommender systems. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 289–299
2023
- [36]
-
[39]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[40]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[41]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh
-
[42]
Advances in neural information processing systems34 (2021), 13937–13949
Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems34 (2021), 13937–13949
2021
-
[43]
Yankun Ren, Zhongde Chen, Xinxing Yang, Longfei Li, Cong Jiang, Lei Cheng, Bo Zhang, Linjian Mo, and Jun Zhou. 2024. Enhancing sequential recommenders with augmented knowledge from aligned large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 345–354
2024
-
[44]
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. 2025. Llava- prumerge: Adaptive token reduction for efficient large multimodal models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22857– 22867
2025
-
[45]
Wenqi Sun, Ruobing Xie, Junjie Zhang, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2024. Distillation is all you need for practically using different pre-trained recommendation models.CoRR(2024)
2024
-
[46]
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, and Yongfeng Zhang. 2024. Idgenrec: Llm-recsys alignment with textual id learning. InProceed- ings of the 47th international ACM SIGIR conference on research and development in information retrieval. 355–364
2024
-
[47]
Dongsheng Wang, Yuxi Huang, Shen Gao, Yifan Wang, Chengrui Huang, and Shuo Shang. 2025. Generative next poi recommendation with semantic id. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. Mining V. 2. 2904–2914
2025
-
[48]
Jie Wang, Alexandros Karatzoglou, Ioannis Arapakis, and Joemon M Jose. 2024. Reinforcement learning-based recommender systems with large language models for state reward and action modeling. InProceedings of the 47th International ACM SIGIR conference on research and development in information retrieval. 375–385
2024
-
[49]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
- [50]
-
[51]
Yidan Wang, Zhaochun Ren, Weiwei Sun, Jiyuan Yang, Zhixiang Liang, Xin Chen, Ruobing Xie, Su Yan, Xu Zhang, Pengjie Ren, et al. 2024. Content-based collaborative generation for recommender systems. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2420– 2430
2024
-
[52]
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, et al . 2024. Eager: Two-stream generative recommender with behavior-semantic collaboration. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3245–3254
2024
- [53]
-
[54]
Yunjia Xi, Hangyu Wang, Bo Chen, Jianghao Lin, Menghui Zhu, Weiwen Liu, Ruiming Tang, Zhewei Wei, Weinan Zhang, and Yong Yu. 2025. Efficiency un- leashed: Inference acceleration for LLM-based recommender systems with spec- ulative decoding. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1891–1901
2025
-
[55]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS. The Twelfth International Conference on Learning Representations
2024
-
[56]
Longtao Xiao, Haozhao Wang, Cheng Wang, Linfei Ji, Yifan Wang, Jieming Zhu, Zhenhua Dong, Rui Zhang, and Ruixuan Li. 2025. Unger: Generative recommendation with a unified code via semantic and collaborative integration. ACM Transactions on Information Systems44, 2 (2025), 1–31
2025
-
[57]
Chaoqun Yang, Xinyu Lin, Wenjie Wang, Yongqi Li, Teng Sun, Xianjing Han, and Tat-Seng Chua. 2025. EARN: Efficient Inference Acceleration for LLM-based Generative Recommendation by Register Tokens. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3483–3494
2025
-
[58]
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. 2025. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 22128–22136
2025
- [59]
-
[60]
Zheng Zhan, Zhenglun Kong, Yifan Gong, Yushu Wu, Zichong Meng, Hangyu Zheng, Xuan Shen, Stratis Ioannidis, Wei Niu, Pu Zhao, et al. 2024. Exploring token pruning in vision state space models.Advances in Neural Information Processing Systems37 (2024), 50952–50971
2024
-
[61]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems36 (2023), 34661–34710
2023
- [62]
-
[63]
Qiyong Zhong, Jiajie Su, Yunshan Ma, Julian McAuley, and Yupeng Hou
-
[64]
Pctx: Tokenizing Personalized Context for Generative Recommendation. arXiv:2510.21276 [cs.IR] https://arxiv.org/abs/2510.21276
- [65]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.