Recognition: no theorem link
GTaP: A GPU-Resident Fork-Join Task-Parallel Runtime with a Pragma-Based Interface
Pith reviewed 2026-05-10 19:13 UTC · model grok-4.3
The pith
GTaP brings fork-join task parallelism to GPUs via state-machine tasks and continuations, often beating OpenMP on a 72-core CPU for large irregular workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GTaP realizes fork-join task parallelism on GPUs by executing tasks as state machines within a persistent kernel model and representing joins as continuations, augmented by work stealing for load balance and EPAQ to reduce warp divergence through user-defined queue partitioning, all exposed via a pragma interface.
What carries the argument
Persistent-kernel execution of tasks represented as state machines, with joins handled by continuations, plus EPAQ for partitioning task queues by execution path.
If this is right
- Programmers can write irregular fork-join code for GPUs using only pragmas, without exposing persistent kernels or state machines.
- Work stealing yields better scalability than a single global queue on the GPU.
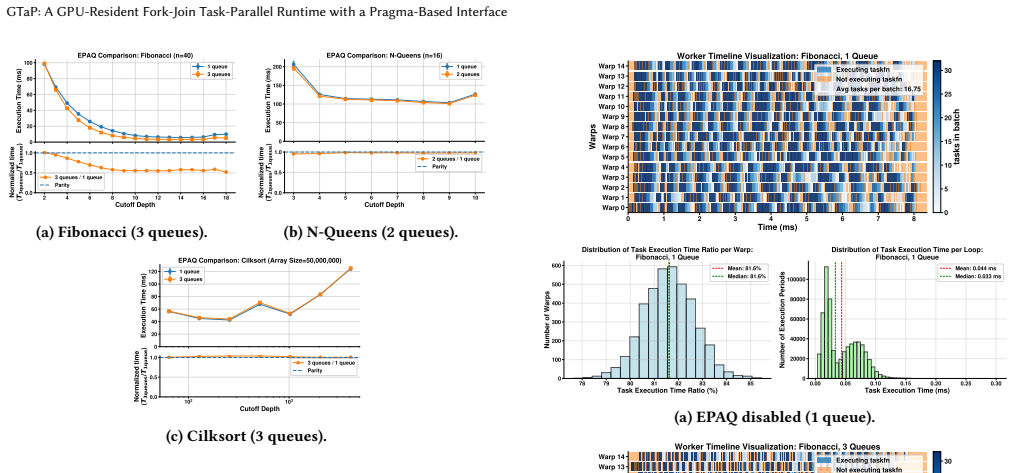
- EPAQ improves performance on some workloads by limiting warp divergence, reaching up to 1.8x on Fibonacci.
Where Pith is reading between the lines
- The state-machine-plus-continuation pattern could be adapted to other SIMT accelerators facing similar irregularity challenges.
- If GPU context-switch costs drop in future hardware, the performance margin over CPUs would likely widen for the same workloads.
- Combining GTaP's queue partitioning with existing GPU libraries might allow mixed regular and irregular phases in one application.
Load-bearing premise
The overhead of encoding tasks as state machines and using continuations for joins stays small enough that the extra parallelism still wins over CPU execution for the targeted irregular workloads on current GPUs.
What would settle it
A benchmark run where state-machine and continuation overheads dominate, producing no speedup or a slowdown versus OpenMP on the same irregular application at large size.
Figures









read the original abstract
Graphics Processing Units (GPUs) excel at regular data-parallel workloads where massive hardware parallelism can be readily exploited. In contrast, many important irregular applications are naturally expressed as task parallelism with a fork-join control structure. While CPU runtimes for fork-join task parallelism are mature, it remains challenging to efficiently support it on GPUs. We propose GTaP, a GPU-resident runtime that supports fork-join task parallelism. GTaP is based on the persistent kernel model, and supports two worker granularities: thread blocks and individual threads. To realize fork-join on GPUs, GTaP represents joins as continuations and executes each task as a state machine that can be split into multiple execution segments. We also extend Clang's frontend with a pragma-based programming model that enables programmers to express fork-join without exposing low-level mechanisms. GTaP employs work stealing for load balancing, providing better scalability than a global-queue approach. For thread-level workers, we further introduce Execution-Path-Aware Queueing (EPAQ), which allows programmers to partition task queues using user-defined criteria, reducing warp divergence caused by mixing heterogeneous control flows within a warp. Across representative irregular applications, GTaP outperforms OpenMP task-parallel execution on a 72-core CPU in many cases, especially for large problem sizes with compute-intensive tasks. We also show that GTaP's design choices outperform naive GPU alternatives. The benefit of EPAQ is workload-dependent: it can improve performance for some benchmarks while having little effect on others; on Fibonacci, EPAQ achieves up to a 1.8$\times$ speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GTaP, a GPU-resident runtime for fork-join task parallelism based on the persistent-kernel model. Tasks are represented as state machines that can be suspended at join points via continuations, supporting both thread-block and thread-level worker granularities. The system incorporates work-stealing for load balancing and introduces Execution-Path-Aware Queueing (EPAQ) to partition task queues and reduce warp divergence. A pragma-based interface is added to Clang. The central claim is that GTaP outperforms OpenMP task-parallel execution on a 72-core CPU across representative irregular applications (especially at large problem sizes with compute-intensive tasks), that its design choices outperform naive GPU alternatives, and that EPAQ delivers up to 1.8× speedup on Fibonacci.
Significance. If the performance claims are supported by reproducible experiments with proper controls, GTaP would represent a meaningful advance in enabling irregular, fork-join task parallelism on GPUs, an area where current GPU runtimes lag behind mature CPU solutions. The pragma interface and EPAQ technique address practical programmability and hardware-specific challenges (warp divergence), with potential impact on HPC workloads involving irregular control flow. The work-stealing and continuation mechanisms are technically interesting extensions of persistent-kernel ideas.
major comments (2)
- [§5] §5 (Evaluation): The reported speedups versus OpenMP lack sufficient experimental details on baselines (specific OpenMP runtime, compiler flags, thread affinity, and input sizes), error bars, and workload characteristics. This is load-bearing for the central claim of outperformance on irregular applications, as the abstract and design sections provide no quantitative isolation of state-machine dispatch or continuation overheads versus the claimed GPU parallelism gains.
- [§4] §4 (Design): No ablation or microbenchmark isolates the per-task cost of state-machine representation and continuation-based joins. Without this, it is impossible to verify whether these overheads remain small enough to be amortized by GPU hardware threads for the targeted irregular workloads, directly addressing the skeptic concern that the weakest assumption may not hold.
minor comments (2)
- [Abstract] Abstract: The phrase 'representative irregular applications' is used without naming the benchmarks; this should be expanded to include a brief list and their key characteristics.
- [§5] The paper would benefit from a summary table in the evaluation section listing each benchmark, its task granularity, and observed speedups with and without EPAQ.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of GTaP. We address each major comment below and will make the indicated revisions to improve reproducibility and address concerns about overheads.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The reported speedups versus OpenMP lack sufficient experimental details on baselines (specific OpenMP runtime, compiler flags, thread affinity, and input sizes), error bars, and workload characteristics. This is load-bearing for the central claim of outperformance on irregular applications, as the abstract and design sections provide no quantitative isolation of state-machine dispatch or continuation overheads versus the claimed GPU parallelism gains.
Authors: We agree that additional details are necessary to support the claims and enable reproduction. In the revised manuscript we will expand §5 to specify the OpenMP runtime (LLVM libomp 15), compiler flags (-O3 -fopenmp -march=native), thread affinity (OMP_PROC_BIND=close), exact input sizes for each benchmark, and error bars (mean ± std. dev. over 5 runs). We will add a table summarizing workload characteristics including task granularity, irregularity (e.g., task-size variance), and compute intensity. We will also insert a new microbenchmark subsection that isolates state-machine dispatch and continuation overheads, allowing direct comparison against the observed GPU parallelism gains for the irregular workloads. revision: yes
-
Referee: [§4] §4 (Design): No ablation or microbenchmark isolates the per-task cost of state-machine representation and continuation-based joins. Without this, it is impossible to verify whether these overheads remain small enough to be amortized by GPU hardware threads for the targeted irregular workloads, directly addressing the skeptic concern that the weakest assumption may not hold.
Authors: We acknowledge the value of explicit isolation. While §4 describes the state-machine and continuation mechanisms, we will add an ablation study and targeted microbenchmarks to §5 (with forward references to §4). These experiments will measure per-task latency for state transitions and joins on synthetic workloads with varying task counts, demonstrating amortization for compute-intensive irregular tasks on GPU hardware threads. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an implementation of GTaP, a GPU-resident fork-join task-parallel runtime using persistent kernels, task state machines with continuations for joins, work-stealing, EPAQ for warp-divergence mitigation, and a Clang pragma extension. Central claims of outperforming 72-core OpenMP on irregular applications rest entirely on reported empirical benchmarks for representative workloads, with no equations, fitted parameters, mathematical derivations, or self-referential reductions. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the design or evaluation; the work is self-contained against external CPU baselines and alternative GPU approaches.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern GPUs can sustain persistent kernels with acceptable overhead for task-parallel workloads
Reference graph
Works this paper leans on
-
[1]
Advanced Micro Devices, Inc. 2026. HIP Documentation. Online documentation. https://rocm.docs.amd.com/projects/HIP/ (accessed 2026-01-23)
2026
-
[2]
Eduard Ayguadé, Nawal Copty, Alejandro Duran, Jay Hoeflinger, Yuan Lin, Federico Massaioli, Xavier Teruel, Priya Unnikrishnan, and Guansong Zhang
-
[3]
The Design of OpenMP Tasks.IEEE Transactions on Parallel and Distributed Systems20, 3 (June 2008), 404–418
2008
-
[4]
Blumofe, Christopher F
Robert D. Blumofe, Christopher F. Joerg, Bradley C. Kuszmaul, Charles E. Leis- erson, Keith H. Randall, and Yuli Zhou. 1995. Cilk: An Efficient Multithreaded Runtime System. InProceedings of the Fifth ACM SIGPLAN Symposium on Prin- ciples and Practice of Parallel Programming(Santa Barbara, California, USA) (PPOPP ’95). Association for Computing Machinery,...
1995
-
[5]
doi:10.1145/209936.209958
-
[6]
Blumofe and Charles E
Robert D. Blumofe and Charles E. Leiserson. 1999. Scheduling Multithreaded Computations by Work Stealing.J. ACM46, 5 (Sept. 1999), 720–748
1999
-
[7]
Chamberlain, David Callahan, and Hans P
Bradford L. Chamberlain, David Callahan, and Hans P. Zima. 2007. Parallel Programmability and the Chapel Language.International Journal of High Perfor- mance Computing Applications21, 3 (2007), 291–312
2007
-
[8]
David Chase and Yossi Lev. 2005. Dynamic circular work-stealing deque. In Proceedings of the seventeenth annual ACM symposium on Parallelism in algorithms and architectures. ACM, Las Vegas Nevada USA, 21–28. doi:10.1145/1073970. 1073974
-
[9]
Sanjay Chatterjee, Max Grossman, Alina Sbîrlea, and Vivek Sarkar. 2013. Dy- namic Task Parallelism with a GPU Work-Stealing Runtime System. InLanguages and Compilers for Parallel Computing, David Hutchison, Takeo Kanade, Josef Kittler, Jon M. Kleinberg, Friedemann Mattern, John C. Mitchell, Moni Naor, Oscar Nierstrasz, C. Pandu Rangan, Bernhard Steffen, M...
-
[10]
Quan Chen, Minyi Guo, and Haibing Guan. 2014. LAWS: locality-aware work- stealing for multi-socket multi-core architectures. InProceedings of the 28th ACM international conference on Supercomputing. ACM, Munich Germany, 3–12. doi:10.1145/2597652.2597665
-
[11]
Yuxin Chen, Benjamin Brock, Serban Porumbescu, Aydin Buluc, Katherine Yelick, and John Owens. 2022. Atos: A Task-Parallel GPU Scheduler for Graph Analytics. InProceedings of the 51st International Conference on Parallel Processing. ACM, Bordeaux France, 1–11. doi:10.1145/3545008.3545056
-
[12]
Yuxin Chen, Benjamin Brock, Serban Porumbescu, Aydin Buluç, Katherine Yelick, and John D. Owens. 2022. Scalable Irregular Parallelism with GPUs: Getting CPUs Out of the Way. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, Dallas, TX, USA, 1–16. doi:10. 1109/SC41404.2022.00055
work page Pith review arXiv 2022
-
[13]
ISO/IEC JTC1/SC22/WG21. 2019. Merge Coroutines TS into C++20 working draft. https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/p0912r5.html (accessed 2026-01-23)
2019
-
[14]
JetBrains. 2026. Coroutines. Online documentation. https://kotlinlang.org/docs/ coroutines-overview.html (accessed 2026-01-23)
2026
-
[15]
Khronos OpenCL Working Group. 2026. The OpenCL™Specification. On- line specification. https://registry.khronos.org/OpenCL/specs/3.0-unified/pdf/ OpenCL_API.pdf (accessed 2026-01-23)
2026
-
[16]
Kosuke Kiuchi, Yudai Tanabe, and Hidehiko Masuhara. 2025. An Efficient Ex- ecution Mechanism on a GPU for Fine-Grained Parallel Programs With the Fork-Join Model.Journal of Information Processing33 (Nov. 2025), 840–851. doi:10.2197/ipsjjip.33.840 Presented at the 153rd IPSJ SIGPRO Workshop. Ac- cepted 2025-05-28. Also published in the IPSJ Transaction on ...
-
[17]
Christopher D. Marlin. 1980.Coroutines: A Programming Methodology, a Language Design and an Implementation. Lecture Notes in Computer Science, Vol. 95. Springer Berlin, Heidelberg. doi:10.1007/3-540-10256-6
-
[18]
Seung-Jai Min, Costin Iancu, and Katherine Yelick. 2011. Hierarchical work stealing on manycore clusters. InFifth Conference on Partitioned Global Address Space Programming Models (PGAS11), Vol. 625
2011
-
[19]
2014.MassiveThreads: A Thread Library for High Productivity Languages
Jun Nakashima and Kenjiro Taura. 2014.MassiveThreads: A Thread Library for High Productivity Languages. Springer Berlin Heidelberg, 222–238
2014
-
[20]
NVIDIA Corporation. 2026. CUDA C++ Programming Guide. Online docu- mentation. https://docs.nvidia.com/cuda/cuda-programming-guide/ (accessed 2026-01-23)
2026
-
[21]
Ryosuke Okuta, Yuya Unno, Daisuke Nishino, Shohei Hido, and Crissman Loomis
-
[22]
In Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty- first Annual Conference on Neural Information Processing Systems (NIPS)
CuPy: A NumPy-Compatible Library for NVIDIA GPU Calculations. In Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty- first Annual Conference on Neural Information Processing Systems (NIPS). http: //learningsys.org/nips17/assets/papers/paper_16.pdf
-
[23]
OpenMP Architecture Review Board. 2024. OpenMP 6.0 Specification. Online specification. https://www.openmp.org/wp-content/uploads/OpenMP-API- Specification-6-0.pdf (accessed 2026-01-23)
2024
-
[24]
Python Software Foundation. 2026. Coroutines and Tasks. Online documentation. https://docs.python.org/3/library/asyncio-task.html (accessed 2026-01-23)
2026
-
[25]
2007.Intel Threading Building Blocks: Outfitting C++ for Multi- Core Processor Parallelism
James Reinders. 2007.Intel Threading Building Blocks: Outfitting C++ for Multi- Core Processor Parallelism. O’Reilly Media
2007
- [26]
-
[27]
Shumpei Shiina and Kenjiro Taura. 2023. Itoyori: Reconciling Global Address Space and Global Fork-Join Task Parallelism. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. ACM, Denver CO USA, 1–15. doi:10.1145/3581784.3607049
- [28]
-
[29]
Markus Steinberger, Michael Kenzel, Pedro Boechat, Bernhard Kerbl, Mark Dok- ter, and Dieter Schmalstieg. 2014. Whippletree: task-based scheduling of dynamic workloads on the GPU.ACM Transactions on Graphics33, 6 (Nov. 2014), 1–11. doi:10.1145/2661229.2661250
-
[30]
Supercomputing Division, Information Technology Center, The University of Tokyo. 2026. Miyabi Supercomputer System. Online documentation. https: //www.cc.u-tokyo.ac.jp/en/supercomputer/miyabi/service/ (accessed 2026-01- 23)
2026
-
[31]
The Khronos SYCL Working Group. 2020. SYCL™2020 Specification. Online specification. https://registry.khronos.org/SYCL/specs/sycl-2020/pdf/sycl-2020. pdf (accessed 2026-01-23)
2020
-
[32]
Stanley Tzeng, Brandon Lloyd, and John D. Owens. 2012. A GPU Task-Parallel Model with Dependency Resolution.Computer45, 8 (Aug. 2012), 34–41. doi:10. 1109/MC.2012.255
2012
-
[33]
Stanley Tzeng, Anjul Patney, and John D. Owens. 2010. Task Management for Irregular-Parallel Workloads on the GPU. InProceedings of High Performance Graphics (HPG ’10). The Eurographics Association, 29–37. doi:10.2312/EGGH/ HPG10/029-037
-
[34]
Sandra Wienke, Paul Springer, Christian Terboven, and Dieter An Mey. 2012. OpenACC — First Experiences with Real-World Applications. InEuro-Par 2012 Parallel Processing, David Hutchison, Takeo Kanade, Josef Kittler, Jon M. Kleinberg, Friedemann Mattern, John C. Mitchell, Moni Naor, Oscar Nierstrasz, C. Pandu Rangan, Bernhard Steffen, Madhu Sudan, Demetri ...
-
[35]
Shaokun Zheng, Xin Chen, Zhong Shi, Ling-Qi Yan, and Kun Xu. 2024. GPU Coroutines for Flexible Splitting and Scheduling of Rendering Tasks.ACM Transactions on Graphics43, 6 (Dec. 2024), 1–24. doi:10.1145/3687766
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.