gMatch: Fine-Grained and Hardware-Efficient Subgraph Matching on GPUs
Pith reviewed 2026-05-10 16:07 UTC · model grok-4.3
The pith
A fine-grained GPU execution model for subgraph matching outperforms prior methods and scales to larger queries and datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
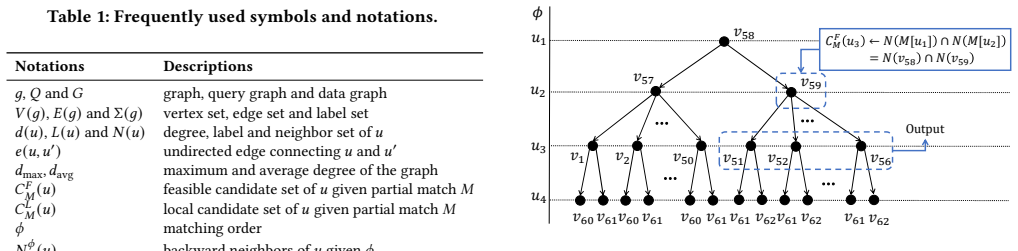
gMatch achieves subgraph matching on GPUs through a fine-grained execution model that reduces memory consumption and supports flexible task scheduling among threads, combined with warp-level batch exploration and lightweight load balancing, outperforming prior methods in both performance and scalability on diverse workloads and real-world datasets.
What carries the argument
The fine-grained execution model that assigns smaller tasks to individual threads to cut memory overhead and enable dynamic scheduling, supported by warp-level batch exploration and lightweight load balancing.
If this is right
- Subgraph matching becomes practical for substantially larger real-world graphs in social networks and bioinformatics.
- GPU thread utilization rises and memory pressure drops, shortening runtimes across varied workloads.
- Mining systems limited to small patterns can be extended without the same scalability collapse.
- Coarse-grained GPU designs are shown to hit inherent limits from memory waste and idle threads.
Where Pith is reading between the lines
- The same fine-grained scheduling ideas could accelerate other irregular graph algorithms on GPUs.
- Hardware vendors might add direct support for warp-level batching to improve graph processing.
- Combining gMatch with distributed multi-GPU setups could push matching to even larger scales.
- Gains may depend on graph density, suggesting further tuning for sparse versus dense cases.
Load-bearing premise
The fine-grained model, warp-level batching, and load balancing will deliver consistent speed and correctness gains without hidden overheads or trade-offs on every graph structure, query size, and GPU hardware.
What would settle it
A run on a query and dataset larger than those handled by STMatch or T-DFS where gMatch either fails to finish, returns incorrect matches, or shows no speedup relative to the best prior method.
Figures














read the original abstract
Subgraph matching is a core operation in graph analytics, supporting a broad spectrum of applications from social network analysis to bioinformatics. Recent GPU-based approaches accelerate subgraph matching by leveraging parallelism but rely on a coarse-grained execution model that suffers from scalability and efficiency issues due to high memory overhead and thread underutilization. In this paper, we propose gMatch, a hardware-efficient subgraph matching approach on GPUs. gMatch introduces a fine-grained execution model that reduces memory consumption and enables flexible task scheduling among threads. We further design warp-level batch exploration and lightweight load balancing to improve execution efficiency and scalability. Experiments on diverse workloads and real-world datasets show that gMatch outperforms state-of-the-art subgraph matching methods, including STMatch, T-DFS, and EGSM, in both performance and scalability. We also compare against state-of-the-art systems for mining small patterns, such as BEEP and G$^2$Miner. While these systems achieve better performance on small datasets, gMatch scales to substantially larger queries and datasets, where existing approaches degrade or fail to complete.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces gMatch, a GPU-based subgraph matching system that replaces coarse-grained execution with a fine-grained model to lower memory overhead and improve thread utilization. It adds warp-level batch exploration for task scheduling and lightweight load balancing for efficiency. Experiments on real-world datasets and diverse workloads claim that gMatch outperforms STMatch, T-DFS, EGSM in speed and scalability, and scales to larger queries than BEEP and G²Miner where the baselines fail.
Significance. If the claimed speedups and scaling limits hold under controlled conditions, gMatch would provide a practical advance for GPU graph analytics by directly mitigating memory bloat and underutilization that limit prior coarse-grained methods. The design choices (fine-grained tasks, warp batches, lightweight balancing) are portable to other irregular graph workloads and could serve as a template for hardware-efficient implementations.
minor comments (3)
- The abstract states performance and scalability wins but supplies no quantitative results, error bars, dataset sizes, or experimental controls. Add a sentence with representative speedups and the largest graph/query sizes tested.
- Section 4 (or wherever the experimental setup appears) should explicitly list the GPU model, memory capacity, and whether results are averaged over multiple runs with standard deviation; this is needed to assess reproducibility of the scalability claims.
- Figure captions and axis labels for the scaling plots should state the exact query sizes and graph edge counts at which baselines time out, so readers can judge the 'substantially larger' claim without consulting the text.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of gMatch and the recommendation for minor revision. The review accurately captures the key ideas of replacing coarse-grained execution with fine-grained task scheduling, warp-level batch exploration, and lightweight load balancing to address memory overhead and thread utilization in GPU subgraph matching.
Circularity Check
No significant circularity detected
full rationale
The paper is a systems/engineering contribution that proposes a fine-grained GPU execution model for subgraph matching, along with warp-level batch exploration and lightweight load balancing. Its claims are supported by direct experimental comparisons against independent prior systems (STMatch, T-DFS, EGSM, BEEP, G²Miner) on real-world datasets and workloads. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described approach. The central results do not reduce to inputs by construction; they are externally validated through implementation and benchmarking, making the work self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mohammad Almasri, Izzat El Hajj, Rakesh Nagi, Jinjun Xiong, and Wen-mei Hwu. 2022. Parallel K-clique counting on GPUs. InProceedings of the 36th ACM International Conference on Supercomputing(Virtual Event)(ICS ’22). Association for Computing Machinery, New York, NY, USA, Article 21, 14 pages
work page 2022
-
[2]
Mohammad Almasri, Neo Vasudeva, Rakesh Nagi, Jinjun Xiong, and Wen-Mei Hwu. 2021. HyKernel: A Hybrid Selection of One/Two-Phase Kernels for Triangle Counting on GPUs. In2021 IEEE High Performance Extreme Computing Conference (HPEC). 1–7
work page 2021
-
[3]
Junya Arai, Yasuhiro Fujiwara, and Makoto Onizuka. 2023. GuP: Fast Subgraph Matching by Guard-based Pruning.Proc. ACM Manag. Data1, 2, Article 167 (June 2023), 26 pages
work page 2023
-
[4]
Bibek Bhattarai, Hang Liu, and H. Howie Huang. 2019. CECI: Compact Em- bedding Cluster Index for Scalable Subgraph Matching. InProceedings of the 2019 International Conference on Management of Data(Amsterdam, Nether- lands)(SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 1447–1462
work page 2019
-
[5]
Fei Bi, Lijun Chang, Xuemin Lin, Lu Qin, and Wenjie Zhang. 2016. Efficient Subgraph Matching by Postponing Cartesian Products. InProceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, June 26 - July 01, 2016, Fatma Özcan, Georgia Koutrika, and Sam Madden (Eds.). ACM, 1199–1214
work page 2016
-
[6]
Vincenzo Bonnici, Rosalba Giugno, Alfredo Pulvirenti, Dennis Shasha, and Al- fredo Ferro. 2013. A subgraph isomorphism algorithm and its application to biochemical data.BMC bioinformatics14 (2013), 1–13
work page 2013
-
[7]
Hongzhi Chen, Miao Liu, Yunjian Zhao, Xiao Yan, Da Yan, and James Cheng
-
[8]
InProceedings of the Thirteenth EuroSys Conference(Porto, Portugal)(EuroSys ’18)
G-Miner: an efficient task-oriented graph mining system. InProceedings of the Thirteenth EuroSys Conference(Porto, Portugal)(EuroSys ’18). Association for Computing Machinery, New York, NY, USA, Article 32, 12 pages
-
[9]
Xuhao Chen and Arvind. 2022. Efficient and Scalable Graph Pattern Mining on GPUs. In16th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 22). USENIX Association, Carlsbad, CA, 857–877
work page 2022
-
[10]
Xuhao Chen, Roshan Dathathri, Gurbinder Gill, and Keshav Pingali. 2020. Pan- golin: an efficient and flexible graph mining system on CPU and GPU.Proc. VLDB Endow.13, 8 (April 2020), 1190–1205
work page 2020
-
[11]
Vinicius Dias, Carlos H. C. Teixeira, Dorgival Guedes, Wagner Meira, and Srini- vasan Parthasarathy. 2019. Fractal: A General-Purpose Graph Pattern Mining System. InProceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands)(SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 1357–1374
work page 2019
-
[12]
Vibhor Dodeja, Mohammad Almasri, Rakesh Nagi, Jinjun Xiong, and Wen-mei Hwu. 2022. PARSEC: PARallel Subgraph Enumeration in CUDA. In2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 168–178
work page 2022
-
[13]
Orri Erling, Alex Averbuch, Josep-Lluis Larriba-Pey, Hassan Chafi, Andrey Gu- bichev, Arnau Prat-Pérez, Minh-Duc Pham, and Peter A. Boncz. 2015. The LDBC Social Network Benchmark: Interactive Workload. InSIGMOD. 619–630
work page 2015
-
[14]
Oded Green, Pavan Yalamanchili, and Lluís-Miquel Munguía. 2014. Fast Tri- angle Counting on the GPU. In2014 4th Workshop on Irregular Applications: Architectures and Algorithms (IA 3). 1–8
work page 2014
-
[15]
Wentian Guo, Yuchen Li, Mo Sha, Bingsheng He, Xiaokui Xiao, and Kian-Lee Tan. 2020. GPU-Accelerated Subgraph Enumeration on Partitioned Graphs. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data(Portland, OR, USA)(SIGMOD ’20). Association for Computing Machinery, New York, NY, USA, 1067–1082
work page 2020
-
[16]
Pankaj Gupta, Venu Satuluri, Ajeet Grewal, Siva Gurumurthy, Volodymyr Zhabiuk, Quannan Li, and Jimmy Lin. 2014. Real-time twitter recommenda- tion: Online motif detection in large dynamic graphs.Proceedings of the VLDB Endowment7, 13 (2014), 1379–1380
work page 2014
-
[17]
Myoungji Han, Hyunjoon Kim, Geonmo Gu, Kunsoo Park, and Wook-Shin Han. 2019. Efficient Subgraph Matching: Harmonizing Dynamic Programming, Adaptive Matching Order, and Failing Set Together. InSIGMOD Conference. 1429–1446
work page 2019
-
[18]
Huahai He and Ambuj K. Singh. 2008. Graphs-at-a-time: query language and access methods for graph databases. InProceedings of the 2008 ACM SIGMOD International Conference on Management of Data(Vancouver, Canada)(SIGMOD ’08). Association for Computing Machinery, New York, NY, USA, 405–418
work page 2008
-
[19]
Yang Hu, Hang Liu, and H. Howie Huang. 2018. High-Performance Triangle Counting on GPUs. In2018 IEEE High Performance extreme Computing Conference (HPEC). 1–5
work page 2018
-
[20]
Kasra Jamshidi, Rakesh Mahadasa, and Keval Vora. 2020. Peregrine: a pattern- aware graph mining system. InProceedings of the Fifteenth European Conference on Computer Systems(Heraklion, Greece)(EuroSys ’20). Association for Computing Machinery, New York, NY, USA, Article 13, 16 pages
work page 2020
-
[21]
Guanxian Jiang, Qihui Zhou, Tatiana Jin, Boyang Li, Yunjian Zhao, Yichao Li, and James Cheng. 2022. VSGM: view-based GPU-accelerated subgraph matching on large graphs. InProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis(Dallas, Texas)(SC ’22). IEEE Press, Article 52, 15 pages
work page 2022
-
[22]
Jiawei Jiang, Yusong Hu, Xiaosen Li, Wen Ouyang, Zhitao Wang, Fangcheng Fu, and Bin Cui. 2022. Analyzing Online Transaction Networks with Network Motifs. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Washington DC, USA)(KDD ’22). Association for Computing Machinery, New York, NY, USA, 3098–3106
work page 2022
-
[23]
Tatiana Jin, Boyang Li, Yichao Li, Qihui Zhou, Qianli Ma, Yunjian Zhao, Hongzhi Chen, and James Cheng. 2023. Circinus: Fast Redundancy-Reduced Subgraph Matching.Proc. ACM Manag. Data1, 1, Article 12 (May 2023), 26 pages
work page 2023
-
[24]
Samiran Kawtikwar, Mohammad Almasri, Wen-Mei Hwu, Rakesh Nagi, and Jinjun Xiong. 2023. Beep: Balanced efficient subgraph enumeration in parallel. In Proceedings of the 52nd International Conference on Parallel Processing. 142–152
work page 2023
-
[25]
Vinayak Kesarwani, Shivangi Gaur, Sudeep Ranjan Sahoo, Kishan Tamboli, and Vishwesh Jatala. 2024. A Partitioning Scheme for Large Scale Clique Counting on Single GPU. In2024 IEEE 31st International Conference on High Performance Computing, Data and Analytics Workshop (HiPCW). 167–168
work page 2024
-
[26]
Farzad Khorasani, Rajiv Gupta, and Laxmi N. Bhuyan. 2015. Scalable SIMD- Efficient Graph Processing on GPUs. InProceedings of the 24th International Conference on Parallel Architectures and Compilation Techniques (PACT ’15). 39– 50
work page 2015
-
[27]
Hyunjoon Kim, Yunyoung Choi, Kunsoo Park, Xuemin Lin, Seok-Hee Hong, and Wook-Shin Han. 2021. Versatile Equivalences: Speeding up Subgraph Query Processing and Subgraph Matching. InProceedings of the 2021 International Con- ference on Management of Data(Virtual Event, China)(SIGMOD ’21). Association for Computing Machinery, New York, NY, USA, 925–937
work page 2021
-
[28]
Bhowmick, Wook-Shin Han, JeongHoon Lee, Seongyun Ko, and Moath H.A
Hyeonji Kim, Juneyoung Lee, Sourav S. Bhowmick, Wook-Shin Han, JeongHoon Lee, Seongyun Ko, and Moath H.A. Jarrah. 2016. DUALSIM: Parallel Subgraph Enumeration in a Massive Graph on a Single Machine. InProceedings of the 2016 International Conference on Management of Data(San Francisco, California, USA)(SIGMOD ’16). Association for Computing Machinery, New...
work page 2016
-
[29]
Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford Large Network Dataset Collection. http://snap.stanford.edu/data. Accessed: April 11, 2026
work page 2014
-
[30]
Yujie Lu, Zhijie Zhang, and Weiguo Zheng. 2025. B S○X: Subgraph Matching with Batch Backtracking Search.Proc. ACM Manag. Data3, 1, Article 15 (Feb. 2025), 27 pages
work page 2025
-
[31]
Chenhao Ma, Reynold Cheng, Laks V. S. Lakshmanan, Tobias Grubenmann, Yixiang Fang, and Xiaodong Li. 2019. LINC: a motif counting algorithm for uncertain graphs.Proc. VLDB Endow.13, 2 (Oct. 2019), 155–168
work page 2019
-
[32]
Daniel Mawhirter and Bo Wu. 2019. AutoMine: harmonizing high-level abstrac- tion and high performance for graph mining. InProceedings of the 27th ACM Symposium on Operating Systems Principles(Huntsville, Ontario, Canada)(SOSP ’19). Association for Computing Machinery, New York, NY, USA, 509–523
work page 2019
-
[33]
Shixuan Sun and Qiong Luo. 2020. In-Memory Subgraph Matching: An In- depth Study. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data(Portland, OR, USA)(SIGMOD ’20). Association for Computing Machinery, New York, NY, USA, 1083–1098
work page 2020
-
[34]
Shixuan Sun, Xibo Sun, Yulin Che, Qiong Luo, and Bingsheng He. 2020. Rapid- Match: a holistic approach to subgraph query processing.Proc. VLDB Endow.14, 2 (Oct. 2020), 176–188
work page 2020
-
[35]
Xibo Sun and Qiong Luo. 2023. Efficient GPU-Accelerated Subgraph Matching. Proc. ACM Manag. Data1, 2, Article 181 (June 2023), 26 pages
work page 2023
-
[36]
Carlos H. C. Teixeira, Alexandre J. Fonseca, Marco Serafini, Georgos Siganos, Mohammed J. Zaki, and Ashraf Aboulnaga. 2015. Arabesque: a system for distributed graph mining. InProceedings of the 25th Symposium on Operating Systems Principles(Monterey, California)(SOSP ’15). Association for Computing Machinery, New York, NY, USA, 425–440
work page 2015
-
[37]
Ha-Nguyen Tran, Jung-jae Kim, and Bingsheng He. 2015. Fast Subgraph Matching on Large Graphs using Graphics Processors. InDatabase Systems for Advanced Ap- plications, Matthias Renz, Cyrus Shahabi, Xiaofang Zhou, and Muhammad Aamir Cheema (Eds.). Springer International Publishing, Cham, 299–315
work page 2015
-
[38]
J. R. Ullmann. 1976. An Algorithm for Subgraph Isomorphism.J. ACM23, 1 (Jan. 1976), 31–42
work page 1976
-
[39]
Yihua Wei and Peng Jiang. 2022. STMatch: accelerating graph pattern matching on GPU with stack-based loop optimizations. InProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (Dallas, Texas)(SC ’22). IEEE Press, Article 53, 13 pages
work page 2022
-
[40]
Peter Willett. 1999.Matching of Chemical and Biological Structures Using Subgraph and Maximal Common Subgraph Isomorphism Algorithms. Springer New York, New York, NY, 11–38
work page 1999
-
[41]
Lizhi Xiang, Arif Khan, Edoardo Serra, Mahantesh Halappanavar, and Aravind Sukumaran-Rajam. 2021. cuTS: scaling subgraph isomorphism on distributed multi-GPU systems using trie based data structure. InProceedings of the Inter- national Conference for High Performance Computing, Networking, Storage and Analysis(St. Louis, Missouri)(SC ’21). Association for...
work page 2021
-
[42]
Rongjian Yang, Zhijie Zhang, Weiguo Zheng, and Jeffrey Xu Yu. 2023. Fast Con- tinuous Subgraph Matching over Streaming Graphs via Backtracking Reduction. Proc. ACM Manag. Data1, 1, Article 15 (May 2023), 26 pages
work page 2023
-
[43]
Lyuheng Yuan, Akhlaque Ahmad, Da Yan, Jiao Han, Saugat Adhikari, Xiaodong Yu, and Yang Zhou. 2024. G2-AIMD: A Memory-Efficient Subgraph-Centric Framework for Efficient Subgraph Finding on GPUs. In2024 IEEE 40th Interna- tional Conference on Data Engineering (ICDE). 3164–3177
work page 2024
-
[44]
Lyuheng Yuan, Da Yan, Jiao Han, Akhlaque Ahmad, Yang Zhou, and Zhe Jiang
-
[45]
In2024 IEEE 40th Interna- tional Conference on Data Engineering (ICDE)
Faster Depth-First Subgraph Matching on GPUs. In2024 IEEE 40th Interna- tional Conference on Data Engineering (ICDE). 3151–3163
-
[46]
Li Zeng, Lei Zou, and M. Tamer Özsu. 2023. SGSI – A Scalable GPU-Friendly Subgraph Isomorphism Algorithm.IEEE Transactions on Knowledge and Data Engineering35, 11 (2023), 11899–11916
work page 2023
-
[47]
Tamer Özsu, Lin Hu, and Fan Zhang
Li Zeng, Lei Zou, M. Tamer Özsu, Lin Hu, and Fan Zhang. 2020. GSI: GPU- friendly Subgraph Isomorphism. In2020 IEEE 36th International Conference on Data Engineering (ICDE). 1249–1260
work page 2020
-
[48]
Shijie Zhang, Shirong Li, and Jiong Yang. 2009. GADDI: distance index based subgraph matching in biological networks. InProceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology (Saint Petersburg, Russia)(EDBT ’09). Association for Computing Machinery, New York, NY, USA, 192–203
work page 2009
-
[49]
Zhijie Zhang, Yujie Lu, Weiguo Zheng, and Xuemin Lin. 2024. A Comprehensive Survey and Experimental Study of Subgraph Matching: Trends, Unbiasedness, and Interaction.Proc. ACM Manag. Data2, 1, Article 60 (March 2024), 29 pages. A SCALABILITY EV ALUATIONS To evaluate the scalability of our algorithm, we conduct four ex- periments on two representative data...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.