Learning an Opponent-aware Anti-jamming Strategy via Online Convex Optimization
Pith reviewed 2026-05-10 16:31 UTC · model grok-4.3
The pith
Incorporating unbiased gradient estimators tailored to DRFM jammers into online convex optimization yields lower regret and faster anti-jamming convergence for frequency-agile radars.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
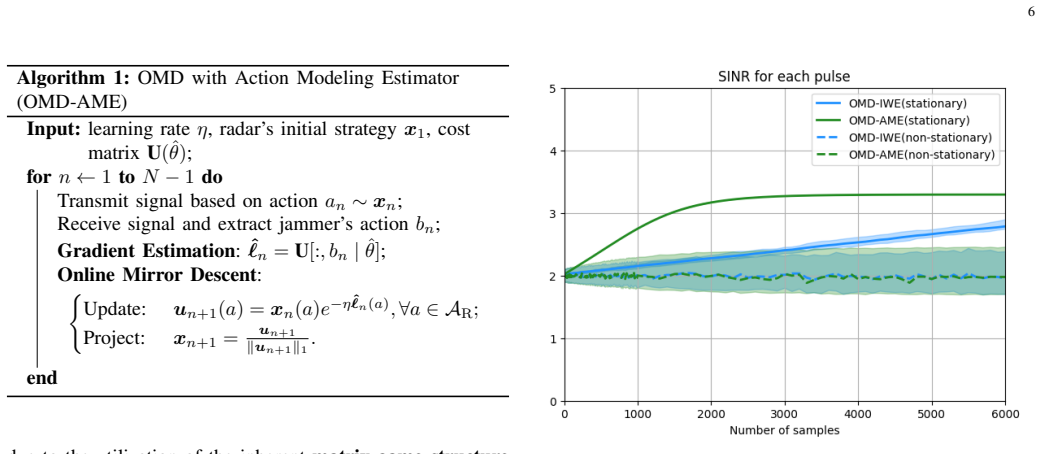
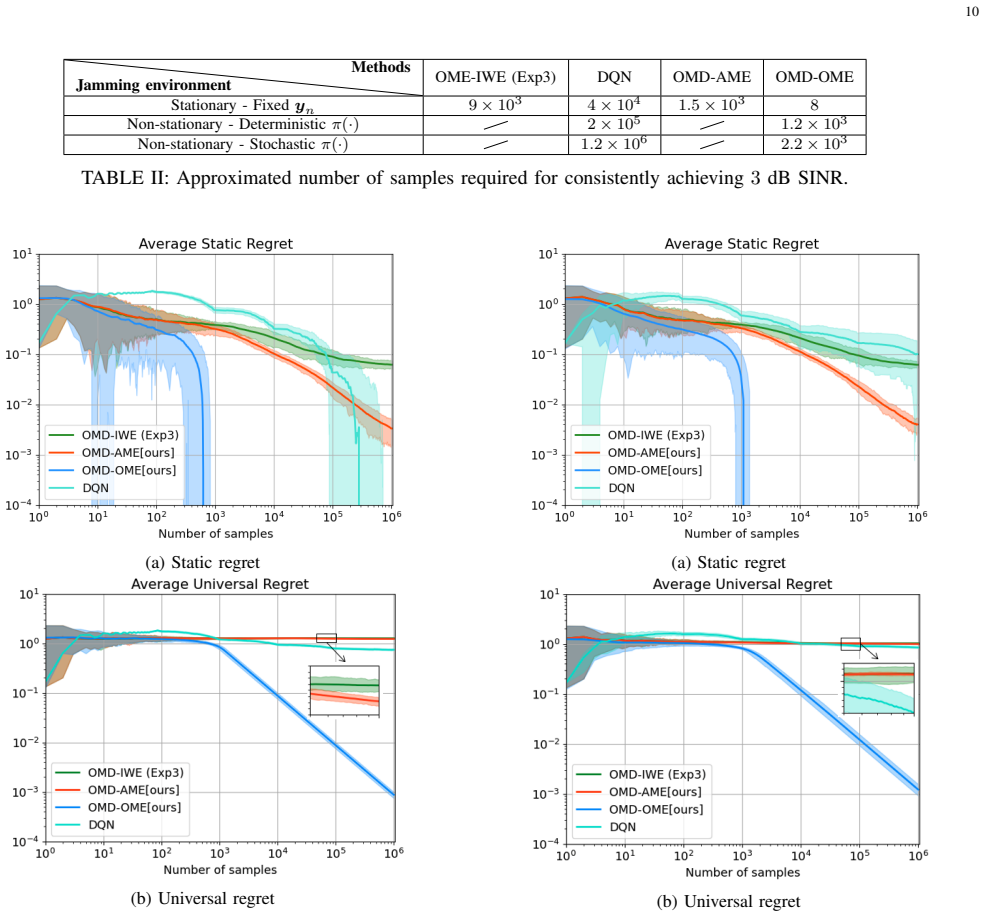
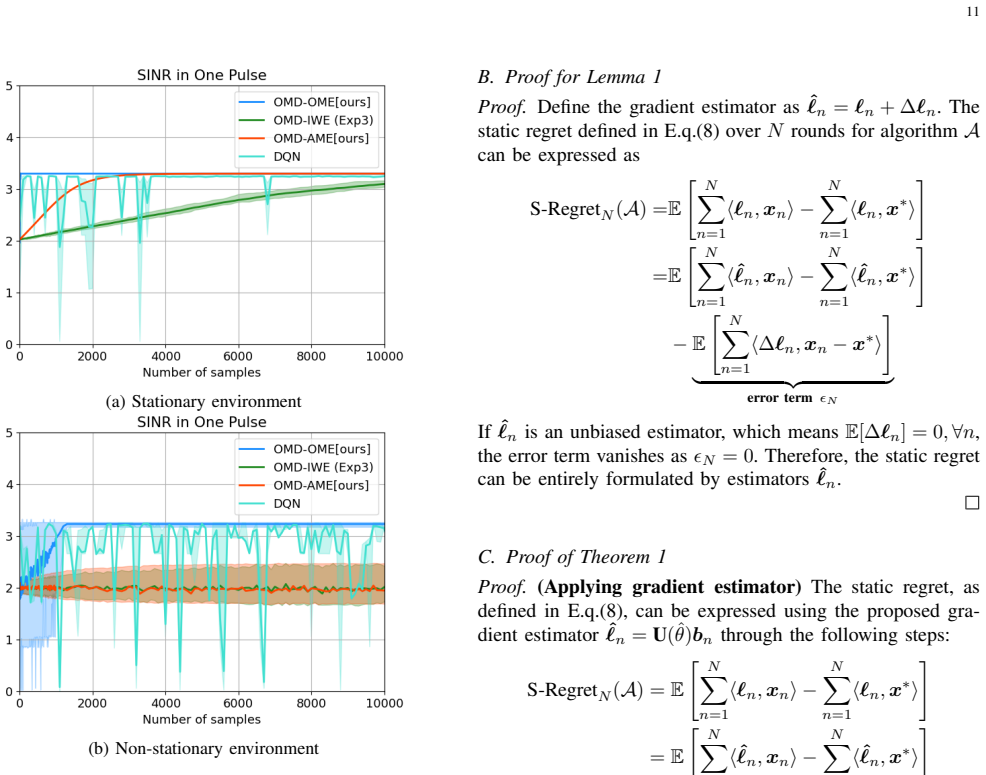
The paper claims that two refined online convex optimization algorithms, each using unbiased gradient estimators constructed specifically for the characteristics of DRFM-based jammers, produce a significantly tighter regret bound and deliver measurably better anti-jamming performance than either standard OCO or reinforcement-learning methods.
What carries the argument
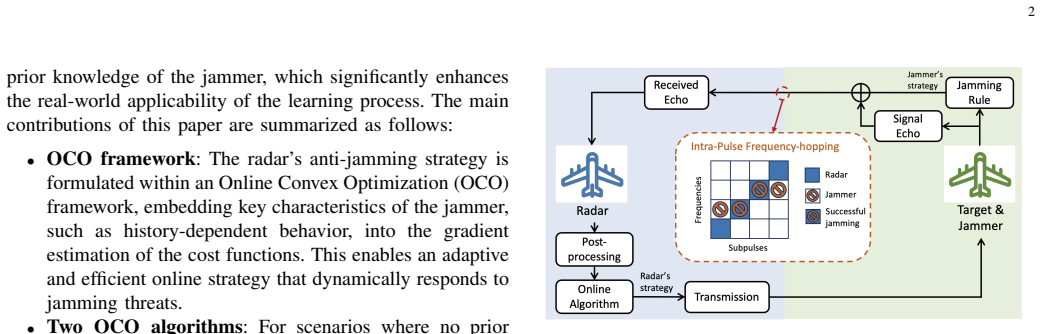
Two refined OCO algorithms that replace conventional gradients with unbiased estimators exploiting the structure of DRFM-based jammers, thereby capturing the radar-jammer interaction more precisely within the convex framework.
If this is right
- The refined estimators produce a measurably tighter long-term regret bound than standard OCO.
- Convergence to effective anti-jamming policies occurs in fewer steps than with conventional methods.
- Simulation performance against DRFM jammers exceeds that of both standard OCO and reinforcement-learning baselines.
- The approach yields opponent-aware strategies that exploit rather than ignore the jammer's memory and replay behavior.
Where Pith is reading between the lines
- The same structure-aware estimator technique could be applied to other online learning settings where partial knowledge of an adversary's update rule exists.
- Real-time radar systems might achieve lower training overhead by embedding these estimators instead of relying on generic gradient methods.
- The framework invites hybrid designs that combine OCO regret guarantees with occasional model-based corrections when jammer behavior drifts.
Load-bearing premise
The radar-jammer interaction must be accurately representable as a convex optimization problem and the jammer's structure must allow construction of unbiased gradient estimators inside that framework.
What would settle it
A simulation run in which the refined algorithms produce regret curves or anti-jamming success rates no better than those of standard OCO would falsify the claimed improvement.
Figures
read the original abstract
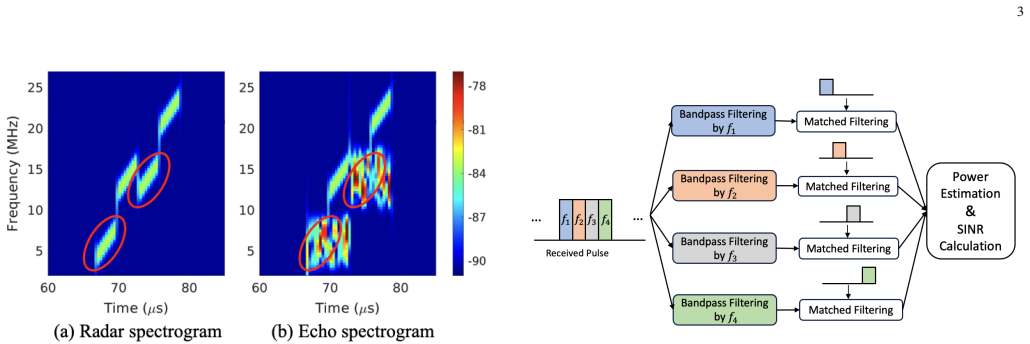
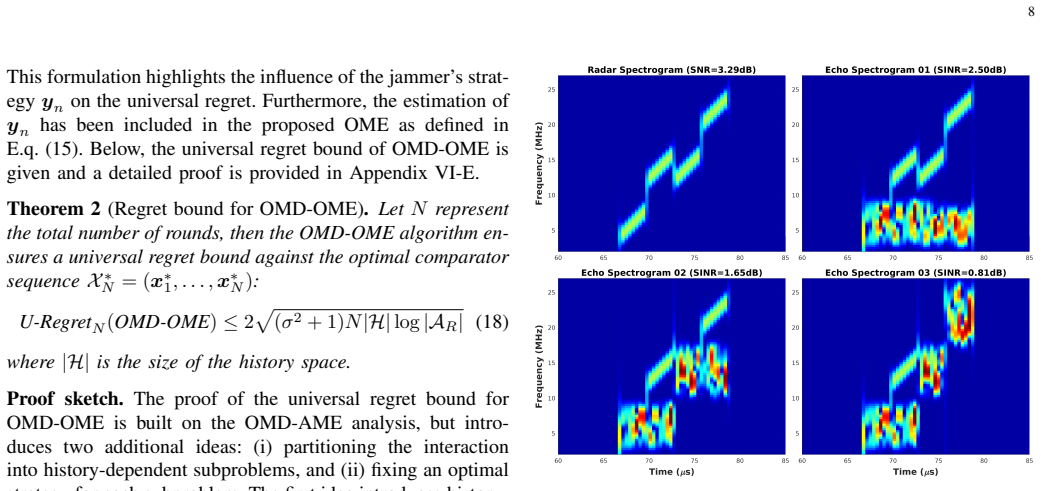
The dynamic competition against intelligent jammer systems presents a significant challenge to modern radar. Traditional active anti-jamming strategy learning methods often suffer from low sample efficiency and fail to fully exploit the structures of the adversary jammer. To reveal the inherent structure, this paper adopts an Online Convex Optimization (OCO) framework to capture the competition between a frequency agile radar and a digital radio frequency memory (DRFM)-based intelligent jammer. Recognizing that conventional OCO algorithms also suffer from suboptimal sample efficiency, two refined algorithms are developed that incorporate unbiased gradient estimators specifically tailored to the unique characteristics of DRFM-based jammers. Our theoretical analysis of the regret bound indicates significant improvements in long-term performance compared to standard OCO. The simulation results consistently show that our algorithms outperform traditional OCO and reinforcement learning baselines, achieving faster convergence and better anti-jamming performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models the dynamic competition between a frequency-agile radar and a DRFM-based intelligent jammer as an online convex optimization (OCO) problem. It develops two refined OCO algorithms incorporating unbiased gradient estimators that exploit the jammer's memory and replay structure, claiming improved regret bounds over standard OCO and superior empirical performance (faster convergence, better anti-jamming) versus both OCO and reinforcement-learning baselines.
Significance. If the per-round loss is convex in the radar action and the proposed estimators are unbiased, the work would strengthen the applicability of OCO to structured adversarial radar-jammer settings by delivering both tighter theoretical guarantees and practical sample-efficiency gains, as demonstrated in the reported simulations.
major comments (2)
- [Problem formulation and loss definition] The modeling of the radar-DRFM interaction as a convex OCO problem is load-bearing for all regret claims, yet the effective loss (e.g., detection probability or post-jammer SINR) is not shown to be convex in the radar's frequency choice. DRFM replay and signal-dependent interference can produce history-dependent, non-convex responses; without an explicit verification or proof that convexity is preserved under the DRFM model, the standard OCO regret machinery does not apply.
- [Algorithm development and regret analysis] The unbiasedness of the two tailored gradient estimators is asserted but not derived in detail. Because the estimators rely on estimates of the jammer's internal state, any bias introduced by finite memory, estimation error, or the replay mechanism would invalidate the claimed regret improvement; a full bias analysis (including variance bounds) is required.
minor comments (2)
- [Numerical results] The simulation section should report exact jammer parameters (memory length, replay probability, power levels) and radar action discretization to permit reproduction of the reported convergence curves.
- [Preliminaries] Notation for the action set, loss function, and gradient estimator should be introduced once and used consistently; several symbols appear to be redefined across sections.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments on our manuscript. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the theoretical foundations without altering the core contributions.
read point-by-point responses
-
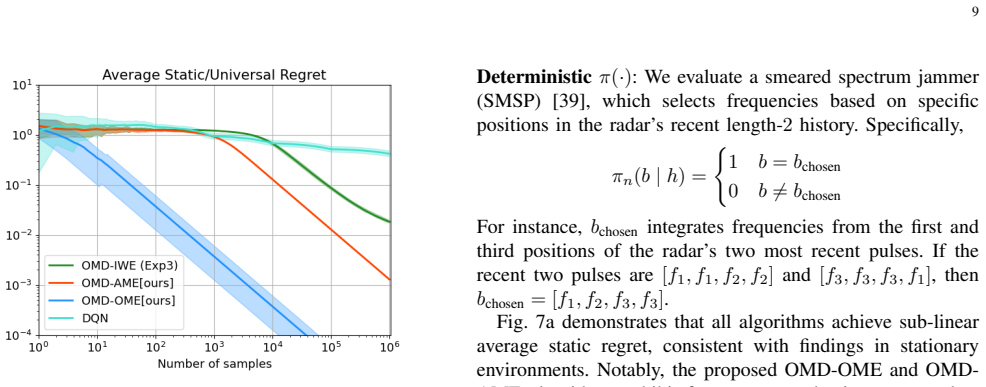
Referee: [Problem formulation and loss definition] The modeling of the radar-DRFM interaction as a convex OCO problem is load-bearing for all regret claims, yet the effective loss (e.g., detection probability or post-jammer SINR) is not shown to be convex in the radar's frequency choice. DRFM replay and signal-dependent interference can produce history-dependent, non-convex responses; without an explicit verification or proof that convexity is preserved under the DRFM model, the standard OCO regret machinery does not apply.
Authors: We appreciate this observation, as convexity is indeed foundational. In the manuscript, the radar action is the instantaneous frequency choice and the per-round loss is the resulting post-jamming SINR (or detection probability), which is convex in the chosen frequency for a fixed jammer state because interference power is a convex function of frequency mismatch. The DRFM replay introduces history dependence through the jammer's internal state, but the instantaneous loss at each round remains convex in the current action once the state is fixed. To make this rigorous and address the referee's concern directly, we will add an explicit lemma and proof in the revised manuscript (new Section 3.1) showing that the effective loss is convex under the stated DRFM model assumptions. This will confirm the applicability of standard OCO regret bounds as a baseline before presenting our refined estimators. revision: yes
-
Referee: [Algorithm development and regret analysis] The unbiasedness of the two tailored gradient estimators is asserted but not derived in detail. Because the estimators rely on estimates of the jammer's internal state, any bias introduced by finite memory, estimation error, or the replay mechanism would invalidate the claimed regret improvement; a full bias analysis (including variance bounds) is required.
Authors: We agree that a detailed derivation is necessary for the claimed regret improvements. The manuscript describes the two DRFM-specific estimators (one exploiting replay memory and one using an unbiased reconstruction of the jammer state) but presents their unbiasedness primarily through high-level arguments rather than full derivations. In the revision we will expand the analysis (new Appendix B) to include: (i) step-by-step proofs that both estimators are unbiased conditional on the jammer's finite memory and replay structure, (ii) explicit bounds on the bias introduced by state estimation error, and (iii) variance bounds that are used to derive the improved regret rates. These additions will directly support the theoretical claims and allow readers to verify the conditions under which the regret improvement holds. revision: yes
Circularity Check
No significant circularity in the OCO modeling or regret analysis
full rationale
The paper adopts the established OCO framework to model radar-DRFM interaction (a standard modeling choice requiring per-round convexity), then constructs tailored unbiased gradient estimators that exploit DRFM memory structure and derives improved regret bounds from the standard OCO machinery applied to these estimators. No load-bearing step reduces by construction to its own inputs: the regret improvement follows from the new estimator variance reduction, not from re-labeling a fit or from a self-citation chain. Simulations supply independent empirical checks. Convexity is an explicit modeling assumption rather than a derived claim that loops back to itself. This matches the reader's assessment of low circularity risk.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The anti-jamming competition between frequency agile radar and DRFM jammer can be modeled as an online convex optimization problem.
- domain assumption Unbiased gradient estimators can be constructed that are tailored to the unique characteristics of DRFM-based jammers.
Reference graph
Works this paper leans on
-
[1]
Radar anti-jamming strategy learning via domain-knowledge enhanced online convex optimization,
L. Liu, W. Pu, Y . Li, B. Jiu, and Z.-Q. Luo, “Radar anti-jamming strategy learning via domain-knowledge enhanced online convex optimization,” in2024 IEEE 13rd Sensor Array and Multichannel Signal Processing Workshop (SAM). IEEE, 2024, pp. 1–5
work page 2024
-
[2]
Adamy,EW 101: A first course in electronic warfare
D. Adamy,EW 101: A first course in electronic warfare. Artech house, 2001, vol. 101
work page 2001
-
[3]
De Martino,Introduction to modern EW systems
A. De Martino,Introduction to modern EW systems. Artech house, 2018
work page 2018
-
[4]
A. E. Spezio, “Electronic warfare systems,”IEEE Transactions on Microwave Theory and Techniques, vol. 50, no. 3, pp. 633–644, 2002
work page 2002
-
[5]
Radar anti-jamming techniques,
M. V . Maksimov, M. Bobnev, L. N. Shustov, B. Krivitskii, G. I. Gor- gonov, V . Ilin, and B. M. Stepanov, “Radar anti-jamming techniques,” Dedham, 1979
work page 1979
-
[6]
Anti-monopulse jamming techniques,
F. Neri, “Anti-monopulse jamming techniques,” inProceedings of the 2001 SBMO/IEEE MTT-S International Microwave and Optoelectronics Conference.(Cat. No. 01TH8568), vol. 2. IEEE, 2001, pp. 45–50
work page 2001
-
[7]
Mainlobe jamming sup- pression via blind source separation,
M. Ge, G. Cui, X. Yu, D. Huang, and L. Kong, “Mainlobe jamming sup- pression via blind source separation,” in2018 IEEE Radar Conference (RadarConf18). Oklahoma City, OK: IEEE, Apr. 2018, pp. 0914–0918
work page 2018
-
[8]
Analysis of Random step frequency radar and comparison with experiments,
S. R. J. Axelsson, “Analysis of Random step frequency radar and comparison with experiments,”IEEE Transactions on Geoscience and Remote Sensing, vol. 45, no. 4, pp. 890–904, Apr. 2007
work page 2007
-
[9]
Coherent signal processing method for frequency-agile radar,
R. Zhou, G. Xia, Y . Zhao, and H. Liu, “Coherent signal processing method for frequency-agile radar,” in2015 12th IEEE International Con- ference on Electronic Measurement & Instruments (ICEMI). Qingdao, China: IEEE, Jul. 2015, pp. 431–434
work page 2015
-
[10]
Generalized multicarrier radar: Models and performance,
M. Bica and V . Koivunen, “Generalized multicarrier radar: Models and performance,”IEEE Transactions on Signal Processing, vol. 64, no. 17, pp. 4389–4402, Sep. 2016
work page 2016
-
[11]
K. Li, B. Jiu, P. Wang, H. Liu, and Y . Shi, “Radar active antagonism through deep reinforcement learning: A way to address the challenge of mainlobe jamming,”Signal Processing, vol. 186, p. 108130, Sep. 2021
work page 2021
-
[12]
Deep q-network based anti-jamming strategy design for frequency agile radar,
K. Li, B. Jiu, and H. Liu, “Deep q-network based anti-jamming strategy design for frequency agile radar,” in2019 International Radar Conference (RADAR). IEEE, Sep. 2019, pp. 1–5. 14
work page 2019
-
[13]
Airborne radar anti-jamming waveform design based on deep reinforcement learning,
Z. Zheng, W. Li, and K. Zou, “Airborne radar anti-jamming waveform design based on deep reinforcement learning,”Sensors, vol. 22, no. 22, p. 8689, Nov. 2022
work page 2022
-
[14]
The MIMO radar and jammer games,
X. Song, P. Willett, S. Zhou, and P. B. Luh, “The MIMO radar and jammer games,”IEEE Transactions on Signal Processing, vol. 60, no. 2, pp. 687–699, Feb. 2012
work page 2012
-
[15]
MIMO radar and target Stackelberg game in the presence of clutter,
X. Lan, W. Li, X. Wang, J. Yan, and M. Jiang, “MIMO radar and target Stackelberg game in the presence of clutter,”IEEE Sensors Journal, vol. 15, no. 12, pp. 6912–6920, Dec. 2015
work page 2015
-
[16]
Neural fictitious self-play for radar antijamming dynamic game with imperfect information,
K. Li, B. Jiu, W. Pu, H. Liu, and X. Peng, “Neural fictitious self-play for radar antijamming dynamic game with imperfect information,”IEEE Transactions on Aerospace and Electronic Systems, vol. 58, no. 6, pp. 5533–5547, Dec. 2022
work page 2022
-
[17]
Counterfactual regret minimization for anti-jamming game of frequency agile radar,
H. Li, Z. Han, W. Pu, L. Liu, K. Li, and B. Jiu, “Counterfactual regret minimization for anti-jamming game of frequency agile radar,” in2022 IEEE 12th Sensor Array and Multichannel Signal Processing Workshop (SAM). IEEE, 2022, pp. 111–115
work page 2022
-
[18]
Radar and jammer intelligent game under jamming power dynamic allocation,
J. Geng, B. Jiu, K. Li, Y . Zhao, H. Liu, and H. Li, “Radar and jammer intelligent game under jamming power dynamic allocation,”Remote Sensing, vol. 15, no. 3, p. 581, Jan. 2023
work page 2023
-
[19]
A radar anti-jamming strategy optimisation based on Stackelberg game,
C. Feng, X. Fu, J. Dong, C. Zhao, H. Chang, P. Lang, and T. Pan, “A radar anti-jamming strategy optimisation based on Stackelberg game,” IET Radar, Sonar & Navigation, pp. 1248–1258, May 2023
work page 2023
-
[20]
Adaptation of frequency hopping interval for radar anti-jamming based on reinforcement learning,
Ailiya, W. Yi, and P. K. Varshney, “Adaptation of frequency hopping interval for radar anti-jamming based on reinforcement learning,”IEEE Transactions on Vehicular Technology, vol. 71, no. 12, pp. 12 434– 12 449, Dec. 2022
work page 2022
-
[21]
Y . Zhang, B. Jiu, X. Peng, H. Liu, and W. Jiang, “A new scheme of target detection for pulse Doppler radar in interrupted sampling repeater jamming environment,”IET Radar, Sonar & Navigation, vol. 16, no. 11, pp. 1836–1850, Nov. 2022
work page 2022
-
[22]
Two-dimensional anti-jamming communication based on deep reinforcement learning,
G. Han, L. Xiao, and H. V . Poor, “Two-dimensional anti-jamming communication based on deep reinforcement learning,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Mar. 2017, pp. 2087–2091
work page 2017
-
[23]
Online convex programming and generalized infinitesi- mal gradient ascent,
M. Zinkevich, “Online convex programming and generalized infinitesi- mal gradient ascent,” inProceedings of the 20th international conference on machine learning (ICML’03), 2003, pp. 928–936
work page 2003
-
[24]
Online learning and online convex optimiza- tion,
S. Shalev-Shwartzet al., “Online learning and online convex optimiza- tion,”Foundations and Trends® in Machine Learning, vol. 4, no. 2, pp. 107–194, 2012
work page 2012
-
[25]
Logarithmic regret algorithms for online convex optimization,
E. Hazan, A. Agarwal, and S. Kale, “Logarithmic regret algorithms for online convex optimization,”Machine Learning, vol. 69, no. 2, pp. 169– 192, 2007
work page 2007
-
[26]
A real-time and protocol-aware reactive jamming framework built on software-defined radios,
D. Nguyen, C. Sahin, B. Shishkin, N. Kandasamy, and K. R. Dandekar, “A real-time and protocol-aware reactive jamming framework built on software-defined radios,” inProceedings of the 2014 ACM Workshop on Software Radio Implementation Forum, Aug. 2014, pp. 15–22
work page 2014
-
[27]
A survey of radar ECM and ECCM,
L. Neng-Jing and Z. Yi-Ting, “A survey of radar ECM and ECCM,” IEEE Transactions on Aerospace and Electronic Systems, vol. 31, no. 3, pp. 1110–1120, 1995
work page 1995
-
[28]
Mathematic principles of interrupted-sampling repeater jamming (ISRJ),
X. Wang, J. Liu, W. Zhang, Q. Fu, Z. Liu, and X. Xie, “Mathematic principles of interrupted-sampling repeater jamming (ISRJ),”Science in China Series F: Information Sciences, vol. 50, pp. 113–123, 2007
work page 2007
-
[29]
Radar compound jamming cognition based on a deep object detection network,
J. Zhang, Z. Liang, C. Zhou, Q. Liu, and T. Long, “Radar compound jamming cognition based on a deep object detection network,”IEEE Transactions on Aerospace and Electronic Systems, vol. 59, no. 3, pp. 3251–3263, 2022
work page 2022
-
[30]
Introduction to online convex optimization,
E. Hazan, “Introduction to online convex optimization,” Aug. 2023
work page 2023
-
[31]
Extracting certainty from uncertainty: Regret bounded by variation in costs,
E. Hazan and S. Kale, “Extracting certainty from uncertainty: Regret bounded by variation in costs,”Machine learning, vol. 80, pp. 165–188, 2010
work page 2010
-
[32]
T. Lattimore and C. Szepesv ´ari,Bandit algorithms, 1st ed. Cambridge University Press, Jul. 2020
work page 2020
-
[33]
The non- stochastic multiarmed bandit problem,
P. Auer, N. Cesa-Bianchi, Y . Freund, and R. E. Schapire, “The non- stochastic multiarmed bandit problem,”SIAM Journal on Computing, vol. 32, no. 1, pp. 48–77, Jan. 2002
work page 2002
-
[34]
Modern techniques of power spectrum estimation,
C. Bingham, M. Godfrey, and J. Tukey, “Modern techniques of power spectrum estimation,”IEEE Transactions on Audio and Electroacoustics, vol. 15, no. 2, pp. 56–66, 1967
work page 1967
-
[35]
Boashash,Time-frequency signal analysis and processing: A compre- hensive reference
B. Boashash,Time-frequency signal analysis and processing: A compre- hensive reference. Academic press, 2015
work page 2015
-
[36]
Power spectrum parameter estimation,
M. Levin, “Power spectrum parameter estimation,”IEEE Transactions on Information Theory, vol. 11, no. 1, pp. 100–107, 1965
work page 1965
-
[37]
Digital radio frequency memory,
S. Roome, “Digital radio frequency memory,”Electronics & Communi- cation Engineering Journal, vol. 2, no. 4, pp. 147–153, 1990
work page 1990
-
[38]
Digital radio frequency memory linear range gate stealer spectrum,
S. D. Berger, “Digital radio frequency memory linear range gate stealer spectrum,”IEEE Transactions on Aerospace and Electronic Systems, vol. 39, no. 2, pp. 725–735, 2003
work page 2003
-
[39]
Suppression of smeared spectrum ECM signal,
M.-H. Sun and B. Tang, “Suppression of smeared spectrum ECM signal,”Journal of the Chinese Institute of Engineers, vol. 32, no. 3, pp. 407–413, 2009
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.