Recognition: unknown
Ti-Audio: The First Multi-Dialectal End-to-End Speech LLM for Tibetan
Pith reviewed 2026-05-10 15:53 UTC · model grok-4.3
The pith
Ti-Audio is the first multi-dialectal end-to-end Speech LLM for Tibetan, reaching state-of-the-art results on automatic speech recognition and speech translation by using cross-dialect cooperation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ti-Audio is the first multi-dialectal end-to-end Speech-LLM for Tibetan. To align speech and text, it uses a Dynamic Q-Former Adapter that extracts essential acoustic features from variable-length inputs, keeping cross-modal alignment stable even with limited data. At the data level, mutual assistance among the U-Tsang, Amdo, and Kham dialects is achieved through a temperature-based sampling strategy that maximizes synergy. The resulting model delivers state-of-the-art performance on Tibetan benchmarks for automatic speech recognition and speech translation.
What carries the argument
The Dynamic Q-Former Adapter, which dynamically extracts essential acoustic features from variable-length speech inputs to maintain stable cross-modal alignment with the language model under data constraints.
If this is right
- Cross-dialectal cooperation via temperature sampling reduces the data needed to train effective Speech-LLMs for Tibetan.
- The Dynamic Q-Former Adapter supplies a practical method for stable speech-to-text alignment when training examples are scarce.
- The same combination of dialect synergy and dynamic adaptation supplies a scalable route to Speech-LLMs in other low-resource, dialect-diverse environments.
- Tibetan speakers gain improved automatic recognition and translation across all three major dialects from a single model.
Where Pith is reading between the lines
- The same temperature-sampling approach could be tested on other dialect clusters, such as Arabic or Chinese regional varieties, to check whether the synergy effect generalizes.
- The work implies that treating closely related speech varieties as a single pooled resource may outperform training separate models for each variety.
- Future extensions could measure whether the Dynamic Q-Former Adapter also helps when adding new dialects or when speech inputs vary in noise level.
Load-bearing premise
That mutual assistance among related dialects via temperature-based sampling can effectively alleviate data scarcity and that the Dynamic Q-Former Adapter ensures stable cross-modal alignment even with limited data.
What would settle it
An ablation experiment in which Ti-Audio without temperature-based sampling or without the Dynamic Q-Former Adapter performs no better than prior single-dialect Tibetan models on the ASR and speech translation benchmarks.
Figures
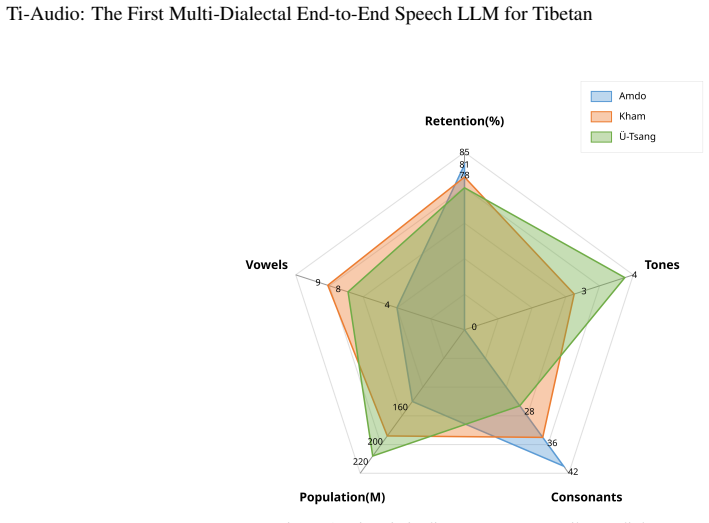



read the original abstract
Recent advances in Speech Large Language Models (Speech-LLMs) have made significant progress, greatly enhancing multimodal interaction capabilities.However, their application in low-resource and dialect-diverse environments still faces challenges. The severe scarcity of Tibetan data, coupled with the phonetic differences among its major dialects (\"U-Tsang, Amdo, and Kham), is a prime example of this challenge. This paper proposes Ti-Audio, the first multi-dialectal end-to-end Speech-LLM for Tibetan. To efficiently align speech and text, we introduce a Dynamic Q-Former Adapter that extracts essential acoustic features from variable-length speech, ensuring stable cross-modal alignment even with limited data. At the data level, we leverage mutual assistance among related dialects to alleviate data scarcity and employ a temperature-based sampling strategy to maximize this synergy. Experimental results demonstrate that Ti-Audio achieves state-of-the-art performance on Tibetan benchmarks for automatic speech recognition and speech translation. Our work validates the effectiveness of cross-dialectal cooperation and provides a scalable paradigm for the development of Speech-LLM in low-resource scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Ti-Audio as the first multi-dialectal end-to-end Speech LLM for Tibetan, addressing data scarcity via a Dynamic Q-Former Adapter for stable speech-text alignment on variable-length inputs and a temperature-based sampling strategy that exploits mutual assistance across the U-Tsang, Amdo, and Kham dialects. It claims state-of-the-art results on Tibetan automatic speech recognition and speech translation benchmarks.
Significance. If the performance gains are substantiated, the work would offer a practical paradigm for Speech-LLMs in low-resource, dialect-diverse languages by showing how cross-dialect cooperation can mitigate data limitations.
major comments (3)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The SOTA claim on Tibetan ASR and translation benchmarks is asserted without reported numerical metrics (e.g., WER/CER or BLEU scores), baseline model names, per-dialect test-set sizes, or statistical significance; this directly undermines evaluation of the central performance claim.
- [§3.2 (Data Strategy)] §3.2 (Data Strategy): No ablation results are provided comparing the temperature-based sampling against uniform sampling or single-dialect training on held-out test sets; without these numbers the assertion that mutual assistance measurably alleviates scarcity cannot be verified.
- [§3.1 (Model Architecture)] §3.1 (Model Architecture): The Dynamic Q-Former Adapter is described as ensuring stable cross-modal alignment with limited data, yet no comparison to a standard Q-Former or ablation on its dynamic components is reported, leaving its contribution to the SOTA result unquantified.
minor comments (2)
- [Introduction] Introduction: The statement that Ti-Audio is 'the first' multi-dialectal Tibetan Speech LLM would benefit from a short citation of prior Tibetan ASR or Speech-LLM efforts to contextualize novelty.
- [Figure 1 (Architecture)] Figure 1 (Architecture): Ensure the diagram explicitly annotates the temperature parameter and how the Dynamic Q-Former processes variable-length inputs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We will revise the manuscript to incorporate explicit numerical results, additional ablations, and direct comparisons as requested, thereby strengthening the substantiation of our claims regarding the Dynamic Q-Former Adapter and cross-dialect sampling strategy.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The SOTA claim on Tibetan ASR and translation benchmarks is asserted without reported numerical metrics (e.g., WER/CER or BLEU scores), baseline model names, per-dialect test-set sizes, or statistical significance; this directly undermines evaluation of the central performance claim.
Authors: We appreciate this observation. While §4 presents comparative results supporting the SOTA claim, we agree that the abstract and main text would benefit from greater explicitness. In the revised manuscript, we will report the specific WER/CER scores for ASR and BLEU scores for speech translation achieved by Ti-Audio and all baselines, include the per-dialect test-set sizes, and add statistical significance testing (e.g., bootstrap confidence intervals or paired significance tests) to rigorously support the performance claims. revision: yes
-
Referee: [§3.2 (Data Strategy)] §3.2 (Data Strategy): No ablation results are provided comparing the temperature-based sampling against uniform sampling or single-dialect training on held-out test sets; without these numbers the assertion that mutual assistance measurably alleviates scarcity cannot be verified.
Authors: We agree that explicit ablations are required to verify the benefit of the temperature-based sampling. In the revision, we will add ablation experiments comparing the proposed temperature-based strategy against uniform sampling and single-dialect training, reporting ASR and translation performance on held-out test sets for each dialect (U-Tsang, Amdo, Kham). These results will quantify the measurable gains from cross-dialect cooperation. revision: yes
-
Referee: [§3.1 (Model Architecture)] §3.1 (Model Architecture): The Dynamic Q-Former Adapter is described as ensuring stable cross-modal alignment with limited data, yet no comparison to a standard Q-Former or ablation on its dynamic components is reported, leaving its contribution to the SOTA result unquantified.
Authors: We thank the referee for highlighting this gap. To isolate the contribution of the dynamic components, we will include a direct ablation in the revised manuscript comparing the Dynamic Q-Former Adapter against a standard (non-dynamic) Q-Former. We will report the resulting differences in ASR and translation metrics to demonstrate the improvement in cross-modal alignment stability under data scarcity. revision: yes
Circularity Check
No circularity detected; empirical validation stands independent of inputs
full rationale
The paper introduces a model architecture (Dynamic Q-Former Adapter) and a data-sampling heuristic (temperature-based cross-dialect sampling) as engineering choices, then reports benchmark performance numbers. No equations, uniqueness theorems, or fitted parameters are presented as deriving further results by construction. The SOTA claim rests on held-out test metrics rather than reducing to the definition of the proposed components or to self-citations. Self-citations, if present, are not load-bearing for the central performance assertion. This is a standard empirical ML paper whose derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Related Tibetan dialects can provide mutual assistance to alleviate data scarcity.
- domain assumption The Dynamic Q-Former Adapter can extract essential acoustic features from variable-length speech for stable cross-modal alignment with limited data.
invented entities (1)
-
Dynamic Q-Former Adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brown, Benjamin Mann, Nick Ryder, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Lucian Koppstein, et al. Flamingo: a visual language model for few-shot learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[3]
Hello gpt-4o.https://openai.com/index/hello-gpt-4o/, 2024
OpenAI. Hello gpt-4o.https://openai.com/index/hello-gpt-4o/, 2024. Accessed: 2026-01-20
2024
-
[4]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities
Dong Zhang, Shumin Li, Nan Zhang, et al. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[5]
Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11818–11832, 2024
2024
-
[6]
Salmonn: Towards generic hearing abilities for large language models
Shuohuang Tang, Ziyang Ma, Yi-Zhe Li, et al. Salmonn: Towards generic hearing abilities for large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[7]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 28448–28485, 2023
2023
-
[8]
Scaling speech technology to 1,000+ languages.Journal of Machine Learning Research (JMLR), 25(97):1–52, 2024
Vineel Pratap, Andros Tjandra, Bowen Bowen, Zhaoheng Nie, Kenneth Rivera, Wei Galuba, Maryam Fazel- Zarandi, Alexei Baevski, Michael Auli, et al. Scaling speech technology to 1,000+ languages.Journal of Machine Learning Research (JMLR), 25(97):1–52, 2024
2024
-
[9]
Investigating decoder-only large language models for speech-to-text translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, and Sravya Popuri. Investigating decoder-only large language models for speech-to-text translation. InProc. INTERSPEECH 2024, pages 2455–2459, 2024
2024
-
[10]
Multilingual denoising pre-training for neural machine translation
Yinhan Liu, Jiatao Gu, Naman Goyal, et al. Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics (TACL), 2020
2020
-
[11]
A multi-dialect tibetan speech corpus and baseline systems for iscslp 2020 challenge
Hongjie Li, Xinyuan Duan, et al. A multi-dialect tibetan speech corpus and baseline systems for iscslp 2020 challenge. InProceedings of the 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), pages 1–5, 2020
2020
-
[12]
TibMD: A multi-dialect tibetan speech corpus for automatic speech recognition.IEEE Access, 9:26489–26497, 2021
Rui Duan, Biljana Ignjatovic, Jinyu Li, and Yue Zhao. TibMD: A multi-dialect tibetan speech corpus for automatic speech recognition.IEEE Access, 9:26489–26497, 2021
2021
-
[13]
Snow Lion Publications, Ithaca, NY , 2003
Nicolas Tournadre and Sangda Dorje.Manual of Standard Tibetan: Language and Civilization. Snow Lion Publications, Ithaca, NY , 2003
2003
-
[14]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[15]
AudioGPT: Understanding and generating speech, music, sound, and talking head
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Yuexian Zou, Zhou Zhao, and Shinji Watanabe. AudioGPT: Understanding and generating speech, music, sound, and talking head. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 23802–2380...
2024
-
[16]
Blending llms into cascaded speech translation: Kit’s offline speech translation system for iwslt 2024, 2024
Sai Koneru, Thai-Binh Nguyen, Ngoc-Quan Pham, Danni Liu, Zhaolin Li, Alexander Waibel, and Jan Niehues. Blending llms into cascaded speech translation: Kit’s offline speech translation system for iwslt 2024, 2024
2024
-
[17]
Tight integrated end-to-end training for cascaded speech translation
Parnia Bahar, Tobias Bieschke, Ralf Schlüter, and Hermann Ney. Tight integrated end-to-end training for cascaded speech translation. InINTERSPEECH 2020, pages 1161–1165, 2020
2020
-
[18]
When end-to-end is overkill: Rethinking cascaded speech-to-text translation
Anna Min, Chenxu Hu, Yi Ren, and Hang Zhao. When end-to-end is overkill: Rethinking cascaded speech-to-text translation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[19]
wav2vec 2.0: A framework for self- supervised learning of speech representations
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self- supervised learning of speech representations. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 12449–12460. Curran Associates, Inc., 2020
2020
-
[20]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdel- rahman Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
2021
-
[21]
AudioPaLM: A large language model that can speak and listen
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chau- mont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. AudioPaLM: A large language model that can speak and listen. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[22]
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, Singapore, December 2023. Association for Computational Linguistics
2023
-
[23]
Speech LLMs in low-resource scenarios: Data volume requirements and the impact of pretraining on high-resource languages
Seraphina Fong, Marco Matassoni, and Alessio Brutti. Speech LLMs in low-resource scenarios: Data volume requirements and the impact of pretraining on high-resource languages. InProc. INTERSPEECH 2025, 2025
2025
-
[24]
Recent advances in speech language models: A survey
Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, and Irwin King. Recent advances in speech language models: A survey. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13943–13970, 2025
2025
-
[25]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
Soundwave: Less is more for speech-text alignment in llms
Yuhao Zhang, Zhiheng Liu, Fan Bu, Ruiyu Zhang, Benyou Wang, et al. Soundwave: Less is more for speech-text alignment in llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18718–18738, 2025
2025
-
[27]
Towards Building Speech Large Language Models for Multitask Understanding in Low-Resource Languages
Mingchen Shao, Bingshen Mu, Chengyou Wang, Hai Li, Ying Yan, Zhonghua Fu, and Lei Xie. Towards building speech large language models for multitask understanding in low-resource languages.arXiv preprint arXiv:2509.14804, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
DialectMoE: An end-to-end multi-dialect speech recognition model with mixture-of-experts
Jie Zhou, Shengxiang Gao, Zhengtao Yu, Ling Dong, and Wenjun Wang. DialectMoE: An end-to-end multi-dialect speech recognition model with mixture-of-experts. InProceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference), pages 1055–1066, Taiyuan, China, July 2024. Chinese Information Processing Society of China
2024
-
[29]
Dynamic adapter meets prompt tuning: Parameter-efficient transfer learning for point cloud analysis
Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, and Xiang Bai. Dynamic adapter meets prompt tuning: Parameter-efficient transfer learning for point cloud analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[30]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Represen- tations (ICLR), 2022
2022
-
[31]
mHuBERT-147: A compact multilingual HuBERT model
Marcely Zanon Boito, Vivek Iyer, Nikolaos Lagos, Laurent Besacier, and Ioan Calapodescu. mHuBERT-147: A compact multilingual HuBERT model. InProc. INTERSPEECH 2024, pages 3939–3943, 2024
2024
-
[32]
(tilamb: A tibetan large language model based on incremental pre-training
Zhuang Wenhao, Sun Yuan, and Zhao Xiaobing. (tilamb: A tibetan large language model based on incremental pre-training. InProceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference), pages 254–267, 2024
2024
-
[33]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations (ICLR), 2019. 11 Ti-Audio: The First Multi-Dialectal End-to-End Speech LLM for Tibetan
2019
-
[35]
Free linguistic and speech resources for tibetan
Guanyu Li, Hongzhi Yu, Thomas Zheng, Jinghao Yan, and Shipeng Xu. Free linguistic and speech resources for tibetan. InAPSIPA ASC, 2017
2017
-
[36]
An open speech resource for Tibetan multi-dialect and multitask recognition.International Journal of Computational Science and Engineering, 22(2-3):297–304, 2020
Yue Zhao, Xiaona Xu, Jianjian Yue, Wei Song, Xiali Li, Licheng Wu, and Qiang Ji. An open speech resource for Tibetan multi-dialect and multitask recognition.International Journal of Computational Science and Engineering, 22(2-3):297–304, 2020
2020
-
[37]
XBMU-AMDO31: An amdo tibetan speech corpus for automatic speech recognition
Yue Zhao, Xiaosong Yang, Hongzhi Yu, Thomas Zheng, Jinghao Yan, and Shipeng Xu. XBMU-AMDO31: An amdo tibetan speech corpus for automatic speech recognition. In2021 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), pages 1–5. IEEE, 2021
2021
-
[38]
Tibetan Greetings: Selected tibetan greetings speech data.http://www.openslr.org/149/, 2023
Linfei Lu, Jiaxin Pang, Stansencuo, Buwonglam, and Linting Huang. Tibetan Greetings: Selected tibetan greetings speech data.http://www.openslr.org/149/, 2023. OpenSLR-149
2023
-
[39]
Emotion recognition in lhasa tibetan speech based on bi-lstm graph convolutional networks.Frontiers in Computing and Intelligent Systems, 8(2):29–34, 2024
Ang Chen, Rongzhao Huang, Tong Xi, Liang Wu, and Wangdui Bianba. Emotion recognition in lhasa tibetan speech based on bi-lstm graph convolutional networks.Frontiers in Computing and Intelligent Systems, 8(2):29–34, 2024
2024
-
[40]
A comprehensive survey on cross-lingual transfer for low-resource neural machine translation.ACM Computing Surveys, 56(2), 2023
Zihan Wang, Huangzhao Zhang, Bin Chen, Zonghong Huang, et al. A comprehensive survey on cross-lingual transfer for low-resource neural machine translation.ACM Computing Surveys, 56(2), 2023. 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.