Divergence-Guided Particle Swarm Optimization
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
DPSO adds a KL-divergence repulsion term to the PSO velocity update to reduce premature convergence on multimodal problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
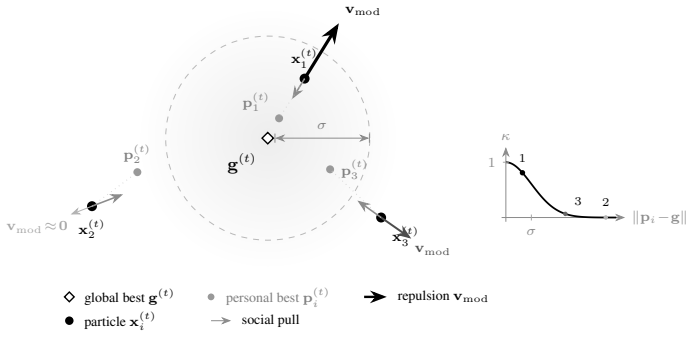
DPSO augments the standard PSO velocity update with a modulation term that repels particles based on the similarity of their personal best to the global best, where the similarity is a Gaussian kernel equivalent to an exponentially decaying function of the KL divergence between Gaussian embeddings of the positions. This provides a principled way to maintain diversity in the swarm on multimodal problems.
What carries the argument
The modulation term in the velocity update, gated by a Gaussian similarity kernel equivalent to an exponentially decaying function of the KL divergence between personal and global bests.
If this is right
- DPSO frequently outperforms standard PSO on multimodal benchmark functions with 2-8x gains on cases such as Pinter, Ackley, and Levy.
- Run-to-run variance drops by up to 5x on those multimodal problems.
- On unimodal landscapes the added term reduces performance, showing the method specifically targets the exploration-exploitation trade-off rather than improving PSO universally.
- The method requires one extra hyperparameter and adds 15-25% wall-clock time without raising asymptotic per-iteration complexity.
Where Pith is reading between the lines
- The divergence-based repulsion idea could be ported to other swarm or population methods to maintain diversity without redesigning their core update rules.
- Applying DPSO to real engineering design problems such as aerodynamic shape optimization or neural architecture search would test whether the benchmark gains translate to noisy or constrained settings.
- A theoretical follow-up could derive bounds on swarm diversity or convergence speed using the established link to f-divergences.
Load-bearing premise
The 36 benchmark functions and the specific Gaussian embedding of best positions are representative enough to show a general exploration-exploitation benefit.
What would settle it
Testing DPSO on a fresh collection of high-dimensional multimodal functions outside the original 36 benchmarks and finding no consistent improvement over standard PSO would falsify the claimed advantage.
Figures









read the original abstract
Particle Swarm Optimization (PSO) is susceptible to premature convergence when the swarm collapses around the global best, particularly on multimodal landscapes in higher dimensions. We propose Divergence-guided PSO (DPSO), which augments the velocity update with a modulation term that repels particles whose personal bests have converged near the global best. The repulsion is gated by a Gaussian similarity kernel, which we prove is equivalent to an exponentially decaying function of the KL divergence between Gaussian-embedded personal and global bests, connecting the mechanism to the family of $f$-divergences and providing a principled basis for kernel design. Experiments on 36 benchmark functions (15 unimodal, 21 multimodal) across dimensions $D \in \{10, 30, 50\}$, each with 30 independent runs, show that DPSO frequently outperforms standard PSO on multimodal problems, with improvements of 2-8$\times$ on functions such as Pinter, Ackley, and Levy, and up to 5$\times$ reduction in run-to-run variance. On unimodal landscapes the modulation term is counterproductive, confirming that DPSO targets the exploration-exploitation trade-off rather than offering a universal improvement. The method adds one hyperparameter, incurs 15--25\% wall-clock overhead, and does not increase the asymptotic per-iteration complexity of PSO. The project code is available here: https://github.com/Kleyt0n/dpso
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Divergence-guided Particle Swarm Optimization (DPSO), which augments the standard PSO velocity update with a repulsion term modulated by a Gaussian similarity kernel between personal-best and global-best positions. The authors derive that this kernel is equivalent to an exponentially decaying function of the KL divergence between Gaussian embeddings of the best positions, thereby connecting the mechanism to the family of f-divergences. Experiments on 36 benchmark functions (15 unimodal, 21 multimodal) in dimensions D in {10, 30, 50}, each with 30 independent runs, report that DPSO frequently outperforms standard PSO on multimodal problems (2-8x gains on functions such as Pinter, Ackley, and Levy, plus up to 5x variance reduction) while degrading performance on unimodal landscapes; the method adds one hyperparameter, incurs 15-25% wall-clock overhead, and preserves the asymptotic per-iteration complexity of PSO. Reproducible code is provided.
Significance. If the results hold, the work supplies a theoretically grounded, divergence-based modulation that specifically targets premature convergence on multimodal landscapes without altering PSO's core complexity. The equivalence proof, the contrasting uni- versus multimodal behavior, the standard experimental protocol (36 functions, multiple dimensions, 30 runs), and public code constitute clear strengths that support reproducibility and falsifiability. The approach could be useful for high-dimensional multimodal optimization tasks in engineering and machine learning, provided the benchmark gains generalize.
major comments (1)
- [§4] §4 (Experimental validation): The central claim that DPSO improves the exploration-exploitation trade-off rests on performance gains observed across the 36 chosen synthetic benchmarks; however, no transfer experiments on constrained problems, noisy landscapes, or real-world applications are reported. This assumption that the selected functions and Gaussian embedding are representative is load-bearing for the generalization stated in the abstract and conclusion.
minor comments (3)
- [Abstract] Abstract: The statement that the kernel 'connects the mechanism to the family of f-divergences' is mentioned without a one-sentence elaboration or pointer to the relevant derivation; adding a brief clause would improve accessibility.
- [§3.2] §3.2 (Kernel derivation): The proof that the Gaussian kernel equals an exponentially decaying KL term is presented as rigorous, yet the text does not explicitly state the embedding dimension or covariance assumptions used in the Gaussian placement of best positions; a short clarifying sentence would remove potential ambiguity.
- [Table 2] Table 2 (or equivalent results table): Reporting only mean and standard deviation without p-values or Wilcoxon signed-rank statistics for the 2-8x improvements leaves the statistical significance of the multimodal gains open to interpretation; adding a significance column would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the constructive comment on experimental scope. We address the major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experimental validation): The central claim that DPSO improves the exploration-exploitation trade-off rests on performance gains observed across the 36 chosen synthetic benchmarks; however, no transfer experiments on constrained problems, noisy landscapes, or real-world applications are reported. This assumption that the selected functions and Gaussian embedding are representative is load-bearing for the generalization stated in the abstract and conclusion.
Authors: We agree that the manuscript's validation is confined to standard synthetic benchmarks and that direct transfer results on constrained, noisy, or real-world problems are absent. This is a genuine limitation for broad generalization claims. The core contribution lies in the divergence-based derivation and the controlled demonstration that the repulsion term improves multimodal performance while harming unimodal cases, using the conventional 36-function protocol with multiple dimensions and 30 runs. In revision we will (i) qualify the abstract and conclusion to state that gains are shown on synthetic multimodal benchmarks, (ii) add an explicit limitations paragraph in the discussion that acknowledges the lack of real-world transfer experiments and outlines planned future work on constrained and noisy problems, and (iii) retain the benchmark results as evidence for the mechanism's targeted effect. These changes will be minor and will not alter the reported empirical findings or complexity analysis. revision: yes
Circularity Check
No circularity: derivation and equivalence are first-principles and self-contained.
full rationale
The paper's core contribution is an explicit augmentation of the PSO velocity update by a repulsion term whose gating kernel is shown mathematically equivalent to an exponentially decaying KL divergence between Gaussian embeddings of pbest and gbest. This equivalence follows directly from the definitions of the Gaussian kernel and KL divergence without any fitting or data-dependent choice. The experimental results on the 36 benchmarks are presented as empirical validation of the resulting exploration-exploitation behavior, not as inputs that define or force the algorithm. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the load-bearing derivation steps. The method therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- repulsion strength hyperparameter
axioms (2)
- domain assumption Gaussian distributions can be used to embed point positions for divergence calculation
- standard math KL divergence between two Gaussians yields a valid similarity measure for repulsion gating
Reference graph
Works this paper leans on
-
[1]
M. Clerc and J. Kennedy. The particle swarm–explosion, stability, and convergence in a multidimen- sional complex space.IEEE Transactions on Evolutionary Computation, 6(1):58–73, 2002. 10 J. Duchi. Derivations for linear algebra and optimization. Technical report, University of California, Berkeley, 2007. D. v. Eschwege and A. Engelbrecht. Belief space-gu...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.