Recognition: unknown
REGREACT: Self-Correcting Multi-Agent Pipelines for Structured Regulatory Information Extraction
Pith reviewed 2026-05-10 14:58 UTC · model grok-4.3
The pith
A multi-agent system with Observe-Diagnose-Repair loops extracts more accurate structured regulatory criteria than single-pass language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RegReAct decomposes regulatory information extraction into seven specialized stages, each equipped with an Observe-Diagnose-Repair loop that validates and corrects outputs against the source, while constructing a typed criterion graph and resolving external dependencies through retrieval and inline summarization of referenced legal content to produce self-contained structured data.
What carries the argument
The Observe-Diagnose-Repair (ODR) loop applied across seven stages to validate against source and correct hallucinations plus regulatory errors.
If this is right
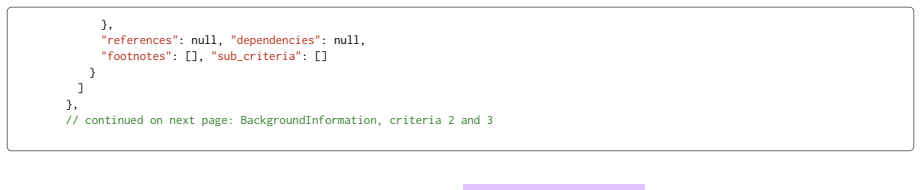
- The method produces a reusable dataset of 242 activities and over 4,800 hierarchical criteria, thresholds, and source summaries from EU Taxonomy documents.
- Outputs are self-contained because referenced legal content is retrieved, summarized, and embedded inline.
- Structural accuracy improves through explicit construction of a typed criterion graph.
- The pipeline outperforms a GPT-4o single-pass baseline on all reported structural and semantic metrics.
Where Pith is reading between the lines
- The same staged correction approach could be tested on other regulatory domains that contain dense cross-references, such as financial or environmental rules.
- Self-contained structured outputs may support downstream automated compliance checking without repeated lookups into original documents.
- If the loops generalize, similar multi-stage repair could be applied to extraction tasks in technical standards or scientific protocols that also suffer from inter-document dependencies.
Load-bearing premise
The Observe-Diagnose-Repair loops can reliably detect and correct model hallucinations as well as cross-reference errors in the regulations themselves without introducing new inaccuracies or requiring external human validation.
What would settle it
Manual inspection of the extracted dataset that reveals persistent uncorrected hallucinations or incorrect resolutions of cross-referenced regulatory content.
Figures







read the original abstract
Extracting structured, machine-readable compliance criteria from regulatory documents remains an open challenge. Single-pass language models hallucinate structural elements, lose hierarchical relationships, and fail to resolve inter-document dependencies. We introduce \textsc{RegReAct}, a self-correcting multi-agent framework that decomposes regulatory information extraction into seven specialized stages, each with an \textit{Observe--Diagnose--Repair} (ODR) loop that validates outputs against the source, correcting not only model hallucinations but also cross-reference errors in the regulations themselves. To ensure structural accuracy, \textsc{RegReAct} constructs a typed criterion graph; to ensure completeness, it resolves external dependencies by retrieving, summarizing, and embedding referenced legal content inline, producing self-contained outputs. Applying \textsc{RegReAct} to three EU Taxonomy Delegated Acts, we construct a dataset comprising 242 activities with over 4,800 hierarchical criteria, thresholds, and enriched source summaries. Evaluation against a GPT-4o single-pass baseline confirms that \textsc{RegReAct} outperforms it across all structural and semantic metrics. Code and data will be made publicly available: https://github.com/RECOR-Benchmark/RECOR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RegReAct, a self-correcting multi-agent framework that decomposes regulatory information extraction into seven specialized stages, each incorporating an Observe-Diagnose-Repair (ODR) loop. The framework builds a typed criterion graph for structural accuracy and resolves external dependencies by retrieving and embedding referenced legal content to produce self-contained outputs. Applied to three EU Taxonomy Delegated Acts, it constructs a dataset of 242 activities with over 4,800 hierarchical criteria, thresholds, and enriched summaries. The central empirical claim is that RegReAct outperforms a GPT-4o single-pass baseline across structural and semantic metrics. Code and data are promised to be released publicly.
Significance. If the ODR loops can be shown to improve extraction reliability without introducing new errors, the work would offer a practical advance for structured information extraction from complex legal texts and the released dataset could serve as a useful benchmark resource. The multi-agent decomposition and graph-based representation are conceptually sound contributions. The commitment to public code and data release is a clear strength supporting reproducibility.
major comments (1)
- Abstract and the description of the ODR loops: the claim that the framework corrects not only model hallucinations but also 'cross-reference errors in the regulations themselves' lacks any described external validation mechanism (human review, legal database lookup, or independent consistency check). This is load-bearing for the reliability of the 4,800+ criteria dataset and all reported performance gains, as model-driven corrections to source content could propagate inaccuracies.
minor comments (2)
- The abstract states outperformance 'across all structural and semantic metrics' without providing any quantitative values, tables, or error analysis; including key results (e.g., exact scores or ablation) in the abstract would strengthen the summary.
- The seven stages are referenced but not enumerated or diagrammed in the provided abstract; a concise overview table or figure early in the methods would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the opportunity to clarify our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: Abstract and the description of the ODR loops: the claim that the framework corrects not only model hallucinations but also 'cross-reference errors in the regulations themselves' lacks any described external validation mechanism (human review, legal database lookup, or independent consistency check). This is load-bearing for the reliability of the 4,800+ criteria dataset and all reported performance gains, as model-driven corrections to source content could propagate inaccuracies.
Authors: We agree that the abstract phrasing risks overstating the ODR loops' scope. The Observe-Diagnose-Repair process validates extracted outputs against the input source text and any retrieved referenced documents to ensure structural consistency and to inline external dependencies. This corrects model-induced errors (e.g., hallucinated hierarchies or missed cross-references) by re-grounding in the provided regulatory text. However, the framework does not include external legal validation, database lookups, or human review to correct substantive inaccuracies that may exist in the regulations themselves. We will revise the abstract and the ODR description in Section 3 to remove the claim about correcting 'cross-reference errors in the regulations themselves' and instead emphasize fidelity to source documents plus retrieval-based dependency resolution. We will also expand the methods to detail the exact validation steps within each ODR loop. These changes will appear in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical framework evaluation against external baseline
full rationale
The paper introduces RegReAct, a multi-agent pipeline with seven-stage Observe-Diagnose-Repair loops for regulatory extraction, then applies it to three EU Taxonomy Delegated Acts to produce a dataset of 242 activities and over 4,800 criteria. Performance is measured via direct comparison to a GPT-4o single-pass baseline on structural and semantic metrics. No equations, fitted parameters, self-referential definitions, or mathematical derivations appear in the described chain. The central results are empirical outputs from processing external regulatory texts, not reductions of predictions to inputs by construction. Any self-citations (if present) do not bear the load of the evaluation claims, which rest on observable dataset construction and metric improvements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can perform reliable self-diagnosis and repair of structural and referential errors in regulatory text extraction
Reference graph
Works this paper leans on
-
[1]
In2025 IEEE 33rd International Requirements Engineering Conference (RE), pages 142–154
Llm-assisted extraction of regulatory require- ments: A case study on the gdpr. In2025 IEEE 33rd International Requirements Engineering Conference (RE), pages 142–154. IEEE. Mohammed Ali, Abdelrahman Abdallah, Amit Agar- wal, Hitesh Laxmichand Patel, and Adam Jatowt
-
[2]
Reasoning-focused Multi-turn Conversational Retrieval Benchmark
Recor: Reasoning-focused multi-turn con- versational retrieval benchmark.arXiv preprint arXiv:2601.05461. Mohammed Ali, Abdelrahman Abdallah, and Adam Jatowt. 2025. Sustainableqa: A comprehensive question answering dataset for corporate sustain- ability and eu taxonomy reporting.arXiv preprint arXiv:2508.03000. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup S...
-
[3]
InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904
Legal-bert: The muppets straight out of law school. InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904. Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Katz, and Nikolaos Aletras. 2022. Lexglue: A benchmark dataset for legal language understanding in english. InProceedings o...
2020
-
[4]
Towards trustworthy legal ai through llm agents and formal reasoning.arXiv preprint arXiv:2511.21033. Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, and 1 others. 2023. Agent- verse: Facilitating multi-agent collaboration and ex- ploring emergent behaviors. InThe Twelfth Interna- t...
-
[5]
arXiv preprint arXiv:2509.11773
Agenticie: An adaptive agent for informa- tion extraction from complex regulatory documents. arXiv preprint arXiv:2509.11773. Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and devel...
-
[6]
Executable governance for ai: Translat- ing policies into rules using llms.arXiv preprint arXiv:2512.04408. European Commission. 2021. Commission delegated regulation (EU) 2021/2139 supplementing Regula- tion (EU) 2020/852 by establishing the technical screening criteria. Official Journal of the European Union, L 442, 9.12.2021, p. 1. European Commission....
-
[7]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738. Neel Guha, Julian Nyarko, Daniel Ho, Christopher Ré, Adam Chilton, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zam- brano, and 1 others. 2023. Legalbench: A collab- oratively built benchmark for measuring legal reas...
work page internal anchor Pith review arXiv 2023
-
[8]
Revisiting relation extraction in the era of large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15566– 15589. Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, and 1 others. 2024. Mineru: An open-source...
-
[9]
Corrective Retrieval Augmented Generation
Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
work page internal anchor Pith review arXiv
-
[10]
point 1(b)
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning repres...
2022
-
[11]
Map position: (v) = 5th child = (e)
-
[12]
Check if X(y)(e) exists AND its semantic topic matches the context
-
[13]
comply with point 1(b)(v)
If both match→use X(y)(e) Example: Text says “comply with point 1(b)(v)” but 1(b)(v) doesn’t exist. Missing 1(b)(v)→ position (v) = 5th = (e). If correct parent is 1(f), look for 1(f)(e). Read semantic topic of 1(f)(e): “fuel switch by 2035” — if context is about fuel switching→USE 1(f)(e). Matching Priority: 1.HIGHEST: Criterion with threshold matching t...
2035
-
[14]
from” and “to
Same threshold type (quantitative values, temporal deadlines) 3.LOWEST: Same structural family (only if no content match found) Forbidden:Do NOT use parent fallback; do NOT return a parent/ancestor of the current node; do NOT return same ID as both “from” and “to”. D.9 Stage 5 (Dependency Resolver): Threshold Inheritance Detection Stage 5 (Dependency Reso...
2030
-
[15]
EXPAND all abbreviations/acronyms to full EU regulatory forms
-
[16]
For the [substantial contribution / DNSH] criteria of [activity] under [objective], what does [regulation] require regarding [topic]?
FRAME as: “For the [substantial contribution / DNSH] criteria of [activity] under [objective], what does [regulation] require regarding [topic]?”
-
[17]
INCLUDE the article/section reference naturally if provided
-
[18]
INCLUDE key regulatory concepts: requirements, thresholds, definitions, conditions
-
[19]
KEEP numeric values, units, and article references exact
-
[20]
The activity complies with the emission threshold set in Article 29(4)(a)
NEVER invent references: only mention Articles/Appendices/Annexes that appear in the criterion text Examples: Activity: Electricity generation using solar PV . Objective: mitigation. Section: substantial contribution. Criterion: “The activity complies with the emission threshold set in Article 29(4)(a)” → “For the substantial contribution of electricity g...
-
[21]
Focus on requirements, thresholds, dates, and conditions relevant to the criterion
-
[22]
Quote key thresholds and dates VERBATIM (in quotation marks)
-
[23]
Keep each direct quote under 100 words
-
[24]
Identify specific articles/sections that apply
-
[25]
Note any conditions or exceptions
-
[26]
Each prompt receives three inputs: theverbatim regulatory text(ground truth source), thegold(human-annotated) field, and thesystem (pipeline-extracted) field
Be factual — do NOT invent requirements not in the source text Input:{criterion},{celex_id},{passages} Output:{text, key_facts, thresholds, confidence} D.19 Semantic Equivalence Judge Prompts The following prompt templates are used by the GPT-4o LLM judge (max 150 tokens) to score semantic equivalence between system-extracted and gold-annotated fields. Ea...
-
[27]
temporal
Structural placement is irrelevant: recurring intervals under “temporal” vs. “quantitative” are not penalized if semantic content is identical
-
[28]
Primary Energy Demand
Metric label is free-text: “Primary Energy Demand” vs. “PED” are equivalent; judge whether they refer to the same physical quantity. 3.Operator equivalence:≥and “at least” are the same;>vs.≥isa meaningful difference (−1pt). 4.Value must be numerically identical: 10 vs. 10.0 is fine; 10 vs. 100 is wrong. 5.Unit normalization: “%” vs. “percent”, “g CO2e/kWh...
-
[29]
Every claim in the summary must be traceable to the source passages
Faithfulness = grounding. Every claim in the summary must be traceable to the source passages. A claim that is true in general EU law but not in these specific passages is hallucination
-
[30]
Numeric thresholds in the summary or thresholds list must appear (exactly or equivalently) in the source passages
-
[31]
Each key fact must be supported by at least one passage
-
[32]
Omission of passage content is acceptable—only fabrication is penalized
-
[33]
score": <int 1-5>,
Article/section references cited in the summary must appear in the passages. Scoring Rubric (1–5): • 5 — Fully faithful: Every claim, threshold, and key fact is directly supported by the passages. Paraphrasing is acceptable if meaning is preserved. • 4 — One minor unsupported detail: All major claims are grounded. Exactly one minor detail lacks direct sup...
-
[34]
Classify each summary claim into three tiers:directly relevant(addresses a specific requirement of the criterion), contextual(provides useful background but does not directly address the criterion), orunrelated(no connection to the criterion)
-
[35]
A claim may be faithful to the passages but irrelevant to the criterion
The criterion text defines relevance—not the passages. A claim may be faithful to the passages but irrelevant to the criterion
-
[36]
contextual
General legal context is “contextual” unless it directly clarifies a requirement in the criterion
-
[37]
score": <int 1-5>,
Key facts should each relate to a specific aspect of the criterion. Scoring Rubric (1–5): • 5 — Fully relevant: Every claim in the summary directly addresses a requirement or condition stated in the criterion. Key facts map to specific criterion aspects. • 4 — One contextual claim: All major claims are directly relevant. Exactly one claim provides backgro...
-
[38]
Identify all compliance-critical elements in the passages: quantitative thresholds, mandatory requirements, condi- tions, deadlines, and exceptions
-
[39]
Classify each element asmajor(quantitative thresholds, mandatory requirements, binding conditions) orminor (definitions, contextual details, non-binding guidance)
-
[40]
Check whether each element is captured in the summary or key facts/thresholds lists
-
[41]
score": <int 1-5>,
A major element omitted from all three outputs (summary, key facts, thresholds) is a substantive gap. Scoring Rubric (1–5): • 5 — Fully complete: All major and minor compliance-critical elements from the passages are captured in the summary, key facts, or thresholds. • 4 — One minor omission: All major elements captured. Exactly one minor element (a defin...
-
[42]
Analyze the criterion to identify its information needs: what specific regulatory content does the criterion reference or require?
-
[43]
Classify each need asprimary(the specific requirement, threshold, or condition the criterion explicitly references) orsecondary(supporting context that aids interpretation)
-
[44]
Coverage measures retrieval adequacy: did the pipeline retrieve and summarize passages that address what the criterion asks for?
-
[45]
score": <int 1-5>,
A criterion referencing a specific article expects the summary to cover that article’s content. A criterion referencing a general regulation expects broader coverage of relevant provisions. Scoring Rubric (1–5): •5 — Full coverage: All primary and secondary information needs of the criterion are addressed by the summary. • 4 — One secondary need unmet: Al...
-
[46]
point 1(f)
Reference extraction: the LLM identifies all criterion references within the paragraph (e.g., “point 1(f)”, “criteria referred to in 1(b)”) with confidence scores
-
[47]
Scope analysis: determines whether the paragraph applies to a single criterion, a range, or an entire section, using the extracted references and surrounding context
-
[48]
child of the referenced criterion) based on its semantic function
Hierarchy determination: assigns the paragraph’s position in the hierarchy (sibling vs. child of the referenced criterion) based on its semantic function. A separatesemantic classificationstep then applies a three-part reasoning chain (audit testability,obliga- tion direction, andcompliance impact) to assign each paragraph a descriptive type such as Verif...
-
[49]
A correctly identified node placed under the wrong parent receives no credit for this feature
Parent placement(weight 0.30): whether the system node sits under the same parent criterion_id as the gold node. A correctly identified node placed under the wrong parent receives no credit for this feature
-
[50]
If gold groups criteria {a, b, c} under one parent but the system groups {a, b, d}, partial credit reflects the overlap
Sibling overlap(weight 0.25): Jaccard similarity between the sibling ID sets of the system and gold nodes. If gold groups criteria {a, b, c} under one parent but the system groups {a, b, d}, partial credit reflects the overlap
-
[51]
A leaf node matched to another leaf receives full credit
Subtree shape(weight 0.25): ratio of child counts, computed as min(s, g)/max(s, g) where s and g are the number of children in the system and gold trees. A leaf node matched to another leaf receives full credit
-
[52]
What are the conditions for classification of protected areas under the IUCN system and Natura 2000 sites according to Directive 92/43/EEC?
Schema completeness(weight 0.20): fraction of the 13 required output fields present as keys on the system node. A node missing two of thirteen fields receives11/13≈0.85for this feature. F1 Computation.The quality scores are summed across all matched pairs to produce a weighted true-positive count. Precision divides this count by the total number of system...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.