Recognition: unknown
CODO: An Automated Compiler for Comprehensive Dataflow Optimization
Pith reviewed 2026-05-10 14:32 UTC · model grok-4.3
The pith
CODO automates creation of efficient FPGA dataflow accelerators by fixing dataflow violations and optimizing memory use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
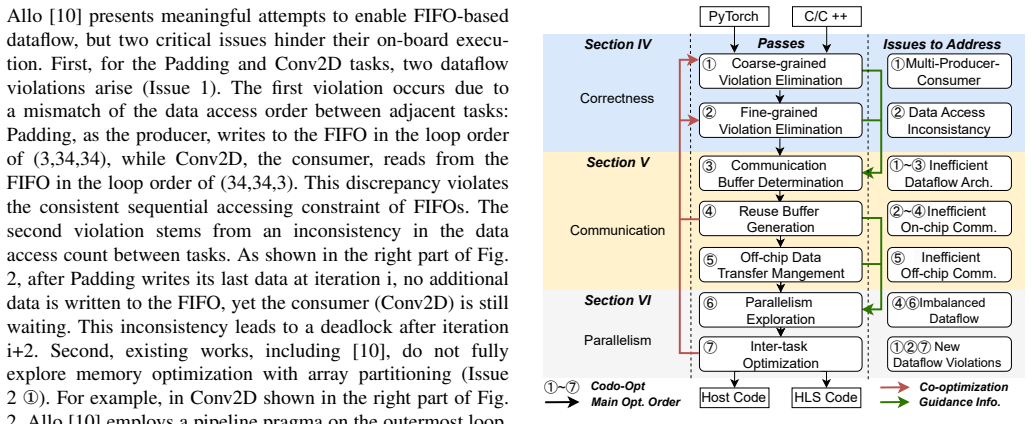
We introduce CODO, an automated compiler that generates feasible and efficient dataflow accelerators on FPGAs. CODO features a systematic method for detecting and eliminating both coarse-grained and fine-grained dataflow violations. Building on this, CODO performs both on- and off-chip data movement optimizations to maximize transfer efficiency and automatic scheduling to generate high-performance dataflow accelerators ensuring a balanced performance-resource trade-off. Synthesis results show that CODO delivers 1.45× to 4.52× latency speedups on typical computation kernels and 3.7× to 33.8× speedups on DNN models compared to SOTA frameworks, with on-board evaluations achieving 7.3× average 2
What carries the argument
The systematic method for detecting and eliminating both coarse-grained and fine-grained dataflow violations, which enables subsequent data movement optimizations and automatic scheduling.
If this is right
- Large-scale applications can be mapped to dataflow architectures on FPGAs without manual resolution of violations.
- On-chip and off-chip data transfers reach higher efficiency through targeted optimizations.
- Automatic scheduling produces designs with improved latency while respecting resource limits.
- DNN and kernel workloads achieve consistent latency reductions over existing compilation flows.
Where Pith is reading between the lines
- The violation-detection approach could be adapted to other reconfigurable computing platforms beyond FPGAs.
- Integration with standard machine-learning toolchains might shorten the path from model to custom hardware.
- Wider use of such compilers could shift more edge inference workloads onto FPGAs for lower power.
Load-bearing premise
That dataflow violations in large-scale applications can be systematically detected and eliminated automatically while still guaranteeing feasible designs that do not introduce new bottlenecks.
What would settle it
A side-by-side implementation of a large DNN model where an expert uses standard HLS tools to produce a dataflow design and its measured latency and resource use is compared directly against the output produced by CODO on the same FPGA board.
Figures









read the original abstract
FPGAs are well-suited for dataflow architectures that process data in a streaming or pipelined manner, thus satisfying the high computational and communication demands of emerging applications. However, manually implementing an efficient dataflow architecture for large-scale applications is still challenging, even for specialists who use high-level synthesis (HLS) to simplify FPGA programming. To address this, we introduce CODO, an automated compiler that generates feasible and efficient dataflow accelerators on FPGAs. CODO features a systematic method for detecting and eliminating both coarse-grained and fine-grained dataflow violations. Building on this, CODO performs both on- and off-chip data movement optimizations to maximize transfer efficiency. To guarantee a higher design quality, CODO performs automatic scheduling to generate high-performance dataflow accelerators, ensuring a balanced performance-resource trade-off. Synthesis results show that CODO delivers $1.45\times$ to $4.52\times$ latency speedups on typical computation kernels and $3.7\times$ to $33.8\times$ speedups on DNN models compared to SOTA frameworks. In on-board evaluations, CODO achieves $7.3\times$ average speedup on CNN models and $2.07\times$ average speedup on the GPT-2 model over SOTA frameworks. The compiler is open-sourced at https://github.com/sjtu-zhao-lab/codo-artifact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CODO, an automated compiler that generates feasible and efficient dataflow accelerators on FPGAs. It claims a systematic method to detect and eliminate both coarse-grained and fine-grained dataflow violations, combined with on- and off-chip data movement optimizations and automatic scheduling to achieve balanced performance-resource trade-offs. Synthesis results are reported to deliver 1.45×–4.52× latency speedups on typical computation kernels and 3.7×–33.8× on DNN models versus SOTA frameworks, with on-board evaluations showing 7.3× average speedup on CNN models and 2.07× on GPT-2; the compiler is open-sourced.
Significance. If the automation guarantees and reported speedups prove reproducible and generalizable, CODO could meaningfully advance FPGA design automation for streaming dataflow architectures, reducing reliance on manual HLS tuning for large-scale applications such as DNN inference. The open-source release at the cited GitHub repository is a clear strength that supports independent verification and extension.
major comments (3)
- Evaluation section (synthesis and on-board results): The central speedup claims (1.45×–4.52× kernels, 3.7×–33.8× DNNs, 7.3× CNNs, 2.07× GPT-2) are stated without any description of the concrete benchmarks, exact SOTA framework versions and configurations, target FPGA platform and resource utilization numbers, number of synthesis runs, or statistical measures. This absence is load-bearing because the performance advantage is predicated on the systematic violation-elimination method succeeding automatically; without these details the claims cannot be assessed for reproducibility or selection bias.
- Compiler design section on violation detection and elimination: The systematic method for detecting and removing coarse- and fine-grained dataflow violations is presented conceptually but supplies no algorithm, pseudocode, complexity bound, or failure-mode analysis. Because the paper’s automation claim and all downstream speedups rest on this method producing feasible, efficient designs without expert intervention or new bottlenecks, the lack of concrete specification prevents evaluation of whether the reported gains are general or limited to hand-selected cases.
- Automatic scheduling and data-movement optimization sections: No formal description is given of the scheduling objective, how on-/off-chip movement decisions interact with the violation fixes, or any proof that the resulting accelerator remains balanced for large designs. This is load-bearing for the “guarantee a higher design quality” assertion and must be supplied to substantiate that the automation does not merely shift the manual effort elsewhere.
minor comments (2)
- Abstract: The phrases “typical computation kernels” and “DNN models” are used without enumeration; a brief list or reference to the evaluation section would improve clarity for readers.
- Open-source statement: The GitHub link is welcome, but the manuscript should explicitly state which artifacts (source, benchmarks, synthesis scripts) are included so that the reported numbers can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below and will revise the manuscript to provide the requested details, algorithms, and formal descriptions.
read point-by-point responses
-
Referee: Evaluation section (synthesis and on-board results): The central speedup claims (1.45×–4.52× kernels, 3.7×–33.8× DNNs, 7.3× CNNs, 2.07× GPT-2) are stated without any description of the concrete benchmarks, exact SOTA framework versions and configurations, target FPGA platform and resource utilization numbers, number of synthesis runs, or statistical measures. This absence is load-bearing because the performance advantage is predicated on the systematic violation-elimination method succeeding automatically; without these details the claims cannot be assessed for reproducibility or selection bias.
Authors: We agree that the evaluation section requires additional concrete details to support reproducibility. In the revised manuscript, we will expand this section to include: the full list of concrete benchmarks with input sizes and characteristics; exact versions, configurations, and command-line settings of all compared SOTA frameworks; the specific FPGA device (including part number) and post-synthesis resource utilization tables for every design; the number of synthesis runs performed per design; and statistical measures such as mean and standard deviation across runs where variability exists. revision: yes
-
Referee: Compiler design section on violation detection and elimination: The systematic method for detecting and removing coarse- and fine-grained dataflow violations is presented conceptually but supplies no algorithm, pseudocode, complexity bound, or failure-mode analysis. Because the paper’s automation claim and all downstream speedups rest on this method producing feasible, efficient designs without expert intervention or new bottlenecks, the lack of concrete specification prevents evaluation of whether the reported gains are general or limited to hand-selected cases.
Authors: The current manuscript describes the violation detection and elimination approach at a conceptual level. We will revise the compiler design section to include a precise algorithmic description, pseudocode for the coarse- and fine-grained detection and elimination passes, asymptotic complexity bounds, and a dedicated subsection on failure modes (e.g., cases where elimination introduces new bottlenecks) together with the heuristics used to avoid them. revision: yes
-
Referee: Automatic scheduling and data-movement optimization sections: No formal description is given of the scheduling objective, how on-/off-chip movement decisions interact with the violation fixes, or any proof that the resulting accelerator remains balanced for large designs. This is load-bearing for the “guarantee a higher design quality” assertion and must be supplied to substantiate that the automation does not merely shift the manual effort elsewhere.
Authors: We acknowledge that formal specifications are missing. The revised sections will define the scheduling objective as an optimization problem with explicit objective function and constraints, describe how on- and off-chip data-movement decisions are coupled to the violation fixes, and provide an analysis (including a heuristic argument and empirical evidence from large designs) showing that the resulting accelerators maintain balanced performance-resource trade-offs. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an automated compiler (CODO) whose core contributions are a systematic detection/elimination method for dataflow violations, on-/off-chip movement optimizations, and automatic scheduling. These are presented as algorithmic procedures whose outputs are evaluated empirically via synthesis results and on-board runs against external SOTA frameworks. No equations, fitted parameters, or self-citations are shown to reduce the reported speedups (1.45–4.52× kernels, 3.7–33.8× DNNs, etc.) to the inputs by construction. The central claims rest on external benchmarks rather than self-definitional renaming or load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alveo u280,
“Alveo u280,” 2024. [Online]. Available: https: //www.xilinx.com/content/dam/xilinx/publications/product-briefs/alveo- u280-product-brief.pdf
2024
-
[2]
Intel hls,
“Intel hls,” 2024. [Online]. Available: https://www.intel.com/content/ www/us/en/docs/programmable/683680/23-2/pro-edition-getting- started-guide.html
2024
-
[3]
Torch-mlir project,
“Torch-mlir project,” 2024. [Online]. Available: https://mlir.llvm.org/ docs/Dialects/Linalg/
2024
-
[4]
Vitis hls dataflow,
“Vitis hls dataflow,” 2024. [Online]. Available: https://docs.amd.com/r/ en-US/ug1399-vitis-hls/pragma-HLS-dataflow
2024
-
[5]
Think fast: A tensor streaming processor (tsp) for accelerating deep learning workloads,
D. Abts, J. Ross, J. Sparling, M. Wong-VanHaren, M. Baker, T. Hawkins, A. Bell, J. Thompson, T. Kahsai, G. Kimmellet al., “Think fast: A tensor streaming processor (tsp) for accelerating deep learning workloads,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 145–158
2020
-
[6]
Yodann: An architecture for ultralow power binary-weight cnn acceleration,
R. Andri, L. Cavigelli, D. Rossi, and L. Benini, “Yodann: An architecture for ultralow power binary-weight cnn acceleration,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 37, no. 1, pp. 48–60, 2017
2017
-
[7]
Chisel: Constructing hardware in a scala embedded language,
J. Bachrach, H. V o, B. Richards, Y . Lee, A. Waterman, R. Avi ˇzienis, J. Wawrzynek, and K. Asanovi ´c, “Chisel: Constructing hardware in a scala embedded language,” inDAC Design Automation Conference 2012, 2012, pp. 1212–1221
2012
-
[8]
A unified framework for automated code transformation and pragma insertion,
S. Basalama and J. Cong, “Stream-hls: Towards automatic dataflow acceleration,” inProceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, ser. FPGA ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3706628.3708878
-
[9]
Understanding the potential of fpga-based spatial acceleration for large language model inference,
H. Chen, J. Zhang, Y . Du, S. Xiang, Z. Yue, N. Zhang, Y . Cai, and Z. Zhang, “Understanding the potential of fpga-based spatial acceleration for large language model inference,”ACM Trans. Reconfigurable Technol. Syst., vol. 18, no. 1, Dec. 2024. [Online]. Available: https://doi.org/10.1145/3656177
-
[10]
Allo: A programming model for composable accelerator design,
H. Chen, N. Zhang, S. Xiang, Z. Zeng, M. Dai, and Z. Zhang, “Allo: A programming model for composable accelerator design,”Proceedings of the ACM on Programming Languages, vol. 8, no. PLDI, pp. 593–620, 2024
2024
-
[11]
Eyeriss: An energy- efficient reconfigurable accelerator for deep convolutional neural net- works,
Y .-H. Chen, T. Krishna, J. S. Emer, and V . Sze, “Eyeriss: An energy- efficient reconfigurable accelerator for deep convolutional neural net- works,”IEEE Journal of Solid-State Circuits, vol. 52, no. 1, pp. 127– 138, 2017
2017
-
[12]
High-level synthesis for fpgas: From prototyping to deployment,
J. Cong, B. Liu, S. Neuendorffer, J. Noguera, K. Vissers, and Z. Zhang, “High-level synthesis for fpgas: From prototyping to deployment,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 30, no. 4, pp. 473–491, 2011
2011
-
[13]
D. Durst, M. Feldman, D. Huff, D. Akeley, R. Daly, G. L. Bernstein, M. Patrignani, K. Fatahalian, and P. Hanrahan, “Type-directed scheduling of streaming accelerators,” inProceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI 2020. New York, NY , USA: Association for Computing Machinery, 2020, p. 408–42...
-
[14]
Riptide: A programmable, energy-minimal dataflow compiler and architecture,
G. Gobieski, S. Ghosh, M. Heule, T. Mowry, T. Nowatzki, N. Beckmann, and B. Lucia, “Riptide: A programmable, energy-minimal dataflow compiler and architecture,” in2022 55th IEEE/ACM International Sym- posium on Microarchitecture (MICRO). IEEE, 2022, pp. 546–564
2022
-
[15]
Tapa: a scalable task-parallel dataflow programming framework for modern fpgas with co-optimization of hls and physical design,
L. Guo, Y . Chi, J. Lau, L. Song, X. Tian, M. Khatti, W. Qiao, J. Wang, E. Ustun, Z. Fanget al., “Tapa: a scalable task-parallel dataflow programming framework for modern fpgas with co-optimization of hls and physical design,”ACM Transactions on Reconfigurable Technology and Systems, vol. 16, no. 4, pp. 1–31, 2023
2023
-
[16]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[17]
Dfx: A low-latency multi-fpga appliance for accelerating transformer-based text generation,
S. Hong, S. Moon, J. Kim, S. Lee, M. Kim, D. Lee, and J.-Y . Kim, “Dfx: A low-latency multi-fpga appliance for accelerating transformer-based text generation,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2022, pp. 616–630
2022
-
[18]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[19]
Pylog: An algorithm-centric python-based fpga programming and synthesis flow,
S. Huang, K. Wu, H. Jeong, C. Wang, D. Chen, and W.-M. Hwu, “Pylog: An algorithm-centric python-based fpga programming and synthesis flow,”IEEE Transactions on Computers, vol. 70, no. 12, pp. 2015–2028, 2021
2015
-
[20]
Tensorlib: A spatial accelerator generation framework for tensor algebra,
L. Jia, Z. Luo, L. Lu, and Y . Liang, “Tensorlib: A spatial accelerator generation framework for tensor algebra,” in2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 2021, pp. 865–870
2021
-
[21]
Dynamically scheduled high- level synthesis,
L. Josipovi ´c, R. Ghosal, and P. Ienne, “Dynamically scheduled high- level synthesis,” inProceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, ser. FPGA ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 127–136. [Online]. Available: https://doi.org/10.1145/3174243.3174264
-
[22]
Spatial: a language and compiler for application accelerators,
D. Koeplinger, M. Feldman, R. Prabhakar, Y . Zhang, S. Hadjis, R. Fiszel, T. Zhao, L. Nardi, A. Pedram, C. Kozyrakis, and K. Olukotun, “Spatial: a language and compiler for application accelerators,”SIGPLAN Not., vol. 53, no. 4, p. 296–311, Jun. 2018. [Online]. Available: https://doi.org/10.1145/3296979.3192379
-
[23]
Heterogeneous dataflow accelerators for multi-dnn workloads,
H. Kwon, L. Lai, M. Pellauer, T. Krishna, Y .-H. Chen, and V . Chan- dra, “Heterogeneous dataflow accelerators for multi-dnn workloads,” in 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2021, pp. 71–83
2021
-
[24]
Heterocl: A multi-paradigm programming infrastructure for software-defined reconfigurable computing,
Y .-H. Lai, Y . Chi, Y . Hu, J. Wang, C. H. Yu, Y . Zhou, J. Cong, and Z. Zhang, “Heterocl: A multi-paradigm programming infrastructure for software-defined reconfigurable computing,” inProceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, pp. 242–251
2019
-
[25]
MLIR: A compiler in- frastructure for the end of Moore’s Law,
C. Lattner, M. Amini, U. Bondhugula, A. Cohen, A. Davis, J. Pienaar, R. Riddle, T. Shpeisman, N. Vasilache, and O. Zinenko, “Mlir: A compiler infrastructure for the end of moore’s law,”arXiv preprint arXiv:2002.11054, 2020
-
[26]
High-performance fpga-based cnn accelerator with block-floating-point arithmetic,
X. Lian, Z. Liu, Z. Song, J. Dai, W. Zhou, and X. Ji, “High-performance fpga-based cnn accelerator with block-floating-point arithmetic,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 27, no. 8, pp. 1874–1885, 2019
2019
-
[27]
MLIR: Multi-Level Intermediate Representation,
MLIR Contributors, “MLIR: Multi-Level Intermediate Representation,” https://mlir.llvm.org, 2026, accessed: 2026-03-06
2026
-
[28]
Polygeist: Raising c to polyhedral mlir,
W. S. Moses, L. Chelini, R. Zhao, and O. Zinenko, “Polygeist: Raising c to polyhedral mlir,” inProceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques, ser. PACT ’21. New York, NY , USA: Association for Computing Machinery, 2021
2021
-
[29]
Duck, Xiang Gao, and Abhik Roychoudhury
R. Nigam, S. Atapattu, S. Thomas, Z. Li, T. Bauer, Y . Ye, A. Koti, A. Sampson, and Z. Zhang, “Predictable accelerator design with time-sensitive affine types,” inProceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI 2020. New York, NY , USA: Association for Computing Machinery, 2020, p. 393–407. [Onli...
-
[30]
Stream-dataflow acceleration,
T. Nowatzki, V . Gangadhar, N. Ardalani, and K. Sankaralingam, “Stream-dataflow acceleration,” in2017 ACM/IEEE 44th Annual Inter- national Symposium on Computer Architecture (ISCA), 2017, pp. 416– 429
2017
-
[31]
Gpt2-medium,
OpenAI Community, “Gpt2-medium,” https://huggingface.co/openai- community/gpt2-medium, 2025, [Online; accessed 17-Nov-2025]
2025
-
[32]
Holistic optimization framework for fpga accelerators,
S. Pouget, M. Lo, L.-N. Pouchet, and J. Cong, “Holistic optimization framework for fpga accelerators,”ACM Trans. Des. Autom. Electron. Syst., Sep. 2025. [Online]. Available: https://doi.org/10.1145/3769307
-
[34]
A unified framework for automated code transformation and pragma insertion,
——, “A unified framework for automated code transformation and pragma insertion,” inProceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, ser. FPGA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 187–198. [Online]. Available: https://doi.org/10.1145/3706628.3708873
-
[35]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:160025533
2019
-
[36]
You only look once: Unified, real-time object detection
J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,”CoRR, vol. abs/1506.02640, 2015. [Online]. Available: http://arxiv.org/abs/1506. 02640
-
[37]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014. 16
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[38]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[39]
Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,
P. Vincent, H. Larochelle, I. Lajoie, Y . Bengio, and P.-A. Manzagol, “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,”J. Mach. Learn. Res., vol. 11, p. 3371–3408, Dec. 2010
2010
-
[40]
Heteroflow: An accelerator programming model with decoupled data placement for software-defined fpgas,
S. Xiang, Y .-H. Lai, Y . Zhou, H. Chen, N. Zhang, D. Pal, and Z. Zhang, “Heteroflow: An accelerator programming model with decoupled data placement for software-defined fpgas,” inProceedings of the 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2022, pp. 78–88
2022
-
[41]
Vitis hls 2023.2,
A. Xilinx, “Vitis hls 2023.2,” https://www.amd.com/en/products/ software/adaptive-socs-and-fpgas/vitis/vitis-hls.html, 2024
2023
-
[42]
Streamtensor: Make tensors stream in dataflow accelerators for llms,
H. Ye and D. Chen, “Streamtensor: Make tensors stream in dataflow accelerators for llms,”Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture®, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281333142
2025
-
[43]
Scalehls: A new scalable high-level synthesis framework on multi-level intermediate representation,
H. Ye, C. Hao, J. Cheng, H. Jeong, J. Huang, S. Neuendorffer, and D. Chen, “Scalehls: A new scalable high-level synthesis framework on multi-level intermediate representation,” in2022 IEEE international symposium on high-performance computer architecture (HPCA). IEEE, 2022, pp. 741–755
2022
-
[44]
Hida: A hierarchical dataflow compiler for high-level synthesis,
H. Ye, H. Jun, and D. Chen, “Hida: A hierarchical dataflow compiler for high-level synthesis,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2024, pp. 215–230
2024
-
[45]
Visualizing and understanding convolutional networks,
M. Zeiler, “Visualizing and understanding convolutional networks,” in European conference on computer vision/arXiv, vol. 1311, 2014
2014
-
[46]
An optimizing framework on mlir for efficient fpga-based accelerator gen- eration,
W. Zhang, J. Zhao, G. Shen, Q. Chen, C. Chen, and M. Guo, “An optimizing framework on mlir for efficient fpga-based accelerator gen- eration,” in2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2024, pp. 75–90
2024
-
[47]
Dnnbuilder: An automated tool for building high-performance dnn hardware accelerators for fpgas,
X. Zhang, J. Wang, C. Zhu, Y . Lin, J. Xiong, W.-m. Hwu, and D. Chen, “Dnnbuilder: An automated tool for building high-performance dnn hardware accelerators for fpgas,” in2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, 2018, pp. 1–8
2018
-
[48]
Comba: A comprehensive model-based analysis framework for high level synthesis of real applications,
J. Zhao, L. Feng, S. Sinha, W. Zhang, Y . Liang, and B. He, “Comba: A comprehensive model-based analysis framework for high level synthesis of real applications,” in2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, 2017, pp. 430–437
2017
-
[49]
Polsca: Polyhedral high-level synthesis with compiler transformations,
R. Zhao, J. Cheng, W. Luk, and G. A. Constantinides, “Polsca: Polyhedral high-level synthesis with compiler transformations,” in 2022 32nd International Conference on Field-Programmable Logic and Applications (FPL). Los Alamitos, CA, USA: IEEE Computer Society, sep 2022, pp. 235–242. [Online]. Available: https://doi. ieeecomputersociety.org/10.1109/FPL570...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.