Intelligent resource prediction for SAP HANA continuous integration build workloads
Pith reviewed 2026-05-10 14:30 UTC · model grok-4.3
The pith
A LightGBM-XGBoost quantile regression ensemble predicts memory use for CI builds and cuts average allocation by 36 GB while holding under-allocation below 0.3 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
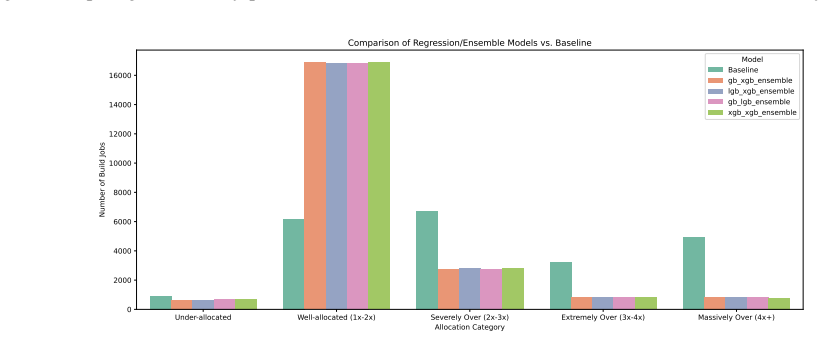
The paper shows that a LightGBM-XGBoost quantile regression ensemble trained on historical build executions can predict the memory a given CI task will need. The ensemble is tuned to penalize under-allocation more heavily than over-allocation. When the resulting predictions replace static resource requests inside the production orchestration layer, average memory savings reach approximately 36 GB per build, under-allocation falls below 0.3 percent, and execution times are unaffected.
What carries the argument
The LightGBM-XGBoost quantile regression ensemble, which produces memory predictions that are then used by a microservice orchestration layer to set dynamic resource limits for each build task.
If this is right
- Cluster nodes can be allocated to more concurrent builds because average memory footprints shrink.
- Static over-provisioning rules can be replaced by per-task predictions without increasing build failures.
- The same orchestration microservice can enforce the new limits transparently for every incoming job.
- Developer productivity stays constant because build run times do not increase.
Where Pith is reading between the lines
- The same prediction pattern could be extended to forecast CPU, disk, or network requirements inside the same CI system.
- An automated drift detector would be required to flag when workload changes make retraining necessary.
- Other large-scale job schedulers could adopt the quantile-ensemble approach to improve utilization without custom engineering for each resource type.
Load-bearing premise
Historical build executions will continue to represent future workloads closely enough that the trained model generalizes without rapid performance loss or frequent retraining.
What would settle it
A measurable rise in under-allocation rate above 0.3 percent or a drop in average memory savings well below 36 GB when the model is applied to a new cohort of build tasks that were not seen during training.
Figures








read the original abstract
Large enterprises often operate extensive Continuous Integration (CI) pipelines on large, heterogeneous compute clusters, where conservative, statically defined resource requirements are used to ensure build reliability. This practice leads to substantial system memory over-allocation, reduced cluster utilization, and increased operational costs. In this paper, we motivate the need for intelligent resource prediction by analyzing over 300,000 historical build executions from a production CI environment with more than one thousand compute nodes. Our analysis shows that, on average, more than 60% of allocated system memory remains unused. We then compare multiple machine learning approaches for predicting build task memory usage, including classification-based methods and regression-based quantile prediction. Our final solution employs a LightGBM-XGBoost quantile regression ensemble optimized to minimize under-allocation while reducing over-provisioning. We integrate this solution into the production CI pipeline via a microservice-based orchestration layer, achieving average memory savings of approximately 36GB per build and reducing under-allocation rates to below 0.3% without negatively impacting build execution times.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes over 300,000 historical SAP HANA CI build executions on a large cluster, showing >60% average memory over-allocation. It evaluates classification and quantile regression ML models, selects a LightGBM-XGBoost ensemble for memory prediction, and deploys it via a microservice orchestration layer in production, reporting ~36 GB average savings per build, under-allocation rates <0.3%, and no increase in build times.
Significance. If the generalization and production results hold, the work is significant for practical resource optimization in large-scale CI/CD systems. It demonstrates a deployable approach to reducing over-provisioning costs while maintaining reliability, which could translate to substantial operational savings in enterprise environments with heterogeneous compute clusters.
major comments (2)
- Abstract and results: the central production claim of 36 GB average savings and <0.3% under-allocation rests on the assumption that the 300 k historical executions remain representative of future builds, yet the manuscript supplies no temporal hold-out evaluation, task-type stratification, or post-deployment drift monitoring to test this; standard cross-validation on the same pool cannot detect degradation from new build configurations or data volumes.
- Methods and evaluation sections: no details are provided on the exact features extracted from build executions, the train/validation/test split strategy, hyperparameter selection process, or the specific quantile levels and loss function used to optimize the ensemble for minimizing under-allocation, preventing verification that the reported metrics are robust rather than overfit.
minor comments (1)
- The abstract states results but the full manuscript should include a dedicated table or figure summarizing the feature set, model hyperparameters, and cross-validation performance metrics for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas to strengthen the evaluation and reproducibility of our work. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract and results: the central production claim of 36 GB average savings and <0.3% under-allocation rests on the assumption that the 300 k historical executions remain representative of future builds, yet the manuscript supplies no temporal hold-out evaluation, task-type stratification, or post-deployment drift monitoring to test this; standard cross-validation on the same pool cannot detect degradation from new build configurations or data volumes.
Authors: We agree that explicit checks for temporal stability and task stratification would strengthen the claims. The 300k executions cover an extended production period with diverse workloads, and the reported savings derive from live deployment on subsequent builds. To address the concern directly, the revised manuscript will add a temporal hold-out experiment (training on earlier data and evaluating on later builds) plus task-type stratification in the evaluation section. We will also note the current lack of automated drift monitoring and flag it as future work. These additions will be included without changing the core production results. revision: yes
-
Referee: Methods and evaluation sections: no details are provided on the exact features extracted from build executions, the train/validation/test split strategy, hyperparameter selection process, or the specific quantile levels and loss function used to optimize the ensemble for minimizing under-allocation, preventing verification that the reported metrics are robust rather than overfit.
Authors: We acknowledge the omission of these implementation details, which limits independent verification. The revised Methods section will provide: the complete feature list (build task metadata, historical memory statistics, node characteristics, and workload descriptors), the train/validation/test split (70/15/15 with temporal ordering to avoid leakage), the hyperparameter tuning procedure (grid search combined with early stopping for both LightGBM and XGBoost), and the quantile regression configuration (targeting the 0.95 quantile with pinball loss to prioritize low under-allocation). These additions will allow readers to assess robustness. revision: yes
Circularity Check
No significant circularity; empirical results rest on external production measurements
full rationale
The paper trains quantile regression ensembles on a historical corpus of 300k build executions and reports measured memory savings and under-allocation rates after deploying the model into a live CI pipeline. No equations, uniqueness theorems, or self-citations are invoked to derive the central performance numbers; the 36 GB savings and <0.3 % under-allocation figures are presented as observed outcomes of the production microservice rather than quantities forced by the training procedure itself. The derivation chain therefore remains self-contained against the external benchmark of actual cluster telemetry.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimizing memory allocation in distributed clusters with predictive modeling
Jonathan Bader, Edgar Blumenthal, Marten Eckardt, Justus Krebs, Joel Witzke, Xemena Wysokinska, Haci Ismail Aslan, and Odej Kao. Optimizing memory allocation in distributed clusters with predictive modeling. In2025 IEEE International Conference on Big Data (Big- Data), pages 8219–8221, 2025
work page 2025
-
[2]
Predict- ing dynamic memory requirements for scientific workflow tasks
Jonathan Bader, Nils Diedrich, Lauritz Thamsen, and Odej Kao. Predict- ing dynamic memory requirements for scientific workflow tasks. In2023 IEEE International Conference on Big Data (BigData), pages 182–189. IEEE, 2023
work page 2023
-
[3]
Ks+: Predicting workflow task memory usage over time
Jonathan Bader, Ansgar L ¨oßer, Lauritz Thamsen, Bj ¨orn Scheuermann, and Odej Kao. Ks+: Predicting workflow task memory usage over time. In2024 IEEE 20th International Conference on e-Science (e-Science), pages 1–7. IEEE, 2024
work page 2024
-
[4]
Sizey: Memory-efficient execution of scientific workflow tasks
Jonathan Bader, Fabian Skalski, Fabian Lehmann, Dominik Scheinert, Jonathan Will, Lauritz Thamsen, and Odej Kao. Sizey: Memory-efficient execution of scientific workflow tasks. In2024 IEEE International Conference on Cluster Computing (CLUSTER), pages 370–381. IEEE, 2024
work page 2024
-
[5]
Lever- aging reinforcement learning for task resource allocation in scientific workflows
Jonathan Bader, Nicolas Zunker, Soeren Becker, and Odej Kao. Lever- aging reinforcement learning for task resource allocation in scientific workflows. In2022 IEEE International Conference on Big Data (Big Data). IEEE, 2022
work page 2022
-
[6]
Toward fine-grained online task characteristics estimation in scientific workflows
Rafael Ferreira Da Silva, Gideon Juve, Ewa Deelman, Tristan Glatard, Fr´ed´eric Desprez, Douglas Thain, Benjam ´ın Tovar, and Miron Livny. Toward fine-grained online task characteristics estimation in scientific workflows. InProceedings of the 8th Workshop on Workflows in Support of Large-Scale Science, pages 58–67, 2013
work page 2013
-
[7]
Rafael Ferreira Da Silva, Gideon Juve, Mats Rynge, Ewa Deelman, and Miron Livny. Online task resource consumption prediction for scientific workflows.Parallel Processing Letters, 25(03), 2015
work page 2015
-
[8]
Rain Durham Goode. Scaling mercurial at facebook. https://engineering. fb.com/2014/01/07/core-infra/scaling-mercurial-at-facebook/, 2014. Ac- cessed: 2025-01-20
work page 2014
- [9]
-
[10]
Sap hana database: Data management for modern business applications.SIGMOD Record, 40:45–51, 12 2011
Franz F ¨arber, Sang Cha, J ¨urgen Primsch, Christof Bornh ¨ovd, Stefan Sigg, and Wolfgang Lehner. Sap hana database: Data management for modern business applications.SIGMOD Record, 40:45–51, 12 2011
work page 2011
- [11]
- [12]
-
[13]
The largest git repo on the planet
Brian Harry. The largest git repo on the planet. https://devblogs. microsoft.com/bharry/the-largest-git-repo-on-the-planet/, 2017. Ac- cessed: 2025-01-20
work page 2017
-
[14]
Joseph, Randy Katz, Scott Shenker, and Ion Stoica
Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, and Ion Stoica. Mesos: A platform for Fine-Grained resource sharing in the data center. In8th USENIX Symposium on Networked Systems Design and Implementation (NSDI 11), Boston, MA, March 2011. USENIX Association
work page 2011
- [15]
-
[16]
Ponder: Online prediction of task memory requirements for scientific workflows
Fabian Lehmann, Jonathan Bader, Ninon De Mecquenem, Xing Wang, Vasilis Bountris, Florian Friederici, Ulf Leser, and Lauritz Thamsen. Ponder: Online prediction of task memory requirements for scientific workflows. In2024 IEEE 20th International Conference on e-Science (e-Science), pages 1–10. IEEE, 2024
work page 2024
-
[17]
https://lightgbm.readthedocs.io/en/stable/
LightGBM, version≥4.0.0. https://lightgbm.readthedocs.io/en/stable/
-
[18]
Uber technology day: Monorepo to multirepo and back again
Aimee Lucido. Uber technology day: Monorepo to multirepo and back again. https://www.youtube.com/watch?v=lV8-1S28ycM, 2017. Accessed: 2025-01-20
work page 2017
- [19]
- [20]
- [21]
-
[22]
Rachel Potvin and Josh Levenberg. Why google stores billions of lines of code in a single repository.Communications of the ACM, 59:78–87, 2016
work page 2016
-
[23]
Helping hpc users specify job memory requirements via machine learning
Eduardo R Rodrigues, Renato LF Cunha, Marco AS Netto, and Michael Spriggs. Helping hpc users specify job memory requirements via machine learning. In2016 Third International Workshop on HPC User Support Tools (HUST), pages 6–13. IEEE, 2016
work page 2016
-
[24]
https://github.com/SAP/task-execution-data-set
Task execution data set. https://github.com/SAP/task-execution-data-set
-
[25]
https://github.com/Zmart64/SAPResourceOptimizer
Sapresourceoptimizer. https://github.com/Zmart64/SAPResourceOptimizer
-
[26]
Practical Pipeline-Aware Regression Test Optimization for Continuous Integration
Daniel Schwendner, Maximilian Jungwirth, Martin Gruber, Martin Knoche, Daniel Merget, and Gordon Fraser. Practical Pipeline-Aware Regression Test Optimization for Continuous Integration . In2025 IEEE Conference on Software Testing, Verification and Validation (ICST), pages 371–381, Los Alamitos, CA, USA, April 2025. IEEE Computer Society
work page 2025
-
[27]
https://scikit-learn.org/stable/index.html
scikit-Learn, version=1.6.1. https://scikit-learn.org/stable/index.html
-
[28]
Ensemble prediction of job resources to improve system performance for slurm-based hpc systems
Mohammed Tanash, Huichen Yang, Daniel Andresen, and William Hsu. Ensemble prediction of job resources to improve system performance for slurm-based hpc systems. InPractice and experience in advanced research computing, pages 1–8. ACM, 2021
work page 2021
-
[29]
Dynamic task shaping for high throughput data analysis applications in high energy physics
Ben Tovar, Ben Lyons, Kelci Mohrman, Barry Sly-Delgado, Kevin Lannon, and Douglas Thain. Dynamic task shaping for high throughput data analysis applications in high energy physics. In2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2022
work page 2022
-
[30]
Feedback-based resource allocation for batch scheduling of scientific workflows
Carl Witt, Dennis Wagner, and Ulf Leser. Feedback-based resource allocation for batch scheduling of scientific workflows. In2019 In- ternational Conference on High Performance Computing & Simulation (HPCS). IEEE, 2019
work page 2019
-
[31]
https://xgboost.readthedocs.io/en/stable/
XGBoost, version≥2.0.0. https://xgboost.readthedocs.io/en/stable/
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.