Recognition: unknown
Energy-based Regularization for Learning Residual Dynamics in Neural MPC for Omnidirectional Aerial Robots
Pith reviewed 2026-05-10 11:22 UTC · model grok-4.3
The pith
Penalizing energy changes in learned residual dynamics makes neural MPC track aerial robots more accurately and stably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
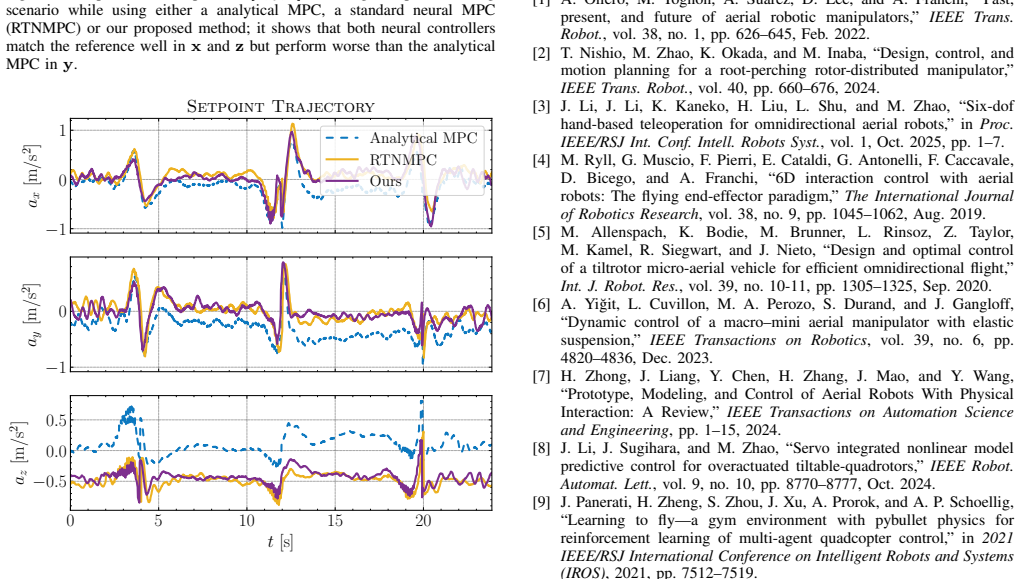
The authors train a neural residual model with an added energy-based regularization term that encourages the network to produce control corrections whose net effect stabilizes the system's energy. When this regularized residual is integrated into the MPC optimization for an omnidirectional aerial robot, real-world flights exhibit a 23 percent reduction in positional mean absolute error relative to an analytical MPC baseline and up to 15 percent lower error with markedly better stability than an unregularized neural MPC.
What carries the argument
The energy-based regularization loss added to the neural residual model's training objective, which penalizes predicted dynamics that increase total system energy and thereby biases the learned corrections toward energy-stabilizing behavior.
If this is right
- The regularized residual dynamics improve positional mean absolute error by 23 percent over analytical MPC across three real-world experiments.
- Compared with standard neural MPC without regularization, the method yields up to 15 percent lower error and significantly higher flight stability.
- The regularization implicitly promotes stability by steering the network toward corrections that respect energy conservation.
- Data-driven MPC can incorporate basic physical constraints such as energy stability without requiring complete analytical models.
Where Pith is reading between the lines
- The same regularization idea could be tested on other underactuated platforms where energy fluctuations correlate with instability, such as quadrotors in wind or legged robots.
- Combining the energy term with additional physics losses, for example on momentum or contact forces, might further reduce the data needed for reliable generalization.
- The approach may allow shorter training datasets because the energy penalty constrains the space of plausible residuals.
- Controller tuning effort could decrease if the regularization reduces the sensitivity of closed-loop performance to small modeling errors.
Load-bearing premise
Penalizing energy increases in the learned residual will produce control corrections that improve tracking and stability without creating new instabilities or preventing the network from fitting the actual unmodeled dynamics.
What would settle it
Repeating the three real-world flight experiments with the same controller structure but observing higher positional error or reduced stability when the energy regularization term is active compared with the unregularized neural MPC.
Figures







read the original abstract
Data-driven Model Predictive Control (MPC) has lately been the core research subject in the field of control theory. The combination of an optimal control framework with deep learning paradigms opens up the possibility to accurately track control tasks without the need for complex analytical models. However, the system dynamics are often nuanced and the neural model lacks the potential to understand physical properties such as inertia and conservation of energy. In this work, we propose a novel energy-based regularization loss function which is applied to the training of a neural model that learns the residual dynamics of an omnidirectional aerial robot. Our energy-based regularization encourages the neural network to cause control corrections that stabilize the energy of the system. The residual dynamics are integrated into the MPC framework and improve the positional mean absolute error (MAE) over three real-world experiments by 23% compared to an analytical MPC. We also compare our method to a standard neural MPC implementation without regularization and primarily achieve a significantly increased flight stability implicitly due to the energy regularization and up to 15% lower MAE. Our code is available under: https://github.com/johanneskbl/jsk_aerial_robot/tree/develop/neural_MPC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an energy-based regularization term for training a neural network to model residual dynamics of an omnidirectional aerial robot. The regularized residual is embedded in an MPC controller. Real-world flight tests on three experiments report a 23% reduction in positional MAE versus a purely analytical MPC baseline and up to 15% lower MAE plus improved stability versus an unregularized neural MPC.
Significance. If the empirical gains prove robust, the approach offers a practical way to inject physical priors (energy conservation) into learned residuals for underactuated aerial systems, potentially improving closed-loop stability without requiring a complete first-principles model. The real-world validation and open-source code are positive features for the field of learning-based MPC.
major comments (2)
- [Section 3 (method / loss)] The energy-based regularization is the core technical contribution, yet the manuscript provides no explicit equation for the regularization loss, the definition of system energy E(s, u) used inside it, or the weighting hyperparameter. Without this formulation it is impossible to verify how the term encourages stabilizing corrections or to reproduce the reported MAE reductions.
- [Section 5 and associated tables/figures] Section 5 (experiments): the 23% and 15% MAE improvements are stated without error bars, standard deviations across repeated flights, or any statistical test. In addition, the data-collection protocol (number of trajectories, flight duration, how residuals are computed from measurements) is not described, leaving the central empirical claim weakly supported.
minor comments (2)
- [Abstract and Section 5] The abstract claims 'significantly increased flight stability' but the results section supplies no quantitative stability metric (e.g., attitude variance or integrated energy deviation).
- [Section 2] Notation for states, residuals, and the analytical model should be collected in a single table for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive assessment of the work's potential impact. We address each major comment below and will revise the manuscript accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Section 3 (method / loss)] The energy-based regularization is the core technical contribution, yet the manuscript provides no explicit equation for the regularization loss, the definition of system energy E(s, u) used inside it, or the weighting hyperparameter. Without this formulation it is impossible to verify how the term encourages stabilizing corrections or to reproduce the reported MAE reductions.
Authors: We agree that the explicit equation for the energy-based regularization loss, the definition of E(s, u), and the weighting hyperparameter are essential for verification and reproducibility. The submitted manuscript describes the intent of the term but omits the precise formulation in Section 3. In the revised version we will add the full equation, define the system energy based on the state and input, and report the hyperparameter value, thereby showing how the regularization promotes stabilizing corrections in the residual dynamics. revision: yes
-
Referee: [Section 5 and associated tables/figures] Section 5 (experiments): the 23% and 15% MAE improvements are stated without error bars, standard deviations across repeated flights, or any statistical test. In addition, the data-collection protocol (number of trajectories, flight duration, how residuals are computed from measurements) is not described, leaving the central empirical claim weakly supported.
Authors: We acknowledge that Section 5 would be strengthened by statistical measures and a complete protocol description. In the revision we will add error bars and standard deviations from the available flight data, include statistical tests for the reported MAE reductions, and expand the data-collection details to cover the number of trajectories, flight durations, and the procedure for computing residuals from measurements. The open-source code will be referenced for additional implementation specifics. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an energy-based regularization term as an additional loss during neural network training for residual dynamics, then integrates the resulting model into an MPC controller and reports empirical MAE improvements on real-world flights against both an analytical MPC baseline and an unregularized neural MPC baseline. No claimed prediction, uniqueness theorem, or first-principles result is shown to reduce by construction to the regularization weight or to any fitted parameter; the reported performance numbers are measured on held-out flight data and are not algebraically equivalent to the training objective. The derivation chain consists of standard supervised learning plus a physics-inspired penalty, followed by separate experimental validation, with no self-citation load-bearing step or ansatz smuggling that collapses the central claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- energy regularization weight
axioms (2)
- domain assumption System dynamics can be usefully decomposed into a known analytical model plus a learnable residual.
- ad hoc to paper Control corrections that stabilize energy will improve closed-loop tracking and stability.
Reference graph
Works this paper leans on
-
[1]
Past, present, and future of aerial robotic manipulators,
A. Ollero, M. Tognon, A. Suarez, D. Lee, and A. Franchi, “Past, present, and future of aerial robotic manipulators,”IEEE Trans. Robot., vol. 38, no. 1, pp. 626–645, Feb. 2022
2022
-
[2]
Design, control, and motion planning for a root-perching rotor-distributed manipulator,
T. Nishio, M. Zhao, K. Okada, and M. Inaba, “Design, control, and motion planning for a root-perching rotor-distributed manipulator,” IEEE Trans. Robot., vol. 40, pp. 660–676, 2024
2024
-
[3]
Six-dof hand-based teleoperation for omnidirectional aerial robots,
J. Li, J. Li, K. Kaneko, H. Liu, L. Shu, and M. Zhao, “Six-dof hand-based teleoperation for omnidirectional aerial robots,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., vol. 1, Oct. 2025, pp. 1–7
2025
-
[4]
6D interaction control with aerial robots: The flying end-effector paradigm,
M. Ryll, G. Muscio, F. Pierri, E. Cataldi, G. Antonelli, F. Caccavale, D. Bicego, and A. Franchi, “6D interaction control with aerial robots: The flying end-effector paradigm,”The International Journal of Robotics Research, vol. 38, no. 9, pp. 1045–1062, Aug. 2019
2019
-
[5]
Design and optimal control of a tiltrotor micro-aerial vehicle for efficient omnidirectional flight,
M. Allenspach, K. Bodie, M. Brunner, L. Rinsoz, Z. Taylor, M. Kamel, R. Siegwart, and J. Nieto, “Design and optimal control of a tiltrotor micro-aerial vehicle for efficient omnidirectional flight,” Int. J. Robot. Res., vol. 39, no. 10-11, pp. 1305–1325, Sep. 2020
2020
-
[6]
Dynamic control of a macro–mini aerial manipulator with elastic suspension,
A. Yi ˘git, L. Cuvillon, M. A. Perozo, S. Durand, and J. Gangloff, “Dynamic control of a macro–mini aerial manipulator with elastic suspension,”IEEE Transactions on Robotics, vol. 39, no. 6, pp. 4820–4836, Dec. 2023
2023
-
[7]
Prototype, Modeling, and Control of Aerial Robots With Physical Interaction: A Review,
H. Zhong, J. Liang, Y . Chen, H. Zhang, J. Mao, and Y . Wang, “Prototype, Modeling, and Control of Aerial Robots With Physical Interaction: A Review,”IEEE Transactions on Automation Science and Engineering, pp. 1–15, 2024
2024
-
[8]
Servo integrated nonlinear model predictive control for overactuated tiltable-quadrotors,
J. Li, J. Sugihara, and M. Zhao, “Servo integrated nonlinear model predictive control for overactuated tiltable-quadrotors,”IEEE Robot. Automat. Lett., vol. 9, no. 10, pp. 8770–8777, Oct. 2024
2024
-
[9]
Learning to fly—a gym environment with pybullet physics for reinforcement learning of multi-agent quadcopter control,
J. Panerati, H. Zheng, S. Zhou, J. Xu, A. Prorok, and A. P. Schoellig, “Learning to fly—a gym environment with pybullet physics for reinforcement learning of multi-agent quadcopter control,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 7512–7519
2021
-
[10]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, no. 1, pp. 411–444, 2022
2022
-
[11]
Nonlinear mpc for quadrotors in close-proximity flight with neural network downwash prediction,
J. Li, L. Han, H. Yu, Y . Lin, Q. Li, and Z. Ren, “Nonlinear mpc for quadrotors in close-proximity flight with neural network downwash prediction,” in2023 62nd IEEE Conference on Decision and Control (CDC), 2023, pp. 2122–2128
2023
-
[12]
Proxfly: Robust control for close proximity quadcopter flight via residual reinforcement learning,
R. Zhang, D. Zhang, and M. W. Mueller, “Proxfly: Robust control for close proximity quadcopter flight via residual reinforcement learning,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 13 683–13 689
2025
-
[13]
Real-time neural mpc: Deep learning model predictive control for quadrotors and agile robotic platforms,
T. Salzmann, E. Kaufmann, J. Arrizabalaga, M. Pavone, D. Scara- muzza, and M. Ryll, “Real-time neural mpc: Deep learning model predictive control for quadrotors and agile robotic platforms,”IEEE Robotics and Automation Letters, vol. 8, no. 4, pp. 2397–2404, 2023
2023
-
[14]
Data-driven mpc for quadrotors,
G. Torrente, E. Kaufmann, P. Föhn, and D. Scaramuzza, “Data-driven mpc for quadrotors,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 3769–3776, 2021
2021
-
[15]
Learning agile and robust omnidirectional aerial motion on overactuated tiltable-quadrotors,
W. Zhang, Z. Ma, J. Li, H. Wang, H. Liu, J. Sugihara, C. Chen, Y . Chen, and M. Zhao, “Learning agile and robust omnidirectional aerial motion on overactuated tiltable-quadrotors,”arXiv preprint arXiv:2602.21583, 2026
-
[16]
Neural network based model predictive control for a quadrotor uav,
B. Jiang, B. Li, W. Zhou, L.-Y . Lo, C.-K. Chen, and C.-Y . Wen, “Neural network based model predictive control for a quadrotor uav,” Aerospace, vol. 9, no. 8, p. 460, 2022
2022
-
[17]
Deterministic and stochastic hybrid modeling with regularization,
A. Osaka, N. Takeishi, and T. Yairi, “Deterministic and stochastic hybrid modeling with regularization,” in2025 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2025, pp. 5637– 5642
2025
-
[18]
Augmenting physical models with deep networks for complex dynamics forecasting,
Y . Yin, V . Le Guen, J. Dona, E. De Bézenac, I. Ayed, N. Thome, and P. Gallinari, “Augmenting physical models with deep networks for complex dynamics forecasting,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2021, no. 12, p. 124012, 2021
2021
-
[19]
Deep grey-box modeling with adaptive data-driven models toward trustworthy estimation of theory-driven models,
N. Takeishi and A. Kalousis, “Deep grey-box modeling with adaptive data-driven models toward trustworthy estimation of theory-driven models,” inInternational Conference on Artificial Intelligence and Statistics, 2023, pp. 4089–4100
2023
-
[20]
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations,”arXiv preprint arXiv:1711.10561, 2017
work page Pith review arXiv 2017
-
[21]
Deep learning-based long-horizon mpc: Robust, high performing, and computationally efficient control for pmsm drives,
M. Abu-Ali, F. Berkel, M. Manderla, S. Reimann, R. Kennel, and M. Abdelrahem, “Deep learning-based long-horizon mpc: Robust, high performing, and computationally efficient control for pmsm drives,” IEEE transactions on power electronics, vol. 37, no. 10, pp. 12 486– 12 501, 2022
2022
-
[22]
L4acados: Learning-based models for acados, applied to gaussian process-based predictive control,
A. Lahr, J. Näf, K. P. Wabersich, J. Frey, P. Siehl, A. Carron, M. Diehl, and M. N. Zeilinger, “L4acados: Learning-based models for acados, applied to gaussian process-based predictive control,”arXiv preprint arXiv:2411.19258, 2024
-
[23]
aca- dos—a modular open-source framework for fast embedded optimal control,
R. Verschueren, G. Frison, D. Kouzoupis, J. Frey, N. v. Duijkeren, A. Zanelli, B. Novoselnik, T. Albin, R. Quirynen, and M. Diehl, “aca- dos—a modular open-source framework for fast embedded optimal control,”Mathematical Programming Computation, vol. 14, no. 1, pp. 147–183, 2022
2022
-
[24]
Hpipm: a high-performance quadratic programming framework for model predictive control,
G. Frison and M. Diehl, “Hpipm: a high-performance quadratic programming framework for model predictive control,”IFAC- PapersOnLine, vol. 53, no. 2, pp. 6563–6569, 2020
2020
-
[25]
Pytorch: An imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high- performance deep learning library,” inNeurIPS, 2019
2019
-
[26]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” arXiv preprint arXiv:1606.08415, 2016
work page Pith review arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.