Cellwise Robust Twoblock Dimension Reduction
Pith reviewed 2026-05-10 10:34 UTC · model grok-4.3
The pith
CRTB provides the first cellwise robust approach to simultaneous dimension reduction for predictor and response blocks by imputing contaminated cells rather than discarding rows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CRTB is the first cellwise robust method for simultaneous dimension reduction of multivariate predictor and response blocks, in both dense and sparse variants. It combines a column-wise pre-filter for cellwise outlier detection with model-based imputation of flagged cells inside an iteratively reweighted M-estimation loop. The algorithm uses the classical twoblock SVD as a warm start and converges quickly, retaining clean cells of partially contaminated rows instead of discarding the observation.
What carries the argument
The iteratively reweighted M-estimation loop that integrates column-wise cellwise outlier pre-filtering and model-based imputation to perform twoblock dimension reduction while retaining usable cells from contaminated rows.
If this is right
- CRTB can handle contamination affecting more than 50% of rows without breakdown.
- It recovers the cellwise outlier pattern with high fidelity from the data.
- In sparse settings, it correctly identifies the informative variables.
- The method provides interpretable results in domain-specific examples with cellwise outliers present.
Where Pith is reading between the lines
- Similar pre-filter and imputation strategies could be adapted to other dimension reduction techniques like principal component analysis for cellwise robustness.
- The approach may prove particularly useful in high-dimensional datasets where casewise deletion would remove too much data.
- Further work could explore extensions to nonlinear or kernel-based twoblock methods.
Load-bearing premise
The column-wise pre-filter must correctly flag contaminated cells without too many errors, and the imputation step must preserve the underlying low-dimensional structure without bias.
What would settle it
A dataset with known cellwise contamination where more than 50 percent of rows are affected and CRTB fails to recover the true dimension reduction directions or misidentifies the outliers would contradict the claims.
Figures













read the original abstract
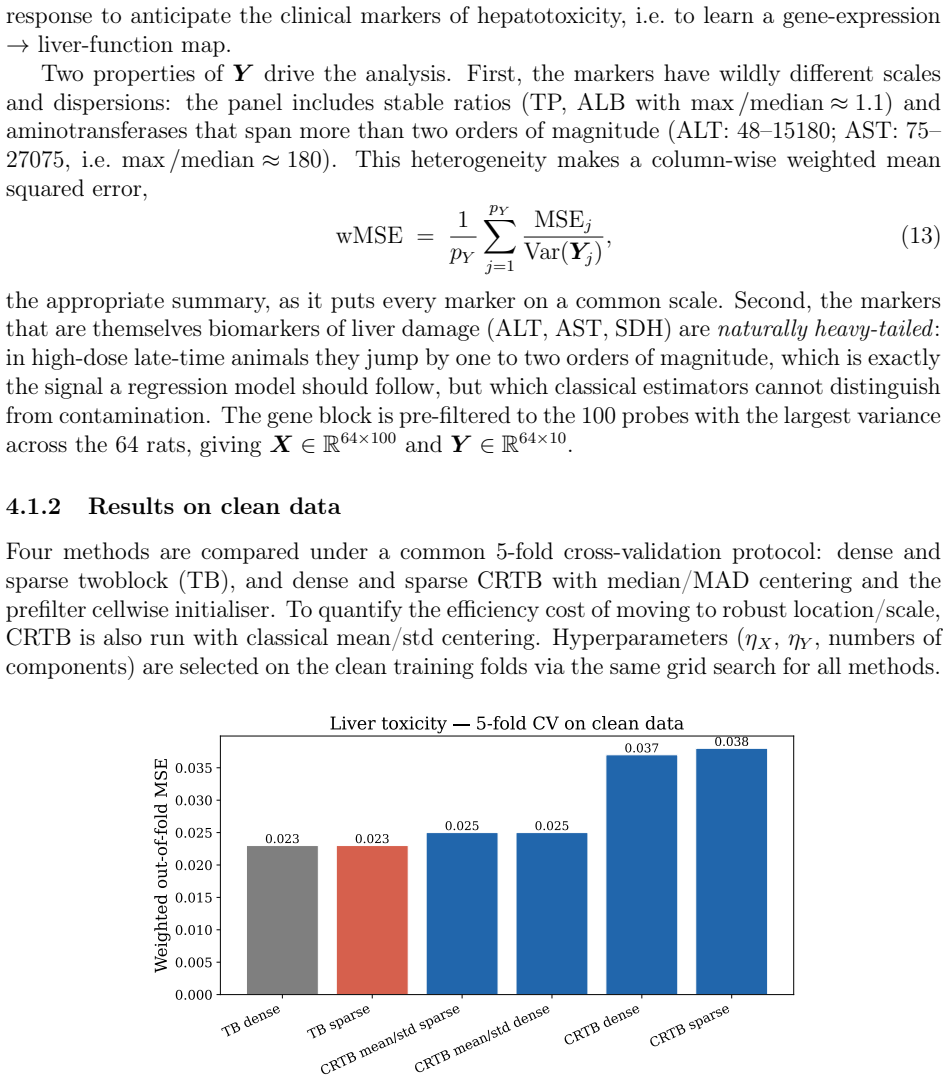
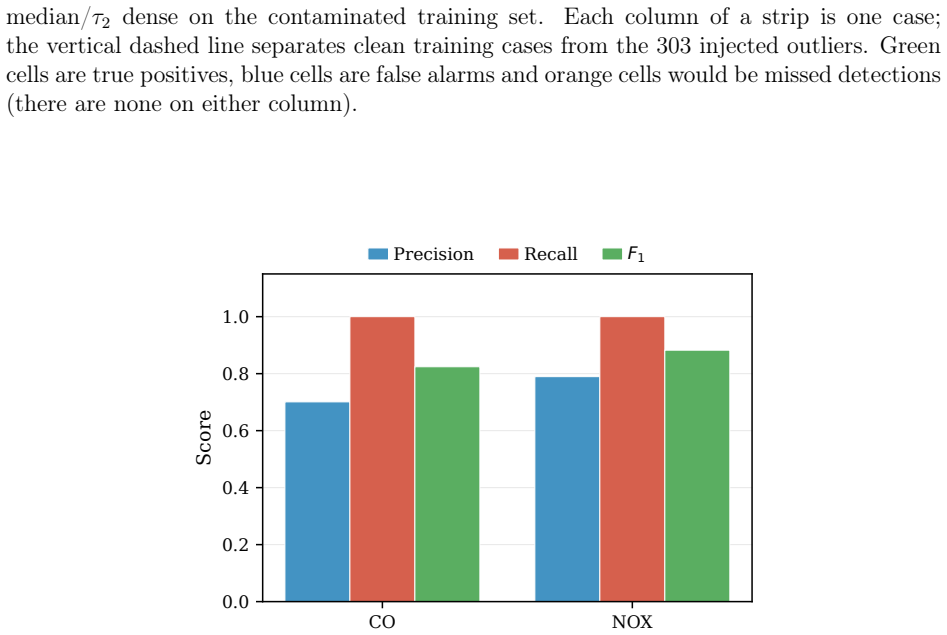
Cellwise Robust Twoblock (CRTB) is introduced, the first cellwise robust method for simultaneous dimension reduction of multivariate predictor and response blocks, in both a dense and a sparse variable-selecting variant. Classical robust methods protect against casewise outliers by downweighting or removing entire observations, a strategy that becomes inefficient -- and eventually breaks down -- when contamination is scattered across individual cells rather than concentrated in whole rows. CRTB combines a column-wise pre-filter for cellwise outlier detection with model-based imputation of flagged cells inside an iteratively reweighted M-estimation loop, retaining the clean cells of partially contaminated rows instead of discarding the observation. An efficient algorithm is provided that uses the classical twoblock SVD as a warm start and converges in a handful of IRLS iterations at a moderate computational cost. The method resists settings where more than $50\%$ of rows contain contaminated cells while retaining comparable efficiency on clean data. A simulation study confirms these properties and shows that CRTB additionally recovers the underlying cellwise outlier pattern with high fidelity and, in the sparse setting, the correct set of informative variables. Two compelling examples illustrate CRTB's practical utility. In each of these, CRTB is shown to be conducive to results that are highly interpretable in the respective domains in the presence of cellwise outliers. As a by-product, the corresponding cells are identified with high fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Cellwise Robust Twoblock (CRTB) method for simultaneous dimension reduction of multivariate predictor and response blocks in both dense and sparse variants. It employs a column-wise pre-filter to detect cellwise outliers, followed by model-based imputation within an iteratively reweighted M-estimation framework that uses classical twoblock SVD as a warm start. The central claims are that CRTB achieves a breakdown point exceeding 50% with respect to the proportion of rows containing contaminated cells, maintains efficiency on clean data, recovers the cellwise outlier pattern with high fidelity, and in the sparse case identifies the correct informative variables. These are supported by a simulation study and two real-data examples demonstrating practical utility and interpretability.
Significance. Should the method's robustness properties and recovery performance be rigorously established, this would constitute a significant contribution to the field of robust multivariate statistics. By addressing cellwise rather than casewise contamination, CRTB enables more efficient use of data in settings where outliers are scattered across observations, which is common in modern high-dimensional applications. The efficient algorithm and dual dense/sparse variants enhance its applicability.
major comments (3)
- §3 (Method description): The reliance on a column-wise pre-filter for cellwise outlier detection ignores potential correlations within and between the predictor and response blocks. This is a load-bearing assumption for the imputation step and the claimed breakdown point, as misflagged cells could bias the twoblock SVD estimates. The manuscript should either provide a theoretical justification or additional simulations under correlated designs to validate this.
- §4 (Algorithm): No convergence analysis or proof of the breakdown point is provided for the full IRLS procedure. The claims appear to rest on the pre-filter's accuracy and the warm-start strategy, but without formal results, it is difficult to assess whether the >50% resistance holds in general.
- Simulation study (Section 6): The simulation study reports high-fidelity recovery, but lacks details on how the data generation incorporates the twoblock structure and correlations; this makes it hard to evaluate if the results support the general claims for both dense and sparse settings.
minor comments (2)
- Introduction: Some references to related work on cellwise robust methods could be expanded for better context.
- Notation section: Clarify the dimensions of the predictor and response matrices early on to aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We address each major comment below, indicating planned revisions where appropriate. Our responses focus on clarifying the methodological choices and strengthening the empirical support.
read point-by-point responses
-
Referee: §3 (Method description): The reliance on a column-wise pre-filter for cellwise outlier detection ignores potential correlations within and between the predictor and response blocks. This is a load-bearing assumption for the imputation step and the claimed breakdown point, as misflagged cells could bias the twoblock SVD estimates. The manuscript should either provide a theoretical justification or additional simulations under correlated designs to validate this.
Authors: The column-wise pre-filter is intentionally marginal to enable scalable cellwise detection without requiring full joint modeling at the detection stage. However, the subsequent model-based imputation explicitly uses the twoblock SVD, which incorporates correlations both within and between the predictor and response blocks. This two-stage structure allows the method to leverage joint information after initial flagging. To empirically address concerns about correlated designs, we will add a new set of simulations with varying correlation structures in the revised manuscript. revision: yes
-
Referee: §4 (Algorithm): No convergence analysis or proof of the breakdown point is provided for the full IRLS procedure. The claims appear to rest on the pre-filter's accuracy and the warm-start strategy, but without formal results, it is difficult to assess whether the >50% resistance holds in general.
Authors: We agree that a rigorous convergence analysis and breakdown-point proof for the complete IRLS procedure would be desirable. Deriving such formal guarantees for this specific combination of pre-filtering, imputation, and twoblock M-estimation is technically involved and falls outside the primary scope of the present work, which emphasizes algorithmic development and practical performance. The >50% resistance claim is supported by extensive Monte Carlo experiments across diverse contamination levels. We will revise the manuscript to include an explicit discussion of the empirical nature of these robustness results and the role of the warm start. revision: partial
-
Referee: Simulation study (Section 6): The simulation study reports high-fidelity recovery, but lacks details on how the data generation incorporates the twoblock structure and correlations; this makes it hard to evaluate if the results support the general claims for both dense and sparse settings.
Authors: We will expand Section 6 with a more detailed description of the data-generating process. This will explicitly document how the twoblock low-rank structure, block-wise correlations, and sparse variable selection are implemented for both the dense and sparse variants, thereby clarifying how the reported recovery performance relates to the general claims. revision: yes
- No formal convergence analysis or proof of the breakdown point for the full IRLS procedure
Circularity Check
No significant circularity; algorithm uses standard IRLS warm-start with independent simulation validation
full rationale
The provided abstract and description present CRTB as an algorithmic combination of a column-wise pre-filter for cellwise outlier detection followed by model-based imputation inside a standard IRLS loop that starts from the classical twoblock SVD. Performance claims (resistance to >50% row contamination, outlier pattern recovery, variable selection in sparse case) are stated to be confirmed by a separate simulation study rather than derived by construction from the fitted parameters themselves. No equations, self-citations, or steps are quoted that reduce a central prediction or uniqueness claim to a fitted input or prior self-result. The derivation chain is therefore self-contained against external benchmarks and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard regularity conditions for M-estimators and IRLS convergence hold.
- ad hoc to paper The column-wise pre-filter identifies cellwise outliers with sufficient accuracy that imputation does not introduce systematic bias into the dimension reduction.
Reference graph
Works this paper leans on
-
[1]
Alqallaf, F., Van Aelst, S., Yohai, V. J., and Zamar, R. H. (2009). Propagation of outliers in multivariate data.The Annals of Statistics, 37(1):311–331. 25
work page 2009
-
[2]
Bushel, P. R., Wolfinger, R. D., and Gibson, G. (2007). Simultaneous clustering of gene expression data with clinical chemistry and pathological evaluations reveals phenotypic prototypes.BMC Systems Biology, 1:15
work page 2007
-
[3]
Centofanti, F., Hubert, M., and Rousseeuw, P. J. (2026). Robust principal components by casewise and cellwise weighting.Technometrics, (just-accepted):1–25
work page 2026
-
[4]
Cook, R. D., Forzani, L., and Liu, L. (2023). Partial least squares for simultaneous reduc- tion of response and predictor vectors in regression.Journal of Multivariate Analysis, 196:105163
work page 2023
-
[5]
Debruyne, M., Höppner, S., Serneels, S., and Verdonck, T. (2019). Outlyingness: Which variables contribute most?Statistics and Computing, 29(4):707–723
work page 2019
-
[6]
Filzmoser, P., Höppner, S., Ortner, I., Serneels, S., and Verdonck, T. (2020). Cellwise robust M regression.Computational Statistics & Data Analysis, 147:106944
work page 2020
-
[7]
Hampel, F. R., Ronchetti, E. M., Rousseeuw, P. J., and Stahel, W. A. (1986).Robust Statistics: The Approach Based on Influence Functions. Wiley Series in Probability and Statistics. John Wiley & Sons
work page 1986
-
[8]
Hubert, M., Rousseeuw, P. J., and Van den Bossche, W. (2019). Macropca: An all-in-one pca method allowing for missing values as well as cellwise and rowwise outliers.Technometrics, 61(4):459–473
work page 2019
-
[9]
Kaya, H., Tüfekci, P., and Uzun, E. (2019). Predicting CO and NOx emissions from gas turbines: Novel data and a benchmark PEMS.Turkish Journal of Electrical Engineering and Computer Sciences, 27(6):4783–4796. Dataset available as UCI Machine Learning Repository #551
work page 2019
-
[10]
Leung, A., Zhang, H., and Zamar, R. (2016). Robust regression estimation and inference in the presence of cellwise and casewise contamination.Computational Statistics & Data Analysis, 99:1–11
work page 2016
-
[11]
Maronna, R. A. and Zamar, R. H. (2002). Robust estimates of location and dispersion for high-dimensional datasets.Technometrics, 44(4):307–317
work page 2002
-
[12]
Pfeiffer, P., Vana-Gür, L., and Filzmoser, P. (2025). Cellwise robust and sparse principal component analysis.Advances in Data Analysis and Classification, pages 1–30
work page 2025
-
[13]
Raymaekers, J. and Rousseeuw, P. J. (2024). Challenges of cellwise outliers.Econometrics and Statistics. In press. Preprint available athttps://arxiv.org/abs/2302.02156
-
[14]
Rousseeuw, P. J. (1984). Least median of squares regression.Journal of the American Statistical Association, 79(388):871–880
work page 1984
-
[15]
Rousseeuw, P. J. and Van den Bossche, W. (2018). Detecting deviating data cells.Techno- metrics, 60(2):135–145. 26
work page 2018
-
[16]
Serneels, S. (2025). Sparse twoblock dimension reduction: A versatile alternative to sparse PLS2 and CCA.Journal of Chemometrics, 39:e70051
work page 2025
- [17]
-
[18]
Serneels, S., Croux, C., Filzmoser, P., and Van Espen, P. J. (2005). Partial robust M- regression.Chemometrics and Intelligent Laboratory Systems, 79(1–2):55–64
work page 2005
-
[19]
Wold, H. (1966). Nonlinear estimation by iterative least squares procedures. In David, F., editor,Papers in Statistics: Festschrift for J. Neyman, pages 411–444. Wiley
work page 1966
-
[20]
Yao, F., Coquery, J., and Lê Cao, K.-A. (2012). Independent principal component anal- ysis for biologically meaningful dimension reduction of large biological data sets.BMC Bioinformatics, 13:24. 27
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.