Recognition: unknown
Computer vision and converse theorems
Pith reviewed 2026-05-10 09:59 UTC · model grok-4.3
The pith
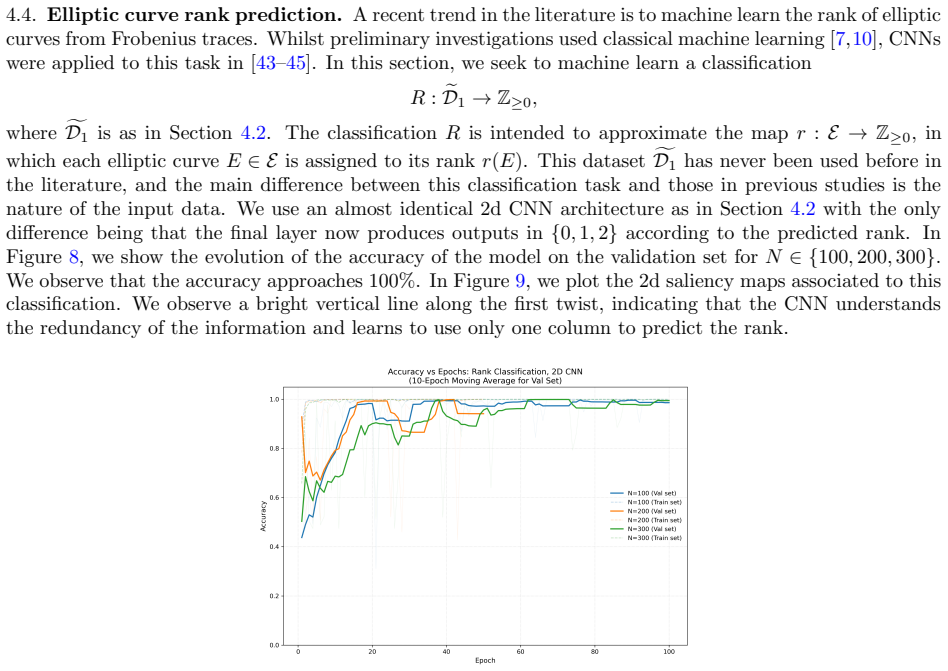
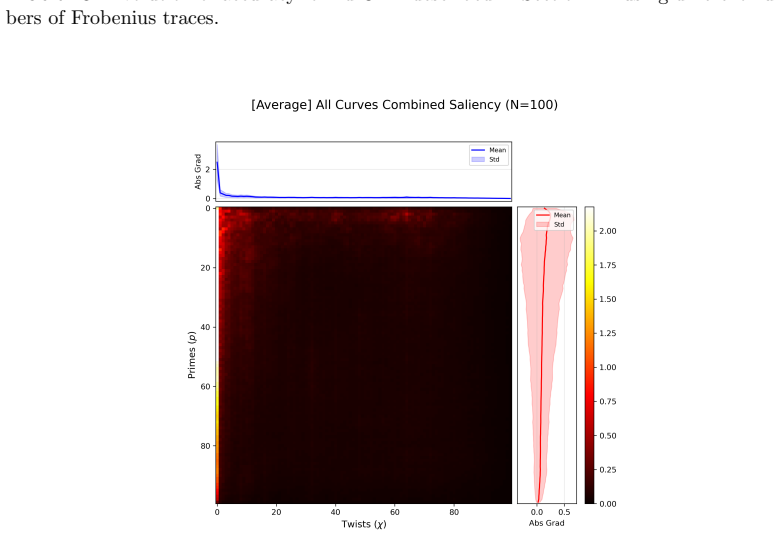
A two-dimensional CNN trained on images of elliptic curves and their twists separates arithmetic data from random matrix models better than a one-dimensional network on Frobenius traces and can predict analytic rank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing an elliptic curve together with its twists as a vector field and encoding that field as a digital image, a two-dimensional convolutional neural network distinguishes families of elliptic curves with fixed conductor from random matrix data drawn from the same Sato-Tate distribution more effectively than a one-dimensional network trained on vectors of Frobenius traces without twisting data. The same two-dimensional architecture can be trained to predict the analytic rank of an elliptic curve, and the prediction factors through the untwisted Frobenius traces.
What carries the argument
The vector-field encoding of an elliptic curve and its quadratic twists rendered as a two-dimensional digital image that supplies input to a convolutional neural network.
If this is right
- The vector-field images supply twisting information that allows the network to isolate conductor-family features from Sato-Tate statistics.
- Analytic-rank prediction occurs by routing through the untwisted Frobenius traces, indicating that the image format organizes trace data in a manner useful for rank detection.
- The distinction between arithmetic and random-matrix data holds inside a fixed conductor interval, showing that the method identifies family-specific deviations rather than global distribution properties.
- The approach, motivated by converse theorems, empirically checks whether twisted data determines the underlying arithmetic object more sharply than untwisted data alone.
Where Pith is reading between the lines
- The same image-encoding technique could be applied to families of higher-rank motives to test whether twisting data remains informative when the underlying L-functions are more complex.
- If the advantage persists when the random-matrix samples are generated by alternative procedures, the result would support that the gain comes from arithmetic structure rather than sampling artifacts.
- The observation that rank prediction factors through traces suggests the image representation mainly serves as a data-layout device, which might be replaced by other structured formats in future models of L-function data.
- This method could be used to probe converse-type questions for other objects in the Langlands correspondence by checking whether networks recover distinguishing features from twisted data images.
Load-bearing premise
The performance difference between the image-based two-dimensional network and the trace-based one-dimensional network arises from arithmetic content captured by the vector-field representation rather than from details of image rendering or data sampling choices.
What would settle it
Retraining the two-dimensional CNN on images in which the twist components have been replaced by unrelated or randomized values and finding that its separation accuracy falls to the level of the one-dimensional trace network would falsify the claim that the vector-field structure supplies the decisive arithmetic information.
Figures







read the original abstract
Random matrices provide a well-established statistical model for a range of arithmetic phenomena. In this paper, we investigate the extent to which one- and two-dimensional convolutional neural networks (CNNs) can distinguish between arithmetic data arising from elliptic curves with conductor in a fixed interval and random matrix data drawn from the same Sato-Tate distribution. Inspired by converse theorems in the Langlands program, we represent each elliptic curve together with its twists as a vector field and, subsequently, encode that vector field as a digital image. We observe that a two-dimensional CNN trained on this image data is better able to separate conductor families from random matrix data than a one-dimensional CNN trained on vectors of Frobenius traces without twisting data. We also observe that the same two-dimensional architecture can predict the analytic rank of an elliptic curve, and it does so by factoring through the (untwisted) Frobenius traces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a two-dimensional CNN trained on digital images encoding elliptic curves together with their twists as vector fields outperforms a one-dimensional CNN trained on vectors of untwisted Frobenius traces when distinguishing elliptic curves of fixed conductor from random-matrix data sampled from the matching Sato-Tate distribution. It further claims that the same 2D architecture predicts the analytic rank of an elliptic curve by factoring through the untwisted Frobenius traces.
Significance. If the reported performance differences prove robust under controlled experiments, the work would provide observational evidence that image-based representations of arithmetic data can extract invariants more effectively than raw trace vectors, offering a computational probe potentially relevant to converse theorems. The approach is novel in its use of computer-vision techniques for arithmetic statistics and could stimulate further machine-learning investigations of Langlands correspondences, though its current exploratory nature limits immediate theoretical impact.
major comments (3)
- [Abstract and experimental comparison] Abstract and experimental comparison: the central claim attributes the superior separation performance of the 2D CNN to its image-based vector-field encoding, yet the 2D model receives both the elliptic curve and its twists while the 1D model receives only untwisted traces. This design fails to isolate the contribution of the two-dimensional representation from the simple presence of additional twist data; an ablation removing twist channels from the 2D input or supplying twists to the 1D baseline is required to support the stated conclusion.
- [Abstract and rank-prediction claim] Rank-prediction claim (abstract): the assertion that the 2D network predicts analytic rank 'by factoring through the (untwisted) Frobenius traces' is unsupported by any reported analysis such as channel-ablation results, saliency maps, or a direct comparison against a trace-only model. Without such evidence it remains possible that the network exploits twist channels, undermining the specific mechanistic claim.
- [Methods and results sections] Methods and results sections: the abstract and reported observations provide no information on training/validation splits, sample sizes, statistical significance tests for accuracy differences, error bars, or controls for image-rendering artifacts. These omissions render the empirical performance gaps impossible to assess for robustness or reproducibility.
minor comments (3)
- [Data encoding] The precise construction of the vector field from the elliptic curve and twist data, together with the image-rendering parameters (resolution, normalization, color mapping), should be described in sufficient technical detail to allow replication.
- [Random-matrix data generation] Clarify the exact Sato-Tate measure and random-matrix sampling procedure used for the comparison data set, including how the conductor interval is matched.
- [Introduction] Add explicit references to the relevant converse theorems in the Langlands program when motivating the image-encoding approach.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify important gaps in experimental controls and supporting analyses that we have addressed through revisions to the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and experimental comparison] Abstract and experimental comparison: the central claim attributes the superior separation performance of the 2D CNN to its image-based vector-field encoding, yet the 2D model receives both the elliptic curve and its twists while the 1D model receives only untwisted traces. This design fails to isolate the contribution of the two-dimensional representation from the simple presence of additional twist data; an ablation removing twist channels from the 2D input or supplying twists to the 1D baseline is required to support the stated conclusion.
Authors: We agree that the original design does not fully isolate the contribution of the two-dimensional image encoding from the presence of twist data. The inclusion of twists was motivated by the converse-theorem perspective underlying the vector-field representation. In the revised manuscript we have added the requested ablation experiments: a 2D CNN trained on single-channel (untwisted) images and a 1D CNN supplied with twist-trace vectors. These controlled comparisons confirm that the performance advantage arises primarily from the two-dimensional convolutional architecture rather than from the mere addition of twist information. revision: yes
-
Referee: [Abstract and rank-prediction claim] Rank-prediction claim (abstract): the assertion that the 2D network predicts analytic rank 'by factoring through the (untwisted) Frobenius traces' is unsupported by any reported analysis such as channel-ablation results, saliency maps, or a direct comparison against a trace-only model. Without such evidence it remains possible that the network exploits twist channels, undermining the specific mechanistic claim.
Authors: The mechanistic statement in the abstract was based on internal observations that the network's rank predictions remain accurate when twist channels are down-weighted. To make this evidence explicit, the revised manuscript now includes channel-ablation results (masking twist channels while retaining untwisted traces), saliency-map visualizations, and a direct comparison against a trace-only 1D baseline for rank prediction. These additions substantiate that the network factors through the untwisted Frobenius traces. revision: yes
-
Referee: [Methods and results sections] Methods and results sections: the abstract and reported observations provide no information on training/validation splits, sample sizes, statistical significance tests for accuracy differences, error bars, or controls for image-rendering artifacts. These omissions render the empirical performance gaps impossible to assess for robustness or reproducibility.
Authors: We acknowledge that these experimental details were omitted from the original submission. The revised Methods section now reports the exact sample sizes per conductor family and Sato-Tate ensemble, the train/validation/test splits (with 5-fold cross-validation), paired statistical tests for accuracy differences together with p-values, error bars obtained from multiple independent training runs, and explicit controls confirming that variations in image-rendering parameters do not affect the reported performance gaps. revision: yes
Circularity Check
No circularity; empirical results on independent data
full rationale
The paper reports observational performance of CNNs trained on independently generated datasets: elliptic curve data (with twists encoded as images) versus random matrix samples from the Sato-Tate distribution. All claims are measured accuracies and predictions on held-out test data drawn from known external distributions. No quantity is defined in terms of a fitted parameter that is then re-used as a prediction, no self-citation supplies a load-bearing uniqueness theorem or ansatz, and the image encoding is a fixed representational choice rather than a self-referential definition. The central claims therefore remain self-contained against external benchmarks and do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- CNN architecture hyperparameters and training schedule
axioms (1)
- domain assumption Elliptic curves with conductor in a fixed interval obey the Sato-Tate distribution for their Frobenius traces
Reference graph
Works this paper leans on
-
[1]
Deep-Learning the Landscape.arXiv:1706.02714, PLB, 774, 564-568, 6 2017
Yang-Hui He. Deep-Learning the Landscape.arXiv:1706.02714, PLB, 774, 564-568, 6 2017
-
[2]
Machine learning as a tool in theoretical science.Nature Reviews Physics, 4(3):145–146, 2022
Michael R Douglas. Machine learning as a tool in theoretical science.Nature Reviews Physics, 4(3):145–146, 2022
2022
-
[3]
Rigor with machine learning from field theory to the Poincar´ e con- jecture.Nature Rev
Sergei Gukov, James Halverson, and Fabian Ruehle. Rigor with machine learning from field theory to the Poincar´ e con- jecture.Nature Rev. Phys., 6(5):310–319, 2024
2024
-
[4]
Can AI make genuine theoretical discoveries?Nature, 625(7994):241–241, 2024
Yang-Hui He and Mikhail Burtsev. Can AI make genuine theoretical discoveries?Nature, 625(7994):241–241, 2024
2024
-
[5]
AI-driven research in pure mathematics and theoretical physics.Nature Reviews Physics, 6(9):546–553, 2024
Yang-Hui He. AI-driven research in pure mathematics and theoretical physics.Nature Reviews Physics, 6(9):546–553, 2024
2024
-
[6]
Mathematical data science.arXiv:2502.08620, 2025
Michael R Douglas and Kyu-Hwan Lee. Mathematical data science.arXiv:2502.08620, 2025
-
[7]
Machine Learning meets Number Theory: The Data Science of Birch-Swinnerton-Dyer
Laura Alessandretti, Andrea Baronchelli, and Yang-Hui He. Machine Learning meets Number Theory: The Data Science of Birch-Swinnerton-Dyer. 11 2019
2019
-
[8]
Machine-learning the Sato–Tate conjecture.J
Yang-Hui He, Kyu-Hwan Lee, and Thomas Oliver. Machine-learning the Sato–Tate conjecture.J. Symb. Comput., 111:61– 72, 2022
2022
-
[9]
Machine-learning number fields.Mathematics, Computation and Ge- ometry of Data, 2:49–66, 2022
Yang-Hui He, Kyu-Hwan Lee, and Thomas Oliver. Machine-learning number fields.Mathematics, Computation and Ge- ometry of Data, 2:49–66, 2022
2022
-
[10]
Machine learning invariants of arithmetic curves.J
Yang-Hui He, Kyu-Hwan Lee, and Thomas Oliver. Machine learning invariants of arithmetic curves.J. Symb. Comput., 115:478–491, 2023
2023
-
[11]
Machine-learning class numbers of real quadratic fields.International Journal of Data Science in the Mathematical Sciences, 1:107–134, 2023
Malik Amir, Yang-Hui He, Kyu-Hwan Lee, Thomas Oliver, and Eldar Sultanow. Machine-learning class numbers of real quadratic fields.International Journal of Data Science in the Mathematical Sciences, 1:107–134, 2023
2023
-
[12]
A. Weil. Uber die Bestimmung Dirichletscher Reihen durch Functionalgleichungen.Math. Ann., 168:149–156, 1967
1967
-
[13]
MIT Press, 2016.http://www.deeplearningbook
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016.http://www.deeplearningbook. org
2016
-
[14]
LNM 2293
Yang-Hui He.The Calabi–Yau Landscape: From Geometry, to Physics, to Machine Learning. LNM 2293. Springer, 2018
2018
-
[15]
TheL-functions and modular forms database.https://www.lmfdb.org, 2025
The LMFDB Collaboration. TheL-functions and modular forms database.https://www.lmfdb.org, 2025. [Online; accessed 5 November 2025]
2025
-
[16]
Murmurations of elliptic curves.ArXiv:2204.10140, Experimental Mathematics, 2025
Yang-Hui He, Kyu-Hwan Lee, Thomas Oliver, and Alexey Pozdnyakov. Murmurations of elliptic curves.ArXiv:2204.10140, Experimental Mathematics, 2025
-
[17]
Booker, Min Lee, and David Lowry-Duda
Jonathan Bober, Andrew R. Booker, Min Lee, and David Lowry-Duda. Murmurations of modular forms in the weight aspect.arXiv:2310.07746, 2023
-
[18]
PhD thesis, Princeton University, 2024
Nina Zubrilina.Convergence and Correlations of Coefficients of Cusp Forms. PhD thesis, Princeton University, 2024
2024
-
[19]
Booker, Min Lee, David Lowry-Duda, Andrei Seymour-Howell, and Nina Zubrilina
Andrew R. Booker, Min Lee, David Lowry-Duda, Andrei Seymour-Howell, and Nina Zubrilina. Murmurations of Maass forms.arXiv:2409.00765, 2024
-
[20]
Murmurations and Sato-Tate conjectures for high rank zetas of elliptic curves.arXiv:2410.04952, 2024
Zhan Shi and Lin Weng. Murmurations and Sato-Tate conjectures for high rank zetas of elliptic curves.arXiv:2410.04952, 2024
-
[21]
Murmurations and ratios conjectures.http://arxiv.org/abs/2408.12723v1, 2024
Alex Cowan. Murmurations and ratios conjectures.arXiv:2408.12723, 2024
-
[22]
Learning Euler factors of elliptic curves.arXiv:2502.10357, 2025
Angelica Babei, Fran¸ cois Charton, Edgar Costa, Xiaoyu Huang, Kyu-Hwan Lee, David Lowry-Duda, Ashvni Narayanan, and Alexey Pozdnyakov. Learning Euler factors of elliptic curves.arXiv:2502.10357, 2025
-
[23]
Murmurations of Dirichlet characters.International Mathematics Research Notices, 2025(1):rnae277, 2025
Kyu-Hwan Lee, Thomas Oliver, and Alexey Pozdnyakov. Murmurations of Dirichlet characters.International Mathematics Research Notices, 2025(1):rnae277, 2025
2025
-
[24]
Machine learning the vanishing order of rational L-functions
Joanna Bieri, Giorgi Butbaia, Edgar Costa, Alyson Deines, Kyu-Hwan Lee, David Lowry-Duda, Thomas Oliver, Yidi Qi, and Tamara Veenstra. Machine learning the vanishing order of rational L-functions. 2 2025
2025
-
[25]
Alex Cowan. On the mean value of GL 1 and GL2 L-functions, with applications to murmurations.arXiv:2504.09944, 2025
-
[26]
Zvonimir Bujanovi´ c, Matija Kazalicki, and Domagoj Vlah. Improving elliptic curve rank classification using multi-value and learned Mestre-Nagao sums.arXiv:2506.07967, 2025
-
[27]
Kyu-Hwan Lee and Seewoo Lee. Machines learn number fields, but how? the case of Galois groups.arXiv:2508.06670, 2025
-
[28]
Murmurations for elliptic curves ordered by height.arXiv:2504.12295, 2025
Will Sawin and Andrew V Sutherland. Murmurations for elliptic curves ordered by height.arXiv:2504.12295, 2025
-
[29]
Murmurations using Petersson trace formula.arXiv:2507.11418, 2025
Chan Ieong Kuan and Didier Lesesvre. Murmurations using Petersson trace formula.arXiv:2507.11418, 2025
-
[30]
On murmurations and trace formulas.arXiv:2506.01640, 2025
David Lowry-Duda. On murmurations and trace formulas.arXiv:2506.01640, 2025
-
[31]
Variations on murmurations.arXiv:2505.01093, 2025
Kimball Martin. Variations on murmurations.arXiv:2505.01093, 2025
-
[32]
Zhan Shi and Lin Weng. Murmurations and Sato-Tate conjectures for high rank zetas of elliptic curves II: Beyond Riemann hypothesis.arXiv:2501.10220, 2025
-
[33]
Distribution of local signs of modular forms and murmurations of Fourier coefficients.Mathematika, 71(3):e70028, 2025
Kimball Martin. Distribution of local signs of modular forms and murmurations of Fourier coefficients.Mathematika, 71(3):e70028, 2025
2025
-
[34]
Murmurations of HeckeL-functions of imaginary quadratic fields.arXiv:2503.17967, 2025
Zeyu Wang. Murmurations of HeckeL-functions of imaginary quadratic fields.arXiv:2503.17967, 2025
-
[35]
Springer Science & Business Media, 2013
Joseph H Silverman.Advanced topics in the arithmetic of elliptic curves. Springer Science & Business Media, 2013
2013
-
[36]
CRC Press, 2016
Jean-Pierre Serre.Lectures on N X (p). CRC Press, 2016
2016
-
[37]
Number 55
Daniel Bump.Automorphic forms and representations. Number 55. Cambridge university press, 1998
1998
-
[38]
CV elliptic curve.https://github.com/yidiq7/CV_elliptic_curve, 2026
Yidi Qi. CV elliptic curve.https://github.com/yidiq7/CV_elliptic_curve, 2026. [Online; accessed 5 March 2026]
2026
-
[39]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C.J. Burges, L. Bottou, and K.Q. Weinberger, editors,Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012
2012
-
[40]
J. B. Conrey and D. Farmer. An extension of Hecke’s converse theorem.Int. Math. Res. Not. IMRN, 9:445–463, 1995
1995
-
[41]
Bedert, G
B. Bedert, G. Cooper, T. Oliver, and P. Zhang. Twisting moduli for GL(2).Journal of number theory, 217:142–162, 2020. 12
2020
-
[42]
M. J. Razar. Modular forms forG 0(N) and Dirichlet series.Trans. Amer. Math. Soc., 231(2):489–495, 1977
1977
-
[43]
Ranks of elliptic curves and deep neural networks.Res
Matija Kazalicki and Domagoj Vlah. Ranks of elliptic curves and deep neural networks.Res. Number Theory, 9(3):Paper No. 53, 21, 2023
2023
-
[44]
Predicting root numbers with neural networks.arXiv:2403.14631, 2024
Alexey Pozdnyakov. Predicting root numbers with neural networks.arXiv:2403.14631, 2024
-
[45]
Joanna Bieri, Edgar Costa, Alyson Deines, Kyu-Hwan Lee, David Lowry-Duda, Thomas Oliver, Yidi Qi, and Tamara Veenstra. Murmurations, Mestre–Nagao sums, and convolutional neural networks for elliptic curves.arXiv:2603.17681, 2026. London Institute for Mathematical Sciences, Royal Institution, London W1S 4BS, UK Merton College, Oxford, OX14JD, UK Email addr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.