Recognition: unknown
Federated Parameter-Efficient Adaptation for Interference Mitigation at the Wireless Edge
Pith reviewed 2026-05-10 08:07 UTC · model grok-4.3
The pith
Placing low-rank adapters on frozen temporal CNNs and federating only those adapters enables interference mitigation across heterogeneous base stations with 20 times lower communication cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
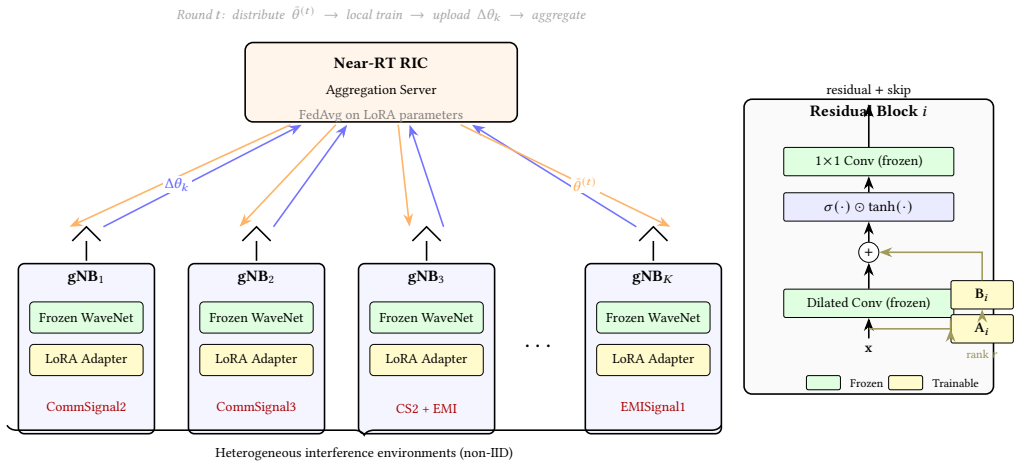
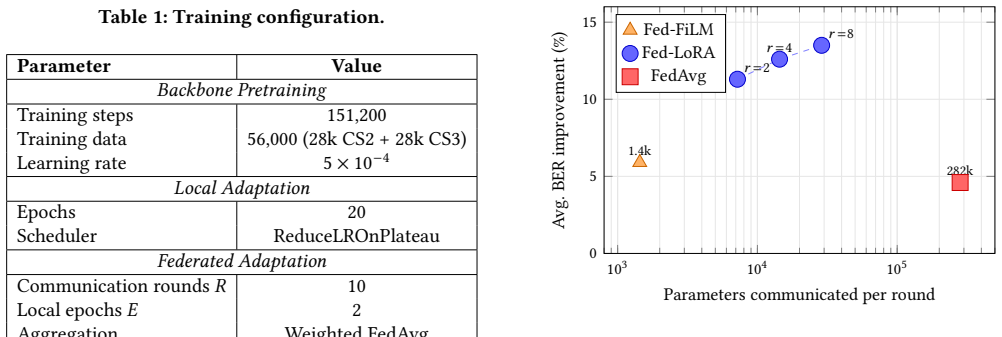
By inserting low-rank adapters only into the dilated convolutional layers of the temporal CNN, the frozen backbone preserves shared signal-extraction features while the adapters learn local interference patterns; federating these adapters via FedAvg then yields 12.6 percent average BER improvement over the frozen model, nearly matching the 12.8 percent of purely local LoRA, outperforming local training on data-starved nodes, and avoiding the catastrophic failure of full-model FedAvg under heterogeneous conditions.
What carries the argument
Low-rank adapters placed on the dilated convolutional layers of a temporal CNN for interference suppression, aggregated across nodes by the standard FedAvg procedure.
If this is right
- Communication volume per round falls by up to a factor of 20 relative to transmitting full model updates.
- Nodes with few local samples receive performance gains from knowledge transferred through the federated adapters.
- The method remains stable where full-model federated averaging produces sharp performance drops.
- Local-only LoRA already improves BER by 12.8 percent on average; the federated version stays within 0.2 percent of that figure.
Where Pith is reading between the lines
- The same placement of adapters on dilated layers could be tested on other temporal tasks such as channel prediction or beam tracking at the edge.
- As network density grows, the 20-fold communication reduction would become increasingly decisive for feasibility.
- If the backbone is pretrained on a wider range of interference types, the adapters might require even fewer local samples to reach target performance.
Load-bearing premise
The frozen backbone continues to extract useful general signal features even when interference statistics differ markedly from one base station to the next.
What would settle it
A controlled experiment in which base stations experience more extreme non-IID interference distributions than those simulated here, checking whether the federated adapters still deliver approximately 12 percent BER improvement on data-poor nodes.
Figures


read the original abstract
Dense wireless deployments face co-channel interference from heterogeneous sources that vary across base stations (gNBs in 5G). While centralized DNN-based approaches to interference mitigation have shown strong performance, deploying and adapting these models across distributed gNBs via federated learning (FL) requires transmitting full model updates each round, resulting in a cost that scales poorly with network density. Parameter-efficient fine-tuning (PEFT) reduces this burden by training and communicating only a small fraction of parameters. While traditionally applied to large foundation models, we adapt Low-Rank Adaptation (LoRA) to temporal convolutional neural network architectures for interference suppression, placing low-rank adapters on the dilated convolutional layers. This placement enables LoRA to learn local interference-specific temporal patterns, while the frozen backbone retains the shared signal extraction capability. These lightweight adapters (5.1\% of backbone parameters) are federated via FedAvg, reducing per-round communication by up to 20$\times$ compared to federating full model updates. We evaluate various PEFT strategies across simulated distributed gNBs with non-IID interference environments. Results show that local LoRA achieves 12.8\% average BER improvement over the frozen backbone, while Fed-LoRA achieves comparable performance (12.6\%). Fed-LoRA outperforms local adaptation on data-starved nodes where federated knowledge transfer compensates for limited samples, all while avoiding the catastrophic degradation observed with full-model FedAvg under heterogeneous conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes adapting Low-Rank Adaptation (LoRA) to temporal convolutional networks for federated interference mitigation at distributed 5G gNBs. By placing low-rank adapters only on dilated convolutional layers (5.1% of backbone parameters), the approach freezes the backbone to retain shared signal extraction while federating adapters via FedAvg. This yields up to 20× communication reduction per round. Empirical results claim local LoRA achieves 12.8% average BER improvement over the frozen backbone, Fed-LoRA matches it at 12.6%, outperforms local adaptation on data-starved nodes, and avoids the degradation of full-model FedAvg under non-IID heterogeneous interference.
Significance. If the results hold with proper verification, the work demonstrates a practical application of parameter-efficient fine-tuning to smaller domain-specific models in wireless networks, enabling scalable federated adaptation without full-model transmission costs. The avoidance of catastrophic degradation under heterogeneity and benefits for data-starved nodes highlight potential for real-world edge deployment in dense 5G scenarios. It extends PEFT techniques beyond large foundation models to temporal CNNs for interference suppression.
major comments (2)
- Abstract: The reported 12.8% (local LoRA) and 12.6% (Fed-LoRA) average BER improvements over the frozen backbone are presented without any details on simulation setup (number of gNBs, exact non-IID interference distributions, samples per node, error bars, or statistical significance tests). These omissions make the central performance claims unverifiable and prevent assessment of whether the gains are robust or attributable to the proposed method.
- Abstract: The key assumption that the frozen backbone retains shared signal extraction capability across heterogeneous non-IID interference environments at distributed gNBs is stated as enabling the LoRA placement and Fed-LoRA success, but no supporting evidence is provided (e.g., per-gNB backbone-only BER results, ablation isolating backbone performance, or pre-training distribution details). This assumption is load-bearing for attributing comparable performance and avoidance of FedAvg collapse to federated adapter transfer.
minor comments (1)
- Abstract: The evaluation of 'various PEFT strategies' is mentioned but not enumerated or compared in detail beyond LoRA and full FedAvg; a table or section listing all tested methods and their communication/performance trade-offs would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below with clarifications from the full paper and propose targeted revisions to enhance verifiability and strengthen the presentation of our assumptions.
read point-by-point responses
-
Referee: Abstract: The reported 12.8% (local LoRA) and 12.6% (Fed-LoRA) average BER improvements over the frozen backbone are presented without any details on simulation setup (number of gNBs, exact non-IID interference distributions, samples per node, error bars, or statistical significance tests). These omissions make the central performance claims unverifiable and prevent assessment of whether the gains are robust or attributable to the proposed method.
Authors: We agree that the abstract, by design, is a concise summary and omits granular experimental parameters. The full manuscript provides these details in Section 4 (Experimental Setup) and Section 5 (Results), including the distributed gNB configuration, modeling of non-IID interference, per-node sample counts, error bars from repeated trials, and statistical significance testing. To improve immediate verifiability, we will revise the abstract to include a brief parenthetical summary of the setup and analysis approach without exceeding typical length constraints. revision: partial
-
Referee: Abstract: The key assumption that the frozen backbone retains shared signal extraction capability across heterogeneous non-IID interference environments at distributed gNBs is stated as enabling the LoRA placement and Fed-LoRA success, but no supporting evidence is provided (e.g., per-gNB backbone-only BER results, ablation isolating backbone performance, or pre-training distribution details). This assumption is load-bearing for attributing comparable performance and avoidance of FedAvg collapse to federated adapter transfer.
Authors: The manuscript presents indirect support for this assumption through the main results: local LoRA and Fed-LoRA achieve comparable BER gains while full-model FedAvg exhibits catastrophic degradation under the same non-IID conditions, consistent with the backbone preserving transferable signal features. However, we acknowledge that explicit per-gNB backbone-only evaluations and pre-training details would make the claim more robust. We will add a dedicated ablation subsection with these analyses in the revised manuscript. revision: yes
Circularity Check
No circularity: purely empirical performance evaluation
full rationale
The paper reports simulation results comparing local LoRA, Fed-LoRA, and full-model FedAvg on BER for interference mitigation using TCN backbones. No equations, derivations, or first-principles predictions are present. Claims rest on observed average improvements (12.8% local, 12.6% federated) and qualitative statements about adapter placement, none of which reduce to fitted inputs or self-citations by construction. The frozen-backbone assumption is an empirical premise tested via the reported experiments rather than a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bouziane Brik, Hatim Chergui, Lanfranco Zanzi, Francesco Devoti, Adlen Ksentini, Muhammad Shuaib Siddiqui, Xavier Costa-Pérez, and Christos Verikoukis. 2025. Explainable AI in 6G O-RAN: A Tutorial and Survey on Architecture, Use Cases, Challenges, and Future Research. IEEE Communications Surveys & Tutorials27, 5 (2025), 2826–. https: //doi.org/10.1109/COM...
- [2]
-
[3]
Ahmet M. Elbir and Sinem Coleri. 2021. Federated Learning for Chan- nel Estimation in Conventional and RIS-Assisted Massive MIMO.IEEE Transactions on Wireless Communications20, 10 (2021), 6518–6533. https://doi.org/10.1109/TWC.2021.3081836
-
[4]
Zhidong Gao, Zhenxiao Zhang, Yuanxiong Guo, and Yanmin Gong
-
[5]
InIEEE INFOCOM 2025 – IEEE 10 Conference on Computer Communications
Federated Adaptive Fine-Tuning of Large Language Models with Heterogeneous Quantization and LoRA. InIEEE INFOCOM 2025 – IEEE 10 Conference on Computer Communications. IEEE
2025
- [6]
-
[7]
Zhen Han, Ning Ding, Yuxian Wu, Xiang Zhao, Kai Lv, Yixuan Gu, Zhiyuan Liu, and Maosong Sun. 2024. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey.Comput. Surveys(2024). https://doi.org/10.1145/3638552
-
[8]
Lukas Henneke. 2024. Improving Data-Driven RF Signal Separation with SOI-Matched Autoencoders. InProceedings of the IEEE Interna- tional Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW). IEEE, 45–46. https://doi.org/10.1109/ICASSPW62465.2024. 10626245
-
[9]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Syl- vain Gelly. 2019. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97). 2790–2799
2019
-
[10]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations (ICLR)
2022
-
[11]
Hiten Prakash Kothari and R. Michael Buehrer. 2025. Interference Mitigation using U-Net Autoencoder based system.arXiv preprint arXiv:2512.13844(2025)
-
[12]
Alejandro Lancho, Amir Weiss, Gary C. F. Lee, Tejas Jayashankar, Binoy G. Kurien, Yury Polyanskiy, and Gregory W. Wornell. 2025. RF Challenge: The Data-Driven Radio Frequency Signal Separation Challenge.IEEE Open Journal of the Communications Society6 (2025), 4083–4100. https://doi.org/10.1109/OJCOMS.2025.3556319
-
[13]
H Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProceedings of the 20th In- ternational Conference on Artificial Intelligence and Statistics (AISTATS), Vol. 54. 1–10
2017
-
[14]
Mostafa Naseri, Jaron Fontaine, Ingrid Moerman, Eli De Poorter, and Adnan Shahid. 2024. A U-Net Architecture for Time-Frequency In- terference Signal Separation of RF Waveforms. InProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Pro- cessing Workshops (ICASSPW). IEEE, 91–92. https://doi.org/10.1109/ ICASSPW62465.2024.10626228
-
[15]
Vincent Poor, and Adnan Shahid
Mostafa Naseri, Eli De Poorter, Ingrid Moerman, H. Vincent Poor, and Adnan Shahid. 2025. High-Throughput Adaptive Co-Channel Interference Cancellation for Edge Devices Using Depthwise Separa- ble Convolutions, Quantization, and Pruning.IEEE Open Journal of the Communications Society6 (2025), 656–. https://doi.org/10.1109/ OJCOMS.2024.3523797
-
[16]
Anselme Ndikumana, Kim Khoa Nguyen, and Mohamed Cheriet. 2023. Federated Learning Assisted Deep Q-Learning for Joint Task Offload- ing and Fronthaul Segment Routing in Open RAN.IEEE Transac- tions on Network and Service Management20, 3 (2023), 3261–3273. https://doi.org/10.1109/TNSM.2023.3245544
-
[17]
Shah, Daniel J
Taiwo Oyedare, Vijay K. Shah, Daniel J. Jakubisin, and Jeffrey H. Reed
-
[18]
https://doi.org/10.1109/ACCESS.2022.3185124
Interference Suppression Using Deep Learning: Current Ap- proaches and Open Challenges.IEEE Access10 (2022), 66238–66266. https://doi.org/10.1109/ACCESS.2022.3185124
-
[19]
Marina, and Thanos Triantafyllou
Qingrui Pan, Mahesh K. Marina, and Thanos Triantafyllou. 2025. On NextG Open RAN as a Sensing Infrastructure. InProceedings of the 26th International Workshop on Mobile Computing Systems and Applications (HotMobile ’25). ACM, CA, La Quinta, USA. https://doi.org/10.1145/ 3708468.3711894
-
[20]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. 2018. FiLM: Visual Reasoning with a General Condi- tioning Layer. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. 3942–3951
2018
- [21]
- [22]
-
[23]
Yasintha Rumesh, Dinaj Attanayaka, Pawani Porambage, Jarno Pinola, Joshua Groen, and Kaushik Chowdhury. 2024. Federated Learning for Anomaly Detection in Open RAN: Security Architecture Within a Digital Twin. InProceedings of the European Conference on Networks and Communications and 6G Summit (EuCNC/6G Summit). 1–6. https: //doi.org/10.1109/EuCNC/6GSummi...
work page doi:10.1109/eucnc/6gsummit60053.2024.10597083 2024
-
[24]
Aliaksandra Shysheya, John Bronskill, Massimiliano Patacchiola, Se- bastian Nowozin, and Richard E. Turner. 2023. FiT: Parameter-Efficient Few-Shot Transfer Learning for Personalized and Federated Image Classification. InProceedings of the International Conference on Learn- ing Representations
2023
-
[25]
Amardip Kumar Singh and Kim Khoa Nguyen. 2024. Communication Efficient Compressed and Accelerated Federated Learning in Open RAN Intelligent Controllers.IEEE/ACM Transactions on Networking 32, 4 (2024), 3361–3376. https://doi.org/10.1109/TNET.2024.3384839
-
[26]
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. 2024. Improving LoRA in Privacy-preserving Federated Learning. InProc. ICLR
2024
-
[27]
Yu Tian, Ahmed Alhammadi, Abdullah Quran, and Abubakar Sani Ali. 2024. A Novel Approach to WaveNet Architecture for RF Sig- nal Separation with Learnable Dilation and Data Augmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW). IEEE, 79–80. https: //doi.org/10.1109/ICASSPW62465.202...
-
[28]
Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. WaveNet: A Generative Model for Raw Audio.arXiv preprint arXiv:1609.03499(2016)
work page internal anchor Pith review arXiv 2016
-
[29]
Shuo Wang, Tianxin Wang, and Xudong Wang. 2025. FedPDA: Col- laborative Learning for Reducing Online-Adaptation Frequency of Neural Receivers. InProceedings of the IEEE International Conference on Computer Communications (INFOCOM). 1–10. https://doi.org/10. 1109/INFOCOM55648.2025.11044747
-
[30]
Han Zhang, Hao Zhou, and Melike Erol-Kantarci. 2022. Federated Deep Reinforcement Learning for Resource Allocation in O-RAN Slicing. In2022 IEEE Global Communications Conference (GLOBECOM). IEEE, 958–963. https://doi.org/10.1109/GLOBECOM48099.2022.10001658
-
[31]
Zhongyuan Zhao, Chenyuan Feng, Wei Hong, Jiamo Jiang, Chao Jia, Tony Q. S. Quek, and Mugen Peng. 2022. Federated Learning With Non-IID Data in Wireless Networks.IEEE Transactions on Wireless Communications21, 3 (2022), 1927–1940. https://doi.org/10.1109/TWC. 2021.3108197
work page doi:10.1109/twc 2022
-
[32]
Zihan Zhong, Zhiqiang Tang, Tong He, Haoyang Fang, and Chun Yuan
-
[33]
Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model. InProc. ICLR. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.