Recognition: unknown
Knowledge Distillation for Lightweight Multimodal Sensing-Aided mmWave Beam Tracking
Pith reviewed 2026-05-10 07:33 UTC · model grok-4.3
The pith
Knowledge distillation produces a lightweight multimodal model for mmWave beam prediction that retains over 96% Top-5 accuracy with far fewer parameters and lower complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that knowledge distillation from a CNN-GRU teacher model to a compact student model enables accurate beam prediction and tracking from historical multimodal camera and radar observations, with the student achieving over 96% Top-5 accuracy while cutting computational complexity by more than 4 times and the number of parameters by over 27 times compared to the teacher.
What carries the argument
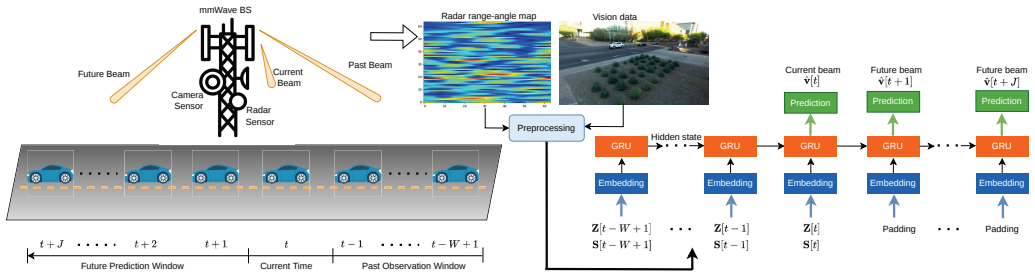
Knowledge distillation process transferring beam prediction capability from a teacher network of convolutional neural networks and gated recurrent units to a lightweight student network trained on historical multimodal sensor data.
If this is right
- Joint use of radar and image data yields higher beam prediction accuracy than either modality alone.
- The student model can support real-time beam tracking due to its reduced computational demands.
- Over 96% Top-5 accuracy provides reliable performance for beam management even when exact beam selection is not always required.
- The framework enables efficient deployment of sensing-aided beam tracking in resource-constrained mmWave systems.
Where Pith is reading between the lines
- This distillation approach could extend to other wireless tasks such as sensing-aided channel estimation or user localization.
- Lightweight models from this method may run directly on user devices, lowering latency compared to centralized processing.
- Combining the technique with additional model compression methods could produce even smaller networks for edge hardware.
Load-bearing premise
The distilled student model will maintain close performance to the teacher when faced with channel conditions and environments not represented in the training dataset.
What would settle it
Collecting new camera, radar, and beam data from a different location or mobility scenario and verifying whether the student model's Top-5 beam prediction accuracy remains above 96 percent.
Figures


read the original abstract
Beam training and prediction in real-world millimeter-wave (mmWave) communications systems are challenging due to rapidly time-varying channels and strong interference from surrounding objects. In this context, widely available sensors, such as cameras and radars, can capture rich environmental information, enabling efficient beam management. This paper proposes a knowledge-distillation (KD)-enabled learning framework for developing lightweight and low-complexity models for beam prediction and tracking using real-world camera and radar data from the DeepSense 6G dataset. Specifically, a powerful teacher network based on convolutional neural networks (CNNs) and gated recurrent units (GRUs) is first designed to predict current and future beams from historical sensor observations. Then, a compact student model is constructed and trained via KD to transfer the predictive capability of the teacher model to a lightweight architecture. Simulation results demonstrate that jointly leveraging radar and image modalities significantly outperforms single-modality approaches. Moreover, the proposed student model achieves over 96% Top-5 beam prediction accuracy while reducing computational complexity by more than 4 times and the number of parameters by over 27 times compared with the teacher model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a knowledge-distillation framework for lightweight mmWave beam prediction and tracking. A teacher model combining CNNs and GRUs is trained on multimodal (camera + radar) observations from the DeepSense 6G dataset to predict current and future beams; this capability is then transferred to a compact student network. The central empirical claims are that joint multimodal fusion outperforms single-modality baselines and that the distilled student reaches >96% Top-5 accuracy while cutting computational complexity by >4× and parameter count by >27× relative to the teacher.
Significance. If the reported accuracy and efficiency numbers prove robust, the work would offer a practical route to deploying sensor-aided beam management on resource-limited devices in mmWave/6G systems. The use of a public dataset, explicit multimodal comparison, and focus on both predictive performance and model size are positive features that address real deployment constraints.
major comments (4)
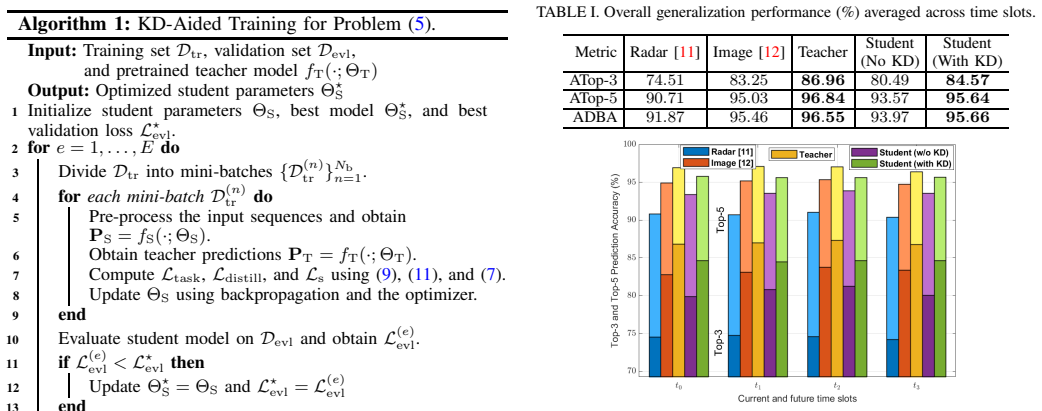
- [§4.2] §4.2 (Results): The 96% Top-5 accuracy figure for the student is stated without standard deviations, confidence intervals, or statistics from multiple independent runs with different random seeds. This directly affects the reliability of the claimed gains over the teacher and single-modality baselines.
- [§3.2] §3.2 (Knowledge Distillation): The precise distillation loss (including temperature, weighting between soft and hard targets, and any task-specific loss) and the full set of training hyperparameters are not provided. Because the student-teacher performance gap is the core empirical result, these details are load-bearing for reproducibility and for understanding why the accuracy remains high after compression.
- [§5] §5 (Experiments and Discussion): All quantitative results use the standard train/validation/test splits of DeepSense 6G. No out-of-distribution evaluation (different scenarios, altered mobility patterns, or sensor calibration drift) is reported, leaving the generalization premise for real-time channel variations untested despite the paper's positioning for practical beam tracking.
- [§4.1] §4.1 (Complexity Analysis): The claimed >4× complexity reduction and >27× parameter reduction are given as aggregate figures without an explicit definition of the complexity metric (FLOPs, MACs, or measured latency on target hardware) or per-layer breakdowns. This prevents independent verification of the efficiency claims.
minor comments (3)
- [Abstract] The abstract refers to 'simulation results' while the work uses real-world DeepSense 6G recordings; a brief clarification of terminology would avoid confusion.
- [Figures] Figure captions and legends could more explicitly state the modalities, beam indices, and evaluation metric (Top-5 accuracy) to improve immediate readability.
- [§2] A short paragraph contrasting the proposed KD approach with prior distillation or lightweight beam-prediction methods in the mmWave literature would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have carefully reviewed each major comment and provide point-by-point responses below. Revisions will be made to address the concerns on statistical reporting, reproducibility details, and complexity definitions. For the generalization comment, we will add discussion while noting scope limitations.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Results): The 96% Top-5 accuracy figure for the student is stated without standard deviations, confidence intervals, or statistics from multiple independent runs with different random seeds. This directly affects the reliability of the claimed gains over the teacher and single-modality baselines.
Authors: We agree that statistical measures from multiple runs are necessary to substantiate the reliability of the reported accuracy. In the revised manuscript, we will include the mean Top-5 accuracy along with standard deviations computed over multiple independent training runs using different random seeds. This will strengthen the empirical claims regarding performance gains. revision: yes
-
Referee: [§3.2] §3.2 (Knowledge Distillation): The precise distillation loss (including temperature, weighting between soft and hard targets, and any task-specific loss) and the full set of training hyperparameters are not provided. Because the student-teacher performance gap is the core empirical result, these details are load-bearing for reproducibility and for understanding why the accuracy remains high after compression.
Authors: We acknowledge the omission of these specifics in the original submission. In the revision, we will provide the exact distillation loss formulation, including the temperature parameter, the weighting coefficients between the soft-target and hard-target losses, and any task-specific loss terms. We will also include a complete table of training hyperparameters for both the teacher and student models to ensure full reproducibility. revision: yes
-
Referee: [§5] §5 (Experiments and Discussion): All quantitative results use the standard train/validation/test splits of DeepSense 6G. No out-of-distribution evaluation (different scenarios, altered mobility patterns, or sensor calibration drift) is reported, leaving the generalization premise for real-time channel variations untested despite the paper's positioning for practical beam tracking.
Authors: We recognize that the evaluation is confined to the dataset's standard splits and lacks explicit OOD testing. Our primary focus was demonstrating the KD framework's effectiveness on the available data. In the revised manuscript, we will expand the discussion to explicitly address generalization limitations and outline future work on OOD scenarios. However, new OOD experiments fall outside the scope of this revision. revision: partial
-
Referee: [§4.1] §4.1 (Complexity Analysis): The claimed >4× complexity reduction and >27× parameter reduction are given as aggregate figures without an explicit definition of the complexity metric (FLOPs, MACs, or measured latency on target hardware) or per-layer breakdowns. This prevents independent verification of the efficiency claims.
Authors: We agree that the complexity claims require clearer definitions and supporting details. In the revised manuscript, we will explicitly define the computational complexity metric as floating-point operations (FLOPs) and include per-layer breakdowns of both parameter counts and FLOPs for the teacher and student models to facilitate independent verification. revision: yes
Circularity Check
No circularity: empirical KD framework evaluated on held-out DeepSense 6G splits
full rationale
The paper presents a standard knowledge-distillation pipeline (teacher CNN+GRU trained on multimodal sensor data, then distilled to a compact student) and reports Top-5 accuracy plus complexity metrics on test portions of the public DeepSense 6G dataset. No equations, uniqueness theorems, or self-citations are invoked to derive the reported accuracy or parameter-reduction figures; those numbers are direct outputs of training and inference on held-out sequences. The derivation chain consists of architecture description, training procedure, and empirical comparison, all externally falsifiable against the same dataset splits without reducing to fitted constants defined inside the same experiment.
Axiom & Free-Parameter Ledger
free parameters (1)
- teacher and student network hyperparameters
axioms (2)
- domain assumption Sensor data (camera images and radar) are correlated with the optimal mmWave beam indices in the dataset.
- standard math Standard back-propagation and gradient descent converge to a useful teacher-student pair.
Reference graph
Works this paper leans on
-
[1]
The roa d towards 6G: A comprehensive survey,
W. Jiang, B. Han, M. A. Habibi, and H. D. Schotten, “The roa d towards 6G: A comprehensive survey,” vol. 2, pp. 334–366, 20 21
-
[2]
Environment sema ntic communication: Enabling distributed sensing aided networ ks,
S. Imran, G. Charan, and A. Alkhateeb, “Environment sema ntic communication: Enabling distributed sensing aided networ ks,” vol. 5, pp. 7767–7786, 2024
2024
-
[3]
P osition-aided beam prediction in the real world: How useful GPS locations a ctually are?
J. Morais, A. Bchboodi, H. Pezeshki, and A. Alkhateeb, “P osition-aided beam prediction in the real world: How useful GPS locations a ctually are?” in Proc. IEEE Int. Conf. Commun. , 2023
2023
-
[4]
Radar aided 6G beam predic tion: Deep learning algorithms and real-world demonstration,
U. Demirhan and A. Alkhateeb, “Radar aided 6G beam predic tion: Deep learning algorithms and real-world demonstration,” i n Proc. IEEE Wireless Commun. and Networking Conf. , 2022
2022
-
[5]
Lid ar aided wireless networks-beam prediction for 5G,
D. Marasinghe, N. Jayaweera, N. Rajatheva, S. Hakola, T. Koskela, O. Tervo, J. Karjalainen, E. Tiirola, and J. Hulkkonen, “Lid ar aided wireless networks-beam prediction for 5G,” in Proc. IEEE V eh. Technol. Conf., 2022
2022
-
[6]
Vision-position multi-modal beam prediction using real m illimeter wave datasets,
G. Charan, T. Osman, A. Hredzak, N. Thawdar, and A. Alkhat eeb, “Vision-position multi-modal beam prediction using real m illimeter wave datasets,” in Proc. IEEE Wireless Commun. and Networking Conf., 2022
2022
-
[7]
Sensing-assisted high reliable communication: A transfo rmer- based beamforming approach,
Y . Cui, J. Nie, X. Cao, T. Y u, J. Zou, J. Mu, and X. Jing, “Sensing-assisted high reliable communication: A transfo rmer- based beamforming approach,” IEEE J. Sel. Topics Signal Process. , vol. 18, no. 5, pp. 782–795, 2024
2024
-
[8]
Advancing mul ti- modal beam prediction with cross-modal feature enhancemen t and dynamic fusion mechanism,
Q. Zhu, Y . Wang, W. Li, H. Huang, and G. Gui, “Advancing mul ti- modal beam prediction with cross-modal feature enhancemen t and dynamic fusion mechanism,” IEEE Trans. Commun. , vol. 73, no. 9, pp. 7931–7940, 2025
2025
-
[9]
Y . M. Park, Y . K. Tun, W. Saad, and C. S. Hong, “Resource-ef ficient beam prediction in mmwave communications with multimodal r ealistic simulation framework,” arXiv preprint arXiv:2504.05187 , 2025
-
[10]
Lidar aided futu re beam prediction in real-world millimeter wave V2I communicatio ns,
S. Jiang, G. Charan, and A. Alkhateeb, “Lidar aided futu re beam prediction in real-world millimeter wave V2I communicatio ns,” IEEE Wireless Commun. Lett. , vol. 12, no. 2, pp. 212–216, 2023
2023
-
[11]
Millimeter wave V2V beam tracking using radar: Algorithms and real-world demonstra tion,
H. Luo, U. Demirhan, and A. Alkhateeb, “Millimeter wave V2V beam tracking using radar: Algorithms and real-world demonstra tion,” in Proc. European Sign. Proc. Conf. , 2023
2023
-
[12]
Attention-enhanced learning for sensing-assisted long- term beam tracking in mmWave communications,
M. Ma, N. T. Nguyen, N. Shlezinger, Y . C. Eldar, and M. Jun tti, “Attention-enhanced learning for sensing-assisted long- term beam tracking in mmWave communications,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Processing , 2026
2026
-
[13]
Knowledge distillation for sensing-assist ed long- term beam tracking in mmWave communications,
M. Ma, N. T. Nguyen, N. Shlezinger, Y . C. Eldar, A. L. Swin dlehurst, and M. Juntti, “Knowledge distillation for sensing-assist ed long- term beam tracking in mmWave communications,” arXiv preprint arXiv:2509.11419, 2025
-
[14]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applicati ons,” arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[15]
Attention is all you ne ed,
A. V aswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jone s, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you ne ed,” Advances in Neural Information Processing Systems , vol. 30, 2017
2017
-
[16]
Focal loss for dense object detection,
T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Doll´ ar, “ Focal loss for dense object detection,” in Proc. IEEE International Conf. on Computer Vision, 2017, pp. 2980–2988
2017
-
[17]
Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset ,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais , U. Demirhan, and N. Srinivas, “Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset ,” IEEE Commun. Mag. , vol. 61, no. 9, pp. 122–128, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.