FliX: Flipped-Indexing for Scalable GPU Queries and Updates
Pith reviewed 2026-05-10 06:33 UTC · model grok-4.3
The pith
FliX replaces index traversal with bucket-assigned warps and batch binary search to support dynamic ordered GPU data structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FliX is a comparison-based flipped indexing design in which compute units (warps) are bound to buckets in the data layer; each bucket then identifies the subset of a batched operation stream that it owns by performing a single binary search over the sorted batch. The design eliminates the separate index layer entirely, replaces repeated index traversals with per-bucket searches, simplifies update paths, and continues to support range queries, successor queries, and dynamic memory reclamation.
What carries the argument
Compute-to-bucket mapping together with per-bucket binary search over the operation batch, which substitutes for index-layer traversals.
If this is right
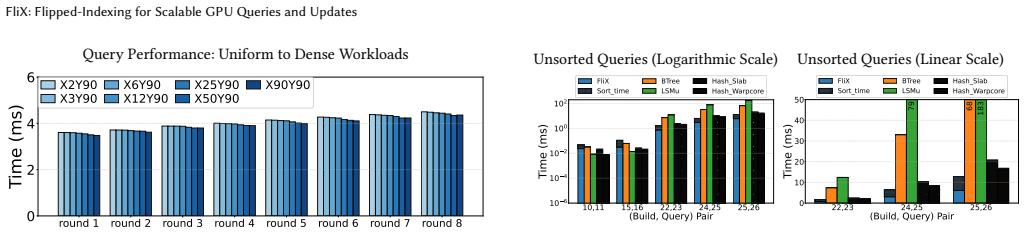
- Query latency falls by a factor of 6.5 relative to a leading GPU B-tree and 1.5 relative to a leading GPU LSM-tree.
- Throughput per unit of memory rises by a factor of four over other ordered GPU structures.
- Insertion throughput in update-heavy workloads exceeds the nearest fully dynamic ordered baseline by more than eight times.
- Query and deletion performance exceed that of state-of-the-art unordered GPU hash tables while still supporting ordering.
Where Pith is reading between the lines
- The same bucket-centric assignment pattern could be applied to other many-core or vector architectures that suffer from index-induced divergence.
- Bucket-level binary search may scale more gracefully than tree descent when the number of concurrent operations grows far beyond the number of buckets.
- The memory-footprint advantage could make FliX attractive for GPU-resident indexes inside larger query engines that already keep data on the device.
Load-bearing premise
That mapping warps directly to buckets and locating operations via batch binary search will avoid introducing new contention, warp divergence, or correctness problems while still allowing dynamic memory reclamation and full ordering.
What would settle it
A workload in which bucket binary searches produce measurably higher warp divergence or lower throughput than index traversals under the same update intensity and bucket occupancy.
Figures










read the original abstract
GPU-based concurrent data structures (CDSs) achieve high throughput for read-only queries, but efficient support for dynamic updates on fully GPU-resident data remains challenging. Ordered CDSs (e.g., B-trees and LSM-trees) maintain an index layer that directs operations to a data layer (buckets or leaves), while hash tables avoid the cost of maintaining order but do not support range or successor queries. On GPUs, maintaining and traversing an index layer under frequent updates introduces contention and warp divergence. To tackle these problems, we flip the indexing paradigm on its head with FliX, a comparison-based, flipped indexing strategy for dynamic, fully GPU-resident CDSs. Traditional GPU CDSs typically take a batch of operations and assign each operation to a GPU thread or warp. FliX, however, assigns compute (e.g., a warp) to each bucket in the data layer, and each bucket then locates operations it is responsible for in the batch. FliX can replace many index layer traversals with a single binary search on the batch, reducing redundant work and warp divergence. Further, FliX simplifies updates as no index layer must be maintained. In our experiments, FliX achieves 6.5x reduced query latency compared to a leading GPU B-tree and 1.5x compared to a leading GPU LSM-tree, while delivering 4x higher throughput per memory footprint than ordered competitors. Despite maintaining order, FliX also surpasses state-of-the-art unordered GPU hash tables in query and deletion performance, and is highly competitive in insertion performance. In update-heavy workloads, it outperforms the closest fully dynamic ordered baseline by over 8x in insertion throughput while supporting dynamic memory reclamation. These results suggest that eliminating the index layer and adopting a compute-to-bucket mapping can enable practical, fully dynamic GPU indexing without sacrificing query performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FliX, a flipped-indexing strategy for fully GPU-resident concurrent data structures. Traditional designs assign operations to threads/warps and traverse an index layer to reach data buckets; FliX instead assigns warps to buckets in the data layer, which locate their responsible operations via a single binary search over a sorted batch. This eliminates index-layer maintenance and traversals, reducing contention and warp divergence while preserving full ordering, range/successor queries, dynamic updates, and memory reclamation. Experiments report 6.5× lower query latency than a leading GPU B-tree, 1.5× than a leading GPU LSM-tree, 4× higher throughput per memory footprint than ordered competitors, and >8× insertion throughput versus the closest dynamic ordered baseline in update-heavy workloads.
Significance. If the performance and correctness claims are substantiated, FliX offers a meaningful shift in GPU CDS design by showing that a compute-to-bucket mapping can deliver both high query performance and practical dynamic updates without an index layer. This addresses a long-standing tension between ordering and GPU efficiency and could influence future GPU database kernels and concurrent structures.
major comments (2)
- [Abstract] Abstract and experimental claims: concrete speedups (6.5× query latency vs. GPU B-tree, 1.5× vs. LSM-tree, 4× throughput-per-footprint, >8× insertion throughput) are stated without any description of hardware, baseline implementations, workload definitions, number of runs, error bars, or statistical tests. This directly undermines evaluation of the central performance claims.
- [§3] §3 (FliX design) and dynamic operations: the core assumption that warp-to-bucket assignment plus per-bucket binary search on the operation batch avoids new contention, divergence, or synchronization costs during bucket splits and memory reclamation is load-bearing. If bucket occupancies become imbalanced or boundary updates require per-operation atomics, the reported latency and throughput advantages would not hold; no microbenchmarks or divergence analysis of these paths are provided.
minor comments (2)
- [§4] Ensure every baseline (e.g., the specific 'leading GPU B-tree' and 'leading GPU LSM-tree') is named with citation and version in the experimental section so readers can reproduce the comparisons.
- [§3] Clarify how the sorted operation batch is produced and whether its construction cost is included in the reported latencies and throughputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, acknowledging where revisions are needed to strengthen the presentation of results and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental claims: concrete speedups (6.5× query latency vs. GPU B-tree, 1.5× vs. LSM-tree, 4× throughput-per-footprint, >8× insertion throughput) are stated without any description of hardware, baseline implementations, workload definitions, number of runs, error bars, or statistical tests. This directly undermines evaluation of the central performance claims.
Authors: We agree that the abstract would be improved by providing readers with immediate context for the reported speedups. The full details—including NVIDIA A100 GPU hardware, baseline implementations drawn from the cited GPU B-tree and LSM-tree papers, YCSB and custom range/update workloads, 10 runs with mean and standard deviation, and absence of statistical hypothesis tests—are presented in Section 5. We will revise the abstract to add a concise qualifier (e.g., “on NVIDIA A100 GPUs using standard benchmarks”) and an explicit pointer to the evaluation section. This change preserves abstract brevity while directly addressing the concern. revision: partial
-
Referee: [§3] §3 (FliX design) and dynamic operations: the core assumption that warp-to-bucket assignment plus per-bucket binary search on the operation batch avoids new contention, divergence, or synchronization costs during bucket splits and memory reclamation is load-bearing. If bucket occupancies become imbalanced or boundary updates require per-operation atomics, the reported latency and throughput advantages would not hold; no microbenchmarks or divergence analysis of these paths are provided.
Authors: The referee correctly notes that the claimed advantages depend on dynamic paths not introducing hidden costs. Section 3 explains that splits trigger warp reassignment to newly created buckets followed by a single batch binary search, and reclamation uses deferred batch-level synchronization rather than per-operation atomics. We acknowledge the absence of dedicated microbenchmarks or divergence profiles for these paths. We will add a short analysis subsection (3.4) containing warp-divergence measurements (via Nsight Compute) and atomic-operation counts for split and reclamation under both balanced and deliberately imbalanced bucket occupancies. This will substantiate that the design remains efficient in these cases. revision: yes
Circularity Check
No circularity detected in algorithmic design or experimental evaluation
full rationale
The paper describes a new GPU data structure design (flipped indexing with warp-to-bucket assignment and per-bucket binary search on operation batches) and reports empirical performance results against baselines. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central claims rest on experimental measurements of latency and throughput rather than any derivation that reduces to its own premises by construction. This is a standard empirical algorithms paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alcantara, Andrei Sharf, Fatemeh Abbasinejad, Shubhabrata Sengupta, Michael Mitzenmacher, John D
Dan A. Alcantara, Andrei Sharf, Fatemeh Abbasinejad, Shubhabrata Sengupta, Michael Mitzenmacher, John D. Owens, and Nina Amenta. 2009. Real-time parallel hashing on the GPU.ACM Trans. Graph.28, 5 (2009), 154. https: //doi.org/10.1145/1618452.1618500
-
[2]
Saman Ashkiani, Martin Farach-Colton, and John D. Owens. 2018. A Dynamic Hash Table for the GPU. In2018 IEEE International Parallel and Distributed Processing Symposium, IPDPS 2018, Vancouver, BC, Canada, May 21-25, 2018. IEEE Computer Society, Vancouver, BC, Canada, 419–429. https://doi.org/10.1109/ IPDPS.2018.00052
-
[3]
Saman Ashkiani, Shengren Li, Martin Farach-Colton, Nina Amenta, and John D. Owens. 2018. GPU LSM: A Dynamic Dictionary Data Structure for the GPU. In 12 FliX: Flipped-Indexing for Scalable GPU Queries and Updates 2018 IEEE International Parallel and Distributed Processing Symposium, IPDPS 2018, Vancouver, BC, Canada, May 21-25, 2018. IEEE Computer Society...
-
[4]
2022.Fully Concurrent GPU Data Structures
Muhammad Abdelghaffar Awad. 2022.Fully Concurrent GPU Data Structures. Ph.D. Dissertation. University of California, Davis
work page 2022
-
[5]
Muhammad A. Awad, Saman Ashkiani, Rob Johnson, Martín Farach-Colton, and John D. Owens. 2019. Engineering a high-performance GPU B-Tree. InProceed- ings of the 24th Symposium on Principles and Practice of Parallel Programming (Washington, District of Columbia)(PPoPP ’19). Association for Computing Ma- chinery, New York, NY, USA, 145–157. https://doi.org/1...
-
[6]
Jiashen Cao, Rathijit Sen, Matteo Interlandi, Joy Arulraj, and Hyesoon Kim. 2023. Gpu database systems characterization and optimization.Proceedings of the VLDB Endowment17, 3 (2023), 441–454. https://doi.org/10.14778/3632093.3632107
-
[7]
Mark Harris and Kyrylo Perelygin. 2017. Cooperative Groups: Flexible CUDA Thread Programming. (2017). https://developer.nvidia.com/blog/cooperative- groups/
work page 2017
-
[8]
Justus Henneberg and Felix Schuhknecht. 2023. RTIndeX: Exploiting Hardware- Accelerated GPU Raytracing for Database Indexing.Proc. VLDB Endow.16, 13 (2023), 4268–4281. https://www.vldb.org/pvldb/vol16/p4268-schuhknecht.pdf
work page 2023
-
[9]
Justus Henneberg, Felix Schuhknecht, Rosina Kharal, and Trevor Brown. 2025. More Bang for Your Buck(et): Fast and Space-Efficient Hardware-Accelerated Coarse-Granular Indexing on GPUs. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, Hong Kong, China, 1320–1333. https://doi. org/10.1109/ICDE65448.2025.00103
-
[10]
Daniel Jünger, Robin Kobus, André Müller, Christian Hundt, Kai Xu, Weiguo Liu, and Bertil Schmidt. 2020. WarpCore: A Library for fast Hash Tables on GPUs. In 27th IEEE International Conference on High Performance Computing, Data, and Analytics, HiPC 2020, Pune, India, December 16-19, 2020. IEEE, Pune, India, 11–20. https://doi.org/10.1109/HIPC50609.2020.00015
-
[11]
Brenton Lessley, Shaomeng Li, and Hank Childs. 2020. HashFight: A Platform- Portable Hash Table for Multi-Core and Many-Core Architectures.Electronic Imaging32, 1 (2020), 376–1–376–13. https://doi.org/10.2352/ISSN.2470-1173. 2020.1.VDA-376
-
[12]
Hao Li, Yi-Cheng Tu, and Bo Zeng. 2019. Concurrent query processing in a GPU-based database system.PloS one14, 4 (2019), e0214720
work page 2019
-
[13]
Chunbin Lin, Benjamin Mandel, Yannis Papakonstantinou, and Matthias Springer
-
[14]
Fast In-Memory SQL Analytics on Typed Graphs.Proceedings of the VLDB Endowment10, 3 (2016), 265–276. https://doi.org/10.14778/3021924.3021941
-
[15]
Sparsh Mittal and Jeffrey S. Vetter. 2015. A Survey of CPU-GPU Heterogeneous Computing Management: GPU Architectures, Data Management and Scheduling Strategies.ACM Computing Surveys (CSUR)47, 4 (2015), 1–38. https://doi.org/ 10.1145/2788396
-
[16]
Nurit Moscovici, Nachshon Cohen, and Erez Petrank. 2017. A gpu-friendly skiplist algorithm. In2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT). IEEE, Portland, OR, USA, 246–259. https: //doi.org/10.1109/PACT.2017.13
-
[17]
Johns Paul, Shengliang Lu, and Bingsheng He. 2021. Database systems on GPUs. Foundations and Trends in Databases11, 1 (2021), 1–108. https://doi.org/10.1561/ 1900000076
work page 2021
-
[18]
Amirhesam Shahvarani and Hans-Arno Jacobsen. 2016. A hybrid B+-tree as solution for in-memory indexing on CPU-GPU heterogeneous computing plat- forms. InProceedings of the 2016 International Conference on Management of Data (SIGMOD ’16). Association for Computing Machinery, New York, NY, USA, 1523–1538
work page 2016
-
[19]
Anil Shanbhag, Samuel Madden, and Xiangyao Yu. 2020. A study of the funda- mental performance characteristics of GPUs and CPUs for database analytics. In Proceedings of the 2020 ACM SIGMOD international conference on Management of data. Association for Computing Machinery, New York, NY, USA, 1617–1632. https://doi.org/10.1145/3318464.3380595
- [20]
-
[21]
Peng Wang, Guangyu Sun, Song Jiang, Jian Ouyang, Shiding Lin, Chen Zhang, and Jason Cong. 2014. An Efficient Design and Implementation of LSM-tree Based Key-Value Store on Open-Channel SSD. InProceedings of the Ninth European Conference on Computer Systems. Association for Computing Machinery, New York, NY, USA, Article 16, 14 pages. https://doi.org/10.11...
-
[22]
2025.Fast Database Join on Ray-tracing Core Equipped GPU
Yijie Wu. 2025.Fast Database Join on Ray-tracing Core Equipped GPU. Ph.D. Dissertation. University of Victoria
work page 2025
-
[23]
Kai Zhang, Kaibo Wang, Yuan Yuan, Lei Guo, Rubao Lee, and Xiaodong Zhang
-
[24]
VLDB Endow.8, 11 (2015), 1226–1237
Mega-KV: A Case for GPUs to Maximize the Throughput of In-Memory Key-Value Stores.Proc. VLDB Endow.8, 11 (2015), 1226–1237. https://doi.org/10. 14778/2809974.2809984 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.