Recognition: unknown
Symphony: Taming Step Misalignments in the Network for Ring-based Collective Operations
Pith reviewed 2026-05-10 06:58 UTC · model grok-4.3
The pith
Symphony mitigates step misalignments in ring-based collectives by tracking per-job pipeline progress in the network and using congestion signals to selectively throttle faster flows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
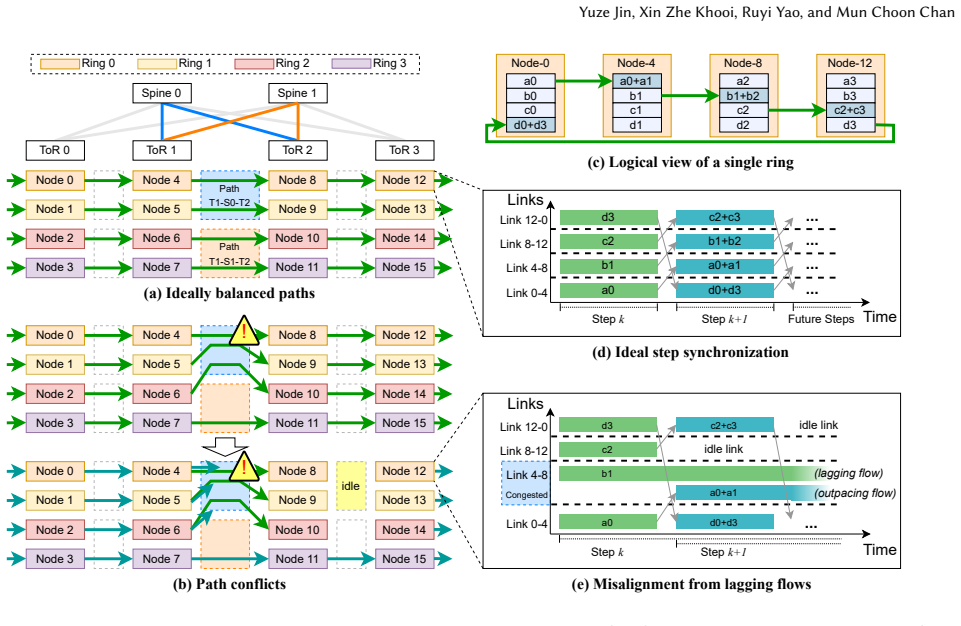
Symphony is an in-network solution that detects pipeline step misalignment in ring collectives and mitigates its impact through a lightweight per-job progress tracker and novel use of congestion signals to selectively throttle outpacing flows, allowing lagging flows to catch up without global coordination.
What carries the argument
Lightweight per-job pipeline progress tracker paired with selective throttling of outpacing flows via congestion signals.
If this is right
- Collective communication time in ring-based operations decreases by up to 54 percent when network jitter and congestion are present.
- Ring collectives maintain better step synchronization without application changes or global coordination.
- The mechanism reuses existing congestion signals, allowing compatibility with current network hardware.
- Implementation on programmable switches is feasible, as demonstrated by a working prototype.
Where Pith is reading between the lines
- The selective throttling idea could apply to other step-synchronized communication patterns beyond rings.
- Lowering misalignment might reduce latency variance across large distributed training jobs.
- Similar in-network controls could address related performance variability in data-center networks.
- Combining the tracker with application-level scheduling might further improve end-to-end training throughput.
Load-bearing premise
A lightweight per-job progress tracker can be maintained accurately at line rate and selective throttling via existing congestion signals will let lagging flows catch up without creating new bottlenecks.
What would settle it
A measurement showing that the progress tracker cannot operate accurately at line rate or that selective throttling increases overall collective completion time instead of reducing it.
Figures







read the original abstract
Ring-based collective operations are widely used in distributed AI training due to their efficient bandwidth utilization. While ring communication excels at pipelining, its performance is heavily dependent on having synchronized step-wise progression. This presents a mismatch to the underlying network conditions in practice: collective operations are vulnerable to network jitter and congestion, leading to step misalignment and increased collective completion time. To that end, we propose Symphony, an in-network solution that detects pipeline step misalignment and mitigates its impact. Symphony introduces (1) a lightweight mechanism to track per-job pipeline progress and (2) a novel use of congestion signals to selectively throttle outpacing flows, allowing lagging flows to catch up without global coordination. Through simulations using Astra-Sim, we show that Symphony effectively mitigates step misalignments in ring-based collectives, resulting in up to 54% improvement in job/collective communication time. Finally, we prototype and validate Symphony on an Intel Tofino2 programmable switch to demonstrate its practicality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Symphony, an in-network mechanism to detect and mitigate step misalignments in ring-based collective operations (e.g., for distributed AI training) caused by network jitter and congestion. It introduces a lightweight per-job pipeline progress tracker and selective throttling of outpacing flows via existing congestion signals to let lagging participants catch up without global coordination. Simulations in Astra-Sim report up to 54% reduction in job/collective communication time, with a basic feasibility prototype implemented on an Intel Tofino2 programmable switch.
Significance. If the reported gains prove robust, Symphony offers a practical, deployable improvement to collective communication performance in AI training clusters by addressing a real mismatch between ring pipelining assumptions and network conditions. The in-network design avoids host or collective modifications, and the Tofino2 prototype provides concrete evidence of implementability on modern programmable hardware, which strengthens the work's engineering contribution.
major comments (3)
- [§5] §5 (Evaluation), simulation results paragraph: The claim of 'up to 54% improvement in job/collective communication time' is presented without any description of the baselines (e.g., unmodified ring collectives or alternative mitigation schemes), the distribution of network jitter/congestion parameters tested, the number of simulation runs, or measures of variability/statistical significance. This makes it impossible to assess whether the gains are load-bearing or sensitive to modeling assumptions.
- [§3.2] §3.2 (Selective Throttling Mechanism): The argument that congestion-signal-based throttling of faster flows will reliably allow lagging ring participants to catch up without inducing secondary bottlenecks, fairness violations, or oscillations rests on unverified assumptions about per-job tracker accuracy at line rate and switch behavior under concurrent jobs. The Tofino2 prototype only validates basic feasibility and does not measure end-to-end collective completion time or these dynamics.
- [§4] §4 (Prototype Implementation): While the Tofino2 prototype demonstrates that the tracker and throttling logic can be realized in P4, it provides no quantitative data on state overhead, lookup latency, or interaction with existing congestion control under realistic multi-job workloads, leaving the 'lightweight' and 'line-rate' claims unquantified.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicitly naming the ring-based collectives evaluated (e.g., AllReduce, AllGather) and the range of job sizes or ring lengths tested.
- [§3] Notation for the per-job progress tracker (e.g., variables for step counters and congestion thresholds) should be introduced with a small table or diagram in §3 for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where we will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation), simulation results paragraph: The claim of 'up to 54% improvement in job/collective communication time' is presented without any description of the baselines (e.g., unmodified ring collectives or alternative mitigation schemes), the distribution of network jitter/congestion parameters tested, the number of simulation runs, or measures of variability/statistical significance. This makes it impossible to assess whether the gains are load-bearing or sensitive to modeling assumptions.
Authors: We agree that the evaluation section requires additional detail to substantiate the reported gains. In the revised manuscript, we will expand §5 to describe the baselines (unmodified ring collectives without Symphony and any alternative schemes considered), the specific distributions and ranges of network jitter and congestion parameters used in Astra-Sim, the number of independent simulation runs per configuration, and statistical measures including means, standard deviations, and confidence intervals. revision: yes
-
Referee: [§3.2] §3.2 (Selective Throttling Mechanism): The argument that congestion-signal-based throttling of faster flows will reliably allow lagging ring participants to catch up without inducing secondary bottlenecks, fairness violations, or oscillations rests on unverified assumptions about per-job tracker accuracy at line rate and switch behavior under concurrent jobs. The Tofino2 prototype only validates basic feasibility and does not measure end-to-end collective completion time or these dynamics.
Authors: The Astra-Sim simulations demonstrate that selective throttling mitigates misalignments without inducing the noted secondary effects across the evaluated scenarios. We will revise §3.2 to provide a more explicit discussion of the underlying assumptions, supported by simulation evidence on tracker accuracy and dynamics. We will also clarify that the Tofino2 prototype serves to validate implementability at line rate while end-to-end performance and multi-job behavior are evaluated via simulation, and note concurrent-job interactions as an area for future quantification. revision: partial
-
Referee: [§4] §4 (Prototype Implementation): While the Tofino2 prototype demonstrates that the tracker and throttling logic can be realized in P4, it provides no quantitative data on state overhead, lookup latency, or interaction with existing congestion control under realistic multi-job workloads, leaving the 'lightweight' and 'line-rate' claims unquantified.
Authors: We agree that quantitative metrics would strengthen the prototype claims. In the revised §4, we will add data from the Tofino2 implementation, including state overhead (e.g., table entries and memory usage per job), measured lookup and processing latencies, and observations on interactions with standard congestion control under multi-job workloads where tested. revision: yes
Circularity Check
No circularity: performance claims are empirical simulation results, not derived from self-referential equations or fits
full rationale
The paper is a systems design work proposing Symphony's per-job progress tracker and congestion-signal throttling for ring collectives. Its central claim (up to 54% improvement) is demonstrated via Astra-Sim simulations and Tofino2 prototype validation rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The evaluation is independent and falsifiable through external simulation runs, satisfying the criteria for a non-circular empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Grattafiori Aaron, Dubey Abhimanyu, Jauhri Abhinav, Pandey Ab- hinav, Kadian Abhishek, Al-Dahle Ahmad, Letman Aiesha, Mathur Akhil, Schelten Alan, et al . 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Saksham Agarwal, Shijin Rajakrishnan, Akshay Narayan, Rachit Agar- wal, David Shmoys, and Amin Vahdat. 2018. Sincronia: near-optimal network design for coflows. InACM SIGCOMM
2018
-
[3]
Albert Gran Alcoz, Alexander Dietmüller, and Laurent Vanbever. 2020. SP-PIFO: Approximating Push-In First-Out Behaviors using Strict- Priority Queues. InUSENIX NSDI
2020
-
[4]
Mohammad Alizadeh, Tom Edsall, Sarang Dharmapurikar, Ramanan Vaidyanathan, Kevin Chu, Andy Fingerhut, Vinh The Lam, Francis Ma- tus, Rong Pan, Navindra Yadav, and George Varghese. 2014. CONGA: distributed congestion-aware load balancing for datacenters. InACM SIGCOMM. doi:10.1145/2619239.2626316
-
[5]
Mohammad Alizadeh, Shuang Yang, Milad Sharif, Sachin Katti, Nick McKeown, Balaji Prabhakar, and Scott Shenker. 2013. pFabric: minimal near-optimal datacenter transport. InACM SIGCOMM
2013
-
[6]
Sanjith Athlur, Nitika Saran, Muthian Sivathanu, Ramachandran Ram- jee, and Nipun Kwatra. 2022. Varuna: scalable, low-cost training of massive deep learning models. InACM EuroSys. doi:10.1145/3492321. 3519584
-
[7]
Wei Bai, Kai Chen, Li Chen, Changhoon Kim, and Haitao Wu. 2016. Enabling ECN over Generic Packet Scheduling. InACM CoNEXT
2016
-
[8]
Wei Bai, Li Chen, Kai Chen, and Haitao Wu. 2016. Enabling ECN in multi-service multi-queue data centers. InUSENIX NSDI
2016
-
[9]
Baidu Research. 2017. Baidu AllReduce: A Lightweight Library for Distributed Deep Learning. https://github.com/baidu-research/baidu- allreduce
2017
-
[10]
Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, and David Walker. 2014. P4: programming protocol- independent packet processors.SIGCOMM Comput. Commun. Rev.44, 3 (July 2014), 87–95. doi:10.1145/2656877.2656890
-
[11]
Pat Bosshart, Glen Gibb, Hun-Seok Kim, George Varghese, Nick McK- eown, Martin Izzard, Fernando Mujica, and Mark Horowitz. 2013. For- warding metamorphosis: fast programmable match-action processing in hardware for SDN. InACM SIGCOMM. doi:10.1145/2486001.2486011
-
[12]
Jiamin Cao, Yu Guan, Kun Qian, Jiaqi Gao, Wencong Xiao, Jianbo Dong, Binzhang Fu, Dennis Cai, and Ennan Zhai. 2024. Crux: GPU- Efficient Communication Scheduling for Deep Learning Training. In ACM SIGCOMM. doi:10.1145/3651890.3672239
-
[13]
Houssine Chetto and Maryline Chetto. 1989. Some Results of the Earliest Deadline Scheduling Algorithm.IEEE Trans. Softw. Eng.15, 10 (Oct. 1989), 1261–1269. doi:10.1109/TSE.1989.559777
-
[14]
Mosharaf Chowdhury and Ion Stoica. 2015. Efficient Coflow Schedul- ing Without Prior Knowledge. InACM SIGCOMM
2015
-
[15]
Mosharaf Chowdhury, Yuan Zhong, and Ion Stoica. 2014. Efficient coflow scheduling with Varys. InACM SIGCOMM
2014
-
[16]
Ultra Ethernet Consortium. 2025. Ultra Ethernet Specification v1.0 (UEC Specification 6.11.25). Specification: https://ultraethernet.org/ wp-content/uploads/sites/20/2025/06/UE-Specification-6.11.25.pdf
2025
-
[17]
Demers, S
A. Demers, S. Keshav, and S. Shenker. 1989. Analysis and simulation of a fair queueing algorithm. InACM SIGCOMM
1989
-
[18]
Yangtao Deng, Lei Zhang, Qinlong Wang, Xiaoyun Zhi, Xinlei Zhang, Zhuo Jiang, Haohan Xu, Lei Wang, Zuquan Song, Gaohong Liu, Yang Bai, Shuguang Wang, Wencong Xiao, Jianxi Ye, Minlan Yu, and Hong Xu. 2025. Mycroft: Tracing Dependencies in Collec- tive Communication Towards Reliable LLM Training. InACM SOSP. doi:10.1145/3731569.3764848
-
[19]
Sally Floyd and Van Jacobson. 1993. Random early detection gateways for congestion avoidance.IEEE/ACM Trans. Netw.1, 4 (Aug. 1993), 397–413. doi:10.1109/90.251892
-
[20]
Sally Floyd, Dr. K. K. Ramakrishnan, and David L. Black. 2001. The Addition of Explicit Congestion Notification (ECN) to IP. RFC 3168. doi:10.17487/RFC3168
-
[21]
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. 2024. RDMA over Ethernet for Distributed Training at Meta Scale. InACM SIGCOMM. doi:10.1145/3651890.3672233
-
[22]
Soudeh Ghorbani, Zibin Yang, P. Brighten Godfrey, Yashar Ganjali, and Amin Firoozshahian. 2017. DRILL: Micro Load Balancing for Low-latency Data Center Networks. InACM SIGCOMM. doi:10.1145/ 3098822.3098839
-
[23]
Andrew Gibiansky. 2017. Bringing HPC Techniques to Deep Learn- ing (ring allreduce). https://andrew.gibiansky.com/blog/machine- learning/baidu-allreduce/
2017
-
[24]
Vin, and Haichen Chen
Pawan Goyal, Harrick M. Vin, and Haichen Chen. 1996. Start-time fair queueing: a scheduling algorithm for integrated services packet switching networks. InACM SIGCOMM
1996
-
[25]
Greg Dorai. 2025. Cisco: The New Family of Cisco Smart Switches: Built to Power What’s Next. https://www.cisco.com/site/us/en/ products/networking/silicon-one/index.html. 13 Yuze Jin, Xin Zhe Khooi, Ruyi Yao, and Mun Choon Chan
2025
-
[26]
Grosvenor, Malte Schwarzkopf, Ionel Gog, Robert N
Matthew P. Grosvenor, Malte Schwarzkopf, Ionel Gog, Robert N. M. Watson, Andrew W. Moore, Steven Hand, and Jon Crowcroft. 2015. Queues Don’t Matter When You Can JUMP Them!. InUSENIX NSDI
2015
-
[27]
Chuanxiong Guo, Haitao Wu, Zhong Deng, Gaurav Soni, Jianxi Ye, Jitu Padhye, and Marina Lipshteyn. 2016. RDMA over Commodity Ethernet at Scale. InACM SIGCOMM. doi:10.1145/2934872.2934908
-
[28]
Aaron Harlap, Henggang Cui, Wei Dai, Jinliang Wei, Gregory R. Ganger, Phillip B. Gibbons, Garth A. Gibson, and Eric P. Xing. 2016. Addressing the straggler problem for iterative convergent parallel ML. InACM SoCC. doi:10.1145/2987550.2987554
-
[29]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep Residual Learning for Image Recognition. arXiv:1512.03385 [cs.CV] https://arxiv.org/abs/1512.03385
work page internal anchor Pith review arXiv 2015
-
[30]
Hoeiland-Joergensen, P
T. Hoeiland-Joergensen, P. McKenney, D. Taht, J. Gettys, and E. Du- mazet. 2018. RFC 8290: The Flow Queue CoDel Packet Scheduler and Active Queue Management Algorithm
2018
-
[31]
Zhiyi Hu, Siyuan Shen, Tommaso Bonato, Sylvain Jeaugey, Cedell Alexander, Eric Spada, James Dinan, Jeff Hammond, and Torsten Hoefler. 2025. Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms. arXiv:2507.04786 [cs.DC] https://arxiv.org/abs/2507.04786
-
[32]
Hanlin Huang, Ke Xu, Tong Li, Zhuotao Liu, Xinle Du, and Xi- angyu Gao. 2025. DiffECN: Differential ECN Marking for Datacenter Networks.IEEE Transactions on Networking33, 1 (2025), 210–225. doi:10.1109/TNET.2024.3477511
-
[33]
Jiajun Huang, Sheng Di, Xiaodong Yu, Yujia Zhai, Jinyang Liu, Yafan Huang, Ken Raffenetti, Hui Zhou, Kai Zhao, Xiaoyi Lu, Zizhong Chen, Franck Cappello, Yanfei Guo, and Rajeev Thakur. 2024. gZCCL: Compression-Accelerated Collective Communication Framework for GPU Clusters. InACM ICS. doi:10.1145/3650200.3656636
-
[34]
Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. 2017. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. InACM HotOS. doi:10.1145/ 3102980.3103005
-
[35]
Intel Corporation. [n. d.]. Intel®Tofino™2. https://www.intel.com/ content/www/us/en/products/network-io/programmable-ethernet- switch/tofino-2-series.html
-
[36]
Charlie Hu, and Xiaojun Lin
Akshay Jajoo, Y. Charlie Hu, and Xiaojun Lin. 2019. Your Coflow has Many Flows: Sampling them for Fun and Speed. InUSENIX ATC
2019
-
[37]
Insu Jang, Zhenning Yang, Zhen Zhang, Xin Jin, and Mosharaf Chowd- hury. 2023. Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates. InACM SOSP. doi:10.1145/3600006.3613152
-
[38]
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin J...
2024
-
[39]
Raj Joshi, Cha Hwan Song, Xin Zhe Khooi, Nishant Budhdev, Ayush Mishra, Mun Choon Chan, and Ben Leong. 2023. Masking Corruption Packet Losses in Datacenter Networks with Link-local Retransmission. InACM SIGCOMM. doi:10.1145/3603269.3604853
-
[40]
Can Karakus, Yifan Sun, Suhas Diggavi, and Wotao Yin. 2017. Straggler mitigation in distributed optimization through data encoding. InNIPS. Curran Associates Inc
2017
-
[41]
Naga Katta, Mukesh Hira, Changhoon Kim, Anirudh Sivaraman, and Jennifer Rexford. 2016. HULA: Scalable Load Balancing Using Pro- grammable Data Planes. InACM Proceedings of the Symposium on SDN Research (SOSR ’16). doi:10.1145/2890955.2890968
-
[42]
Xin Zhe Khooi, Levente Csikor, Jialin Li, Min Suk Kang, and Dinil Mon Divakaran. 2021. Revisiting Heavy-Hitter Detection on Commodity Programmable Switches. In2021 IEEE 7th International Conference on Network Softwarization (NetSoft)
2021
-
[43]
ChonLam Lao, Yanfang Le, Kshiteej Mahajan, Yixi Chen, Wenfei Wu, Aditya Akella, and Michael Swift. 2021. ATP: In-network Aggregation for Multi-tenant Learning. InUSENIX NSDI
2021
-
[44]
Kangwook Lee, Maximilian Lam, Ramtin Pedarsani, Dimitris Papail- iopoulos, and Kannan Ramchandran. 2016. Speeding up distributed machine learning using codes. InIEEE International Symposium on Information Theory (ISIT)
2016
-
[45]
Wenxue Li, Xiangzhou Liu, Yunxuan Zhang, Zihao Wang, Wei Gu, Tao Qian, Gaoxiong Zeng, Shoushou Ren, Xinyang Huang, Zhenghang Ren, Bowen Liu, Junxue Zhang, Kai Chen, and Bingyang Liu. 2025. Revisiting RDMA Reliability for Lossy Fabrics. InACM SIGCOMM. doi:10.1145/3718958.3750480
-
[46]
Yuliang Li, Rui Miao, Hongqiang Harry Liu, Yan Zhuang, Fei Feng, Lingbo Tang, Zheng Cao, Ming Zhang, Frank Kelly, Mohammad Al- izadeh, and Minlan Yu. 2019. HPCC: high precision congestion control. InACM SIGCOMM. doi:10.1145/3341302.3342085
-
[47]
Xudong Liao, Yijun Sun, Han Tian, Xinchen Wan, Yilun Jin, Zilong Wang, Zhenghang Ren, Xinyang Huang, Wenxue Li, Kin Fai Tse, Zhizhen Zhong, Guyue Liu, Ying Zhang, Xiaofeng Ye, Yiming Zhang, and Kai Chen. 2025. MixNet: A Runtime Reconfigurable Optical- Electrical Fabric for Distributed Mixture-of-Experts Training. InACM SIGCOMM. doi:10.1145/3718958.3750465
-
[48]
Hwijoon Lim, Juncheol Ye, Sangeetha Abdu Jyothi, and Dongsu Han
-
[49]
Accelerating Model Training in Multi-cluster Environments with Consumer-grade GPUs. InACM SIGCOMM. doi:10.1145/3651890. 3672228
-
[50]
Shengkai Lin, Qinwei Yang, Zengyin Yang, Yuchuan Wang, and Shizhen Zhao. 2024. LubeRDMA: A Fail-safe Mechanism of RDMA. InACM APNET. doi:10.1145/3663408.3663411
-
[51]
linux-rdma contributors. 2024. rdma-core: RDMA Core Userspace Libraries and Daemons. https://github.com/linux-rdma/rdma-core
2024
-
[52]
Shuo Liu, Qiaoling Wang, Junyi Zhang, Wenfei Wu, Qinliang Lin, Yao Liu, Meng Xu, Marco Canini, Ray C. C. Cheung, and Jianfei He. 2023. In-Network Aggregation with Transport Transparency for Distributed Training. InACM ASPLOS. doi:10.1145/3582016.3582037
-
[53]
Tongrui Liu, Chenyang Hei, Fuliang Li, Chengxi Gao, Jiamin Cao, Tian- shu Wang, Ennan Zhai, and Xingwei Wang. 2025. ResCCL: Resource- Efficient Scheduling for Collective Communication. InACM SIGCOMM. doi:10.1145/3718958.3750514
-
[54]
Xuting Liu, Behnaz Arzani, Siva Kesava Reddy Kakarla, Liangyu Zhao, Vincent Liu, Miguel Castro, Srikanth Kandula, and Luke Marshall
-
[55]
Rethinking Machine Learning Collective Communication as a Multi-Commodity Flow Problem. InACM SIGCOMM. doi:10.1145/ 3651890.3672249
-
[56]
Zhangqiang Ming, Yuchong Hu, Xinjue Zheng, Wenxiang Zhou, and Dan Feng. 2025. SAFusion: Efficient Tensor Fusion with Sparsifica- tion Ahead for High-Performance Distributed DNN Training. InACM HPDC. New York, NY, USA. doi:10.1145/3731545.3731581
-
[57]
Radhika Mittal, Vinh The Lam, Nandita Dukkipati, Emily Blem, Hassan Wassel, Monia Ghobadi, Amin Vahdat, Yaogong Wang, David Wether- all, and David Zats. 2015. TIMELY: RTT-based Congestion Control for the Datacenter. InACM SIGCOMM. doi:10.1145/2785956.2787510
-
[58]
Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John Ouster- hout. 2018. Homa: a receiver-driven low-latency transport protocol using network priorities. InACM SIGCOMM. doi:10.1145/3230543. 3230564
-
[59]
Pipedream: generalized pipeline parallelism for dnn training,
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: generalized pipeline parallelism for DNN 14 Symphony training. InACM SOSP. doi:10.1145/3341301.3359646
-
[60]
Kathleen Nichols and Van Jacobson. 2012. Controlling queue delay. Commun. ACM55, 7 (July 2012), 42–50. doi:10.1145/2209249.2209264
-
[61]
nsnam. 2025. ns-3 Network Simulator. https://www.nsnam.org/
2025
-
[62]
Nvidia. 2022. Doubling all2all Performance with NVIDIA Col- lective Communication Library 2.12. https://developer.nvidia. com/blog/doubling-all2all-performance-with-nvidia-collective- communication-library-2-12/
2022
-
[63]
NVIDIA. 2025. NVIDIA Collective Communication Library (NCCL) Documentation. https://docs.nvidia.com/deeplearning/nccl/user- guide/docs/index.html
2025
- [64]
-
[65]
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai. 2024. Alibaba HPN: A Data Center Network for Large Language Model Training. InACM SIGCOMM. doi:10.1145/3651890.3672265
-
[66]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[67]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
ZeRO: Memory Optimizations Toward Training Trillion Parame- ter Models. arXiv:1910.02054 [cs.LG] https://arxiv.org/abs/1910.02054
-
[68]
Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna. 2020. ASTRA-SIM: Enabling SW/HW Co-Design Exploration for Distributed DL Training Platforms. InIEEE ISPASS
2020
-
[69]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. InACM SIGKDD. doi:10.1145/3394486.3406703
-
[70]
Todd Young, Sean Treichler, Vitalii Starchenko, Albina Borisevich, Alex Sergeev, and Michael Matheson
Joshua Romero, Junqi Yin, Nouamane Laanait, Bing Xie, M. Todd Young, Sean Treichler, Vitalii Starchenko, Albina Borisevich, Alex Sergeev, and Michael Matheson. 2022. Accelerating Collective Com- munication in Data Parallel Training across Deep Learning Frame- works. InUSENIX NSDI 22
2022
-
[71]
Amedeo Sapio, Marco Canini, Chen-Yu Ho, Jacob Nelson, Panos Kalnis, Changhoon Kim, Arvind Krishnamurthy, Masoud Moshref, Dan Ports, and Peter Richtarik. 2021. Scaling Distributed Machine Learning with In-Network Aggregation. InUSENIX NSDI
2021
-
[72]
Linus E Schrage and Louis W Miller. 1966. The Queue M/G/1 with the Shortest Remaining Processing Time Discipline.Operations Research 14, 4 (1966), 670–684
1966
-
[73]
Alexander Sergeev and Mike Del Balso. 2018. Horovod: fast and easy distributed deep learning in TensorFlow. arXiv:1802.05799 [cs.LG] https://arxiv.org/abs/1802.05799
work page Pith review arXiv 2018
-
[74]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. TACCL: Guiding Collective Algorithm Synthesis using Communication Sketches. InUSENIX NSDI
2023
-
[75]
Sharma, Ming Liu, Kishore Atreya, and Arvind Krish- namurthy
Naveen Kr. Sharma, Ming Liu, Kishore Atreya, and Arvind Krish- namurthy. 2018. Approximating fair queueing on reconfigurable switches. InUSENIX NSDI
2018
-
[76]
M. Shreedhar and G. Varghese. 1996. Efficient fair queuing using deficit round-robin.IEEE/ACM Transactions on Networking4, 3 (1996), 375–385. doi:10.1109/90.502236
-
[77]
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, Deep Shah, Ashmitha Jeevaraj Shetty, Greg Steinbrecher, Yulun Wang, Bruce Wu, Xinfeng Xie, Jingyi Yang, Mingran Yang, Kenny Yu, Min- lan Yu, Cen Zhao, Wes Bland, Denis Boyda, Suman Gumudavelli, Prashanth Kannan, Cristian Lu...
-
[78]
Karen Simonyan and Andrew Zisserman. 2015. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs.CV] https://arxiv.org/abs/1409.1556
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[79]
Cha Hwan Song, Xin Zhe Khooi, Raj Joshi, Inho Choi, Jialin Li, and Mun Choon Chan. 2023. Network Load Balancing with In-network Re- ordering Support for RDMA. InACM SIGCOMM. doi:10.1145/3603269. 3604849
-
[80]
Dimakis, and Nikos Karam- patziakis
Rashish Tandon, Qi Lei, Alexandros G. Dimakis, and Nikos Karam- patziakis. 2017. Gradient coding: avoiding stragglers in distributed learning. InICML. JMLR.org
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.