E2AFS: Energy-Efficient Approximate Floating Point Square Rooter for Error Tolerant Computing
Pith reviewed 2026-05-10 06:59 UTC · model grok-4.3
The pith
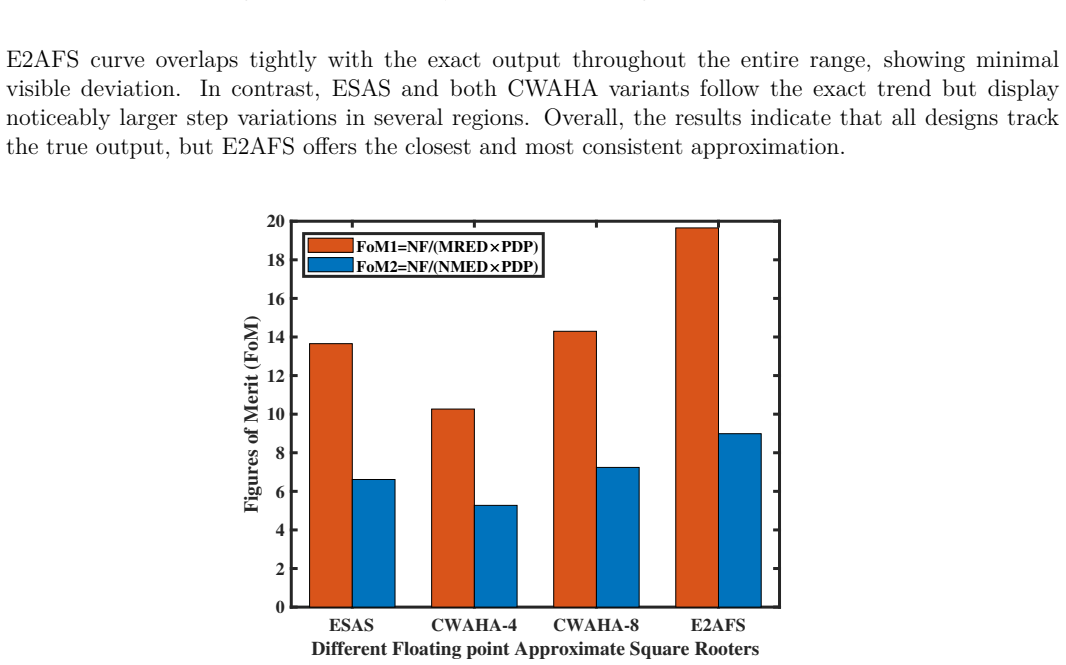
E2AFS introduces a multiplier-free approximate floating-point square-root architecture that achieves lower dynamic power, shorter delay, and better power-delay product than prior designs while keeping errors acceptable for error-tolerantuse
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
E2AFS is a fully multiplier-free floating-point square-root architecture that minimizes logic depth and switching activity. FPGA implementation on Artix-7 demonstrates the lowest dynamic power of 7.63 mW, shortest critical-path delay of 4.639 ns, and minimum power-delay product of 35.39 pJ versus existing ESAS and CWAHA designs. Error metrics and graphical analysis establish consistently low deviation from the exact function, and end-to-end validation in Sobel edge detection and K-means color quantization shows the approximation remains suitable for low-power real-time edge and embedded platforms.
What carries the argument
The E2AFS multiplier-free floating-point square-root architecture that reduces logic depth and switching activity to improve power and delay.
If this is right
- Records 7.63 mW dynamic power on Artix-7 FPGA
- Achieves 4.639 ns critical-path delay
- Delivers 35.39 pJ power-delay product
- Maintains low deviation from exact square-root function
- Supports low-power real-time operation in edge and embedded platforms
Where Pith is reading between the lines
- The multiplier-free approach may transfer to other floating-point operations under similar hardware constraints
- Lower power and delay could allow more complex computations within fixed energy budgets on battery-powered edge devices
- The error-tolerance validation suggests the unit could fit additional real-time signal-processing pipelines beyond the two tested applications
Load-bearing premise
The approximation errors stay small enough that they do not degrade end-to-end quality in the targeted error-tolerant applications such as Sobel edge detection and K-means quantization.
What would settle it
Power or delay measurements on an Artix-7 device exceeding 7.63 mW or 4.639 ns, or visible quality loss in Sobel edge detection and K-means outputs when using E2AFS versus exact square-root computation, would disprove the efficiency and suitability claims.
Figures




read the original abstract
Floating-point square-root computation is a power- and delay-critical operation in edge-AI, signal-processing, and embedded systems. Conventional implementations typically rely on multipliers or iterative pipelines, resulting in increased hardware complexity, switching activity, and energy consumption. This work presents E2AFS, a lightweight and fully multiplier-free floating-point square-root architecture optimized for energy-efficient computation. By reducing logic depth and minimizing switching activity, the proposed design achieves substantial improvements in hardware efficiency and performance. FPGA implementation on an Artix-7 device demonstrates that E2AFS achieves the lowest dynamic power (7.63 mW), the shortest critical-path delay (4.639 ns), and the minimum power-delay product (35.39 pJ) compared to existing ESAS and CWAHA architectures. Error evaluation using multiple accuracy metrics, together with graphical analysis, shows that E2AFS closely approximates the exact square-root function with consistently low deviation. Application-level validation in Sobel edge detection and K-means color quantization further confirms its suitability for low-power real-time edge and embedded platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes E2AFS, a lightweight multiplier-free approximate floating-point square-root architecture for energy-efficient computation in error-tolerant domains. It claims that FPGA synthesis on an Artix-7 device yields the lowest dynamic power (7.63 mW), shortest critical-path delay (4.639 ns), and minimum power-delay product (35.39 pJ) relative to the ESAS and CWAHA baselines, while maintaining low approximation error as shown by accuracy metrics, graphical analysis, and end-to-end tests on Sobel edge detection and K-means color quantization.
Significance. If the performance deltas hold under identical synthesis conditions, the design could offer a practical hardware primitive for low-power edge-AI and embedded signal-processing pipelines where square-root operations are frequent. The combination of multiplier elimination, reported PDP improvement, and application-level validation would strengthen the case for approximate arithmetic in resource-constrained platforms.
major comments (3)
- [FPGA Implementation Results] FPGA results section (abstract and implementation results): The central superiority claims for dynamic power, delay, and PDP rest on comparisons to ESAS and CWAHA, yet the manuscript provides no explicit statement that all three designs were re-implemented by the authors using identical Vivado synthesis settings, optimization directives, place-and-route constraints, clock frequency for power analysis, and input switching activity. These factors directly affect the reported 7.63 mW / 4.639 ns / 35.39 pJ figures; without this confirmation the deltas cannot be attributed solely to the E2AFS architecture.
- [Proposed Architecture / Error Evaluation] Proposed design and error evaluation sections: No design equations, algorithmic steps, or error formulas are supplied for the approximation method. The abstract asserts a “multiplier-free” property and “consistently low deviation,” but without the underlying mapping or error-bound derivation it is impossible to verify the claimed reduction in logic depth or to reproduce the accuracy metrics used for the Sobel and K-means tests.
- [Application-Level Validation] Application validation section: The claim that approximation error “does not meaningfully degrade” end-to-end quality in Sobel edge detection and K-means quantization is load-bearing for the error-tolerant suitability argument, yet the manuscript reports only qualitative confirmation without quantitative metrics (e.g., PSNR, clustering accuracy delta, or visual difference scores) comparing exact versus approximate outputs.
minor comments (1)
- [Abstract / Figures] Ensure that all figures referenced in the error and application sections are numbered and captioned consistently with the text; the abstract mentions “graphical analysis” without a corresponding figure citation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and rigor of our manuscript. We address each major comment point by point below and will revise the paper to incorporate the suggested clarifications and additions.
read point-by-point responses
-
Referee: [FPGA Implementation Results] The central superiority claims for dynamic power, delay, and PDP rest on comparisons to ESAS and CWAHA, yet the manuscript provides no explicit statement that all three designs were re-implemented by the authors using identical Vivado synthesis settings, optimization directives, place-and-route constraints, clock frequency for power analysis, and input switching activity. These factors directly affect the reported 7.63 mW / 4.639 ns / 35.39 pJ figures; without this confirmation the deltas cannot be attributed solely to the E2AFS architecture.
Authors: We confirm that E2AFS, ESAS, and CWAHA were all re-implemented by the authors on the same Artix-7 device using identical Vivado synthesis settings, optimization directives, place-and-route constraints, clock frequency, and input switching activity vectors for power estimation. We will add an explicit paragraph in the FPGA Implementation Results section stating these conditions to ensure the performance comparisons are fully reproducible and attributable to architectural differences. revision: yes
-
Referee: [Proposed Architecture / Error Evaluation] No design equations, algorithmic steps, or error formulas are supplied for the approximation method. The abstract asserts a “multiplier-free” property and “consistently low deviation,” but without the underlying mapping or error-bound derivation it is impossible to verify the claimed reduction in logic depth or to reproduce the accuracy metrics used for the Sobel and K-means tests.
Authors: The Proposed Architecture section describes the multiplier-free approximation via bit-level manipulations of the mantissa and exponent, along with the resulting logic simplification. To address the concern, we will add explicit design equations for the approximation mapping, a step-by-step algorithmic description (including pseudocode), and the error-bound derivation in the revised manuscript. This will enable verification of the logic-depth reduction and reproduction of the accuracy metrics. revision: yes
-
Referee: [Application-Level Validation] The claim that approximation error “does not meaningfully degrade” end-to-end quality in Sobel edge detection and K-means quantization is load-bearing for the error-tolerant suitability argument, yet the manuscript reports only qualitative confirmation without quantitative metrics (e.g., PSNR, clustering accuracy delta, or visual difference scores) comparing exact versus approximate outputs.
Authors: We acknowledge that the current application validation relies primarily on qualitative visual comparisons. In the revision, we will add quantitative metrics: PSNR and SSIM for Sobel edge detection, and clustering accuracy/purity deltas for K-means, directly comparing exact and approximate outputs. These additions will provide objective support for the claim that approximation error does not meaningfully degrade end-to-end quality. revision: yes
Circularity Check
No circularity in empirical hardware design and FPGA results
full rationale
The paper proposes an approximate floating-point square-root hardware architecture (E2AFS) and reports direct FPGA synthesis metrics (power, delay, PDP) plus error and application-level results on Artix-7. No derivation chain, first-principles prediction, parameter fitting presented as output, or self-citation load-bearing any claim is present. Central results are empirical measurements from synthesis and testing, not reductions to inputs by construction or renaming of prior results. This matches the reader's assessment of minimal circularity burden for a design paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Parhami, Computer Arithmetic: Algorithms and Hardware Designs
B. Parhami, Computer Arithmetic: Algorithms and Hardware Designs . London, U.K.: Oxford University Press, 2000
work page 2000
-
[2]
Approximate computing: An emerging paradigm for energy-efficient design,
J. Han and M. Orshansky, “Approximate computing: An emerging paradigm for energy-efficient design,” in 2013 18th IEEE European Test Symposium (ETS) , 2013, pp. 1–6
work page 2013
-
[3]
A review, classification, and comparative evaluation of approximate arithmetic circuits,
H. Jiang, C. Liu, L. Liu, F. Lombardi, and J. Han, “A review, classification, and comparative evaluation of approximate arithmetic circuits,” J. Emerg. Technol. Comput. Syst. , vol. 13, no. 4, Aug. 2017
work page 2017
-
[4]
Approximate arithmetic circuits: A survey, characterization, and recent applications,
H. Jiang, F. J. H. Santiago, H. Mo, L. Liu, and J. Han, “Approximate arithmetic circuits: A survey, characterization, and recent applications,” Proceedings of the IEEE, vol. 108, no. 12, pp. 2108–2135, 2020
work page 2020
-
[5]
Systematic design of an approximate adder: The opti- mized lower part constant-or adder,
A. Dalloo, A. Najafi, and A. Garcia-Ortiz, “Systematic design of an approximate adder: The opti- mized lower part constant-or adder,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 26, no. 8, pp. 1595–1599, 2018
work page 2018
-
[6]
Design and evaluation of low power error tolerant adder,
R. NA, A. A. A, and S. P, “Design and evaluation of low power error tolerant adder,” in 2023 International Conference on Next Generation Electronics (NEleX) , 2023, pp. 1–6
work page 2023
-
[7]
Design of approximate radix-4 booth multipliers for error-tolerant computing,
W. Liu, L. Qian, C. Wang, H. Jiang, J. Han, and F. Lombardi, “Design of approximate radix-4 booth multipliers for error-tolerant computing,” IEEE Transactions on Computers , vol. 66, no. 8, pp. 1435–1441, 2017
work page 2017
-
[8]
Design and analysis of approximate redundant binary multipliers,
W. Liu, T. Cao, P. Yin, Y. Zhu, C. Wang, E. E. Swartzlander, and F. Lombardi, “Design and analysis of approximate redundant binary multipliers,” IEEE Transactions on Computers , vol. 68, no. 6, pp. 804–819, 2019
work page 2019
-
[9]
Energy-efficient logarithmic square rooter for error-resilient applications,
N. Arya, M. Pattanaik, and G. Sharma, “Energy-efficient logarithmic square rooter for error-resilient applications,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems , vol. 29, no. 11, pp. 1994–1997, 11 2021
work page 1994
-
[10]
Esas: Exponent series based approximate square root design,
O. G. Ratnaparkhi and M. Rao, “Esas: Exponent series based approximate square root design,” in 2022 25th Euromicro Conference on Digital System Design (DSD) , 2022, pp. 39–45
work page 2022
-
[11]
P. Goyal and S. K. Sahoo, “Low-power hardware architecture of optimized logarithmic square rooter with enhanced error compensation for error-tolerant systems,” Integration, vol. 105, p. 102522, 2025
work page 2025
-
[12]
Cwaha: Cluster-wise approximation for hardware implementation of arithmetic functions,
O. G. Ratnaparkhi and M. Rao, “Cwaha: Cluster-wise approximation for hardware implementation of arithmetic functions,” in 2023 IEEE Computer Society Annual Symposium on VLSI (ISVLSI) , 2023, pp. 1–6
work page 2023
-
[13]
Vivado design suite tutorial: Power analysis and optimization,
X. Inc., “Vivado design suite tutorial: Power analysis and optimization,” 2022, available at: https: //www.xilinx.com. 10
work page 2022
-
[14]
New metrics for the reliability of approximate and probabilistic adders,
J. Liang, J. Han, and F. Lombardi, “New metrics for the reliability of approximate and probabilistic adders,” IEEE Transactions on Computers , vol. 62, pp. 1760–1771, 09 2013
work page 2013
-
[15]
R. Gonzalez and R. Woods, Digital Image Processing . Upper Saddle River, N.J.: Prentice Hall, 2008
work page 2008
-
[16]
Design tradeoffs in a hardware implemen- tation of the k-means clustering algorithm,
M. Leeser, J. Theiler, M. Estlick, and J. Szymanski, “Design tradeoffs in a hardware implemen- tation of the k-means clustering algorithm,” in Proceedings of the 2000 IEEE Sensor Array and Multichannel Signal Processing Workshop. SAM 2000 (Cat. No.00EX410) , 2000, pp. 520–524. 11
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.