Recognition: unknown
Input-Side Variance Suppression under Non-Normal Transient Amplification in Continuous-Control Reinforcement Learning
Pith reviewed 2026-05-10 04:50 UTC · model grok-4.3
The pith
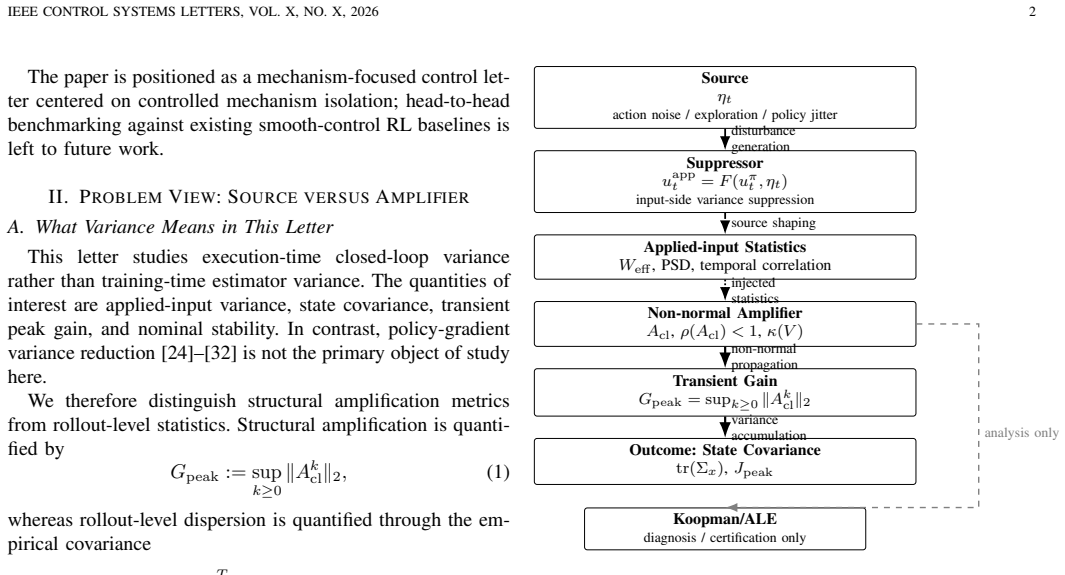
In stable non-normal control loops from RL, small input perturbations get transiently amplified into large state covariance, and suppressing input variance reduces the downstream effect without changing peak gain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the studied continuous-control RL settings, non-normal transient amplification in stable closed loops turns small input perturbations into disproportionately large state covariance; an input-side variance suppression layer reduces applied-input variance and thereby lowers downstream covariance without altering the structural peak gain, as demonstrated by separating eigenvector geometry from input statistics and validating on quadrotor tasks with surrogate models used only for analysis.
What carries the argument
The source-amplifier decomposition of closed-loop variance, in which non-normal transient amplification serves as the amplifier for input perturbations; the input-side variance suppression layer acts as the practical intervention that targets the source side.
If this is right
- Reducing input variance at the policy output can shrink state covariance even when the loop's non-normality and peak gain stay the same.
- The approach supplies a direct way to cut high-frequency jitter without retraining the policy or redesigning the plant.
- The separation of geometry and input-statistic effects shows that variance reduction need not require lowering the system's intrinsic amplification potential.
- Surrogate-based validation indicates the mechanism can be checked on other continuous-control tasks without embedding the surrogates in the controller.
Where Pith is reading between the lines
- If the input-suppression layer works across tasks, it could be inserted as a post-training module to smooth existing policies.
- The finding suggests that some observed jitter in converged RL policies may stem from transient amplification rather than policy nonsmoothness alone.
- The same source-side logic might apply to other non-normal systems where direct gain reduction is costly, such as certain fluid or power-system controls.
Load-bearing premise
That the two interventions cleanly isolate non-normal amplification from other variance sources by fixing eigenvalues versus fixing non-normal geometry, and that the Koopman surrogates faithfully represent the actual closed-loop behavior for validation.
What would settle it
A closed-loop experiment in which input variance is reduced at fixed non-normal geometry yet state covariance does not decrease, or in which eigenvector geometry is altered at fixed eigenvalues yet the predicted change in transient amplification fails to appear.
Figures



read the original abstract
Continuous-control reinforcement learning (RL) often exhibits large closed-loop variance, high-frequency control jitter, and sensitivity to disturbance injection. Existing explanations usually emphasize disturbance sources such as action noise, exploration perturbations, or policy nonsmoothness. This letter studies a complementary amplifier-side perspective: in nominally stable yet strongly non-normal closed loops, small input perturbations can undergo transient amplification and lead to disproportionately large state covariance. Motivated by this source--amplifier decomposition, we introduce an input-side variance suppression layer that operates between the learned policy and the plant input to reduce applied-input variance and step-to-step jitter. To separate mechanism from correlation, we use two control-theoretic interventions: one varies only eigenvector geometry under fixed eigenvalues and spectral radius, and the other varies only applied-input statistics under fixed strongly non-normal geometry. We then provide mechanism-consistent external validation on planar quadrotor tasks. Throughout, Koopman/ALE surrogates are used only as analysis and certification tools, not as direct performance paths. Taken together, the results support a narrower claim: in the studied settings, non-normal transient amplification is an important and under-emphasized contributor to execution-time closed-loop variance, and source-side suppression can reduce downstream covariance without changing the structural peak gain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in continuous-control RL, large closed-loop variance and jitter arise in part from transient amplification due to non-normal dynamics in nominally stable systems. It introduces an input-side variance suppression layer between policy and plant to reduce input variance without altering structural peak gain. To isolate the mechanism, two interventions are used: varying eigenvector geometry at fixed eigenvalues/spectral radius, and varying input statistics at fixed non-normal geometry. External validation on planar quadrotor tasks is provided, with Koopman/ALE surrogates employed strictly as analysis and certification tools rather than direct controllers.
Significance. If the central results hold, the work usefully complements disturbance-focused explanations of RL variance by emphasizing an amplifier-side contribution from non-normality. The source-amplifier decomposition and the demonstration that input-side suppression can reduce downstream covariance without changing peak gain could inform more robust policy deployment. The explicit separation of analysis tools from performance paths and the mechanism-consistent validation approach are strengths that enhance the paper's rigor.
major comments (1)
- [Abstract] Abstract and the description of the two interventions: the claim that these interventions cleanly separate non-normal transient amplification from input-coupling effects is load-bearing for the source-amplifier decomposition. Redesigning feedback to alter eigenvectors while preserving eigenvalues necessarily changes the closed-loop operator and may modify effective input matrix columns or disturbance channels; without explicit equations demonstrating that the input-to-state coupling terms remain invariant, observed covariance differences cannot be attributed solely to the non-normality measure.
minor comments (2)
- [Validation section] Clarify whether the suppression layer parameters are derived independently of the validation data or fitted on the same trajectories used for covariance reporting.
- [Results] Add quantitative details (e.g., percentage covariance reduction, statistical significance) to the quadrotor results to allow direct assessment of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comment. The concern about explicit invariance of input-to-state coupling under the two interventions is well-taken, and we have revised the manuscript to address it directly.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the two interventions: the claim that these interventions cleanly separate non-normal transient amplification from input-coupling effects is load-bearing for the source-amplifier decomposition. Redesigning feedback to alter eigenvectors while preserving eigenvalues necessarily changes the closed-loop operator and may modify effective input matrix columns or disturbance channels; without explicit equations demonstrating that the input-to-state coupling terms remain invariant, observed covariance differences cannot be attributed solely to the non-normality measure.
Authors: We have added explicit state-space equations and derivations in the revised Section III. For the eigenvector intervention, the closed-loop matrix is constructed as A = V Λ V^{-1} with Λ and spectral radius fixed while V is varied; the input matrix B and any disturbance input matrix are held identical across all realizations, so the input-to-state operator (and its columns) remains invariant. The second intervention fixes the non-normal geometry (A and B) and varies only the second-moment statistics of the applied input. These constructions ensure that covariance differences are attributable to the non-normality measure. The added material includes the invariance verification and the precise feedback redesign used. revision: yes
Circularity Check
No significant circularity; derivation relies on independent interventions and external validation
full rationale
The paper introduces an input-side suppression layer and employs two explicit control-theoretic interventions (eigenvector geometry at fixed eigenvalues; input statistics at fixed non-normal geometry) to isolate transient amplification effects, followed by validation on planar quadrotor tasks using Koopman/ALE surrogates strictly as analysis tools. No equations or steps reduce a claimed prediction to a fitted parameter by construction, nor does any load-bearing premise rest on self-citation chains or imported uniqueness theorems. The central claim remains supported by the separation of interventions and task-level results rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The closed-loop system is nominally stable yet strongly non-normal
- domain assumption Koopman/ALE surrogates serve only as analysis and certification tools and do not alter the learned policy
invented entities (1)
-
input-side variance suppression layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Control regularization for reduced variance reinforcement learning,
R. Cheng, A. Verma, G. Orosz, S. Chaudhuri, Y . Yue, and J. W. Burdick, “Control regularization for reduced variance reinforcement learning,” in Proceedings of the 36th International Conference on Machine Learning, 2019, pp. 1141–1150
2019
-
[2]
Regularizing action policies for smooth control with reinforcement learning,
S. Mysore, B. Mabsout, R. Mancuso, and K. Saenko, “Regularizing action policies for smooth control with reinforcement learning,”arXiv preprint arXiv:2012.06644, 2021
-
[3]
Gradient- based regularization for action smoothness in robotic control with reinforcement learning,
I. Lee, H.-G. Cao, C.-T. Dao, Y .-C. Chen, and I.-C. Wu, “Gradient- based regularization for action smoothness in robotic control with reinforcement learning,”arXiv preprint arXiv:2407.04315, 2024
-
[4]
Smooth exploration for robotic reinforcement learning,
A. Raffin, J. Kober, and F. Stulp, “Smooth exploration for robotic reinforcement learning,” inProceedings of the 6th Conference on Robot Learning, 2022, pp. 1634–1644
2022
-
[5]
Addressing function ap- proximation error in actor-critic methods,
S. Fujimoto, H. van Hoof, and D. Meger, “Addressing function ap- proximation error in actor-critic methods,” inProceedings of the 35th International Conference on Machine Learning, 2018, pp. 1587–1596
2018
-
[6]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inProceedings of the 35th International Conference on Machine Learning, 2018, pp. 1861–1870
2018
-
[7]
Action robust reinforcement learning and applications in continuous control,
C. Tessler, Y . Efroni, and S. Mannor, “Action robust reinforcement learning and applications in continuous control,” inProceedings of the 36th International Conference on Machine Learning, 2019, pp. 6215– 6224
2019
-
[8]
Td-regularized actor- critic methods,
S. Parisi, V . Tangkaratt, J. Peters, and M. E. Khan, “Td-regularized actor- critic methods,”Machine Learning, vol. 108, no. 8–9, pp. 1469–1501, 2019
2019
-
[9]
Variance aware reward smoothing for deep reinforcement learning,
Y . Dong, S. Zhang, X. Liu, Y . Zhang, and S. Tan, “Variance aware reward smoothing for deep reinforcement learning,”Neurocomputing, vol. 459, pp. 340–354, 2021
2021
-
[10]
Autore- gressive policies for continuous control deep reinforcement learning,
D. Korenkevych, A. R. Mahmood, G. Vasan, and J. Bergstra, “Autore- gressive policies for continuous control deep reinforcement learning,” inProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, 2019, pp. 2820–2826
2019
-
[11]
Smoothing policies and safe policy gradients,
M. Papini, M. Pirotta, and M. Restelli, “Smoothing policies and safe policy gradients,”arXiv preprint arXiv:1905.03231, 2022
-
[12]
H.-G. Cao, I. Lee, B.-J. Hsu, Z.-Y . Lee, Y .-W. Shih, H.-C. Wang, and I.-C. Wu, “Image-based regularization for action smoothness in autonomous miniature racing car with deep reinforcement learning,” arXiv preprint arXiv:2307.08230, 2023
-
[13]
Hydrodynamic stability without eigenvalues,
L. N. Trefethen, A. E. Trefethen, S. C. Reddy, and T. A. Driscoll, “Hydrodynamic stability without eigenvalues,”Science, vol. 261, no. 5121, pp. 578–584, 1993
1993
-
[14]
Generalized stability theory. part I: Autonomous operators,
B. F. Farrell and P. J. Ioannou, “Generalized stability theory. part I: Autonomous operators,”Journal of the Atmospheric Sciences, vol. 53, no. 14, pp. 2025–2040, 1996
2025
-
[15]
Nonmodal stability theory,
P. J. Schmid, “Nonmodal stability theory,”Annual Review of Fluid Mechanics, vol. 39, pp. 129–162, 2007
2007
-
[16]
Variance maintained by stochastic forcing of non-normal dynamical systems associated with linearly stable shear flows,
B. F. Farrell and P. J. Ioannou, “Variance maintained by stochastic forcing of non-normal dynamical systems associated with linearly stable shear flows,”Physical Review Letters, vol. 72, no. 8, pp. 1188–1191, 1994
1994
-
[17]
Stability- certified reinforcement learning via spectral normalization,
R. Takase, N. Yoshikawa, T. Mariyama, and T. Tsuchiya, “Stability- certified reinforcement learning via spectral normalization,”arXiv preprint arXiv:2012.13744, 2020
-
[18]
Lyapunov-regularized reinforcement learning for power system transient stability,
W. Cui and B. Zhang, “Lyapunov-regularized reinforcement learning for power system transient stability,”arXiv preprint arXiv:2103.03869, 2022
-
[19]
Data-driven nonlinear stabilization using koopman operator,
B. Huang, X. Ma, and U. Vaidya, “Data-driven nonlinear stabilization using koopman operator,”arXiv preprint arXiv:1901.07678, 2019
-
[20]
S. Sinha, S. P. Nandanoori, J. Drgona, and D. Vrabie, “Data-driven sta- bilization of discrete-time control-affine nonlinear systems: A koopman operator approach,”arXiv preprint arXiv:2203.14114, 2022
-
[21]
Data-driven feedback stabilisation of nonlinear systems: Koopman-based model predictive control,
A. Narasingam, S. H. Son, and J. S.-I. Kwon, “Data-driven feedback stabilisation of nonlinear systems: Koopman-based model predictive control,”International Journal of Control, vol. 96, no. 1, pp. 1–16, 2023
2023
-
[22]
Robust data-driven control for nonlinear systems using the koopman operator,
R. Strasser, J. Berberich, and F. Allg ¨ower, “Robust data-driven control for nonlinear systems using the koopman operator,”arXiv preprint arXiv:2304.03519, 2023
-
[23]
Learning stable koopman embeddings for identification and control,
F. Fan, B. Yi, D. Rye, G. Shi, and I. R. Manchester, “Learning stable koopman embeddings for identification and control,”arXiv preprint arXiv:2401.08153, 2024
-
[24]
Variance reduction tech- niques for gradient estimates in reinforcement learning,
E. Greensmith, P. L. Bartlett, and J. Baxter, “Variance reduction tech- niques for gradient estimates in reinforcement learning,”Journal of Machine Learning Research, vol. 5, pp. 1471–1530, 2004
2004
-
[25]
Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic
S. Gu, T. Lillicrap, Z. Ghahramani, R. E. Turner, and S. Levine, “Q- Prop: Sample-efficient policy gradient with an off-policy critic,”arXiv preprint arXiv:1611.02247, 2017
work page Pith review arXiv 2017
-
[26]
Stochastic variance reduction for policy gradient estimation,
T. Xu, Q. Liu, and J. Peng, “Stochastic variance reduction for policy gradient estimation,”arXiv preprint arXiv:1710.06034, 2018
-
[27]
Variance reduction for policy gra- dient with action-dependent factorized baselines,
C. Wu, A. Rajeswaran, Y . Duan, V . Kumar, A. M. Bayen, S. Kakade, I. Mordatch, and P. Abbeel, “Variance reduction for policy gra- dient with action-dependent factorized baselines,”arXiv preprint arXiv:1803.07246, 2018
-
[28]
Trajectory-wise control variates for variance reduction in policy gradient methods,
C.-A. Cheng, X. Yan, and B. Boots, “Trajectory-wise control variates for variance reduction in policy gradient methods,” inProceedings of the 4th Conference on Robot Learning, 2020, pp. 1379–1394
2020
-
[29]
Action- dependent control variates for policy optimization via stein’s identity,
H. Liu, Y . Feng, Y . Mao, D. Zhou, J. Peng, and Q. Liu, “Action- dependent control variates for policy optimization via stein’s identity,” arXiv preprint arXiv:1710.11198, 2018
-
[30]
Analysis and improve- ment of policy gradient estimation,
T. Zhao, H. Hachiya, G. Niu, and M. Sugiyama, “Analysis and improve- ment of policy gradient estimation,” inAdvances in Neural Information Processing Systems, 2011, pp. 262–270
2011
-
[31]
Policy gradient in continuous time,
R. Munos, “Policy gradient in continuous time,”Journal of Machine Learning Research, vol. 7, pp. 771–791, 2006
2006
-
[32]
Reinforcement learning in continuous time and space: A stochastic control approach,
H. Wang, T. Zariphopoulou, and X. Y . Zhou, “Reinforcement learning in continuous time and space: A stochastic control approach,”Journal of Machine Learning Research, vol. 21, no. 198, pp. 1–34, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.