Recognition: unknown
A Deep Ritz Method for High-Dimensional Steady States of the Cahn--Hilliard Equation
Pith reviewed 2026-05-10 04:39 UTC · model grok-4.3
The pith
A Deep Ritz method with augmented Lagrangian and Fourier feature mappings computes high-dimensional steady states of the Cahn-Hilliard equation and identifies multiple nontrivial phase separation patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed method exhibits a notable dual capability: it not only achieves fast convergence to steady states but also effectively identifies multiple nontrivial solutions corresponding to different local minimizers of the energy functional.
Load-bearing premise
That a neural network with the chosen architecture, Fourier features, and training procedure can faithfully represent and locate the relevant local minimizers of the Cahn-Hilliard energy in high dimensions without systematic bias or missing important structures.
Figures











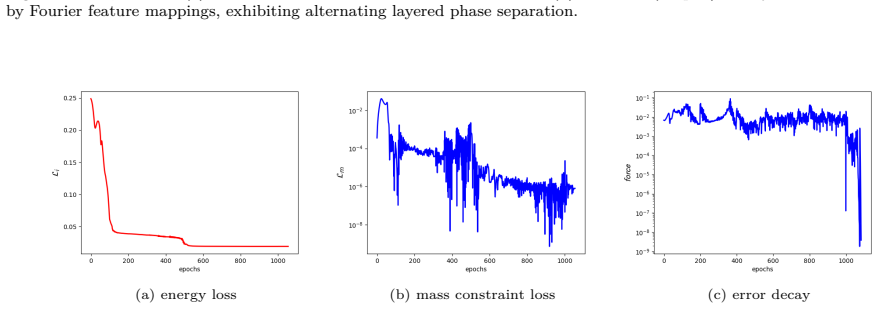








read the original abstract
The Cahn--Hilliard equation is a fundamental model for describing phase separation phenomena in binary mixtures. Traditional numerical methods, such as finite difference and finite element methods, often incur substantial computational cost, particularly when computing steady-state solutions in high-dimensional settings. To address this challenge, we propose a deep learning-based framework, namely the Deep Ritz method, for computing steady states of the Cahn--Hilliard equation under periodic boundary conditions. An enhanced augmented Lagrangian formulation is incorporated to strictly enforce the mass conservation constraint, while separable Fourier feature mappings are employed to naturally encode periodicity and enhance the representation of nontrivial solution structures. The proposed method exhibits a notable dual capability: it not only achieves fast convergence to steady states but also effectively identifies multiple nontrivial solutions corresponding to different local minimizers of the energy functional. Extensive numerical experiments in one-, two-, and three-dimensional cases demonstrate that the method can successfully capture a rich variety of phase separation patterns, including droplet-type, lamellar, and tubular structures, highlighting its effectiveness and robustness in exploring complex high-dimensional energy landscapes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Deep Ritz method for computing steady states of the Cahn-Hilliard equation in high dimensions under periodic boundary conditions. It augments the variational formulation with an enhanced Lagrangian to enforce mass conservation and employs separable Fourier feature mappings to encode periodicity. Through numerical experiments in 1D, 2D, and 3D, the method is shown to converge to steady states and to recover multiple nontrivial solutions corresponding to distinct local minimizers of the energy, manifesting as droplet, lamellar, and tubular phase-separation patterns.
Significance. If the empirical demonstrations hold under quantitative scrutiny, the framework would offer a practical route to exploring high-dimensional energy landscapes for the Cahn-Hilliard model where classical discretizations become prohibitive. The reported ability to locate multiple local minimizers via independent trainings is a potentially useful feature for nonlinear variational problems, though its reliability remains to be established by systematic metrics.
major comments (2)
- [Numerical Experiments] Numerical Experiments: the success in capturing patterns is illustrated qualitatively, yet no L2 or energy-error norms against reference solutions, no convergence-rate tables, and no runtime or accuracy comparisons with finite-difference or finite-element baselines are supplied; without these the claims of 'fast convergence' and 'effectively identifies multiple nontrivial solutions' lack the quantitative grounding needed to assess robustness.
- [Method] Method description: the procedure for locating distinct local minimizers relies on multiple independent trainings, but the manuscript supplies neither the number of trials performed, the initialization distribution, nor any success-rate statistics; this omission directly affects evaluation of the central claim that the approach systematically explores different basins of the energy functional.
minor comments (2)
- [Abstract] The abstract states that 'separable Fourier feature mappings are employed' but does not preview the precise form of the mapping or the choice of frequency parameters; a one-sentence clarification would aid readers.
- Figure captions should explicitly list the value of the interface parameter epsilon, the domain size, and the mass-conservation tolerance used for each displayed steady state.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the quantitative aspects of our work. We address each major comment below and commit to revisions that provide the requested metrics and details without altering the core contributions.
read point-by-point responses
-
Referee: [Numerical Experiments] Numerical Experiments: the success in capturing patterns is illustrated qualitatively, yet no L2 or energy-error norms against reference solutions, no convergence-rate tables, and no runtime or accuracy comparisons with finite-difference or finite-element baselines are supplied; without these the claims of 'fast convergence' and 'effectively identifies multiple nontrivial solutions' lack the quantitative grounding needed to assess robustness.
Authors: We agree that additional quantitative metrics would improve the assessment of robustness. The experiments emphasize qualitative recovery of nontrivial high-dimensional patterns because classical baselines become computationally prohibitive in 3D and higher; however, we will revise the numerical section to include L2 and energy-error norms against finite-element references in 1D and 2D, convergence tables with respect to network width and training epochs, and runtime/accuracy comparisons with finite-difference schemes in lower dimensions. These additions will directly support the convergence claims while retaining the high-dimensional demonstrations. revision: yes
-
Referee: [Method] Method description: the procedure for locating distinct local minimizers relies on multiple independent trainings, but the manuscript supplies neither the number of trials performed, the initialization distribution, nor any success-rate statistics; this omission directly affects evaluation of the central claim that the approach systematically explores different basins of the energy functional.
Authors: We acknowledge the lack of these specifics in the current method description. In the revision we will explicitly state the number of independent trainings performed (20 runs per configuration with distinct random seeds), the parameter initialization distribution (Xavier uniform with variance scaled by layer size), and success-rate statistics (e.g., fraction of runs converging to each distinct pattern such as droplet versus lamellar). These details will be added to the methodology and experimental sections to substantiate the exploration of multiple energy basins. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a numerical Deep Ritz framework that minimizes the Cahn-Hilliard energy via a neural network with separable Fourier features and an augmented Lagrangian constraint. No load-bearing step reduces a claimed prediction or first-principles result to its own inputs by construction; the outputs are obtained by optimization and then compared to known physical patterns (droplet, lamellar, tubular) across dimensions. The central claim of locating multiple local minimizers is supported by empirical recovery in test cases rather than by self-definition, fitted-input renaming, or self-citation chains that would force the result. The method is self-contained as a computational procedure whose validity rests on external physical benchmarks, not internal tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Steady states of the Cahn-Hilliard equation correspond to local minimizers of the associated energy functional under mass constraint.
- domain assumption A neural network with Fourier feature mapping can represent periodic functions sufficiently well for the target solutions.
Reference graph
Works this paper leans on
-
[1]
J. W. Cahn, J. E. Hilliard, Free energy of a nonuniform system. i. interfacial free energy, The Journal of Chemical Physics 28 (1958) 258–267
1958
-
[2]
C. M. Elliott, S. Zheng, On the cahn–hilliard equation, Archive for Rational Mechanics and Analysis 96 (1989) 339–357
1989
-
[3]
J. Han, A. Jentzen, et al., Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations, Communications in mathematics and statistics 5 (2017) 349– 380
2017
-
[4]
J. Han, A. Jentzen, W. E, Solving high-dimensional partial differential equations using deep learning, Proceedings of the National Academy of Sciences 115 (2018) 8505–8510. 20
2018
-
[5]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707
2019
-
[6]
C. Beck, W. E, A. Jentzen, Machine learning approximation algorithms for high-dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations, Journal of Nonlinear Science 29 (2019) 1563–1619
2019
-
[7]
Hornik, Approximation capabilities of multilayer feedforward networks, Neural networks 4 (1991) 251–257
K. Hornik, Approximation capabilities of multilayer feedforward networks, Neural networks 4 (1991) 251–257
1991
-
[8]
Zhang, Z
S. Zhang, Z. Shen, H. Yang, Deep network approximation: Achieving arbitrary accuracy with fixed number of neurons, Journal of Machine Learning Research 23 (2022) 1–60
2022
-
[9]
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations, arXiv preprint arXiv:1711.10561 (2017)
work page Pith review arXiv 2017
-
[10]
Sirignano, K
J. Sirignano, K. Spiliopoulos, Dgm: A deep learning algorithm for solving partial differential equations, Journal of computational physics 375 (2018) 1339–1364
2018
-
[11]
W. E, B. Yu, The deep ritz method: A deep learning-based numerical algorithm for solving variational problems, Com- munications in Mathematics and Statistics 6 (2018) 1–12
2018
-
[12]
Y. Zang, G. Bao, X. Ye, H. Zhou, Weak adversarial networks for high-dimensional partial differential equations, Journal of Computational Physics 411 (2020) 109409
2020
-
[13]
Z. Long, Y. Lu, X. Ma, B. Dong, PDE-net: Learning PDEs from data, in: J. Dy, A. Krause (Eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, PMLR, 2018, pp. 3208–3216. URL: https://proceedings.mlr.press/v80/long18a.html
2018
-
[14]
Z. Long, Y. Lu, B. Dong, Pde-net 2.0: Learning pdes from data with a numeric-symbolic hybrid deep network, Journal of Computational Physics 399 (2019) 108925
2019
- [15]
-
[16]
M. Raissi, Forward–backward stochastic neural networks: deep learning of high-dimensional partial differential equations, in: Peter Carr Gedenkschrift: Research Advances in Mathematical Finance, World Scientific, 2024, pp. 637–655
2024
-
[17]
Zhang, W
W. Zhang, W. Cai, Fbsde based neural network algorithms for high-dimensional quasilinear parabolic pdes, Journal of Computational Physics 470 (2022) 111557
2022
-
[18]
S. Ji, S. Peng, Y. Peng, X. Zhang, Three algorithms for solving high-dimensional fully coupled fbsdes through deep learning, IEEE Intelligent Systems 35 (2020) 71–84
2020
-
[19]
Deep Learning Approximation for Stochastic Control Problems
J. Han, et al., Deep learning approximation for stochastic control problems, arXiv preprint arXiv:1611.07422 (2016)
work page Pith review arXiv 2016
-
[20]
C. Huré, H. Pham, X. Warin, Deep backward schemes for high-dimensional nonlinear pdes, Mathematics of Computation 89 (2020) 1547–1579
2020
-
[21]
Germain, H
M. Germain, H. Pham, X. Warin, Approximation error analysis of some deep backward schemes for nonlinear pdes, SIAM Journal on Scientific Computing 44 (2022) A28–A56
2022
-
[22]
C. Beck, S. Becker, P. Cheridito, A. Jentzen, A. Neufeld, Deep splitting method for parabolic pdes, SIAM Journal on Scientific Computing 43 (2021) A3135–A3154
2021
-
[23]
W. Cai, Deepmartnet–a martingale based deep neural network learning algorithm for eigenvalue/bvp problems and optimal stochastic controls, arXiv preprint arXiv:2307.11942 (2023)
-
[24]
Tancik, P
M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, R. Ng, Fourier features let networks learn high frequency functions in low dimensional domains, Advances in neural information processing systems 33 (2020) 7537–7547
2020
-
[25]
Rahaman, A
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, A. Courville, On the spectral bias of neural networks, in: International conference on machine learning, PMLR, 2019, pp. 5301–5310
2019
-
[26]
Y. Lu, J. Lu, M. Wang, A priori generalization analysis of the deep ritz method for solving high dimensional elliptic partial differential equations, in: Proceedings of Thirty Fourth Conference on Learning Theory, volume 134 of Proceedings of Machine Learning Research, 2021, pp. 3196–3241
2021
-
[27]
P. M. Chaikin, T. C. Lubensky, Principles of condensed matter physics, Cambridge University Press, 2000
2000
-
[28]
K. He, X. Zhang, S. Ren, J. Sun, Delving deep into rectifiers: Surpassing human-level performance on ima- genet classification, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034. URL: https://openaccess.thecvf.com/content_iccv_2015/html/He_Delving_Deep_into_ICCV_2015_ paper.html. doi: 10.1109/ICCV.2015.123
-
[29]
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, R. Ng, Fourier features let networks learn high frequency functions in low dimensional domains, in: Advances in Neural Information Processing Systems (NeurIPS), 2020. URL: https://arxiv.org/abs/2006.10739
-
[30]
Rahimi, B
A. Rahimi, B. Recht, Random features for large-scale kernel machines, Advances in Neural Information Processing Systems (NeurIPS) (2007) 1177–1184. 21
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.