Recognition: unknown
OOPrompt: Reifying Intents into Structured Artifacts for Modular and Iterative Prompting
Pith reviewed 2026-05-10 02:26 UTC · model grok-4.3
The pith
OOPrompt turns user intents into structured, manipulable prompt objects instead of linear text strings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reifying user intents into structured artifacts, OOPrompt enables modular creation, editing, iteration, and reuse of prompts, unifying and generalizing prior point systems for prompt-based LLM interaction. The design space supports this through object-like properties that make intents explicit and manipulable rather than implicit in linear text.
What carries the argument
Object-Oriented Prompting (OOPrompt) paradigm that reifies intents into structured, manipulable artifacts.
If this is right
- Complex prompts can be decomposed into independent, reusable components rather than rewritten from scratch each time.
- Existing techniques such as chain-of-thought or few-shot examples can be encapsulated as distinct object types within the same framework.
- Prompt-based systems gain a consistent way to support iteration on specific intent facets without disrupting the whole prompt.
- Designers of LLM interfaces obtain a unified design space that generalizes multiple ad-hoc prompting methods.
Where Pith is reading between the lines
- The same object model could be applied to other generative interfaces, such as image or code generators, where intents are similarly multifaceted.
- Shared libraries of prompt objects might enable collaboration or version control practices that are currently difficult with plain text prompts.
- Future LLM tools could incorporate visual editors that treat prompts as draggable, connectable components, resembling low-code environments.
Load-bearing premise
The benefits observed in the formative study with 20 participants and the subsequent validation study generalize beyond the specific prototype and participant pool to broader prompt-based LLM systems.
What would settle it
A larger, more diverse user study that finds no measurable gain in prompt composition speed, accuracy, or satisfaction when participants use structured OOPrompt artifacts versus conventional linear text prompts.
Figures






read the original abstract
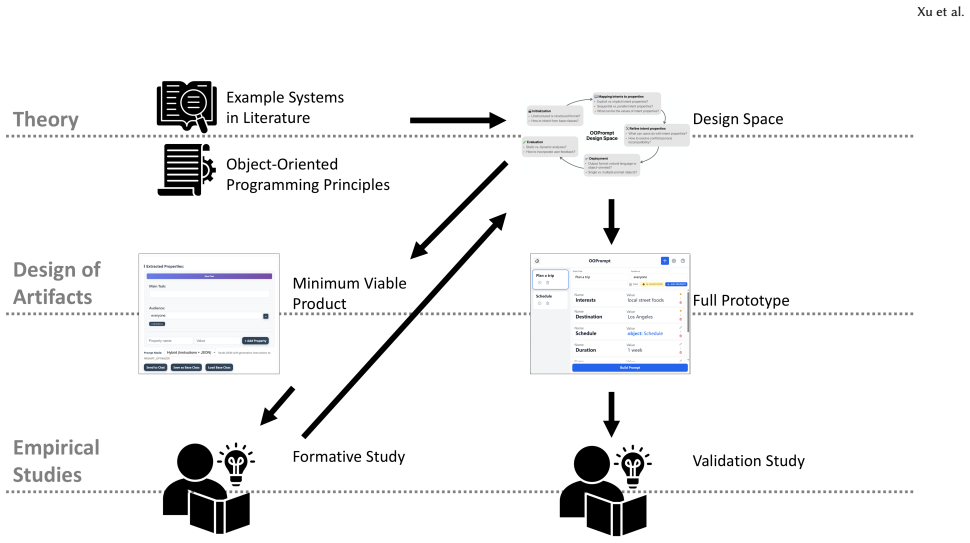
The rise of large language models (LLMs) has given rise to a class of prompt-based interactive systems where users primarily express their input in natural language. However, composing a prompt as a linear text string becomes unwieldy when capturing users' multifaceted intents. We present Object-Oriented Prompting (OOPrompt), an emergent interaction paradigm that enables users to create, edit, iterate, and reuse prompts as structured, manipulable artifacts, unifying and generalizing several existing point systems. We first outlined a design space from existing work and built an early prototype, which we deployed as a probe in a formative study with 20 participants. Their feedback informed an expanded OOPrompt design space. We then developed the full OOPrompt prototype and conducted a validation study to further understand OOPrompt's added values and trade-offs. We expect the OOPrompt design space to provide theoretical and empirical guidance to the design and engineering of prompt-based, LLM-enabled interactive systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Object-Oriented Prompting (OOPrompt) as an interaction paradigm that reifies user intents into structured, manipulable artifacts rather than linear text strings. It derives an initial design space from existing prompting systems, deploys an early prototype in a formative study with 20 participants, expands the design space based on feedback, implements a full prototype, and conducts a validation study to assess added values (modularity, iteration, reuse) and trade-offs, claiming to unify and generalize prior point systems while providing theoretical and empirical guidance for prompt-based LLM interfaces.
Significance. If the validation study's evidence for benefits holds under scrutiny, OOPrompt could meaningfully advance HCI for LLM systems by offering a coherent framework that addresses the scalability limits of linear prompting. The design space and iterative prototype development represent a constructive contribution that could guide engineering of future tools, particularly where complex, multi-faceted intents must be expressed and refined.
major comments (2)
- [Validation study] Validation study section: The manuscript provides no details on the study design, participant demographics or recruitment, specific tasks or prompts used, quantitative or qualitative measures of 'added value' and trade-offs (e.g., how modularity or reuse were operationalized and scored), statistical analysis, or controls for confounds such as prototype familiarity. These omissions are load-bearing because the central claims about unification, generalization, and practical benefits rest directly on the outcomes of this study.
- [Discussion] Discussion or implications section: The assertion that OOPrompt unifies existing systems and that observed benefits transfer beyond the single prototype and participant pool lacks supporting analysis or explicit limitations discussion. The formative study (n=20) and validation study are tied to an iteratively refined prototype whose design space was shaped by the same participants; without evidence or argumentation for transfer to other interfaces, models, or task distributions, the generalization claim cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: The summary of the two studies is too high-level; adding one sentence on key measures or findings would improve standalone readability without lengthening the abstract excessively.
- [Design space] Design space description: Provide concrete examples of how participant feedback from the formative study directly altered specific dimensions of the expanded design space (e.g., new artifact types or manipulation operations).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key areas where our reporting and argumentation can be strengthened. We address each major comment below and will revise the manuscript to improve transparency and balance in our claims.
read point-by-point responses
-
Referee: [Validation study] Validation study section: The manuscript provides no details on the study design, participant demographics or recruitment, specific tasks or prompts used, quantitative or qualitative measures of 'added value' and trade-offs (e.g., how modularity or reuse were operationalized and scored), statistical analysis, or controls for confounds such as prototype familiarity. These omissions are load-bearing because the central claims about unification, generalization, and practical benefits rest directly on the outcomes of this study.
Authors: We agree that the validation study section lacks the necessary detail for readers to fully evaluate the results. The study was executed with a complete protocol, but space constraints led to an abbreviated presentation. In the revised manuscript we will expand this section to describe the full study design, participant recruitment method and demographics, the specific tasks and example prompts used, how modularity, iteration, and reuse were operationalized and scored (both quantitatively and qualitatively), the statistical tests performed, and controls such as counterbalancing and training procedures. We will also include key results tables and representative qualitative excerpts. This revision will make the empirical support for our claims verifiable. revision: yes
-
Referee: [Discussion] Discussion or implications section: The assertion that OOPrompt unifies existing systems and that observed benefits transfer beyond the single prototype and participant pool lacks supporting analysis or explicit limitations discussion. The formative study (n=20) and validation study are tied to an iteratively refined prototype whose design space was shaped by the same participants; without evidence or argumentation for transfer to other interfaces, models, or task distributions, the generalization claim cannot be evaluated.
Authors: We accept that the current discussion does not provide sufficient analysis or limitations to support the unification and generalization statements. The unification claim originates primarily from the initial design space derived from prior prompting literature, with the studies serving as validation rather than the sole basis. Nevertheless, we agree the text requires explicit mapping and a limitations discussion. In revision we will add (1) an analysis that explicitly maps OOPrompt elements to representative prior systems and (2) a dedicated limitations subsection addressing the prototype-specific nature of the findings, the role of the formative study in shaping the design space, participant characteristics, and the absence of direct evidence for transfer across interfaces, models, or task domains. We will also qualify the language around generalization to reflect these boundaries while retaining the design space as the primary generalizable contribution. revision: yes
Circularity Check
No circularity: design-study paper with independent empirical grounding
full rationale
The paper presents OOPrompt as an interaction paradigm derived from an initial design space taken from prior external literature, refined via a formative study (n=20), then validated in a second study. No equations, fitted parameters, or mathematical derivations exist. The unification claim rests on participant feedback and observed benefits in the prototypes, not on any self-referential reduction or self-citation chain. The studies are independent empirical evidence rather than tautological. This is a standard, self-contained HCI contribution with no load-bearing self-definition or prediction-by-construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ian Arawjo, Chelse Swoopes, Priyan Vaithilingam, Martin Wattenberg, and Elena L. Glassman. 2024. ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 304, 18 ...
-
[3]
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al . 2023. Improving im- age generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf2, 3 (2023), 8
2023
-
[4]
2007.Object-Oriented Analysis and Design with Applications (3rd ed.)
Grady Booch, Robert Maksimchuk, Michael Engle, Bobbi Young, Jim Conallen, and Kelli Houston. 2007.Object-Oriented Analysis and Design with Applications (3rd ed.). Addison-Wesley Professional
2007
-
[5]
Virginia Braun and Victoria Clarke. 2021. Thematic analysis: A practical guide. (2021)
2021
-
[6]
Yuzhe Cai, Shaoguang Mao, Wenshan Wu, Zehua Wang, Yaobo Liang, Tao Ge, Chenfei Wu, Wang You, Ting Song, Yan Xia, Jonathan Tien, Nan Duan, and Furu Wei. 2024. Low-code LLM: Graphical User Interface over Large Language Models. arXiv:2304.08103 [cs.CL] https://arxiv.org/abs/2304.08103
-
[7]
Xiang’Anthony Chen, Tiffany Knearem, and Yang Li. 2025. The GenUI Study: Exploring the Design of Generative UI Tools to Support UX Practitioners and Beyond. InProceedings of the 2025 ACM Designing Interactive Systems Conference. 1179–1196
2025
- [8]
-
[9]
Evans Xu Han, Alice Qian Zhang, Haiyi Zhu, Hong Shen, Paul Pu Liang, and Jane Hsieh. 2025. POET: Supporting Prompting Creativity and Personalization with Automated Expansion of Text-to-Image Generation. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–18
2025
-
[10]
Hilary Hutchinson, Wendy Mackay, Bo Westerlund, Benjamin B Bederson, Al- lison Druin, Catherine Plaisant, Michel Beaudouin-Lafon, Stéphane Conversy, Helen Evans, Heiko Hansen, et al. 2003. Technology probes: inspiring design for and with families. InProceedings of the SIGCHI conference on Human factors in computing systems. 17–24
2003
-
[11]
Peiling Jiang, Jude Rayan, Steven P. Dow, and Haijun Xia. 2023. Graphologue: Exploring Large Language Model Responses with Interactive Diagrams. InPro- ceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA)(UIST ’23). Association for Computing Ma- chinery, New York, NY, USA, Article 3, 20 pages. doi:10....
-
[12]
Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know?Transactions of the Association for Computational Linguistics8 (2020), 423–438
2020
-
[13]
Ishika Joshi, Simra Shahid, Shreeya Venneti, Manushree Vasu, Yantao Zheng, Yunyao Li, Balaji Krishnamurthy, and Gromit Yeuk-Yin Chan. 2024. CoPrompter: User-Centric Evaluation of LLM Instruction Alignment for Improved Prompt Engineering. arXiv:2411.06099 [cs.HC] https://arxiv.org/abs/2411.06099
- [14]
-
[15]
Soomin Kim, Jinsu Eun, Yoobin Elyson Park, Kwangwon Lee, Gyuho Lee, and Joonhwan Lee. 2025. PromptPilot: Exploring User Experience of Prompting with AI-Enhanced Initiative in LLMs.International Journal of Human–Computer Interaction(2025), 1–23. arXiv:https://doi.org/10.1080/10447318.2025.2489030 doi:10.1080/10447318.2025.2489030
-
[16]
Tae Soo Kim, Yoonjoo Lee, Minsuk Chang, and Juho Kim. 2023. Cells, Gen- erators, and Lenses: Design Framework for Object-Oriented Interaction with Large Language Models. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA)(UIST ’23). Association for Computing Machinery, New York, NY, USA, Article...
-
[17]
Tae Soo Kim, Yoonjoo Lee, Jamin Shin, Young-Ho Kim, and Juho Kim. 2024. Evallm: Interactive evaluation of large language model prompts on user-defined criteria. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–21
2024
- [18]
- [19]
-
[20]
Michael Xieyang Liu, Frederick Liu, Alexander J. Fiannaca, Terry Koo, Lucas Dixon, Michael Terry, and Carrie J. Cai. 2024. “We Need Structured Output”: To- wards User-centered Constraints on Large Language Model Output. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI ’24). ACM, 1–9. doi:10.1145/3613905.3650756
-
[21]
Yuhan Liu, Michael JQ Zhang, and Eunsol Choi. 2025. User feedback in human- LLM dialogues: a lens to understand users but noisy as a learning signal. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2666–2681
2025
- [22]
-
[23]
Qianou Ma, Weirui Peng, Hua Shen, Kenneth Koedinger, and Tongshuang Wu
-
[24]
What you say= what you want? Teaching humans to articulate require- ments for LLMs
-
[25]
Qianou Ma, Weirui Peng, Chenyang Yang, Hua Shen, Ken Koedinger, and Tong- shuang Wu. 2025. What should we engineer in prompts? training humans in requirement-driven llm use.ACM Transactions on Computer-Human Interaction 32, 4 (2025), 1–27
2025
-
[26]
Wendy E. Mackay and Anne-Laure Fayard. 1997. HCI, natural science and design: a framework for triangulation across disciplines. InProceedings of the 2nd Conference on Designing Interactive Systems: Processes, Practices, Methods, and Techniques(Amsterdam, The Netherlands)(DIS ’97). Association for Computing Machinery, New York, NY, USA, 223–234. doi:10.114...
- [27]
-
[28]
Damien Masson, Sylvain Malacria, Géry Casiez, and Daniel Vogel. 2024. Direct- gpt: A direct manipulation interface to interact with large language models. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–16
2024
- [29]
-
[30]
Swaroop Mishra, Daniel Khashabi, Chitta Baral, Yejin Choi, and Hannaneh Hajishirzi. 2022. Reframing instructional prompts to gptk’s language. InFindings of the association for computational linguistics: ACL 2022. 589–612
2022
-
[31]
2013.The design of everyday things: Revised and expanded edition
Don Norman. 2013.The design of everyday things: Revised and expanded edition. Basic books
2013
-
[32]
Savvas Petridis, Michael Terry, and Carrie Jun Cai. 2023. Promptinfuser: Bringing user interface mock-ups to life with large language models. InExtended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems. 1–6
2023
-
[33]
Nicholas Polys, Ayat Mohammed, and Ben Sandbrook. 2024. Prompt Engineering for X3D Object Creation with LLMs. InProceedings of the 29th International ACM Conference on 3D Web Technology(Guimarães, Portugal)(Web3D ’24). Association for Computing Machinery, New York, NY, USA, Article 18, 7 pages. doi:10.1145/ 3665318.3677159
-
[34]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[35]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125 [cs.CV] https://arxiv.org/abs/2204.06125
work page internal anchor Pith review arXiv
-
[36]
Laria Reynolds and Kyle McDonell. 2021. Prompt programming for large language models: Beyond the few-shot paradigm. InExtended abstracts of the 2021 CHI conference on human factors in computing systems. 1–7
2021
-
[37]
Nathalie Riche, Anna Offenwanger, Frederic Gmeiner, David Brown, Hugo Romat, Michel Pahud, Nicolai Marquardt, Kori Inkpen, and Ken Hinckley. 2025. AI- Instruments: Embodying Prompts as Instruments to Abstract & Reflect Graphical Interface Commands as General-Purpose Tools. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI...
- [38]
-
[39]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schul- hoff, Pranav Sandeep Dulepet, Saurav Vidyadhara, Dayeon Ki, Sweta Agrawal, Chau Pham, Gerson Kroiz, Feileen Li, Hudson Tao, Ashay Srivastava, Hevan- der Da Costa, Saloni Gupta, Megan L. Rogers, Inna Goncearenc...
work page internal anchor Pith review arXiv 2025
-
[40]
L. Shen, H. Li, Y. Wang, X. Xie, and H. Qu. 2025. Prompting Generative AI with Interaction-Augmented Instructions. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems. ACM, 1–9. Xu et al
2025
-
[41]
Shneiderman. 1983. Direct Manipulation: A Step Beyond Programming Lan- guages.Computer16, 8 (1983), 57–69. doi:10.1109/MC.1983.1654471
-
[42]
Hari Subramonyam, Roy Pea, Christopher Pondoc, Maneesh Agrawala, and Colleen Seifert. 2024. Bridging the gulf of envisioning: Cognitive challenges in prompt based interactions with llms. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–19
2024
-
[43]
Sangho Suh, Meng Chen, Bryan Min, Toby Jia-Jun Li, and Haijun Xia. 2024. Luminate: Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Art...
-
[44]
Sangho Suh, Bryan Min, Srishti Palani, and Haijun Xia. 2023. Sensecape: En- abling Multilevel Exploration and Sensemaking with Large Language Models. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). ACM, 1–18. doi:10.1145/3586183.3606756
-
[45]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Ming Wang, Yuanzhong Liu, Xiaoyu Liang, Songlian Li, Yijie Huang, Xiaoming Zhang, Sijia Shen, Chaofeng Guan, Daling Wang, Shi Feng, Huaiwen Zhang, Yifei Zhang, Minghui Zheng, and Chi Zhang. 2024. LangGPT: Rethinking Structured Reusable Prompt Design Framework for LLMs from the Programming Language. arXiv:2402.16929 [cs.SE] https://arxiv.org/abs/2402.16929
-
[47]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL] https: //arxiv.org/abs/2201.11903
work page internal anchor Pith review arXiv 2023
-
[48]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next- Gen LLM Applications via Multi-Agent Conversation. arXiv:2308.08155 [cs.AI] https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Tongshuang Wu, Ellen Jiang, Aaron Donsbach, Jeff Gray, Alejandra Molina, Michael Terry, and Carrie J Cai. 2022. PromptChainer: Chaining Large Language Model Prompts through Visual Programming. InExtended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA) (CHI EA ’22). Association for Computing Machinery, New Y...
-
[50]
Tongshuang Wu, Michael Terry, and Carrie Jun Cai. 2022. AI Chains: Transpar- ent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts. InProceedings of the 2022 CHI Conference on Human Factors in Comput- ing Systems(New Orleans, LA, USA)(CHI ’22). Association for Computing Ma- chinery, New York, NY, USA, Article 385, 22 pages. do...
-
[51]
Haijun Xia, Bruno Araujo, Tovi Grossman, and Daniel Wigdor. 2016. Object- Oriented Drawing. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems(San Jose, California, USA)(CHI ’16). Association for Computing Machinery, New York, NY, USA, 4610–4621. doi:10.1145/2858036. 2858075
- [52]
-
[53]
Xiaotong Xu, Jiayu Yin, Catherine Gu, Jenny Mar, Sydney Zhang, Jane L E, and Steven P Dow. 2024. Jamplate: Exploring llm-enhanced templates for idea reflection. InProceedings of the 29th International Conference on Intelligent User Interfaces. 907–921
2024
-
[54]
Zamfirescu-Pereira, Richmond Y
J.D. Zamfirescu-Pereira, Richmond Y. Wong, Bjoern Hartmann, and Qian Yang
-
[55]
Zhang, Jonathan Bragg, and Joseph Chee Chang
Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 437, 21 pages. doi:10.1145/3544548. 3581388
-
[56]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF inter- national conference on computer vision. 3836–3847
2023
-
[57]
Zhongyi Zhou, Jing Jin, Vrushank Phadnis, Xiuxiu Yuan, Jun Jiang, Xun Qian, Kristen Wright, Mark Sherwood, Jason Mayes, Jingtao Zhou, Yiyi Huang, Zheng Xu, Yinda Zhang, Johnny Lee, Alex Olwal, David Kim, Ram Iyengar, Na Li, and Ruofei Du. 2025. InstructPipe: Generating Visual Blocks Pipelines with Human Instructions and LLMs. arXiv:2312.09672 [cs.HC] doi:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.