Recognition: unknown
LoopCTR: Unlocking the Loop Scaling Power for Click-Through Rate Prediction
Pith reviewed 2026-05-10 01:41 UTC · model grok-4.3
The pith
LoopCTR trains CTR models with recursive layer reuse but runs inference in a single forward pass that already beats all baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoopCTR introduces a loop scaling paradigm that increases training-time computation through recursive reuse of shared model layers, decoupling computation from parameter growth. It adopts a sandwich architecture enhanced with Hyper-Connected Residuals and Mixture-of-Experts, and employs process supervision at every loop depth to encode multi-loop benefits into the shared parameters. This enables a train-multi-loop, infer-zero-loop strategy where a single forward pass without any loop already outperforms all baselines.
What carries the argument
Loop scaling via recursive reuse of shared layers with process supervision at every depth inside a sandwich architecture that includes Hyper-Connected Residuals and Mixture-of-Experts.
If this is right
- Achieves state-of-the-art results on three public benchmarks and one industrial dataset.
- Reveals 0.02-0.04 AUC of untapped headroom via oracle analysis.
- Models trained with fewer loops exhibit higher oracle performance ceilings.
- Decouples scaling computation from parameter count, easing industrial deployment constraints.
Where Pith is reading between the lines
- The same supervision pattern could let other parameter-constrained ranking models harvest extra training compute without raising serving cost.
- If the encoding works reliably, inference could become input-adaptive by optionally adding loops only when needed.
- The observed oracle ceiling difference suggests that loop count during training may itself become a tunable hyperparameter for final capacity.
Load-bearing premise
Supervising the output at each successive loop depth successfully embeds the performance gains of multiple loops into the weights so they remain available during a single non-looped forward pass.
What would settle it
Train identical models with and without per-depth process supervision, then compare their zero-loop inference AUC; if the supervised version shows no gain, the core claim does not hold.
Figures






read the original abstract
Scaling Transformer-based click-through rate (CTR) models by stacking more parameters brings growing computational and storage overhead, creating a widening gap between scaling ambitions and the stringent industrial deployment constraints. We propose LoopCTR, which introduces a loop scaling paradigm that increases training-time computation through recursive reuse of shared model layers, decoupling computation from parameter growth. LoopCTR adopts a sandwich architecture enhanced with Hyper-Connected Residuals and Mixture-of-Experts, and employs process supervision at every loop depth to encode multi-loop benefits into the shared parameters. This enables a train-multi-loop, infer-zero-loop strategy where a single forward pass without any loop already outperforms all baselines. Experiments on three public benchmarks and one industrial dataset demonstrate state-of-the-art performance. Oracle analysis further reveals 0.02--0.04 AUC of untapped headroom, with models trained with fewer loops exhibiting higher oracle ceilings, pointing to a promising frontier for adaptive inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoopCTR, a loop scaling approach for Transformer-based CTR prediction that reuses shared sandwich layers (with Hyper-Connected Residuals and MoE) recursively during training while applying process supervision at every loop depth. This is claimed to encode multi-loop benefits into the parameters, enabling a train-multi-loop/infer-zero-loop regime in which a single forward pass already outperforms all baselines. Experiments on three public benchmarks plus one industrial dataset report SOTA results, with oracle analysis indicating 0.02-0.04 AUC of remaining headroom that is larger for models trained with fewer loops.
Significance. If the transfer from multi-depth supervision to zero-loop inference holds and the empirical gains are reproducible, the method would offer a practical way to increase training compute without inflating parameter count or inference latency, directly addressing industrial CTR deployment constraints. The oracle analysis also identifies a concrete direction for adaptive inference.
major comments (2)
- [Abstract] Abstract and experimental claims: the central train-multi-loop/infer-zero-loop advantage rests on the untested assumption that process supervision at depths 1, 2, … improves the shared layers' behavior on raw (zero-loop) inputs. No ablation isolating zero-loop performance with vs. without multi-depth supervision is reported, so it remains possible that the observed gains are simply those of ordinary deeper training plus extra compute rather than a genuine transfer effect.
- [Experiments] Experimental section: SOTA claims on public and industrial datasets are presented without details on baseline re-implementations, hyper-parameter search budgets, statistical significance tests, or variance across runs. This absence directly undermines assessment of the reported AUC improvements and the oracle-headroom numbers.
minor comments (2)
- [Method] The definition and implementation of Hyper-Connected Residuals and the MoE routing inside the sandwich layers are described at a high level; a precise equation or pseudocode block would improve reproducibility.
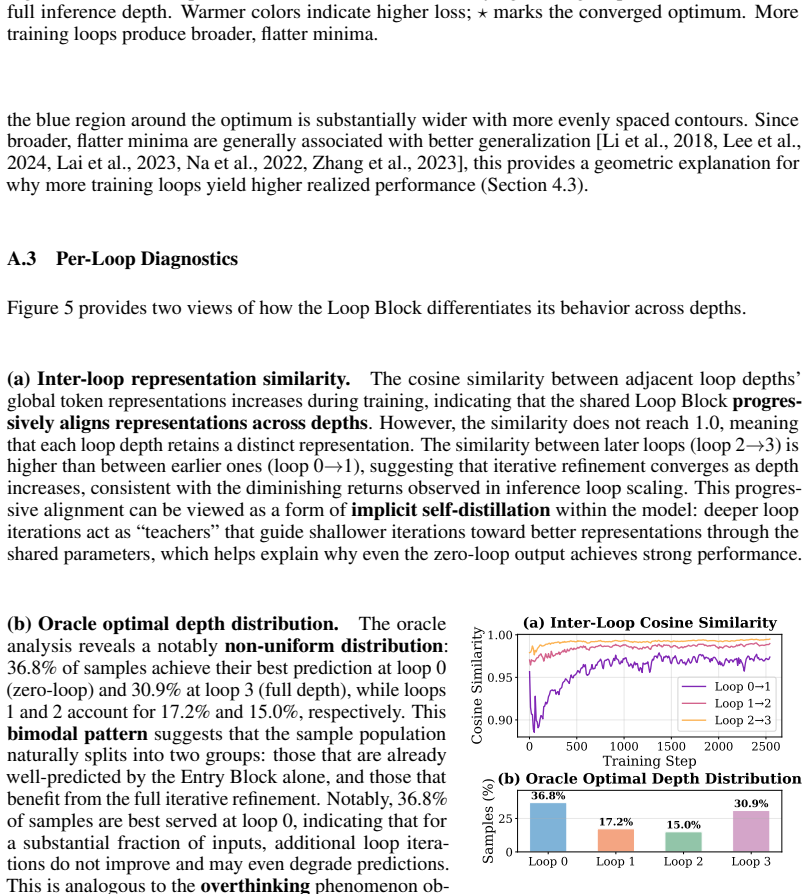
- [Analysis] The oracle analysis (0.02-0.04 AUC headroom) is intriguing but would benefit from a brief description of how the oracle is constructed and whether it is computed on the same test splits used for the main results.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of our claims and experimental reporting that we will address in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental claims: the central train-multi-loop/infer-zero-loop advantage rests on the untested assumption that process supervision at depths 1, 2, … improves the shared layers' behavior on raw (zero-loop) inputs. No ablation isolating zero-loop performance with vs. without multi-depth supervision is reported, so it remains possible that the observed gains are simply those of ordinary deeper training plus extra compute rather than a genuine transfer effect.
Authors: We agree that an explicit ablation isolating the effect of multi-depth process supervision on zero-loop performance is necessary to substantiate the transfer claim. In the revised manuscript we will add this ablation by training and evaluating two variants on the same public and industrial datasets: one with process supervision applied only at the final loop depth and one with supervision at all depths. Both variants will be evaluated strictly in zero-loop inference mode. This will directly test whether the gains arise from the supervision mechanism rather than from increased training compute or depth alone. The oracle analysis already indicates untapped headroom that varies with training-loop count, but we accept that direct comparative evidence is required. revision: yes
-
Referee: [Experiments] Experimental section: SOTA claims on public and industrial datasets are presented without details on baseline re-implementations, hyper-parameter search budgets, statistical significance tests, or variance across runs. This absence directly undermines assessment of the reported AUC improvements and the oracle-headroom numbers.
Authors: We acknowledge that the current experimental section lacks sufficient detail for full reproducibility and statistical assessment. In the revision we will expand the section to report: (i) precise re-implementation details for each baseline, including any architectural adaptations required to match our evaluation protocol; (ii) the hyper-parameter search space, budget, and selection procedure applied to both LoopCTR and the baselines; (iii) statistical significance tests (e.g., paired t-tests across runs) on the reported AUC differences; and (iv) mean and standard deviation of AUC across at least five independent runs with different random seeds. These additions will allow readers to evaluate the magnitude and reliability of the claimed improvements and the oracle-headroom estimates. revision: yes
Circularity Check
No significant circularity; empirical claims rest on benchmarks, not self-referential definitions
full rationale
The paper introduces LoopCTR with a sandwich architecture, Hyper-Connected Residuals, MoE, and process supervision across loop depths to support a train-multi/infer-zero strategy. However, the central performance claims are validated through experiments on three public benchmarks and one industrial dataset, plus oracle analysis, rather than any equations or quantities defined in terms of themselves. No self-citations are load-bearing for uniqueness theorems, no fitted inputs are relabeled as predictions, and no ansatzes are smuggled via prior work. The derivation chain is self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
free parameters (1)
- loop depth during training
axioms (1)
- domain assumption Process supervision at every loop depth encodes multi-loop benefits into shared parameters
invented entities (1)
-
Hyper-Connected Residuals
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Association for Computing Machinery. ISBN 9781450340359. doi: 10.1145/2959100.2959190. URLhttps://doi.org/10.1145/2959100.2959190. Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber, Christopher Potts, and Christopher D Manning. Moeut: Mixture-of-experts universal transformers.Advances in Neural Information Processing Systems, 37:28589–28614,
-
[3]
Sunhao Dai, Jiakai Tang, Jiahua Wu, Kun Wang, Yuxuan Zhu, Bingjun Chen, Bangyang Hong, Yu Zhao, Cong Fu, Kangle Wu, et al. Onepiece: Bringing context engineering and reasoning to industrial cascade ranking system.arXiv preprint arXiv:2509.18091,
-
[4]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers.arXiv preprint arXiv:1807.03819,
work page internal anchor Pith review arXiv
-
[5]
arXiv preprint arXiv:2409.15647 (2024)
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
-
[6]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983,
work page internal anchor Pith review arXiv
-
[7]
Hiformer: Heterogeneous feature interactions learning with transformers for recommender systems
Huan Gui, Ruoxi Wang, Ke Yin, Long Jin, Maciej Kula, Taibai Xu, Lichan Hong, and Ed H Chi. Hiformer: Heterogeneous feature interactions learning with transformers for recommender systems. arXiv preprint arXiv:2311.05884,
-
[8]
Training Compute-Optimal Large Language Models
10 Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10,
work page internal anchor Pith review arXiv
-
[9]
Mixformer: Co-scaling up dense and sequence in industrial recommenders
Xu Huang, Hao Zhang, Zhifang Fan, Yunwen Huang, Zhuoxing Wei, Zheng Chai, Jinan Ni, Yuchao Zheng, and Qiwei Chen. Mixformer: Co-scaling up dense and sequence in industrial recommenders. arXiv preprint arXiv:2602.14110, 2026a. Yunwen Huang, Shiyong Hong, Xijun Xiao, Jinqiu Jin, Xuanyuan Luo, Zhe Wang, Zheng Chai, Shikang Wu, Yuchao Zheng, and Jingjian Lin....
-
[10]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Scaling recommender transformers to one billion parameters.arXiv preprint arXiv:2507.15994,
Kirill Khrylchenko, Artem Matveev, Sergei Makeev, and Vladimir Baikalov. Scaling recommender transformers to one billion parameters.arXiv preprint arXiv:2507.15994,
-
[12]
Yeskendir Koishekenov, Aldo Lipani, and Nicola Cancedda. Encode, think, decode: Scaling test-time reasoning with recursive latent thoughts.arXiv preprint arXiv:2510.07358,
-
[13]
Association for Computing Machinery. ISBN 9798400702419. doi: 10.1145/3604915.3608831. URL https://doi.org/10.1145/3604915. 3608831. Youngwan Lee, Jeffrey Ryan Willette, Jonghee Kim, and Sung Ju Hwang. Visualizing the loss landscape of self-supervised vision transformer,
-
[14]
ISBN 9781450368896. doi: 10.1145/3343031.3350950. URL https://doi.org/10.1145/ 3343031.3350950. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
-
[15]
Train flat, then compress: Sharpness-aware minimization learns more compressible models
Clara Na, Sanket Vaibhav Mehta, and Emma Strubell. Train flat, then compress: Sharpness-aware minimization learns more compressible models. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4909–4936, Abu Dhabi, United Arab Emirates, December
2022
-
[16]
doi: 10.18653/v1/2022.findings-emnlp.361
Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.361. 11 Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with latent thoughts: On the power of looped transformers.arXiv preprint arXiv:2502.17416,
-
[17]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419,
work page internal anchor Pith review arXiv
-
[18]
Think before recommend: Unleashing the latent reasoning power for sequential recommendation
Jiakai Tang, Sunhao Dai, Teng Shi, Jun Xu, Xu Chen, Wen Chen, Jian Wu, and Yuning Jiang. Think before recommend: Unleashing the latent reasoning power for sequential recommendation.arXiv preprint arXiv:2503.22675,
-
[19]
Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the web conference 2021, pages 1785–1797,
2021
-
[20]
mHC: Manifold-Constrained Hyper-Connections
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, et al. mhc: Manifold-constrained hyper-connections.arXiv preprint arXiv:2512.24880,
work page internal anchor Pith review arXiv
-
[21]
Kevin Xu and Issei Sato. On expressive power of looped transformers: Theoretical analysis and enhancement via timestep encoding.arXiv preprint arXiv:2410.01405,
-
[22]
Liren Yu, Wenming Zhang, Silu Zhou, Tao Zhang, Zhixuan Zhang, and Dan Ou. Hhft: Hierarchical heterogeneous feature transformer for recommendation systems.arXiv preprint arXiv:2511.20235,
-
[23]
ISBN 9798400720406. doi: 10.1145/3746252.3761527. URLhttps://doi.org/10.1145/3746252.3761527. Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152,
-
[24]
Dhen: A deep and hierarchical ensemble network for large-scale click-through rate prediction,
Buyun Zhang, Liang Luo, Xi Liu, Jay Li, Zeliang Chen, Weilin Zhang, Xiaohan Wei, Yuchen Hao, Michael Tsang, Wenjun Wang, et al. Dhen: A deep and hierarchical ensemble network for large-scale click-through rate prediction.arXiv preprint arXiv:2203.11014,
-
[25]
Wukong: Towards a scaling law for large-scale recommendation,
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, et al. Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545,
-
[26]
Ruifeng Zhang, Zexi Huang, Zikai Wang, Ke Sun, Bohang Zheng, Yuchen Jiang, Zhe Chen, Zhen Ouyang, Huimin Xie, Phil Shen, et al. Zenith: Scaling up ranking models for billion-scale livestreaming recommendation.arXiv preprint arXiv:2601.21285,
-
[27]
doi: 10.1109/CVPR52729.2023.01932. Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender.arXiv preprint arXiv:2510.26104,
-
[28]
arXiv preprint arXiv:2409.19606 , year=
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. Hyper-connections.arXiv preprint arXiv:2409.19606,
-
[29]
Scaling Latent Reasoning via Looped Language Models
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6309–6316, 2025a. Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tiany...
work page internal anchor Pith review arXiv 2018
-
[30]
2 / 2 .8719.8713 .6492 .7441 .6600 .8816 2 / 3 .8705 .8682 .6576 .7423 .6593 .8833 2 / 4 .8726 .8713.6560 .7448 .6638.8774 2 / 5 .8688 .8674 .6607 .7446 .6624.8759 16 Activated experts.Activating 2 out of 4 experts yields the best AUC on both datasets. Using only 1 expert (no routing diversity) and activating all 4 experts (no sparsity) both degrade perfo...
-
[31]
Let Tseq and Tglb denote the number of sequential and global tokens after long-term sequence compression, respectively, and let T= Tseq +T glb
D.2 Complexity Analysis We analyze the computational complexity of LoopCTR. Let Tseq and Tglb denote the number of sequential and global tokens after long-term sequence compression, respectively, and let T= Tseq +T glb. Let d denote the hidden dimension, dff the FFN intermediate dimension, n the number of hyper-connection streams, E the total number of Mo...
2048
-
[32]
demonstrated improved length generalization on algo- rithmic reasoning tasks. On the practical side, MoEUT [Csordás et al., 2024], LoopLM [Zhu et al., 2025b], and ETD [Koishekenov et al., 2025] have explored training strategies for weight-tied models in language modeling. These works collectively validate the potential of looped architectures, yet they al...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.