Recognition: unknown
LAFA: A Framework for Reproducible Longitudinal Assessment of Protein Function Annotation Models
Pith reviewed 2026-05-09 22:14 UTC · model grok-4.3
The pith
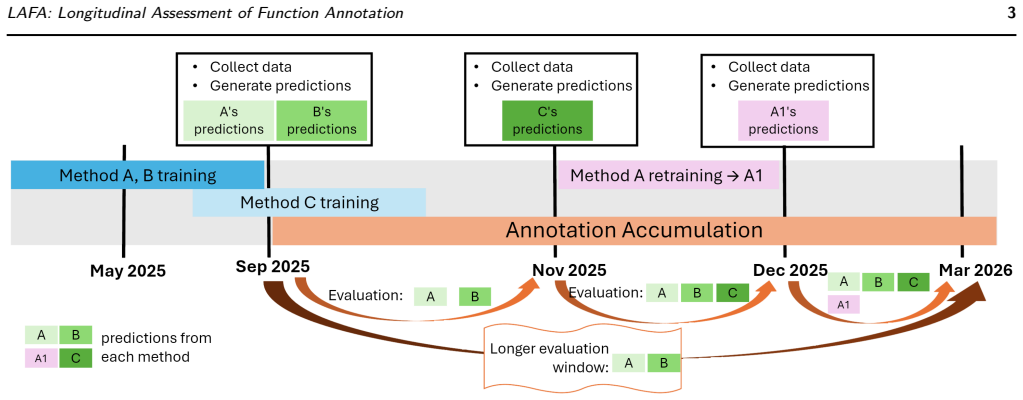
LAFA provides ongoing benchmarking of containerized protein function prediction methods against accumulating annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LAFA is a persistent benchmarking system that continuously evaluates containerized function prediction methods, enabling up-to-date and robust comparative assessment of method performance under evolving ground truth.
What carries the argument
The LAFA server, which hosts and repeatedly executes containerized prediction methods for standardized, time-delayed evaluations against growing annotation sets.
If this is right
- Prediction methods can be compared more frequently than the triennial CAFA events allow.
- Developers receive timely signals on how performance shifts as new ground-truth annotations accumulate.
- Reproducibility improves because all methods run inside standardized containers.
- The field gains a finer-grained record of progress instead of snapshots every three years.
- New methods can be added and assessed without waiting for the next formal challenge.
Where Pith is reading between the lines
- Similar continuous frameworks could be adapted for other bioinformatics prediction tasks such as structure or interaction modeling.
- Aggregated long-term results might reveal whether certain algorithmic families maintain advantages as annotation volume grows.
- Automated ingestion of new annotations from public databases could reduce manual intervention and extend the platform's reach.
- Users of prediction tools might begin selecting methods based on their tracked performance trajectories rather than single challenge rankings.
Load-bearing premise
Containerized methods can be executed reliably and consistently over long periods without technical drift, data access problems, or changes in annotation standards invalidating prior results.
What would settle it
A previously submitted containerized method fails to produce comparable output when rerun after several months because of dependency updates or database changes.
Figures
read the original abstract
Motivation: Protein function prediction is a challenging task and an open problem in computational biology. The Critical Assessment of protein Function Annotation (CAFA) is a triennial, community-driven initiative that provides an independent, large-scale evaluation of computational methods for protein function prediction through time-delayed benchmarking experiments. CAFA has played a key role in highlighting high-performing methodologies and fostering detailed analysis and exchange of ideas. However, outside the periodic CAFA challenges, there is no platform for the continuous evaluation of newly developed methods and tracking performance as function annotations accumulate. Results: Here we introduce the Longitudinal Assessment of Protein Function Annotation Models server (LAFA) as a persistent benchmarking system for protein function prediction methods. LAFA provides a continuous evaluation of containerized function prediction methods, enabling up-to-date and robust comparative assessment of method performance under evolving ground truth. LAFA accelerates methodological iteration, supports reproducibility, and offers a more dynamic and fine-grained view of progress in protein function prediction. Code and Data Availability: LAFA is available at https://functionbench.net/. Detailed evaluation results can be found at https://github.com/anphan0828/CAFA_forever
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LAFA, a server-based framework for the continuous, longitudinal benchmarking of containerized protein function prediction methods. It positions LAFA as a persistent platform that fills the gap between triennial CAFA challenges by enabling ongoing evaluation of new methods against evolving ground-truth annotations (e.g., from UniProt/GO), with claims of improved reproducibility, up-to-date comparisons, and support for methodological iteration.
Significance. If the implementation delivers on its robustness claims, LAFA would provide a valuable community resource for dynamic performance tracking in protein function annotation, accelerating iteration beyond static CAFA cycles and promoting container-based reproducibility. The public availability of the server (functionbench.net) and evaluation results (GitHub) is a concrete strength that could facilitate adoption and external validation.
major comments (2)
- [Results] Results section (and abstract): The central claim that LAFA enables 'robust comparative assessment' under evolving ground truth rests on the assumption that containerized methods remain executable and produce comparable outputs over years. However, the manuscript provides no concrete mechanisms—such as pinned base images, dependency manifests, re-validation protocols, or handling for upstream library/GO format changes—to prevent Docker image rot or silent output alterations. This is load-bearing for the 'continuous' and 'robust' properties.
- [Methods/Implementation] Implementation or Methods description: No details are given on error-handling, container execution safeguards, or how historical benchmark runs are preserved/invalidated when annotation standards shift. Without these, prior comparisons lose meaning, directly affecting the longitudinal assessment goal.
minor comments (2)
- [Abstract/Introduction] The abstract and introduction could more explicitly reference the CAFA literature and prior benchmarking platforms to better situate the novelty.
- [Figures/Tables] Figure or table captions (if present) should clarify how performance metrics are computed across time points to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of robustness and implementation for the LAFA framework. We address each major comment point by point below. Where the manuscript was lacking in detail, we have revised it to incorporate the requested information.
read point-by-point responses
-
Referee: [Results] Results section (and abstract): The central claim that LAFA enables 'robust comparative assessment' under evolving ground truth rests on the assumption that containerized methods remain executable and produce comparable outputs over years. However, the manuscript provides no concrete mechanisms—such as pinned base images, dependency manifests, re-validation protocols, or handling for upstream library/GO format changes—to prevent Docker image rot or silent output alterations. This is load-bearing for the 'continuous' and 'robust' properties.
Authors: We agree that the original manuscript did not provide sufficient detail on mechanisms to ensure long-term executability and output stability of containerized methods, which is essential to support the claims of robust longitudinal assessment. In the revised manuscript, we have added a dedicated subsection under Implementation describing our approach: all submitted methods use pinned base images (e.g., specific Ubuntu or Python versions) with embedded dependency manifests (requirements.txt, environment.yml, or equivalent); we run periodic re-validation on a fixed reference dataset to detect any drift in outputs due to library updates; and we maintain versioned snapshots of GO and UniProt annotations, with explicit logging of any upstream format changes that could affect comparability. These additions directly address the concern and strengthen the reproducibility claims. revision: yes
-
Referee: [Methods/Implementation] Implementation or Methods description: No details are given on error-handling, container execution safeguards, or how historical benchmark runs are preserved/invalidated when annotation standards shift. Without these, prior comparisons lose meaning, directly affecting the longitudinal assessment goal.
Authors: We acknowledge this omission in the original description. The revised Methods section now includes explicit details on these aspects: error-handling via automated retry logic, comprehensive logging of container exit codes and resource usage, and safeguards such as CPU/memory limits and network isolation during execution. For historical runs, we store each benchmark result with metadata including the exact annotation version and container hash; when major standard shifts occur (e.g., GO term obsoletions or format changes), we flag affected runs as 'epoch-specific' and provide tools for users to filter or re-evaluate within consistent annotation periods. This preserves the integrity of longitudinal comparisons. revision: yes
Circularity Check
No circularity: framework description with no derivations or self-referential claims
full rationale
The manuscript introduces LAFA as a containerized benchmarking server for continuous protein function annotation evaluation. It contains no equations, no fitted parameters, no predictions derived from inputs, and no load-bearing self-citations of uniqueness theorems or ansatzes. The central claim rests on the external availability of the server and GitHub results rather than any internal reduction to prior outputs by construction. This is a standard software-framework paper whose claims are externally verifiable via the provided links and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Containerized methods execute reproducibly across evaluation runs and time
- domain assumption New experimental annotations accumulate reliably and can serve as ground truth
Reference graph
Works this paper leans on
-
[1]
2023 , howpublished =
Iddo Friedberg and Predrag Radivojac and Clara De Paolis and Damiano Piovesan and Parnal Joshi and Walter Reade and Addison Howard , title =. 2023 , howpublished =
2023
-
[2]
Bioinformatics , volume=
Information-theoretic evaluation of predicted ontological annotations , author=. Bioinformatics , volume=. 2013 , publisher=
2013
-
[3]
Nature biotechnology , volume=
The nf-core framework for community-curated bioinformatics pipelines , author=. Nature biotechnology , volume=. 2020 , publisher=
2020
-
[4]
Nucleic Acids Research , volume=
DeepGOWeb: fast and accurate protein function prediction on the (Semantic) Web , author=. Nucleic Acids Research , volume=. 2021 , publisher=
2021
-
[5]
Nucleic acids research , volume=
Gapped BLAST and PSI-BLAST: a new generation of protein database search programs , author=. Nucleic acids research , volume=. 1997 , publisher=
1997
-
[6]
Nature biotechnology , volume=
Nextflow enables reproducible computational workflows , author=. Nature biotechnology , volume=. 2017 , publisher=
2017
-
[7]
Nucleic acids research , volume=
UniProt: the universal protein knowledgebase in 2025 , author=. Nucleic acids research , volume=. 2025 , publisher=
2025
-
[8]
Earth and Space Science , volume=
From open data to open science , author=. Earth and Space Science , volume=. 2021 , publisher=
2021
-
[9]
Proceedings of the ACM on Software Engineering , volume=
Scientific open-source software is less likely to become abandoned than one might think! lessons from curating a catalog of maintained scientific software , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[10]
Advances in Methods and Practices in Psychological Science , volume=
Reproducibility and replicability in a fast-paced methodological world , author=. Advances in Methods and Practices in Psychological Science , volume=. 2019 , publisher=
2019
-
[11]
Briefings in bioinformatics , volume=
Automated protein function prediction—the genomic challenge , author=. Briefings in bioinformatics , volume=. 2006 , publisher=
2006
-
[12]
Nature Reviews Methods Primers , volume=
Containers for computational reproducibility , author=. Nature Reviews Methods Primers , volume=. 2023 , publisher=
2023
-
[13]
Nature Protocols , volume=
Packaging and containerization of computational methods , author=. Nature Protocols , volume=. 2024 , publisher=
2024
-
[14]
Clara De Paolis Kaluza and Damiano Piovesan and Parnal Joshi and Chris Mungall and Martyna Plomecka and Walter Reade and María Cruz , title =
Iddo Friedberg and Predrag Radivojac and Paul D Thomas and An Phan and M. Clara De Paolis Kaluza and Damiano Piovesan and Parnal Joshi and Chris Mungall and Martyna Plomecka and Walter Reade and María Cruz , title =. 2025 , howpublished =
2025
-
[15]
PLoS computational biology , volume=
Annotation error in public databases: misannotation of molecular function in enzyme superfamilies , author=. PLoS computational biology , volume=. 2009 , publisher=
2009
-
[16]
Nucleic Acids Research , volume=
The. Nucleic Acids Research , volume=. 2026 , publisher=
2026
-
[17]
Genome biology , volume=
An expanded evaluation of protein function prediction methods shows an improvement in accuracy , author=. Genome biology , volume=. 2016 , publisher=
2016
-
[18]
Nature methods , volume=
A large-scale evaluation of computational protein function prediction , author=. Nature methods , volume=. 2013 , publisher=
2013
-
[19]
Zhou, Naihui and Jiang, Yuxiang and Bergquist, Timothy R and Lee, Alexandra J and Kacsoh, Balint Z and Crocker, Alex W and Lewis, Kimberley A and Georghiou, George and Nguyen, Huy N and Hamid, Md Nafiz and others , journal=. The. 2019 , publisher=
2019
-
[20]
2024 , publisher=
Piovesan, Damiano and Zago, Davide and Joshi, Parnal and De Paolis Kaluza, M Clara and Mehdiabadi, Mahta and Ramola, Rashika and Monzon, Alexander Miguel and Reade, Walter and Friedberg, Iddo and Radivojac, Predrag and others , journal=. 2024 , publisher=
2024
-
[21]
Trends in Genetics , volume=
Dessimoz, Christophe and. Trends in Genetics , volume=. 2013 , publisher=
2013
-
[22]
Genome Biology , volume=
Empowering bioinformatics communities with Nextflow and nf-core , author=. Genome Biology , volume=. 2025 , publisher=
2025
-
[23]
Proteomics , volume=
Deep learning methods for protein function prediction , author=. Proteomics , volume=. 2025 , publisher=
2025
-
[24]
bioRxiv , pages=
A unified multimodal model for generalizable zero-shot and supervised protein function prediction , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[25]
2020 , publisher=
Kulmanov, Maxat and Hoehndorf, Robert , journal=. 2020 , publisher=
2020
-
[26]
Bioinformatics Advances , volume=
Improving protein function prediction by learning and integrating representations of protein sequences and function labels , author=. Bioinformatics Advances , volume=. 2024 , publisher=
2024
-
[27]
Proteins: Structure, Function, and Bioinformatics , volume=
Continuous Automated Model EvaluatiOn (CAMEO) complementing the critical assessment of structure prediction in CASP12 , author=. Proteins: Structure, Function, and Bioinformatics , volume=. 2018 , publisher=
2018
-
[28]
Proteins: Structure, Function, and Bioinformatics , volume=
Machine learning techniques for protein function prediction , author=. Proteins: Structure, Function, and Bioinformatics , volume=. 2020 , publisher=
2020
-
[29]
Continuous. Proteins , author =. 2021 , pmid =. doi:10.1002/prot.26213 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.